文章目录
- 1. 介绍
- 1.1 什么是逻辑回归?
- 1.2 逻辑回归的应用领域
- 2. 逻辑回归的原理
- 2.1 Sigmoid 函数
- 2.2 决策边界
- 2.3 损失函数
- 3. 逻辑回归的实现
- 3.1 数据准备
- 3.2 创建逻辑回归模型
- 3.3 模型训练
- 3.4 模型预测
- 3.5 模型评估
- 4. 可视化决策边界
- 4.1 绘制散点图
- 4.2 绘制决策边界
- 5. 使用不同数据集测试模型
- 5.1 线性可分数据集
- 5.2 线性不可分数据集
- 6. 多分类逻辑回归
- 6.1 One-vs-Rest 方法
- 6.2 Softmax 回归
- 多分类逻辑回归的实现
- 7. 逻辑回归的优缺点
- 7.1 优点
- 7.2 缺点
- 8. 总结
1. 介绍
在当今信息时代,机器学习和人工智能已经渗透到了各行各业,成为推动科技和产业发展的重要驱动力。其中,逻辑回归作为一种简单而有效的分类算法,在数据科学和机器学习领域扮演着重要角色。本篇博客将深入探讨逻辑回归的原理和实现,并通过代码示例展示其在不同数据集上的分类效果。同时,我们还将介绍逻辑回归的优缺点,帮助你更好地理解逻辑回归算法的特点和适用场景。
1.1 什么是逻辑回归?
逻辑回归是一种经典的机器学习算法,尽管名字中包含"回归"二字,但实际上它主要用于解决分类问题。在逻辑回归中,我们试图找到一条决策边界,将数据分为两个类别,通常表示为正类和负类。该算法通过对输入特征进行加权线性组合,然后使用Sigmoid函数将结果映射到[0, 1]的概率区间,从而进行分类。逻辑回归在二分类问题上表现出色,并且其思想和原理在更复杂的分类算法中也有广泛的应用。
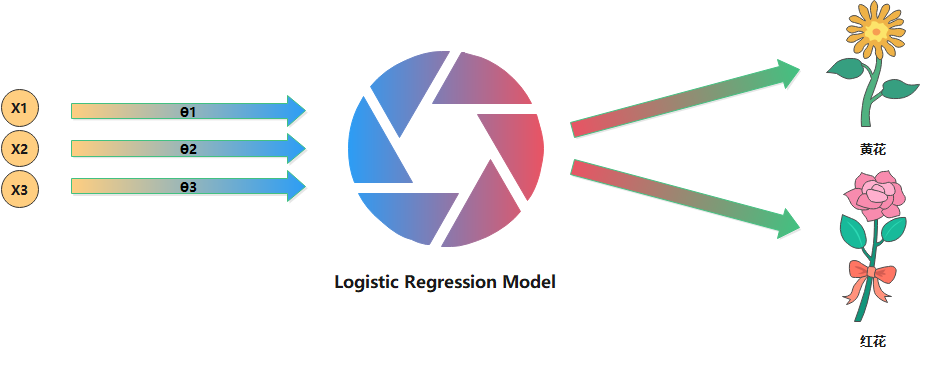
1.2 逻辑回归的应用领域
由于其简单高效的特点,逻辑回归被广泛应用于各个领域,涵盖了众多实际应用场景。以下是逻辑回归在一些领域中的应用示例:
医学领域
- 疾病诊断:例如通过患者的临床指标来预测是否患有某种疾病。
- 药物疗效预测:预测患者对某种药物治疗的响应程度。
自然语言处理
- 文本情感分析:判断一段文本的情感是正面的、负面的还是中性的。
- 垃圾邮件分类:自动将收件箱中的垃圾邮件过滤出来,减少用户的骚扰。
金融领域
- 信用风险评估:评估借款人的信用风险,帮助银行决定是否批准贷款申请。
- 欺诈检测:通过用户的交易数据来识别可能的欺诈行为。
市场营销
- 用户购买行为预测:根据用户的历史购买记录,预测其未来可能感兴趣的产品。
- 客户流失预警:预测哪些客户可能会流失,以便及时采取措施保留客户。
逻辑回归的广泛应用使得它成为机器学习领域入门必学的算法之一,也为从事数据科学和人工智能的研究者和从业者提供了强有力的工具。
在接下来的博客中,我们将逐步深入探讨逻辑回归的原理,并通过实例代码演示如何在Python中实现逻辑回归算法。无论你是初学者还是有一定经验的开发者,相信本篇博客都能为你对逻辑回归的理解和应用提供有价值的帮助。让我们一起开始逐步探索逻辑回归的奥秘吧!
