一.索引的基本含义
1.索引类似于一本书的目录,可以加快查询的进度
2.是以列为维度来设置的(为一列来添加索引)
二.索引的优劣
1.优势:提高查询的速度
2.劣势:占据额外的硬盘空间(因为索引的相关数据要存储到硬盘中),可能会拖慢增删改的速度(因为在增删改时索引也同时要进行相应的改变)
三.具体的操作方式
1.创建索引
(1).自动创建
设置主键primary key,外键foreign key,唯一性约束unique会自动在所在的 列上创建索引
(2).手动创建
create index 索引名 on 表名(列名)
2.查看表中的索引
show index from 表名
3.删除索引
drop index 索引名 on 表名
四.索引的数据结构
1.索引的数据结构不推荐哈希表的原因
哈希表的工作原理是把给定的key通过hash函数映射一个具体的下标才能定位到一 个具体的位置,所以哈希表只适用于精确查询,不能够进行模糊查询
2.索引的数据结构不推荐红黑树的原因
红黑树能够进行范围查询和模糊查询但是因为红黑树是二叉树,在数据量过多的时 候二叉树的深度会很深,这会导致在进行查询的时候进行多次的比较,就会导致硬盘进 行多次的IO操作,消耗资源。
3.B+树是为了数据库量身定制的数据结构的原因
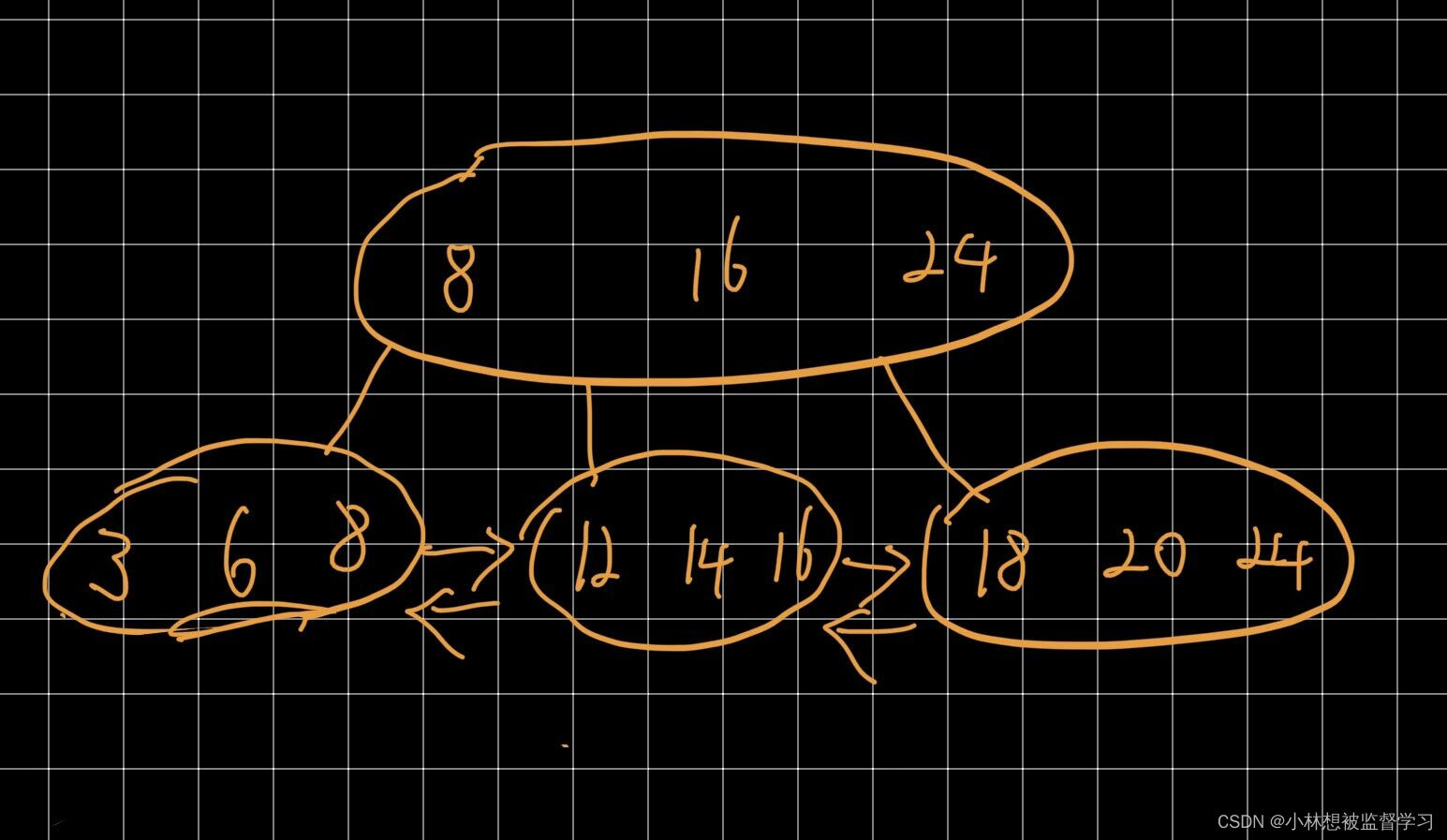
(1).B+树的特点:
a.B+树也是N叉搜索树,但是N个key分出了N个区间,其中节点上的最后一个 key值是最大值
b.父节点中的key会在字节点中重复出现(而且是以最大值的身份),看起来 是有很多的重复元素,浪费了空间,但实际上达成了一个很重要的效果,叶子结点 这一层,包含了整个数据的全集
c.把叶子结点按照链表这样的方式,首尾相连,此时就可以通过叶子结点之间 的这种连接,快速的找到上一个和下一个元素,进一步的也方便范围查询
(2).B+树的优势
a.特别擅长范围查询,因为通过比较查找到范围的起点和终点后,起点和终点在叶 子结点上的链表便是要查询的范围中的值
b.所有的查询操作都会落在叶子节点上吗,比较次数是均衡的,查询时间是稳定的 (有时候稳定比快更重要)
c.由于叶子节点是完整的数据全集,因此表的每一行数据的其他列,都可以保存在 叶子节点上,而非叶子节点,只存储构建索引的key即可(如id)
五.一些细节
其实在物理层面上不需要表格这样的数据结构,直接使用B+树来存储这个表的数据,表 格只是用户看起来这像是一个表格而已
此时非叶子节点的存储空间的消耗是非常少的,可以在内存中缓存一份,此时在进行数据查询的时候就可以通过内存来直接比较,从而更快速的找到叶子节点的记录,比较这个操作发生在内存中,进一步减少了硬盘的IO操作