文章目录
- 使用 Kustomize 定义应用
- 改造示例应用
- 1.创建基准和多环境目录
- 2.环境差异分析
- 3.为 Base 目录创建通用 Manifest
- 4.为开发环境目录创建差异 Manifest
- 5.为预发布环境创建差异 Manifest
- 6.为生产环境创建差异 Manifest
- 部署 Kustomize 应用
- 部署到开发环境
- 部署到生产环境
- 使用 Helm 定义应用
- Helm Chart 和 values.yaml
- Helm Release
- 改造示例应用
- 创建 Helm Chart 目录结构
- 配置 Chart.yaml 内容
- 使用模版变量
- 部署helm应用
- 部署到staging环境
- 部署到prod环境
- 打包发布 Helm Chart
- 创建 GitHub Token
- 推送 Helm Chart
- 安装远端仓库的 Helm Chart
- Helm 应用管理
- 调试 Helm Chart
- 查看已安装的 Helm Release
- 更新 Helm Release
- 查看 Helm Release 历史版本
- 回滚 Helm Release
- 卸载 Helm Release
使用 Kustomize 定义应用
在 Kubernetes 中,标准的应用定义格式则是 YAML 编写的 Manifest 文件。
但是,在实际使用 Kubernetes 时,我们一般都会面临多环境的问题。例如通常我们会把环境分为开发、测试、预发布和生产环境。由于 YAML 是一种“静态”的配置语言,它并不像编程语言一样使用变量来计算最终结果,所以在多环境的情况下,常规方式需要我们编写多套应用配置。
显然,这种直接把多套应用部署到不同环境的方式并不优雅。一是因为多套应用定义很难维护和统一,最后会导致环境之间的差异越来越大;二是因为在大部分情况下,不同环境的 Kubernetes 对象都是相同的,只在一些和环境相关的配置上有差异,编写多套应用定义会导致维护成本增加。
而 Kustomize 正是针对这种场景而设计的应用定义模型。我们只需要定义一套 Kustomize 应用就能够实现对多环境的适配。
本次会将原始的 Kubernetes Manifest 改造成 Kustomize 的应用定义方式。
改造成 Kustomize 之后的效果图:
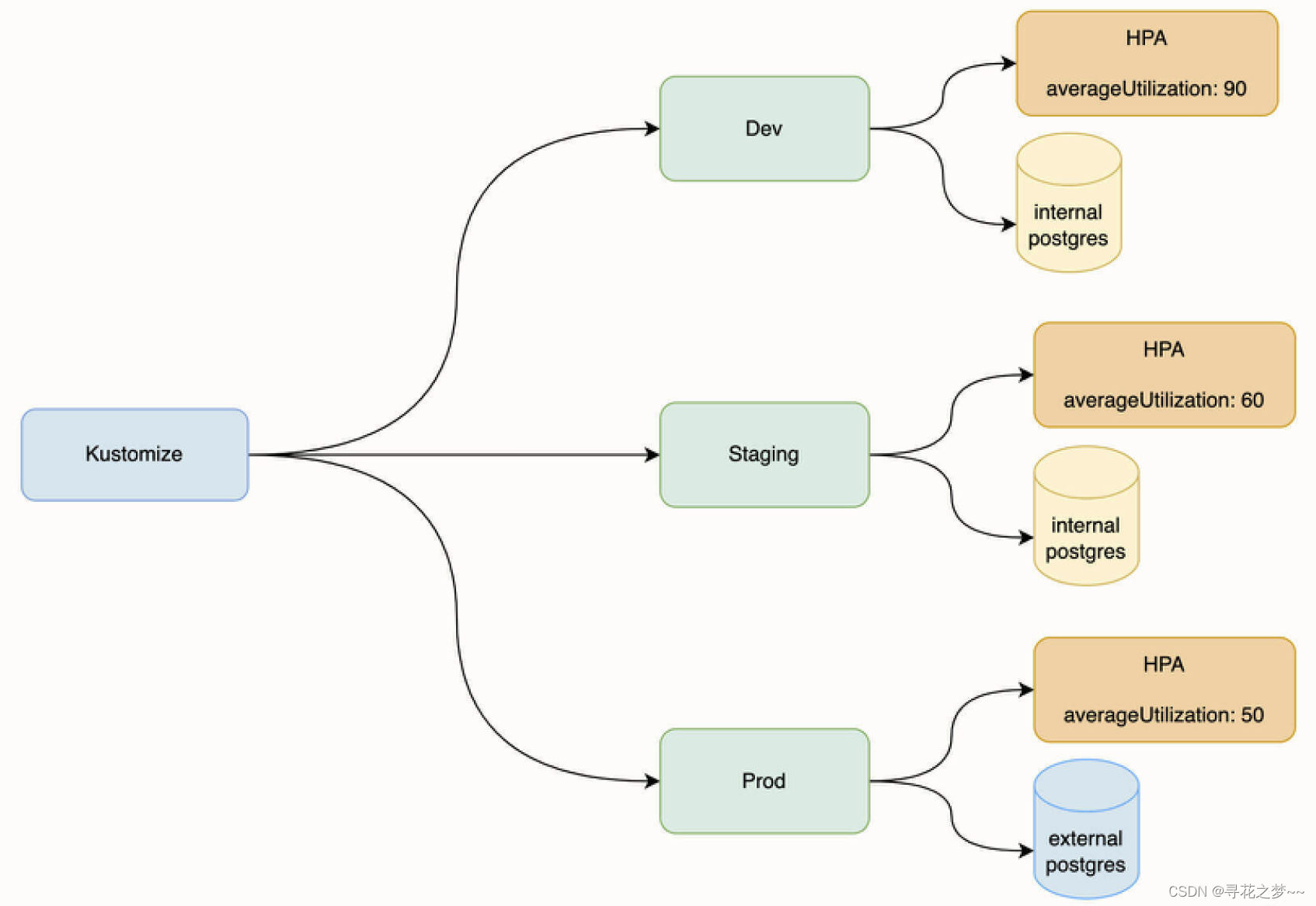
- Dev:开发环境。
- Staging:预发布环境。
- Prod:生产环境。
这三个环境部署的应用都是同一套,但在配置上有所不同。首先,开发环境对稳定性要求一般,所以我们使用在 Kubernetes 集群内部署的 postgres 示例,并且将 HPA 自动伸缩策略的触发条件配置为 “CPU 平均使用率 90% 时触发”,这可以进一步提高开发环境的资源利用率。
预发布环境对稳定性要求相对而言更高一些,我们同样可以使用在 Kubernetes 集群部署的 postgres 实例,但 HPA 触发条件是 “CPU 平均使用率为 60%”,这可以让 HPA 及时介入,确保稳定性。
生产环境对稳定性要求最高,所以一般情况下我们会使用云厂商提供的数据库服务来替代自托管的数据库。另外,HPA 的触发条件也更低,为 50%,在系统产生一定压力时,就让 HPA 提前介入工作。
改造示例应用
1.创建基准和多环境目录
[root@VM-1-13-tencentos kubernetes-example]# ll
total 12
drwxr-xr-x 2 root root 4096 Jul 15 15:09 backend
drwxr-xr-x 2 root root 4096 Jul 15 15:09 deploy
drwxr-xr-x 4 root root 4096 Jul 15 15:09 frontend
[root@VM-1-13-tencentos kubernetes-example]# ls deploy/
backend.yaml database.yaml frontend.yaml hpa.yaml ingress.yaml
[root@VM-1-13-tencentos kubernetes-example]# mkdir kustomize && cd kustomize
[root@VM-1-13-tencentos kustomize]# mkdir base overlay
[root@VM-1-13-tencentos kustomize]# cd overlay && mkdir dev staging prod
PS:
base 是基准目录,它将用来存放 3 个环境共同的 Kubernetes Manifest;
overlay 是多环境目录,用来存放不同环境差异化的 Manifest 文件。
然后进入 overlay 目录,再创建 dev、staging 和 prod 目录,它们分别对应三个环境。
2.环境差异分析
base 目录是基准目录,这意味着不同环境在部署时,都会引用这个目录的 Kubernetes Manifest。因为开发、预发布和生产环境除了 数据库和 HPA 的差异以外,其他的 Manifest 都是通用的。
接下来,我们具体分析一下数据库和 HPA 的差异。
首先,在开发和预发布环境中,我们使用的是部署在 Kubernetes 下的 postgres 实例。所以,对于开发和预发布环境,我们需要部署 postgres Deployment,而在生产环境则不需要部署 postgres。显然,postgres Deployment 不是这三个环境的通用资源,不需要被加入到基准目录中。