敬请期待后续内容,我们将带您踏上逻辑回归之旅!
2. 逻辑回归的原理
逻辑回归作为一种简单而强大的分类算法,其原理相对直观且易于理解。在本节中,我们将深入探讨逻辑回归的核心组件,包括Sigmoid函数、决策边界和损失函数。
2.1 Sigmoid 函数
逻辑回归的核心是Sigmoid函数(也称为逻辑函数),它是一种常用的激活函数。Sigmoid函数可以将任意实数映射到[0, 1]区间内的概率值。它的数学表达式如下:
σ ( z ) = 1 1 + e − z \sigma(z) = \frac{1}{1 + e^{-z}} σ(z)=1+e−z1

其中, z z z是线性函数的输出结果, e e e是自然常数(约等于2.71828)。Sigmoid函数的图像呈现出一条S形曲线,当 z z z趋近于正无穷时, σ ( z ) \sigma(z) σ(z)趋近于1;当 z z z趋近于负无穷时, σ ( z ) \sigma(z) σ(z)趋近于0。
逻辑回归通过将输入特征进行加权线性组合,并将结果通过Sigmoid函数映射到[0, 1]的概率区间,从而得到样本属于正类的概率。通常,我们可以将模型预测的概率阈值设定为0.5,即概率大于0.5的样本被预测为正类,概率小于等于0.5的样本被预测为负类。
2.2 决策边界
在逻辑回归中,我们希望找到一个决策边界,将不同类别的样本分开。决策边界可以看作是在特征空间中的一个超平面,它将样本划分为两个区域,每个区域对应一个类别。对于二维特征空间,决策边界即为一条直线,而对于更高维度的特征空间,决策边界是一个超平面。
决策边界的位置是由模型的参数决定的,即通过训练数据来学习得到的。训练过程的目标是调整模型的参数权重,使得决策边界能够尽可能准确地将正类和负类样本分开。
2.3 损失函数
在逻辑回归中,我们需要定义一个损失函数来衡量模型预测结果与实际标签之间的差异。常用的损失函数是交叉熵损失函数(Cross-Entropy Loss),它可以用来度量两个概率分布之间的相似性。
对于二分类问题,设样本的实际标签为 y y y,模型预测的概率为 y ^ \hat{y} y^。交叉熵损失函数的数学表达式如下:
Loss = − y ⋅ log ( y ^ ) − ( 1 − y ) ⋅ log ( 1 − y ^ ) \text{Loss} = -y \cdot \log(\hat{y}) - (1 - y) \cdot \log(1 - \hat{y}) Loss=−y⋅log(y^)−(1−y)⋅log(1−y^)
其中, y y y的取值为0或1,当 y = 1 y=1 y=1时,第一项 − y ⋅ log ( y ^ ) -y \cdot \log(\hat{y}) −y⋅log(y^)的值为0,当 y = 0 y=0 y=0时,第二项 − ( 1 − y ) ⋅ log ( 1 − y ^ ) -(1 - y) \cdot \log(1 - \hat{y}) −(1−y)⋅log(1−y^)的值为0。损失函数的目标是最小化样本的预测误差,使得模型能够更准确地预测样本的类别。
在训练过程中,我们使用梯度下降等优化算法来调整模型的参数,使得损失函数最小化。通过迭代优化过程,模型逐渐收敛,得到最佳的参数权重,从而实现对决策边界的学习。
逻辑回归的原理相对简单,但它在实际应用中表现优异。在下一节中,我们将展示如何在Python中实现逻辑回归,并通过实例演示其在不同数据集上的分类效果。
3. 逻辑回归的实现
在本节中,我们将详细介绍逻辑回归的实现步骤,包括数据准备、创建逻辑回归模型、模型训练、模型预测和模型评估。
3.1 数据准备
首先,我们需要准备数据集用于逻辑回归模型的训练和测试。数据集通常包含特征矩阵和对应的类别标签。特征矩阵包含了用于分类的特征,而类别标签则是样本的分类结果。
在这里,我们假设已经有一个数据集,其中包含了样本的特征矩阵X和类别标签y。我们可以使用Numpy等库来加载和处理数据集,确保特征矩阵X的维度为(m, n),其中m是样本数目,n是特征数目,类别标签y的维度为(m, )。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
# 生成线性可分的二维数据集
X, y = make_classification(n_samples=100, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1,
random_state=42)
# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
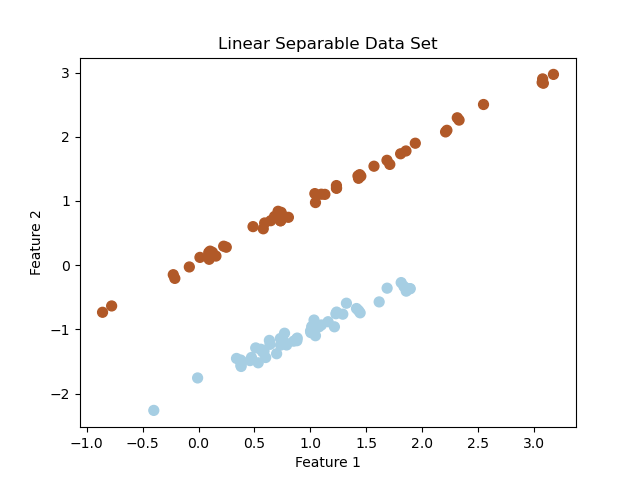
