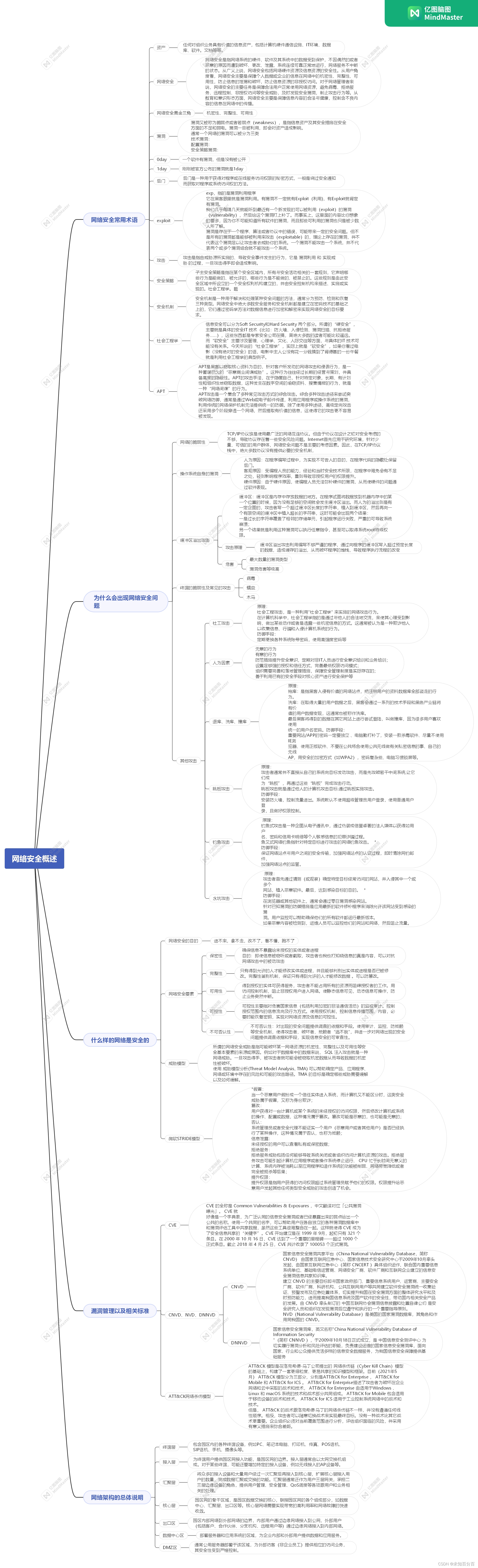
一、说明
本篇是 变压器因其计算效率和可扩展性而成为NLP的首选模型。在计算机视觉中,卷积神经网络(CNN)架构仍然占主导地位,但一些研究人员已经尝试将CNN与自我注意相结合。作者尝试将标准变压器直接应用于图像,发现在中型数据集上训练时,与类似ResNet的架构相比,这些模型的准确性适中。然而,当在更大的数据集上进行训练时,视觉转换器(ViT)取得了出色的结果,并在多个图像识别基准上接近或超过了最先进的技术。本文记录这种结论,等有时机去验证。
二、CNN卷积网络transformer起源
这篇博文的灵感来自谷歌研究团队的一篇题为“图像价值16X16字:大规模图像识别的变形金刚”的论文。本文建议使用直接应用于图像补丁的纯转换器来完成图像分类任务。视觉转换器 (ViT) 在多个基准测试中优于最先进的卷积网络,同时在对大量数据进行预训练后,需要更少的计算资源进行训练。
变压器因其计算效率和可扩展性而成为NLP的首选模型。在计算机视觉中,卷积神经网络(CNN)架构仍然占主导地位,但一些研究人员已经尝试将CNN与自我注意相结合。作者尝试将标准变压器直接应用于图像,发现在中型数据集上训练时,与类似ResNet的架构相比,这些模型的准确性适中。然而,当在更大的数据集上进行训练时,视觉转换器(ViT)取得了出色的结果,并在多个图像识别基准上接近或超过了最先进的技术。
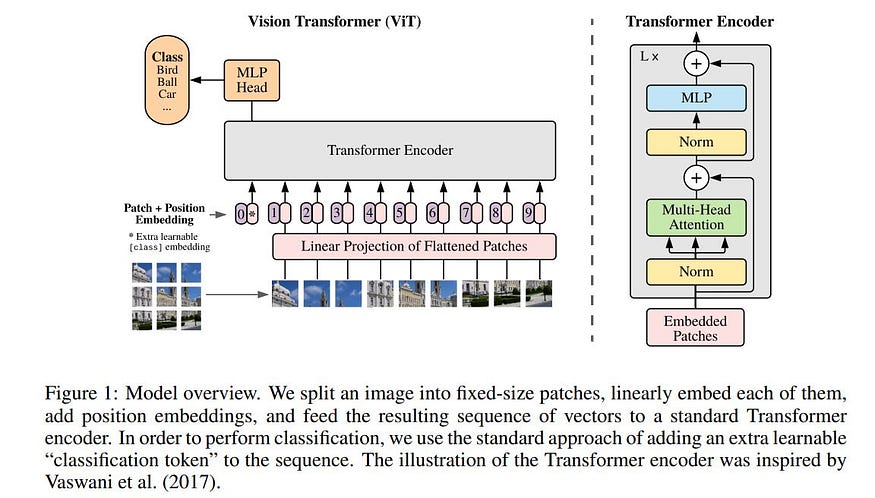
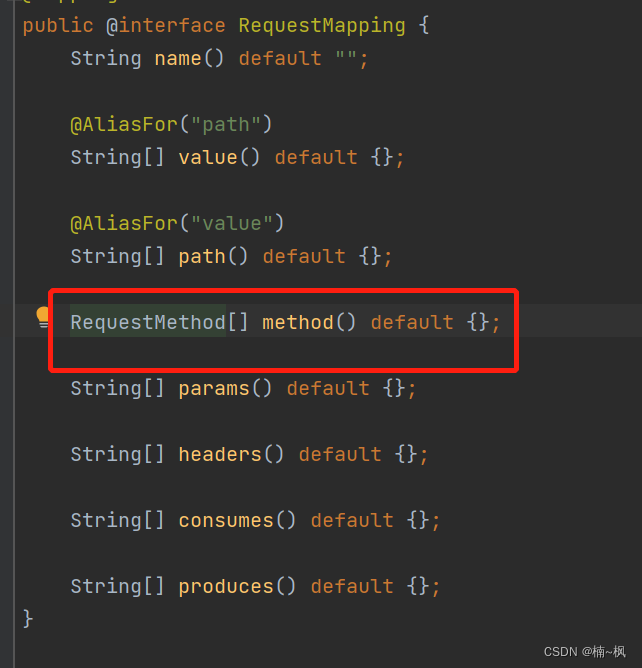
图 1(取自原始论文)描述了一个模型,该模型通过将 2D 图像转换为展平的 2D 补丁序列来处理 <>D 图像。然后将补丁映射到具有可训练线性投影的恒定潜在矢量大小。一个可学习的嵌入被附加到补丁序列之前,它在转换器编码器输出端的状态用作图像表示。然后将图像表示通过分类头进行预训练或微调。添加位置嵌入以保留位置信息,嵌入向量序列用作变压器编码器的输入,该编码器由多头自注意和 MLP 块的交替层组成。
过去,CNN长期以来一直是图像处理任务的首选。它们擅长通过卷积层捕获局部空间模式,从而实现分层特征提取。CNN擅长从大量图像数据中学习,并在图像分类,对象检测和分割等任务中取得了显着的成功。
虽然CNN在各种计算机视觉任务中拥有良好的记录,并且可以有效地处理大规模数据集,但视觉转换器在全局依赖关系和上下文理解至关重要的情况下具有优势。然而,视觉变压器通常需要大量的训练数据才能实现与CNN相当的性能。此外,CNN由于其可并行化的性质而具有计算效率,使其对于实时和资源受限的应用程序更加实用。
三、示例:CNN 与视觉转换器
在本节中,我们将使用 CNN 和视觉转换器方法,在 Kaggle 中可用的猫和狗数据集上训练视觉分类器。首先,我们将从 Kaggle 下载包含 25000 张 RGB 图像的猫和狗数据集。如果您还没有,可以阅读此处的说明,了解如何设置 Kaggle API 凭据。以下 Python 代码会将数据集下载到当前工作目录中。
from kaggle.api.kaggle_api_extended import KaggleApi
api = KaggleApi()
api.authenticate()
# we write to the current directory with './'
api.dataset_download_files('karakaggle/kaggle-cat-vs-dog-dataset', path='./')下载文件后,您可以使用以下命令解压缩文件。