其次,对于 HPA 配置,它们的 Manifest 内容是相似的,只有对象中的 averageUtilization 字段值不同。所以在这种情况下, 我们可以认为 HPA 是通用资源,不同环境只需要对 averageUtilization 字段值进行修改即可。
这里要注意一个小细节,在生产环境下,由于后端使用的是外部数据库服务,所以它的数据库连接信息肯定也是不同的。用 Deployment Env 环境变量。这也就意味着,不同环境的 Deployment Manifest 和 HPA 的情况非常类似,内容差不多,只有一些值有差异。所以, 我们也可以认为后端的 Deployment 也是通用资源。
3.为 Base 目录创建通用 Manifest
经过上面的分析,我们可以得出结论,base 目录需要包含的通用 Manifest 有下面这几个文件:
- backend.yaml
- frontend.yaml
- hpa.yaml
- ingress.yaml
[root@VM-1-13-tencentos kubernetes-example]# cp deploy/backend.yaml deploy/frontend.yaml deploy/hpa.yaml deploy/ingress.yaml ./kustomize/base/
需要在 base 目录下额外创建一个文件,告诉 Kustomize 哪些 Manifest 需要被引用。
[root@VM-1-13-tencentos base]# cat kustomization.yaml
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
resources:
- backend.yaml
- frontend.yaml
- hpa.yaml
- ingress.yaml
4.为开发环境目录创建差异 Manifest
[root@VM-1-13-tencentos kubernetes-example]# cp deploy/database.yaml kustomize/overlay/dev/
最重要的一点,开发环境在复用 base 目录的 hpa.yaml 时,还需要改变其中一个字段的值。
Kustomize 的价值就体现在这里,它可以对 Manifest 的某个值进行覆写。
在开发环境,要覆写 hpa.yaml 的 averageUtilization 字段,我们只需要提供差异部分的 Manifest 即可。在 dev 目录下创建 hpa.yaml
[root@VM-1-13-tencentos dev]# cat hpa.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: frontend
spec:
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 90
---
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: backend
spec:
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 90
在这段内容中,我们只提供了 spec.metrics 字段的内容,Kustomize 将对 dev 目录和 base 目录下相同名称的资源进行对比并合并,相同的字段以 dev 目录下的内容为准,这样就实现了覆盖操作。
总结:
我们需要为 Kustomize 提供不同环境下 Manifest 差异的部分,并提供资源类型和名称用于比对。
最后,我们还需要在 kustomize/overlay/dev 目录下创建一个文件,用来向 Kustomize 提供环境的差异信息
[root@VM-1-13-tencentos dev]# ll
total 12
-rw-r--r-- 1 root root 1043 Jul 15 15:18 database.yaml
-rw-r--r-- 1 root root 445 Jul 15 15:19 hpa.yaml
-rw-r--r-- 1 root root 257 Jul 15 15:22 kustomization.yaml
[root@VM-1-13-tencentos dev]# cat kustomization.yaml
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
bases:
- ../../base #定义的通用资源目录的路径
- database.yaml #dev环境需要db
patchesStrategicMerge: #Kustomize 提供的一种修改合并资源的方法
- hpa.yaml
5.为预发布环境创建差异 Manifest
预发布环境和开发环境类似,它对应 kustomize/overlay/staging 目录。除了 HPA averageUtilization 字段配置差异以外,其他配置是相同的。
我们可以直接将 kustomize/overlay/dev 目录下的 database.yaml、hpa.yaml 和 kustomization.yaml 文件拷贝到 kustomize/overlay/staging 目录。
[root@VM-1-13-tencentos kubernetes-example]# cp -r kustomize/overlay/dev/* kustomize/overlay/staging/
注意:
将hpa中的averageUtilization字段改为“60”
最终,kustomize/overlay/staging 目录也同样包含三个文件。