# 绘制散点图表示数据集
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Paired, marker='o', s=50)
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Linear Separable Data Set')
plt.show()
3.2 创建逻辑回归模型
在实现逻辑回归模型之前,我们需要定义一个逻辑回归模型的类。该类将包含逻辑回归算法的实现,并提供以下方法:
_sigmoid(self, z): 计算Sigmoid函数的值,用于将原始得分转换为概率值。_initialize_parameters(self, n_features): 初始化模型的参数,包括权重和偏置。_compute_cost(self, y, y_pred): 计算交叉熵损失函数的值,衡量模型预测值与实际标签之间的差异。fit(self, X, y): 使用训练集进行模型训练,通过梯度下降等优化算法调整模型的参数。predict(self, X): 对新样本进行预测,输出预测的类别标签。accuracy(self, y_true, y_pred): 计算模型在测试集上的准确率,用于评估模型的性能。
class LogisticRegression:
def __init__(self, learning_rate=0.01, num_iterations=1000):
self.learning_rate = learning_rate
self.num_iterations = num_iterations
self.weights = None
self.bias = None
def _sigmoid(self, z):
return 1 / (1 + np.exp(-z))
def _initialize_parameters(self, n_features):
self.weights = np.zeros(n_features)
self.bias = 0
def _compute_cost(self, y, y_pred):
m = len(y)
cost = -(1 / m) * np.sum(y * np.log(y_pred) + (1 - y) * np.log(1 - y_pred))
return cost
def fit(self, X, y):
m, n_features = X.shape
self._initialize_parameters(n_features)
for _ in range(self.num_iterations):
# 计算预测值
z = np.dot(X, self.weights) + self.bias
y_pred = self._sigmoid(z)
# 计算梯度
dw = (1 / m) * np.dot(X.T, (y_pred - y))
db = (1 / m) * np.sum(y_pred - y)
# 更新参数
self.weights -= self.learning_rate * dw
self.bias -= self.learning_rate * db
def predict(self, X):
z = np.dot(X, self.weights) + self.bias
y_pred = self._sigmoid(z)
return np.round(y_pred)
def accuracy(self, y_true, y_pred):
accuracy = np.mean(y_true == y_pred)
return accuracy
3.3 模型训练
在模型训练阶段,我们将使用训练集(X_train, y_train)来训练逻辑回归模型。首先,我们需要初始化模型的参数,然后通过梯度下降等优化算法迭代更新参数,使得损失函数最小化。具体来说,我们将重复以下步骤直到收敛:
- 计算模型在训练集上的预测值y_pred。
- 计算模型预测值与实际标签之间的差异,即损失函数。
- 计算损失函数关于参数的梯度,即权重和偏置的偏导数。
- 更新参数,使得损失函数减小。
# 创建逻辑回归模型并进行训练
model = LogisticRegression(learning_rate=0.01, num_iterations=1000)
model.fit(X_train, y_train)
3.4 模型预测
在模型训练完成后,我们将使用训练好的逻辑回归模型来对新样本进行预测。对于一个新的样本,我们将其特征向量作为输入,通过模型预测得到对应的类别标签。
# 对测试集进行预测
y_pred = model.predict(X_test)
3.5 模型评估