!unzip -qq kaggle-cat-vs-dog-dataset.zip
!rm -r kaggle-cat-vs-dog-dataset.zip使用以下命令克隆视觉转换器 GitHub 存储库。此存储库包含vision_tr目录下的视觉转换器所需的所有代码。
!git clone https://github.com/RustamyF/vision-transformer.git
!mv vision-transformer/vision_tr .下载的数据需要清理并准备训练我们的图像分类器。创建以下实用程序函数以 Pytorch 的 DataLoader 格式清理和加载数据。
import torch.nn as nn
import torch
import torch.optim as optim
from torchvision import datasets, models, transforms
from torch.utils.data import DataLoader, Dataset
from PIL import Image
from sklearn.model_selection import train_test_split
import os
class LoadData:
def __init__(self):
self.cat_path = 'kagglecatsanddogs_3367a/PetImages/Cat'
self.dog_path = 'kagglecatsanddogs_3367a/PetImages/Dog'
def delete_non_jpeg_files(self, directory):
for filename in os.listdir(directory):
if not filename.endswith('.jpg') and not filename.endswith('.jpeg'):
file_path = os.path.join(directory, filename)
try:
if os.path.isfile(file_path) or os.path.islink(file_path):
os.unlink(file_path)
elif os.path.isdir(file_path):
shutil.rmtree(file_path)
print('deleted', file_path)
except Exception as e:
print('Failed to delete %s. Reason: %s' % (file_path, e))
def data(self):
self.delete_non_jpeg_files(self.dog_path)
self.delete_non_jpeg_files(self.cat_path)
dog_list = os.listdir(self.dog_path)
dog_list = [(os.path.join(self.dog_path, i), 1) for i in dog_list]
cat_list = os.listdir(self.cat_path)
cat_list = [(os.path.join(self.cat_path, i), 0) for i in cat_list]
total_list = cat_list + dog_list