[root@VM-1-13-tencentos kubernetes-example]# ls -l kustomize/overlay/staging/
total 12
-rw-r--r-- 1 root root 1043 Jul 15 15:25 database.yaml
-rw-r--r-- 1 root root 445 Jul 15 15:25 hpa.yaml
-rw-r--r-- 1 root root 257 Jul 15 15:25 kustomization.yaml
6.为生产环境创建差异 Manifest
生产环境对应 kustomize/overlay/prod 目录,它比较特别,和开发环境、预发布环境相比有下面这三个差别。
1.不需要部署 postgres Deployment。
2.HPA averageUtilization 字段不同。
3.后端服务数据库连接信息不同。
对于第一点,处理起来非常简单,只要不在 kustomize/overlay/prod 目录下创建 database.yaml 文件即可。第二点的处理方式和前面两个环境一致,只需要提供 HPA 差异部分即可。对于第三点,需要提供后端服务里 Deployment 文件 Env 环境变量字段的差异文件。
[root@VM-1-13-tencentos kubernetes-example]# cp kustomize/overlay/dev/hpa.yaml kustomize/overlay/prod/
将 kustomize/overlay/prod/hpa.yaml 文件的 averageUtilization 字段修改为 50。
deployment.yaml 文件的作用是修改 Env 环境变量,为生产环境的 Pod 提供外部数据库的连接信息。
[root@VM-1-13-tencentos prod]# cat deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: backend
spec:
template:
spec:
containers:
- name: flask-backend
env:
- name: DATABASE_URI
value: "10.10.10.10"
- name: DATABASE_USERNAME
value: external_postgres
- name: DATABASE_PASSWORD
value: external_postgres
[root@VM-1-13-tencentos prod]# cat kustomization.yaml
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
bases:
- ../../base
patchesStrategicMerge:
- hpa.yaml
- deployment.yaml
到这里就完成了对示例应用的改造。kustomize 目录的结构如下所示。
[root@VM-1-13-tencentos kubernetes-example]# tree -L 3 kustomize/
kustomize/
├── base
│ ├── backend.yaml
│ ├── frontend.yaml
│ ├── hpa.yaml
│ ├── ingress.yaml
│ └── kustomization.yaml
└── overlay
├── dev
│ ├── database.yaml
│ ├── hpa.yaml
│ └── kustomization.yaml
├── prod
│ ├── deployment.yaml
│ ├── hpa.yaml
│ └── kustomization.yaml
└── staging
├── database.yaml
├── hpa.yaml
└── kustomization.yaml
部署 Kustomize 应用
从 1.14 版本开始,kubectl 内置了对 Kustomize 的支持。所以部署 Kustomize 应用同样也可以使用 kubectl。
在这里,我们尝试在一个集群内同时部署开发环境和生产环境,环境之间通过命名空间来做环境隔离。
部署到开发环境
[root@VM-1-13-tencentos kubernetes-example]# kubectl create ns dev
namespace/dev created
[root@VM-1-13-tencentos kubernetes-example]# kubectl apply -k kustomize/overlay/dev -n dev
$ kubectl get hpa backend -n dev --output jsonpath='{.spec.metrics[0].resource.target.averageUtilization}'
90
返回值为 90,符合预期。
$ kubectl get deployment postgres -n dev
NAME READY UP-TO-DATE AVAILABLE AGE
postgres 1/1 1 1 46s
查看 backend Deployment 的 Env 环境变量,检查是否使用了集群内的数据库实例。
$ kubectl get deployment backend -n dev --output jsonpath='{.spec.template.spec.containers[0].env[*]}'