最后,我们将使用测试集(X_test, y_test)来评估模型的性能。常用的评估指标包括准确率、精确率、召回率、F1-score等。我们可以使用predict方法得到模型在测试集上的预测结果,然后与真实的类别标签y_test进行比较,计算评估指标。根据评估结果,我们可以了解模型的分类性能,判断其是否满足要求。
# 计算模型准确率
accuracy = model.accuracy(y_test, y_pred)
print("模型在测试集上的准确率: {:.2f}%".format(accuracy * 100))
4. 可视化决策边界
在本节中,我们将使用逻辑回归算法在二维特征空间上进行分类,并可视化决策边界,以便更直观地了解模型的分类效果。
4.1 绘制散点图
首先,我们需要生成一个二维数据集,其中包含两个类别的样本。我们可以使用make_classification函数来生成一个线性可分的数据集,其中有两个类别的样本。然后,我们将数据集分成训练集和测试集。
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
# 生成线性可分的二维数据集
X, y = make_classification(n_samples=100, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1,
random_state=42)
# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 绘制散点图表示数据集
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Paired, marker='o', s=50)
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Linear Separable Data Set')
plt.show()
运行上述代码后,你将看到一个散点图,其中包含了两个类别的样本点。散点图中的颜色表示样本所属的类别,不同颜色代表不同类别。
4.2 绘制决策边界
接下来,我们将使用逻辑回归模型在特征空间上绘制决策边界。决策边界是一个线性函数,它将特征空间划分为两个区域,分别对应两个类别的样本。
import numpy as np
from LogisticRegression import LogisticRegression # 导入前面实现的逻辑回归类
# 创建逻辑回归模型并进行训练
model = LogisticRegression(learning_rate=0.01, num_iterations=1000)
model.fit(X_train, y_train)
# 绘制决策边界
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1), np.arange(y_min, y_max, 0.1))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.8, cmap=plt.cm.Paired)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Paired, marker='o', s=50)
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Decision Boundary of Logistic Regression')
plt.show()
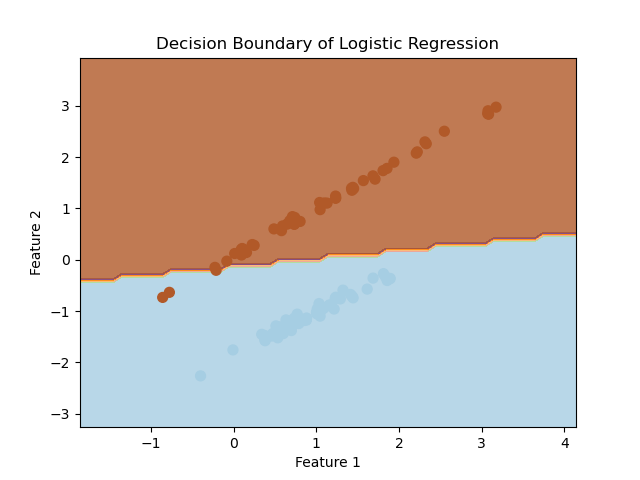
在上述代码中,我们首先创建了一个逻辑回归模型,并使用训练集对其进行训练。然后,我们在特征空间上创建网格点,并利用训练好的模型对每个网格点进行预测,得到预测结果Z。最后,我们使用plt.contourf函数绘制决策边界,并用散点图表示数据集中的样本点。
运行上述代码后,你将看到一个带有决策边界的图像。决策边界将特征空间划分为两个区域,分别对应两个类别的样本。在这个例子中,由于数据集是线性可分的,逻辑回归模型可以得到较好的分类效果。
请注意,对于非线性可分的数据集,逻辑回归的分类效果可能不如在线性可分数据集上的表现。在下一节中,我们将使用不同数据集来测试逻辑回归的分类性能,并讨论其在不同数据情况下的表现。
5. 使用不同数据集测试模型
在本节中,我们将使用两种不同类型的数据集来测试逻辑回归模型的分类性能。分别是线性可分数据集和线性不可分数据集。
5.1 线性可分数据集
线性可分数据集是指可以用一条直线将不同类别的样本完全分开的数据集。在这种情况下,逻辑回归表现良好,并且可以准确地找到一个决策边界,将正类和负类样本分开。
