编者按:大型语言模型(Large language models, LLMs)因其在学术界和工业界展现出前所未有的性能而备受青睐。随着 LLMs 在研究和实际应用中被广泛使用,对其进行有效评测变得愈发重要。近期已有多篇论文围绕大模型的评测进行研究,但尚未有文章对评测的方法、数据、挑战等进行完整的梳理。日前,微软亚洲研究院的研究员们参与完成了介绍大模型评测领域的第一篇综述文章《A Survey on Evaluation of Large Language Models》。该论文一共调研了219篇文献,以评测对象 (what to evaluate)、评测领域 (where to evaluate)、评测方法 (How to evaluate)和目前的评测挑战等几大方面对大模型的评测进行了详细的梳理和总结。研究员们也将持续维护大模型评测的开源项目以促进此领域的发展。
为什么要研究大模型评测?
通俗来讲,大模型是一个能力很强的函数 f,与之前的机器学习模型并无本质不同。那么,为什么要研究大模型的评测?大模型评测跟以前的机器学习模型评测有何不同?
首先,研究评测可以帮助我们更好地理解大模型的长处和短处。尽管多数研究表明大模型在诸多通用任务上已达到类人或超过人的水平,但仍然有很多研究在质疑其能力来源是否为对训练数据集的记忆。如,人们发现,当只给大模型输入 LeetCode 题目编号而不给任何信息的时候,大模型居然也能够正确输出答案,这显然是训练数据被污染了。
其次,研究评测可以更好地为人与大模型的协同交互提供指导和帮助。大模型的服务对象终究是人,那么为了更好地进行人机交互新范式的设计,我们便有必要对其各方面能力进行全面了解和评测。如,我们最近的研究工作 PromptBench:首个大语言模型提示鲁棒性的评测基准,便详细地评测了大模型在“指令理解”方面的鲁棒性,结论是其普遍容易受到干扰、不够稳定,这便启发了我们从 prompt 层面来加强系统的容错能力。
最后,研究评测可以更好地统筹和规划大模型未来的发展的演变、防范未知和可能的风险。大模型一直在不断进化,其能力也越来越强。那么,通过合理、科学的评测机制的设计,我们能否用演化的角度来评测其能力?如何提前预知其可能的风险?这都是重要的研究内容。