{"name":"DATABASE_URI","value":"pg-service"} {"name":"DATABASE_USERNAME","value":"postgres"} {"name":"DATABASE_PASSWORD","value":"postgres"}
部署到生产环境
[root@VM-1-13-tencentos base]# kubectl create ns prod
namespace/prod created
[root@VM-1-13-tencentos base]# kubectl apply -k kustomize/overlay/prod -n prod
从创建的资源来看,相比较开发环境,生产环境并没有部署 postgres Deployment 和 postgres Service,这同样也符合生产环境资源定义预期。
$ kubectl get hpa backend -n prod --output jsonpath='{.spec.metrics[0].resource.target.averageUtilization}'
50
$ kubectl get deployment postgres -n prod
Error from server (NotFound): deployments.apps "postgres" not found
查看 backend Deployment 的 Env 环境变量,以便检查是否使用了外部数据库。
$ kubectl get deployment backend -n prod --output jsonpath='{.spec.template.spec.containers[0].env[*]}'
{"name":"DATABASE_URI","value":"10.10.10.10"} {"name":"DATABASE_USERNAME","value":"external_postgres"} {"name":"DATABASE_PASSWORD","value":"external_postgres"}
预期。
删除环境:
$ kubectl delete -k kustomize/overlay/dev -n dev
总结:
Kustomize 从实际的场景出发,为我们提供了多环境的解决方案,它除了具备 Kubernetes Manifest 声明式的优势以外,还具有可重用的特性。其次,由于 Kustomize 没有模板语言,直接使用已有的 Manifest 来生成配置,所以将标准的 Kubernetes 应用改造成 Kustomize 应用相对简单。
在将示例应用改造成 Kustomize 的过程中,我设计了 3 套环境,分别是开发、预发布和生产环境,不同环境在配置上存在一些差异,我们也借此理清了 Kustomize 中基准目录和环境目录的概念。
在创建不同的环境目录时,你需要提供两种类型的文件,首先是 kustomization.yaml 文件,其次是用来描述和基准目录差异的文件,Kustomize 将会对比差异,并且进行覆盖操作。需要注意的是,本次主要介绍了 patchesStrategicMerge 这种覆盖方式,这种方式可以覆盖我们大部分的使用场景,不过 Kustomize 还有其他的一些覆盖策略,例如 PatchesJson6902 和 PatchTransformer 等,链接:https://kubectl.docs.kubernetes.io/references/kustomize/builtins/
使用 Helm 定义应用
在使用 Kustomize 对某个对象进行覆写时,你可能注意到了一个细节,那就是我们需要了解 base 目录下通用 Kubernetes 对象的具体细节,例如工作负载的名称和类型,以及字段的结构层级。当业务应用比较简单的时候,由于 Kubernetes 对象并不多,所以提前了解这些细节并没有太大的问题。
但是,当业务应用变得复杂,例如有数十个微服务场景时,那么 Kubernetes 对象可能会有上百个之多,这时候 Kustomize 的应用定义方式可能就会变得难以维护,尤其是当我们在 kustomization.yaml 文件定义大量覆写操作时,这种隐式的定义方式会让人产生迷惑。
其次,如果我们站在应用的发行角度来说,你会发现 Kustomize 对最终用户暴露所有Kubernetes 对象概念的方式太过于底层,我们可能需要一种更上层的应用定义方式。
所以,社区诞生了另一种应用定义方式:Helm。
Helm 是一种真正意义上的 Kubernetes 应用的包管理工具,它对最终用户屏蔽了 Kubernetes 对象概念,将复杂度左移到了应用开发者侧,终端用户只需要提供安装参数,就可以将应用安装到 Kubernetes 集群内。
将示例应用改造成 Helm 之后,我们期望得到的效果:
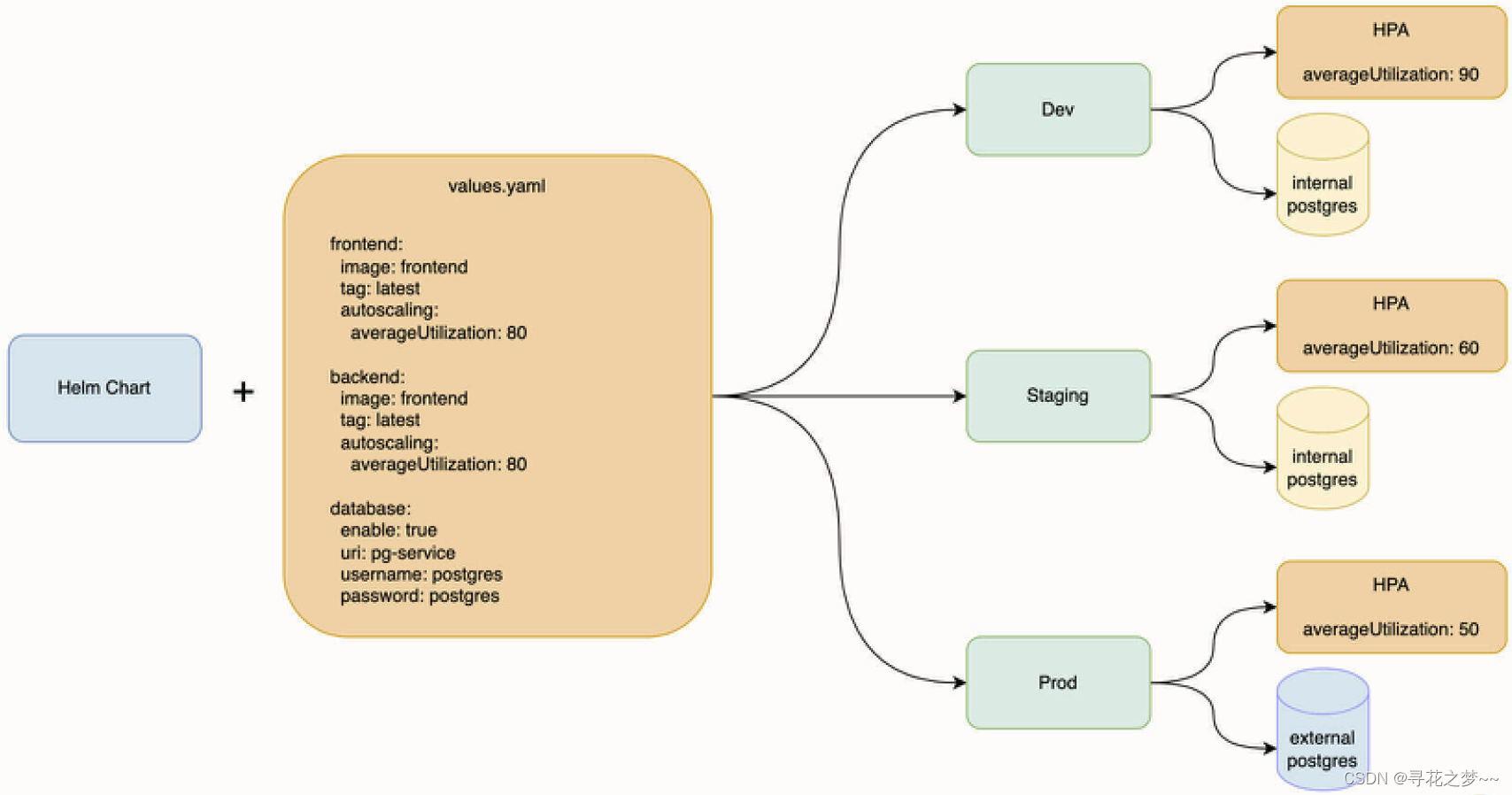
本次实现和 Kustomize 一样的效果,将同一个 Helm Chart 部署到 Dev(开发)、Staging(预发布)、Prod(生产) 三个环境时,控制不同环境的 HPA、数据库以及镜像版本配置。
环境差异方面除了 Prod 环境以外,其他两个环境都使用在集群内部署的 postgres 数据库,另外,三个环境的 HPA 配置也不同。
Helm Chart 和 values.yaml
Chart 是 Helm 的一种应用封装格式,它由一些特定文件和目录组成。为了方便 Helm Chart 存储、分发和下载,它采用 tgz 的格式对文件和目录进行打包。
一个标准的 Helm Chart 目录结构
$ ls
Chart.yaml templates values.yaml