我们已经在上一节中演示了使用线性可分数据集的情况。接下来,我们将使用不同的线性可分数据集来进一步测试逻辑回归模型,并评估其分类效果。
# 生成新的线性可分数据集
X_linear_separable, y_linear_separable = make_classification(n_samples=100, n_features=2, n_informative=2,
n_redundant=0, n_clusters_per_class=1, random_state=10)
# 划分数据集为训练集和测试集
X_train_linear_separable, X_test_linear_separable, y_train_linear_separable, y_test_linear_separable = \
train_test_split(X_linear_separable, y_linear_separable, test_size=0.2, random_state=42)
# 创建逻辑回归模型并进行训练
model_linear_separable = LogisticRegression(learning_rate=0.01, num_iterations=1000)
model_linear_separable.fit(X_train_linear_separable, y_train_linear_separable)
# 在测试集上进行预测
y_pred_linear_separable = model_linear_separable.predict(X_test_linear_separable)
# 计算模型的准确率
accuracy_linear_separable = model_linear_separable.accuracy(y_test_linear_separable, y_pred_linear_separable)
print(f"在线性可分数据集上的准确率:{accuracy_linear_separable}")
5.2 线性不可分数据集
线性不可分数据集是指无法用一条直线将不同类别的样本完全分开的数据集。在这种情况下,逻辑回归可能无法找到一个理想的决策边界,导致分类效果较差。
我们将使用一个线性不可分数据集来测试逻辑回归模型,并观察其分类效果。
# 生成线性不可分数据集
X_non_linear_separable, y_non_linear_separable = make_classification(n_samples=100, n_features=2, n_informative=2,
n_redundant=0, n_clusters_per_class=1,
flip_y=0.3, random_state=20)
# 划分数据集为训练集和测试集
X_train_non_linear_separable, X_test_non_linear_separable, y_train_non_linear_separable, y_test_non_linear_separable = \
train_test_split(X_non_linear_separable, y_non_linear_separable, test_size=0.2, random_state=42)
# 创建逻辑回归模型并进行训练
model_non_linear_separable = LogisticRegression(learning_rate=0.01, num_iterations=1000)
model_non_linear_separable.fit(X_train_non_linear_separable, y_train_non_linear_separable)
# 在测试集上进行预测
y_pred_non_linear_separable = model_non_linear_separable.predict(X_test_non_linear_separable)
# 计算模型的准确率
accuracy_non_linear_separable = model_non_linear_separable.accuracy(y_test_non_linear_separable,
y_pred_non_linear_separable)
print(f"在线性不可分数据集上的准确率:{accuracy_non_linear_separable}")
在上述代码中,我们分别使用了线性可分数据集和线性不可分数据集来测试逻辑回归模型。通过比较模型在两种不同数据集上的准确率,我们可以观察到逻辑回归在线性可分数据集上表现良好,而在线性不可分数据集上可能会出现分类效果较差的情况。