train_list, test_list = train_test_split(total_list, test_size=0.2)
train_list, val_list = train_test_split(train_list, test_size=0.2)
print('train list', len(train_list))
print('test list', len(test_list))
print('val list', len(val_list))
return train_list, test_list, val_list
# data Augumentation
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
])
class dataset(torch.utils.data.Dataset):
def __init__(self, file_list, transform=None):
self.file_list = file_list
self.transform = transform
# dataset length
def __len__(self):
self.filelength = len(self.file_list)
return self.filelength
# load an one of images
def __getitem__(self, idx):
img_path, label = self.file_list[idx]
img = Image.open(img_path).convert('RGB')
img_transformed = self.transform(img)
return img_transformed, label四、CNN方法
此图像分类器的 CNN 模型由三层 2D 卷积组成,内核大小为 3,步幅为 2,最大池化层为 2。在卷积层之后,有两个全连接层,每个层由 10 个节点组成。下面是说明此结构的代码片段:
class Cnn(nn.Module):
def __init__(self):
super(Cnn, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=3, padding=0, stride=2),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=3, padding=0, stride=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.layer3 = nn.Sequential(
nn.Conv2d(32, 64, kernel_size=3, padding=0, stride=2),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.fc1 = nn.Linear(3 * 3 * 64, 10)
self.dropout = nn.Dropout(0.5)
self.fc2 = nn.Linear(10, 2)
self.relu = nn.ReLU()
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = self.layer3(out)
out = out.view(out.size(0), -1)
out = self.relu(self.fc1(out))