其中,Chart.yaml 文件是 Helm Chart 的描述文件,例如名称、描述和版本等。
templates 目录用来存放模板文件,你可以把它视作 Kubernetes Manifest,但它和 Manifest 最大的区别是,模板文件可以包含变量,变量的值则来自于 values.yaml 文件定义的内容。
values.yaml 文件是安装参数定义文件,它不是必需的。在 Helm Chart 被打包成 tgz 包时,如果 templates 目录下的 Kubernetes Manifest 包含变量,那么你需要通过它来提供默认的安装参数。作为最终用户,当安装某一个 Helm Chart 的时候,也可以提供额外的 YAML 文件来覆盖默认值。比如在上面的期望效果图中,我们为同一个 Helm Chart 提供不同的安装参数,就可以得到具有配置差异的多套环境。
Helm Release
Helm Release 实际上是一个“安装”阶段的概念,它指的是本次安装的唯一标识(名称)
改造示例应用
创建 Helm Chart 目录结构
$ cd kubernetes-example && mkdir helm
$ mkdir helm/templates && touch helm/Chart.yaml && touch helm/values.yaml
配置 Chart.yaml 内容
cat Chart.yaml
apiVersion: v2
name: kubernetes-example
description: A Helm chart for Kubernetes
type: application
version: 0.1.0
appVersion: "0.1.0"
apiVersion 字段设置为 v2,代表使用 Helm 3 来安装应用。
name 表示 Helm Chart 的名称,当使用 helm install 命令安装 Helm Chart 时,指定的名称也就是这里配置的名称。
description 表示 Helm Chart 的描述信息
type 表示类型,这里我们将其固定为 application,代表 Kubernetes 应用。
version 表示我们打包的 Helm Chart 的版本,当使用 helm install 时,可以指定这里定义的版本号。Helm Chart 的版本就是通过这个字段来管理的,当我们发布新的 Chart 时,需要更新这里的版本号。
appVersion 和 Helm Chart 无关,它用于定义应用的版本号,建立当前 Helm Chart 和应用版本的关系。
使用模版变量
values.yaml—模板变量的值都会引自这个文件。根据我们对不同环境配置差异化的要求,我抽象了这几个可配置项:
- 镜像版本
- HPA CPU 平均使用率
- 是否启用集群内数据库
- 数据库连接地址、账号和密码
cat helm/values.yaml
frontend:
image: ccr.ccs.tencentyun.com/app-public/frontend
tag: 'latest'
autoscaling:
averageUtilization: 90
backend:
image: ccr.ccs.tencentyun.com/app-public/backend
tag: 'latest'
autoscaling:
averageUtilization: 90
database:
enabled: true
uri: pg-service
username: postgres
password: postgres
除了 values.yaml,我们还需要让 helm/templates 目录下的文件能够读取到 values.yaml 的内容,这就需要模板变量了。
举一个最简单的例子,要读取 values.yaml 中的 frontend.image 字段,可以通过 “{{ .Values.frontend.image }}” 模板变量来获取值。
所以,要将这个“静态”的 Helm Chart 改造成“动态”的, 我们只需要用模板变量来替换 templates 目录下需要实现“动态”的字段。
了解原理后,我们来修改 helm/templates/backend.yaml 文件,用模板替换需要从 values.yaml 读取的字段。
cat helm/templates/backend.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: backend
labels:
app: backend
spec:
# Answer of lesson 22
replicas: 1
selector:
matchLabels:
app: backend
template:
metadata:
labels:
app: backend
spec:
containers:
- name: flask-backend
image: "{{ .Values.backend.image }}:{{ .Values.backend.tag }}"
imagePullPolicy: Always
ports:
- containerPort: 5000
env:
- name: DATABASE_URI
value: "{{ .Values.database.uri }}"
- name: DATABASE_USERNAME
value: "{{ .Values.database.username }}"
- name: DATABASE_PASSWORD
value: "{{ .Values.database.password }}"
......