请注意,对于线性不可分数据集,我们可以使用更复杂的分类算法如支持向量机(SVM)或神经网络来获得更好的分类结果。这表明逻辑回归虽然简单有效,但在处理复杂问题时可能需要考虑其他更适合的算法。
综上所述,逻辑回归是一种强大的分类算法,在处理线性可分问题时具有良好的性能。然而,对于线性不可分问题,逻辑回归的分类效果可能有限,需要根据具体情况考虑其他算法的应用。在实际应用中,根据数据集的特点和问题的要求,选择合适的分类算法是至关重要的。
6. 多分类逻辑回归
在前面的内容中,我们已经介绍了逻辑回归在二分类问题上的应用。然而,在实际应用中,我们常常会遇到多分类问题,即将样本分为多个类别。逻辑回归可以通过扩展到多分类情况来解决这类问题。本节中,我们将介绍两种常用的多分类逻辑回归方法:One-vs-Rest方法和Softmax回归。
6.1 One-vs-Rest 方法
One-vs-Rest(OvR)方法也称为One-vs-All(OvA)方法。在OvR方法中,对于多分类问题中的每个类别,我们都训练一个二分类逻辑回归模型。具体来说,对于第i个类别,我们将其作为正类,将其他所有类别作为负类,然后训练一个二分类逻辑回归模型。这样,我们就得到了多个二分类逻辑回归模型。
在预测时,我们对新样本使用每个模型进行分类,最后将概率最高的类别作为最终的分类结果。
One-vs-Rest方法简单且易于实现,适用于各种类型的多分类问题。然而,在某些情况下,当类别数目很大时,可能会导致训练多个模型的计算开销较大。
6.2 Softmax 回归
Softmax回归也称为多项逻辑回归,是一种更为直接的多分类逻辑回归方法。在Softmax回归中,我们直接将多个类别的预测概率进行归一化处理,得到每个类别的概率分布。
假设有K个类别,对于第i个样本,模型对其属于第k个类别的概率可以表示为:
P ( y i = k ) = e z i k ∑ j = 1 K e z i j P(y_i=k) = \frac{e^{z_{ik}}}{\sum_{j=1}^{K} e^{z_{ij}}} P(yi=k)=∑j=1Kezijezik
其中, z i k z_{ik} zik表示模型对样本i属于第k个类别的原始得分。Softmax回归的目标是最大化训练数据上的似然函数,通过调整模型的参数使得模型的预测概率与实际标签之间的差异最小化。
在预测时,我们选择概率最高的类别作为最终的分类结果。
Softmax回归在处理多分类问题时更加直接,且通常表现较好。它将多个类别的概率考虑在内,更全面地描述了样本的分类情况。
在实际应用中,我们可以根据问题的特点和数据集的规模选择合适的多分类逻辑回归方法。如果类别数目较大,计算开销较大时,可以考虑使用One-vs-Rest方法。如果希望直接得到类别的概率分布,或者类别数目较少,可以选择Softmax回归。
下面我们将通过Python代码演示多分类逻辑回归的实现,包括One-vs-Rest方法和Softmax回归。请注意,在实际应用中,我们可以使用现有的机器学习库(如scikit-learn)来更方便地实现这些方法。
多分类逻辑回归的实现
在Python中,我们可以使用scikit-learn库来实现多分类逻辑回归。scikit-learn提供了LogisticRegression类,可以轻松地处理多分类问题。
首先,我们需要准备多分类的数据集,然后分别使用One-vs-Rest方法和Softmax回归来训练模型,并进行预测。
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 生成多分类数据集
X_multi_class, y_multi_class = make_classification(n_samples=500, n_features=2, n_informative=2,
n_redundant=0, n_clusters_per_class=1, n_classes=3, random_state=42)
# 划分数据集为训练集和测试集
X_train_multi, X_test_multi, y_train_multi, y_test_multi = train_test_split(X_multi_class, y_multi_class,
test_size=0.2, random_state=42)
# 使用One-vs-Rest方法训练模型
model_ovr = LogisticRegression(multi_class='ovr', max_iter=1000)
model_ovr.fit(X_train_multi, y_train_multi)
