文章目录
- 乒乓操作
- 乒乓操作简单介绍
- 乒乓操作的处理流程
- 代码参考
- 功能代码
- testbench
- 波形文件
- 乒乓操作应用场景
- 何时考虑使用乒乓操作
- 乒乓操作的三个优点
- 具体实现分析
- 不间断地处理数据,无缝缓冲与处理
- 可以节约缓冲区空间
- 用低速模块处理高速数据流
乒乓操作
乒乓操作简单介绍
- 乒乓操作常用于数据流的控制处理,在流水处理中,完成数据的无缝缓冲和处理
- 典型乒乓操作示例图

乒乓操作的处理流程
- 输入数据流通过“输入数据选择单元”将数据流等时分配到两个数据缓冲区,数据缓冲区可以为任何存储模块(双口RAM、单口RAM、FIFO等)
- 在第n个缓冲周期,将输入的数据流缓存到“数据缓冲模块1”
- 在第n+1个缓冲周期,通过对“输入数据选择单元”的切换,将输入的数据流缓存到“数据缓冲模块2”,同时将“数据缓冲模块1”缓存的第n个周期的数据通过“输出数据选择单元”的切换,送到“数据流运算处理模块”
- 在第n+2个缓冲周期,通过对“输入数据选择单元”的切换,将输入的数据流缓存到“数据缓冲模块1”,同时将“数据缓冲模块2”缓存的第n+1个周期的数据通过“输出数据选择单元”的切换,送到“数据流运算处理模块”
- 如此循环
代码参考
功能代码
// 乒乓操作
// 输入数据的存储区域分为buffer1和buffer2,分为两个状态,state = 0和state = 1
// state = 0, 读buffer2,写buffer1
// state = 1, 读buffer1,写buffer2
module pinpong (
input clk ,
input rst_n ,
input [7:0] data_in ,
output reg [7:0] data_out
);
// 定义两块存储区域
reg [7:0] buffer1;
reg [7:0] buffer2;
reg wr_flag; // 写标志 wr_flag=0 写buffer1;wr_flag=1 写buffer2
reg rd_flag; // 读标志 rd_flag=0 读buffer2;rd_flag=1 读buffer1
reg state;
// 时序逻辑描述状态转换
always @ (posedge clk or negedge rst_n) begin
if (!rst_n) begin
state = 1'b0;
end else begin
case (state)
1'b0 : state <= 1'b1;
1'b1 : state <= 1'b0;
default : state <= 1'b0;
endcase
end
end
// 输出逻辑
always @(*) begin
if (!rst_n) begin
wr_flag <= 1'd0;
rd_flag <= 1'd0;
end else begin
case (state)
1'b0 : begin
wr_flag <= 1'd0;//写1读2
rd_flag <= 1'd0;
end
1'b1 : begin
wr_flag <= 1'd1;//写2读1
rd_flag <= 1'd1;
end
default : begin
wr_flag <= 1'd0;//写1读2
rd_flag <= 1'd0;
end
endcase
end
end
always @ (posedge clk or negedge rst_n) begin
if (!rst_n) begin
buffer1 <= 8'b0;
buffer2 <= 8'b0;
end else begin
case (wr_flag)
1'b0 : buffer1 <= data_in; //wr_flag = 0 ,写buffer1
2'b1 : buffer2 <= data_in; //wr_flag = 1 ,写buffer2
default : begin
buffer1 <= 8'b0;
buffer2 <= 8'b0;
end
endcase
end
end
always @ (posedge clk or negedge rst_n) begin
if (!rst_n) begin
data_out <= 8'b0;
end else begin
case ( rd_flag)
1'b0 : data_out <= buffer2; //rd_flag = 0,读buffer2
1'b1 : data_out <= buffer1; //rd_flag = 1,读buffer1
default : data_out <= 8'b0 ;
endcase
end
end
endmodule
testbench
`timescale 1ns / 1ps
`include "pingpong.v"
module tb_pinpong;
// pinpong Parameters
parameter PERIOD = 10;
// pinpong Inputs
reg clk = 0 ;
reg rst_n = 0 ;
reg [7:0] data_in = 0 ;
// pinpong Outputs
wire [7:0] data_out ;
initial
begin
forever #(PERIOD/2) clk=~clk;
end
initial
begin
#(PERIOD) rst_n = 1;
end
initial
begin
forever #(PERIOD) data_in = data_in + 1'd1;
end
pinpong u_pinpong (
.clk ( clk ),
.rst_n ( rst_n ),
.data_in ( data_in [7:0] ),
.data_out ( data_out [7:0] )
);
initial
begin
$dumpfile("./build/pingpong.vcd");
$dumpvars;
#1000
$finish;
end
endmodule
波形文件