cat helm/templates/frontend.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: frontend
labels:
app: frontend
spec:
# do not include replicas in the manifests if you want replicas to be controlled by HPA
replicas: 1
selector:
matchLabels:
app: frontend
template:
metadata:
labels:
app: frontend
spec:
containers:
- name: react-frontend
image: "{{ .Values.frontend.image }}:{{ .Values.frontend.tag }}"
......
还需要修改 helm/templates/hpa.yaml 文件的 averageUtilization 字段。
......
metadata:
name: frontend
spec:
......
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: {{ .Values.frontend.autoscaling.averageUtilization }}
---
......
metadata:
name: backend
spec:
......
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: {{ .Values.backend.autoscaling.averageUtilization }}
注意,相比较其他的模板变量,在这里我们没有在模板变量的外部使用双引号,这是因为 averageUtilization 字段是一个 integer 类型,而双引号加上模板变量的意思是 string 类型。
最后,我们希望使用 values.yaml 中的 database.enable 字段来控制是否向集群提交helm/templates/database.yaml 文件。所以我们可以在文件首行和最后一行增加下面的内容。
{{- if .Values.database.enabled -}}
......
{{- end }}
部署helm应用
在将示例应用改造成 Helm Chart 之后,我们就可以使用 helm install 进行安装了。这里我会将 Helm Chart 分别安装到 helm-staging 和 helm-prod 命名空间,它们对应预发布环境和生产环境,接着我会介绍如何为不同的环境传递不同的参数。
部署到staging环境
我们为 Helm Chart 创建的 values.yaml 实际上是默认值,在预发布环境,我们希望将前后端的 HPA CPU averageUtilization 从默认的 90 调整为 60,你可以在安装时使用 --set 来调整特定的字段,不需要修改 values.yaml 文件。
$ helm install my-kubernetes-example ./helm --namespace helm-staging --create-namespace --set frontend.autoscaling.averageUtilization=60 --set backend.autoscaling.averageUtilization=60
NAME: my-kubernetes-example
LAST DEPLOYED: Sun Jul 16 17:56:30 2023
NAMESPACE: helm-staging
STATUS: deployed
REVISION: 1
TEST SUITE: None
在这个安装例子中,我们使用 --set 参数来调整 frontend.autoscaling.averageUtilization 字段值,其它的字段值仍然采用 values.yaml 提供的默认值。
部署完成后,你可以查看我们为预发布环境配置的后端服务 HPA averageUtilization 字段值。
kubectl get hpa backend -n helm-staging --output jsonpath='{.spec.metrics[0].resource.target.averageUtilization}'
60
返回值为 60,和我们配置的安装参数一致。
同时,你也可以查看是否部署了数据库,也就是 postgres 工作负载。
kubectl get deployment postgres -n helm-staging
NAME READY UP-TO-DATE AVAILABLE AGE
postgres 1/1 1 1 74s
可以查看 backend Deployment 的 Env 环境变量,以便检查是否使用集群内的数据库实例。
kubectl get deployment backend -n helm-staging --output jsonpath='{.spec.template.spec.containers[0].env[*]}'
{"name":"DATABASE_URI","value":"pg-service"} {"name":"DATABASE_USERNAME","value":"postgres"} {"name":"DATABASE_PASSWORD","value":"postgres"}
返回结果都符合预期。
部署到prod环境
部署到生产环境的例子相对来说配置项会更多,除了需要修改 database.enable 字段,禁用集群内数据库实例以外,还需要修改数据库连接的三个环境变量。所以,我们使用另一种安装参数传递方式: 使用文件传递。