# 使用Softmax回归训练模型
model_softmax = LogisticRegression(multi_class='multinomial', solver='lbfgs', max_iter=1000)
model_softmax.fit(X_train_multi, y_train_multi)
# 在测试集上进行预测
y_pred_ovr = model_ovr.predict(X_test_multi)
y_pred_softmax = model_softmax.predict(X_test_multi)
# 计算模型的准确率
accuracy_ovr = accuracy_score(y_test_multi, y_pred_ovr)
accuracy_softmax = accuracy_score(y_test_multi, y_pred_softmax)
print(f"One-vs-Rest方法在多分类数据集上的准确率:{accuracy_ovr}")
print(f"Softmax回归在多分类数据集上的准确率:{accuracy_softmax}")
在上述代码中,我们生成了一个包含3个类别的多分类数据集。然后,我们使用LogisticRegression类分别采用One-vs-Rest方法(设置multi_class='ovr')和Softmax回归(设置multi_class='multinomial')进行训练。最后,我们计算模型在测试集上的准确率,并输出结果。
通过上述代码,我们可以观察到两种多分类逻辑回归方法在不同数据集上的分类效果。请注意,scikit-learn库提供了许多其他参数可以进一步优化模
型的性能,例如正则化参数等。在实际应用中,我们可以根据具体情况进行调参和优化。
7. 逻辑回归的优缺点
逻辑回归是一种简单而有效的分类算法,在许多实际应用中得到广泛使用。然而,它也有其自身的优点和缺点。在本节中,我们将探讨逻辑回归的优点和缺点。
7.1 优点
- 简单高效:逻辑回归是一种线性分类算法,其原理简单且易于理解。训练过程高效,适用于大规模数据集。
- 适用性广泛:逻辑回归适用于各种类型的问题,包括二分类和多分类任务。
- 可解释性强:逻辑回归模型的参数权重可以解释特征对于分类的影响程度,因此可以帮助理解分类结果的原因。
- 适用于在线学习:逻辑回归支持在线学习,即可以在新数据到达时动态更新模型。
7.2 缺点
- 线性限制:逻辑回归是一种线性分类算法,对于非线性问题的分类效果可能较差。当数据集不是线性可分时,逻辑回归可能无法得到理想的分类结果。
- 容易欠拟合:逻辑回归对于复杂的数据分布可能容易欠拟合,导致分类效果不佳。在处理复杂问题时,可能需要考虑使用更复杂的分类算法。
- 对异常值敏感:逻辑回归对异常值比较敏感,如果数据集中存在大量的异常值,可能会影响模型的性能。
- 依赖特征工程:逻辑回归对特征工程的依赖较大,模型的性能受到特征选择和特征处理的影响。
综上所述,逻辑回归作为一种简单而强大的分类算法,具有许多优点,包括简单高效、适用性广泛和可解释性强。然而,它也有其局限性,特别是在处理非线性问题和复杂数据分布时,可能需要考虑其他更适合的分类算法。在实际应用中,我们应该根据具体问题的特点和数据集的特征选择合适的分类算法,并结合特征工程来提升模型的性能。
8. 总结
本篇博客深入介绍了逻辑回归算法的原理、实现和应用,并对其优缺点进行了分析。逻辑回归是一种简单而有效的分类算法,适用于各种类型的问题,包括二分类和多分类任务。
在博客中,我们首先对逻辑回归的原理进行了详细阐述。我们介绍了Sigmoid函数作为逻辑回归的核心组成部分,以及如何使用决策边界将样本分为两个类别。同时,我们还讨论了逻辑回归的损失函数,即交叉熵损失函数,用于衡量模型预测值与实际标签之间的差异。
接着,我们详细介绍了逻辑回归的实现步骤。从数据准备到模型训练和预测,我们逐步展示了如何使用Python代码实现逻辑回归算法。我们还介绍了逻辑回归的优点和缺点,帮助读者了解其适用范围和局限性。
为了更直观地了解逻辑回归的分类效果,我们还可视化了决策边界。通过绘制散点图和决策边界,我们可以更好地理解逻辑回归在不同数据集上的分类表现。
最后,我们还简要介绍了多分类逻辑回归,包括One-vs-Rest方法和Softmax回归。这些方法扩展了逻辑回归算法的应用范围,可以处理多个类别的分类问题。
总体而言,逻辑回归是一种简单而强大的分类算法,适用于各种实际应用。然而,在处理非线性问题和复杂数据分布时,可能需要考虑其他更适合的分类算法。在实际应用中,我们应根据具体问题的特点选择合适的算法,并结合特征工程和模型调优来提升模型性能。
希望本篇博客对读者理解逻辑回归算法有所帮助,同时也能对机器学习和分类问题有更深入的认识。谢谢阅读!