乒乓操作应用场景
- 学习乒乓操作的处理流程之后,会很明显地想到FIFO操作,因为类似的逻辑想法,从输入端观测,FIFO同样可以对输入数据进行一定的缓存,从输出端观测,从FIFO读出的数据需要按照当前指针按序“选择”读出的数据
- 那在使用时,究竟如何对乒乓操作和FIFO进行选择
何时考虑使用乒乓操作
- 异步FIFO跨时钟域
- 效率第一的场景
- 非空即读的场景
- 不间断读、不间断写的场景
- 数据流接口
乒乓操作的三个优点
- 不间断地处理数据,无缝缓冲与处理
- 可以节约缓冲区空间
- 用低速模块处理高速数据流
具体实现分析
不间断地处理数据,无缝缓冲与处理

-
资源使用情况
- 两个1K大小的FIFO1和FIFO2
- 数据输入1K
-
时序分析
- 第n缓冲周期,data1写入FIFO1
- 第n+1缓冲周期,data2写入FIFO2,并data1从FIFO1读出
- 第n+2缓冲周期,data3写入FIFO1,并data2从FIFO2读出
- 第n+3缓冲周期,data4写入FIFO2,并data3从FIFO1读出
-
观测
- 写侧:n~n+3缓冲周期,无间断写入数据
- 读侧:n+1~n+3缓冲周期,无间断读出数据
-
此时思考一个问题:为何在此处使用两个1K大小的FIFO进行乒乓操作,为何不直接使用1个2K大小的FIFO?
- 若处于同步状态,不存在跨时钟域
- 2个1K大小的FIFO进行乒乓操作,和使用1个2K大小FIFO是一样的
- 因为当前为同步状态,同步状态的FIFO不存在任何安全风险,并且此时无论是缓存空间大小的使用,还是模块的使用,乒乓和FIFO没有本质上的区别
- 这种情况下,可以使用2个1K大小的FIFO配合乒乓操作,同样可以直接使用1个2K大小的FIFO
- 若处于异步状态,存在跨时钟域
- 对于使用2个1K大小FIFO乒乓操作来讲,不存在同时对读写地址进行比较判断空满的情况,因为同一个时间段内,一个FIFO只进行写另一个FIFO只进行读,对于单个FIFO来讲,无需将读侧指针同步到写侧判满或将写侧指针同步到读侧判空,则不存在安全风险问题
- 对于使用1个2K大小的异步FIFO操作来讲,存在同时对读写指针进行比较判断空满的情况,同一个时间段内,既要将读侧指针同步到写侧判满,又需要将写侧指针同步到读侧判空,就有概率出现误判,即误判空或误判满,此时就不能保证数据的无间断
- 故使用1个2K的异步FIFO会出现对同时读写的地址跨时钟同步判断,会引入不可忽视的安全风险,此处2个1K大小FIFO的乒乓操作优于1个2K大小的异步FIFO
- 此处也对应“何时考虑使用乒乓操作”的几种场景
- 若处于同步状态,不存在跨时钟域
可以节约缓冲区空间
- 节约缓冲区空间就是能对一片缓冲区空间进行循环利用
- 这里我们借用OpenZR+中ofec中的操作,具体ofec流程在本篇中不做解释,有兴趣可以官网下载文档学习,关注章节7
- https://www.openzrplus.org/documents/