要使用文件来传递安装参数,首先需要准备这个文件。你需要将下面的内容保存为 helm/values-prod.yaml 文件。
cat ./helm/values-prod.yaml
frontend:
image: ccr.ccs.tencentyun.com/app-public/frontend
tag: latest
autoscaling:
averageUtilization: 50
backend:
image: ccr.ccs.tencentyun.com/app-public/backend
tag: latest
autoscaling:
averageUtilization: 50
database:
enabled: false
uri: 10.10.10.10
username: external_postgres
password: external_postgres
在 values-prod.yaml 文件内,我们只需要提供覆写的 Key 而不需要原样复制默认的 values.yaml 文件内容,这个操作和 Kustomize 的 Patch 操作有一点类似。
接下来,我们使用 helm install 命令来安装它,同时指定新的 values-prod.yaml 文件作为安装参数。
helm install my-kubernetes-example ./helm -f ./helm/values-prod.yaml --namespace helm-prod --create-namespace
NAME: my-kubernetes-example
LAST DEPLOYED: Sun Jul 16 18:01:28 2023
NAMESPACE: helm-prod
STATUS: deployed
REVISION: 1
TEST SUITE: None
kubectl get hpa backend -n helm-prod --output jsonpath='{.spec.metrics[0].resource.target.averageUtilization}'
50
kubectl get deployment postgres -n helm-prod
Error from server (NotFound): deployments.apps "postgres" not found
查看 backend Deployment 的 Env 环境变量,检查是否使用了外部数据库。
kubectl get deployment backend -n helm-prod --output jsonpath='{.spec.template.spec.containers[0].env[*]}'
{"name":"DATABASE_URI","value":"10.10.10.10"} {"name":"DATABASE_USERNAME","value":"external_postgres"} {"name":"DATABASE_PASSWORD","value":"external_postgres"}
返回结果同样符合预期。
到这里,将实例应用改造成 Helm Chart 的工作已经全部完成了。
打包发布 Helm Chart
创建 GitHub Token
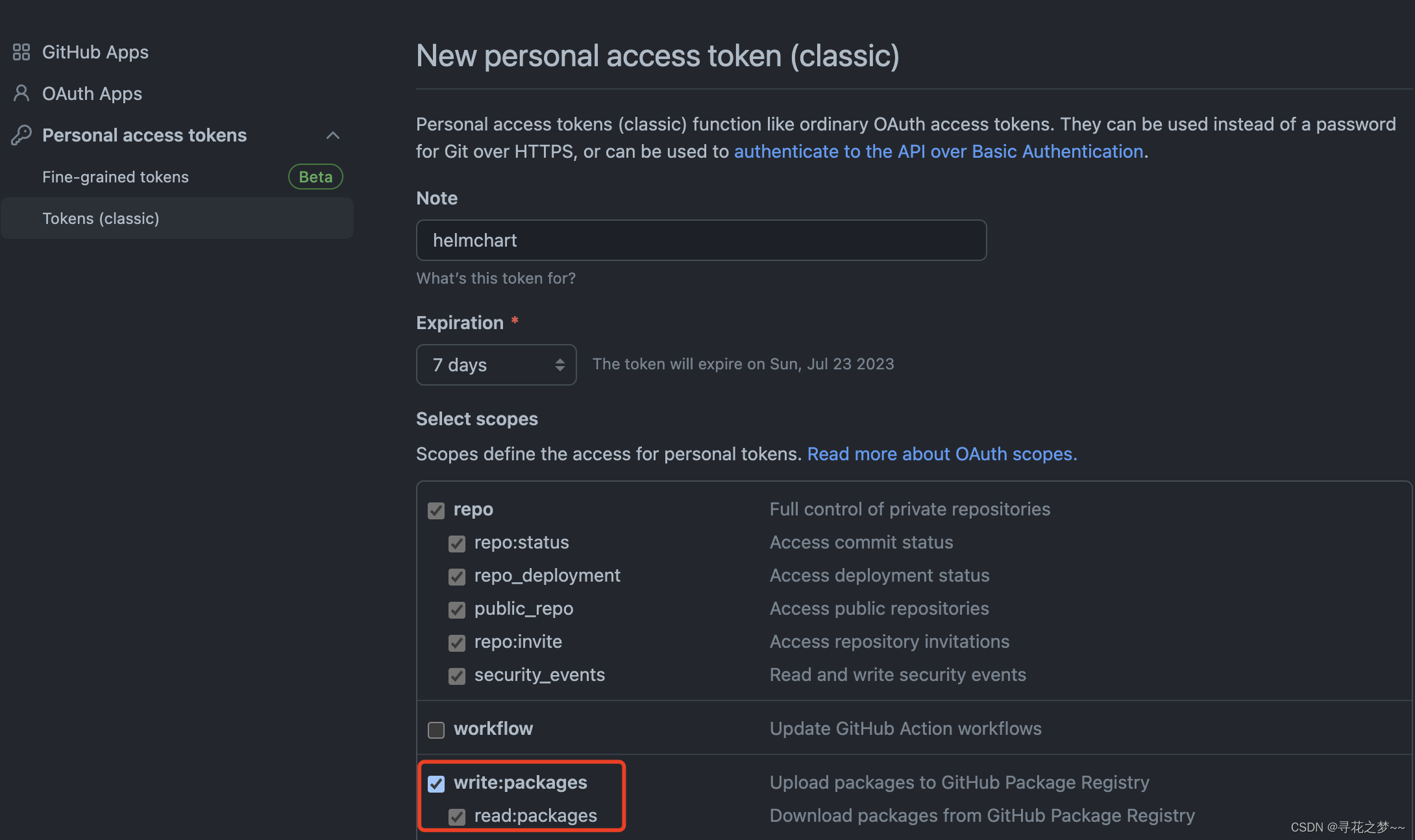
保存好token值。
推送 Helm Chart
在推送之前,还需要使用 GitHub ID 和刚才创建的 Token 登录到 GitHub Package。
helm registry login -u ${github_id} https://ghcr.io
Password:
Login Succeeded
应用的根目录下,执行 helm package 命令来打包 Helm Chart。
helm package ./helm
Successfully packaged chart and saved it to: /srv/k8s_yaml/gitops/kubernetes-example/kubernetes-example-0.1.0.tgz
使用 helm push 命令推送到 GitHub Package
helm push kubernetes-example-0.1.0.tgz oci://ghcr.io/{github_id}/helm
命令运行结束后将展示 Digest 字段,就说明 Helm Chart 推送成功了。
安装远端仓库的 Helm Chart
当我们成功把 Helm Chart 推送到 GitHub Package 之后,就可以直接使用远端仓库来安装 Helm Chart 了。和一般的安装步骤不同的是,由于 GitHub Package 仓库使用的是 OCI 标准的存储方式,所以无需执行 helm repo add 命令添加仓库,可以直接使用 helm install 命令来安装。
$ helm install my-kubernetes-example oci://ghcr.io/xxxxxx/helm/kubernetes-example --version 0.1.0 --namespace remote-helm-staging --create-namespace --set frontend.autoscaling.averageUtilization=60 --set backend.autoscaling.averageUtilization=60
version 字段指定的是 Helm Chart 的版本号。在安装时,同样可以使用 --set 或者指定 -f 参数来覆写 values.yaml 的字段。
Helm 应用管理
调试 Helm Chart
$ helm template ./helm -f ./helm/values-prod.yaml
---
# Source: kubernetes-example/templates/backend.yaml
apiVersion: v1