out = self.fc2(out)
return out训练是用特斯拉T4(g4dn-xlarge)GPU机器进行的,训练了10个训练周期。Jupyter Notebook 在项目的 GitHub 存储库中可用,其中包含训练循环的代码。以下是每个纪元的训练循环的结果。
五、视觉转换器方法
视觉变压器架构设计有可定制的尺寸,可以根据特定要求进行调整。对于这种大小的图像数据集,此体系结构仍然很大。
from vision_tr.simple_vit import ViT
model = ViT(
image_size=224,
patch_size=32,
num_classes=2,
dim=128,
depth=12,
heads=8,
mlp_dim=1024,
dropout=0.1,
emb_dropout=0.1,
).to(device)视觉转换器中的每个参数都起着关键作用,如下所述:
image_size=224:此参数指定模型输入图像的所需大小(宽度和高度)。在这种情况下,图像的大小应为 224x224 像素。patch_size=32:图像被分成较小的补丁,此参数定义每个补丁的大小(宽度和高度)。在本例中,每个修补程序为 32x32 像素。num_classes=2:此参数表示分类任务中的类数。在此示例中,模型旨在将输入分为两类(猫和狗)。dim=128:它指定模型中嵌入向量的维数。嵌入捕获每个图像修补程序的表示形式。depth=12:此参数定义视觉转换器模型(编码器模型)中的深度或层数。更高的深度允许更复杂的特征提取。heads=8:此参数表示模型自注意机制中的注意力头数。mlp_dim=1024:指定模型中多层感知器 (MLP) 隐藏层的维数。MLP 负责在自我注意后转换令牌表示。dropout=0.1:此参数控制辍学率,这是一种用于防止过度拟合的正则化技术。它在训练期间将输入单位的一部分随机设置为 0。emb_dropout=0.1:它定义了专门应用于令牌嵌入的辍学率。此丢弃有助于防止在训练期间过度依赖特定令牌。
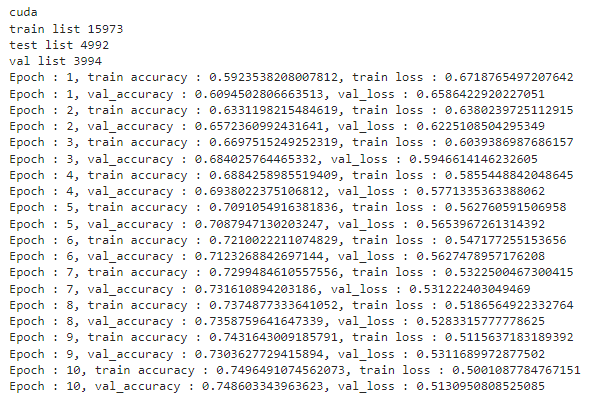
使用Tesla T4(g4dn-xlarge)GPU机器对分类任务的视觉转换器进行了20个训练周期的训练。训练进行了20个epoch(而不是CNN使用的10个epoch),因为训练损失的收敛速度很慢。以下是每个纪元的训练循环的结果。

CNN 方法在 75 个时期内达到了 10% 的准确率,而视觉转换器模型的准确率达到了 69%,训练时间要长得多。
六、结论
总之,在比较CNN和Vision Transformer模型时,在模型大小,内存要求,准确性和性能方面存在显着差异。CNN 型号传统上以其紧凑的尺寸和高效的内存利用率而闻名,使其适用于资源受限的环境。事实证明,它们在图像处理任务中非常有效,并在各种计算机视觉应用中表现出出色的精度。另一方面,视觉变压器提供了一种强大的方法来捕获图像中的全局依赖关系和上下文理解,从而提高某些任务的性能。然而,与CNN相比,视觉变压器往往具有更大的模型尺寸和更高的内存要求。虽然它们可能会达到令人印象深刻的准确性,尤其是在处理较大的数据集时,但计算需求可能会限制它们在资源有限的场景中的实用性。最终,CNN 和 Vision Transformer 模型之间的选择取决于手头任务的特定要求,考虑可用资源、数据集大小以及模型复杂性、准确性和性能之间的权衡等因素。随着计算机视觉领域的不断发展,预计这两种架构将取得进一步进展,使研究人员和从业者能够根据他们的特定需求和限制做出更明智的选择。