-
简单说明此处数据操作就是:按照列优先写入数据,最终按照行优先读出数据
-
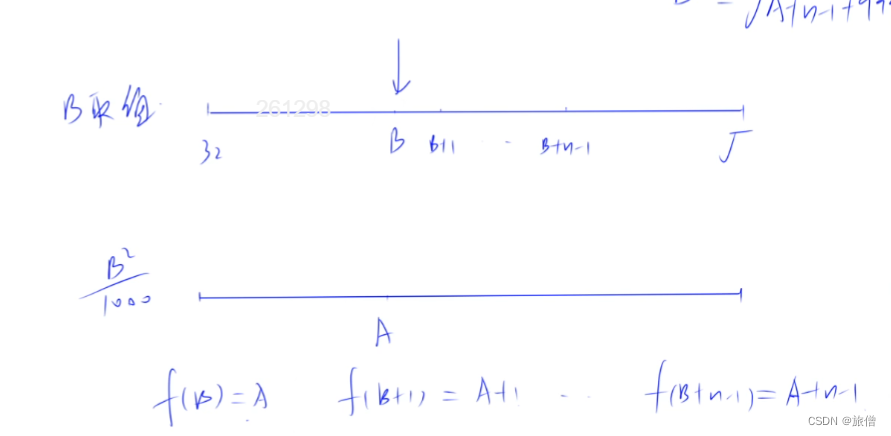
整体需要处理数据量32 * 111bits
- 输入端:32 * 111bits = 16 * 2 * 111bits,按照列优先将数据写入寄存器,一次写入222bits,总共需要16clk将整块数据写入完毕
- 输出端:32 * 111bits = 16 * 2 * 111bits = 16 * 2 * (16 * 6+15)bits,按照行优先将数据从寄存器读出,一次读出222bits,总共需要16clk将整块数据读出完毕
-
如何用到乒乓操作思想
- 由于数据的写入与读出的结构差异,最先写入的数据并不能立马读出,因为对于要读出的结构来讲,数据并没有填充完毕,则基础操作方式可以为:开辟两片同等大小的缓冲区存储数据,当第一大块数据写入完毕,数据可以按序读出时,读出的同时新到来的数据写入第二片缓冲区,以此类推
- 进一步地,我们可以按照结构重新审视缓冲空间的利用程度
- 数据列优先地写入存储器,连续14clk之后,会发现当前首两行的数据已经填充完毕
- 在第15clk,数据列优先地写入存储器的同时,可以按照行优先的方式读出首两行111bits数据,此时第一块32 * 111bits数据还未完全写入但已可以读出
- 在第16clk,数据列优先地写入存储器的同时,可以按照行优先的方式读出首两行111bits数据,此时第一块数据32 * 111bits已完全写入,并已经读出两次数据
- 从第17clk开始,新的整块数据到来时,无需重新开辟新的存储空间,只需将新到来数据写入已读出的位置中即可(不可直接写入,需要按照协议重新排列后写入,但此处关注乒乓操作,ofec原理的具体操作不做过多说明)
- 此处利用读写空间的时钟间隙与数据写入读出的方式,实现了一块大小的空间存储大量数据的功能,从而节约了缓冲区空间
用低速模块处理高速数据流

- 资源使用情况
- 4个1K大小的FIFO
- 时序说明
- 为方便计算与演示,输入端一次输入1K大小数据,周期为1S,即1Kbits/s
- 输出端周期为2S
- 时序分析
- 使用有限的寄存器处理读侧写侧时钟频率不匹配的情况,可以考虑并行度的调整,让两侧吞吐量一致,2 * 1024bits = 1 * 2048bits
- 由于读写频率差异,首先对并行度进行调整后,前后吞吐量一致,单位时间内数据的写入读出平衡,需要开辟4个1K大小的缓冲区空间
- 分析
- 1~2S内数据以1K大小写了两次,分别按顺序写入FIFO1和FIFO
- 3~4S内数据以1K大写写了两次,分别按顺序写入FIFO3和FIFO4,与此同时数据从FIFO1与FIFO2取出拼成1个2K大小的数据读出
- 5~6S内数据以1K大写写了两次,分别按顺序写入FIFO1和FIFO2,与此同时数据从FIFO3与FIFO4取出拼成1个2K大小的数据读出
- 观测
- 写侧:在4S的时间内进行4次写入,共写入4 * 1K的数据量,并且时时刻刻都在写,写无间断
- 读侧:在4S的时间内进行2次读出,共读出2 * 2K的数据量,并且时时刻刻都在读,无间断读
- 从两侧吞吐量来看,单位时间内输入输出比特数相等,并且实现了低速处理高速数据情况