kind: Service
......
---
# Source: kubernetes-example/templates/frontend.yaml
apiVersion: v1
kind: Service
......
--dry-run参数:
$ helm install my-kubernetes-example oci://ghcr.io/lyzhang1999/helm/kubernetes-example --version 0.1.0 --dry-run
Pulled: ghcr.io/lyzhang1999/helm/kubernetes-example:0.1.0
Digest: sha256:8a0cc4a2ac00f5b1f7a50d6746d54a2ecc96df6fd419a70614fe2b9b975c4f42
NAME: my-kubernetes-example
......
---
# Source: kubernetes-example/templates/database.yaml
......
查看已安装的 Helm Release
~# helm list -A
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
ks-core kubesphere-system 4 2023-07-11 14:48:48.913097166 +0800 CSTdeployed ks-core-0.1.0 v3.1.0
my-kubernetes-example helm-prod 1 2023-07-16 18:01:28.721864874 +0800 CSTdeployed kubernetes-example-0.1.0 0.1.0
my-kubernetes-example helm-staging 1 2023-07-16 17:56:30.840599554 +0800 CSTdeployed kubernetes-example-0.1.0 0.1.0
notification-manager kubesphere-monitoring-system 1 2023-03-07 15:19:35.610346462 +0800 CSTdeployed notification-manager-1.4.0 1.4.0
snapshot-controller kube-system 4 2023-07-11 14:47:38.019617338 +0800 CSTdeployed snapshot-controller-0.2.0 4.0.0
zadig-zadig zadig 2 2023-06-26 17:53:49.340684248 +0800 CSTdeployed zadig-1.17.0 1.17.0
更新 Helm Release
使用 helm upgrade 命令,Helm 会自动对比新老版本之间的 Manifest 差异,并执行升级
$ helm upgrade my-kubernetes-example ./helm -n example
Release "my-kubernetes-example" has been upgraded. Happy Helming!
NAME: my-kubernetes-example
LAST DEPLOYED: Thu Oct 20 16:31:25 2022
NAMESPACE: example
STATUS: deployed
REVISION: 2
TEST SUITE: None
查看 Helm Release 历史版本
$ helm history my-kuebrnetes-example -n example
REVISION UPDATED STATUS CHART APP VERSION DESCRIPTION
1 Thu Oct 20 16:09:22 2022 superseded kubernetes-example-0.1.0 0.1.0 Install complete
2 Thu Oct 20 16:31:25 2022 deployed kubernetes-example-0.1.0 0.1.0 Upgrade complete
回滚 Helm Release
$ helm rollback my-kubernetes-example 1 -n example
Rollback was a success! Happy Helming!
卸载 Helm Release
$ helm uninstall my-kubernetes-example -n example
release "my-kubernetes-example" uninstalled
总结:
Helm Chart 实际上是由特定的文件和目录组成的,一个最简单的 Helm Chart 包含 Chart.yaml、values.yaml 和 templates 目录,当我们把这个特定的目录打包为 tgz 压缩文件时,实际上它也就是标准的 Helm Chart 格式。
相比较 Kustomize 和原生 Manifest,Helm Chart 更多是从“应用”的视角出发的,它为 Kubernetes 应用提供了打包、存储、发行和启动的能力,实际上它就是一个 Kubernetes 的应用包管理工具。此外,Helm 通过模板语言为我们提供了暴露应用关键参数的能力,使用者只需要关注安装参数而不需要去理解内部细节。
而 Kustomize 和 Manifest 则使用原生的 YAML 和 Kubernetes API 进行交互,不具备包管理的概念,所以在这方面它们之间有着本质的区别。
那么, 如果把 Kubernetes 比作是操作系统,Helm Chart 其实就可以类比为 Windows 的应用安装包,它们都是应用的一种安装方式。