因此,研究大模型的评测具有十分重要的意义。
综述主要内容
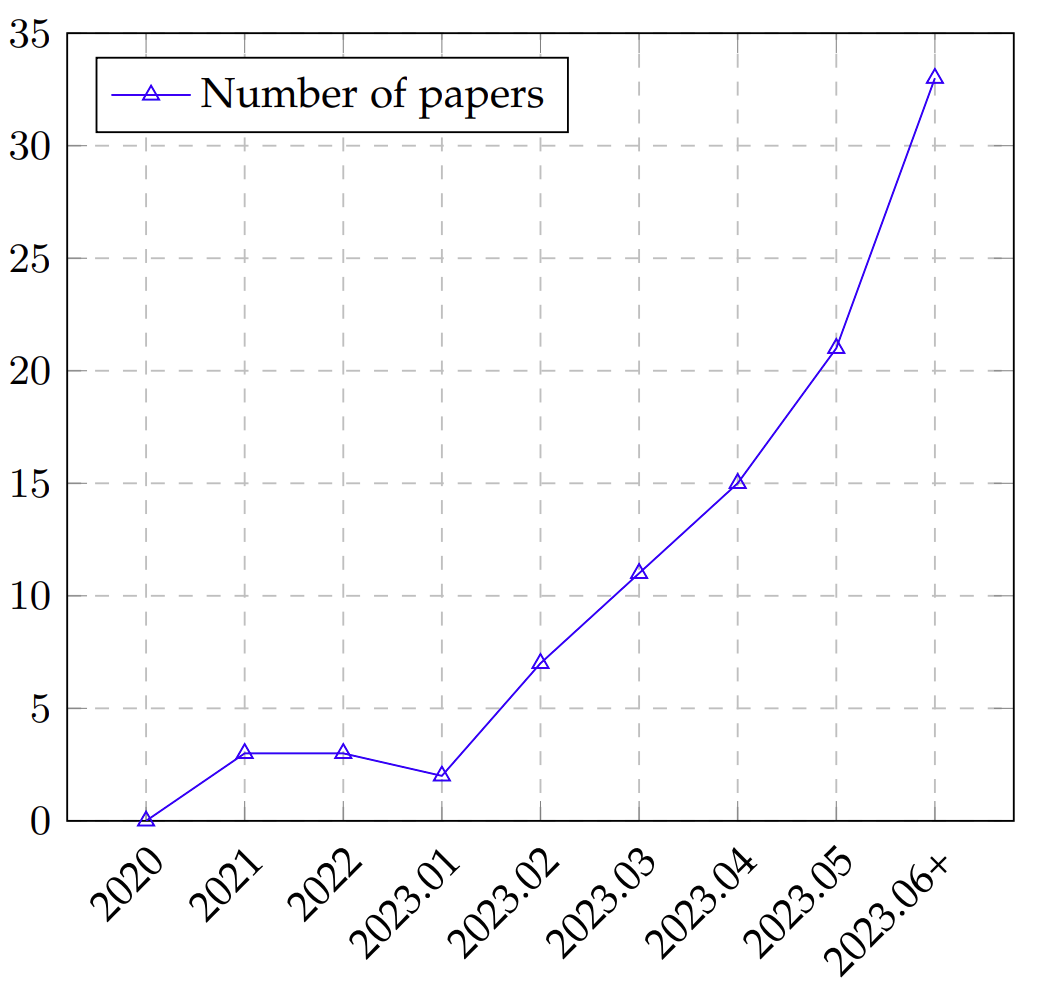
自 ChatGPT 去2022年10月问世以来,关于大模型的研究变得炙手可热起来。我们希望探讨大模型研究的一个重要方向:模型评测。根据不完全统计(见下图),大模型的评测方面发表的文章呈上升趋势,越来越多的研究着眼于设计更科学、更好度量、更准确的评测方式来对大模型的能力进行更深入的了解。
为此,我们于近期完成了介绍大模型评测领域的第一篇综述文章《A Survey on Evaluation of Large Language Models》。该论文一共调研了219篇文献,以评测对象 (what to evaluate)、评测领域 (where to evaluate)、评测方法 (How to evaluate)和目前的评测挑战等几大方面对大模型的评测进行了详细的梳理和总结。其研究目标是增强对大模型当前状态的理解,阐明它们的优势和局限性,并为其未来发展提供见解。同时,我们也将该项工作进行了开源,希望有更多同行参与,共同促进该领域的发展。

论文链接:https://arxiv.2307.03109
开源链接:https://github.com/MLGroupJLU/LLM-eval-survey
大模型评测相关研究:https://llm-eval.github.io/
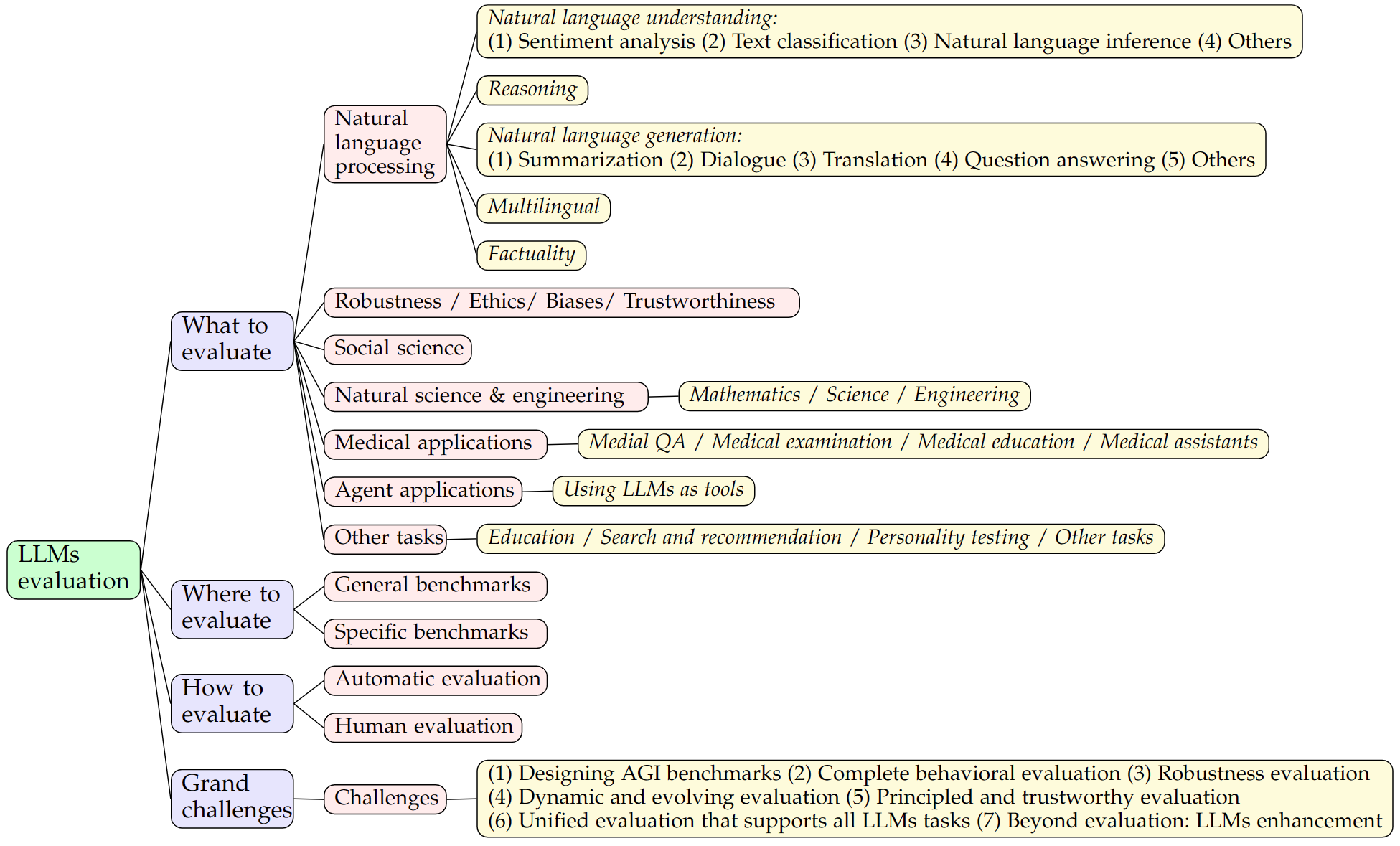
作为大型语言模型(Large language models, LLMs)评测的首次全面综述,本文主要从三个方面对现有工作进行了探索:

• 评测内容 (What to evaluate),对海量的 LLMs 评测任务进行分类并总结评测结果;
• 评测领域 (Where to evaluate),对 LLMs 评测常用的数据集和基准进行了总结;
• 评测方法 (How to evaluate),总结了目前流行的两种 LLMs 评测方法。
研究框架
此外,研究还对大模型评测不可或缺的三个维度内容进行了综合总结。最后,研究讨论了大模型评测时可能面临的重大挑战,为今后的研究提供了建议。
评测什么
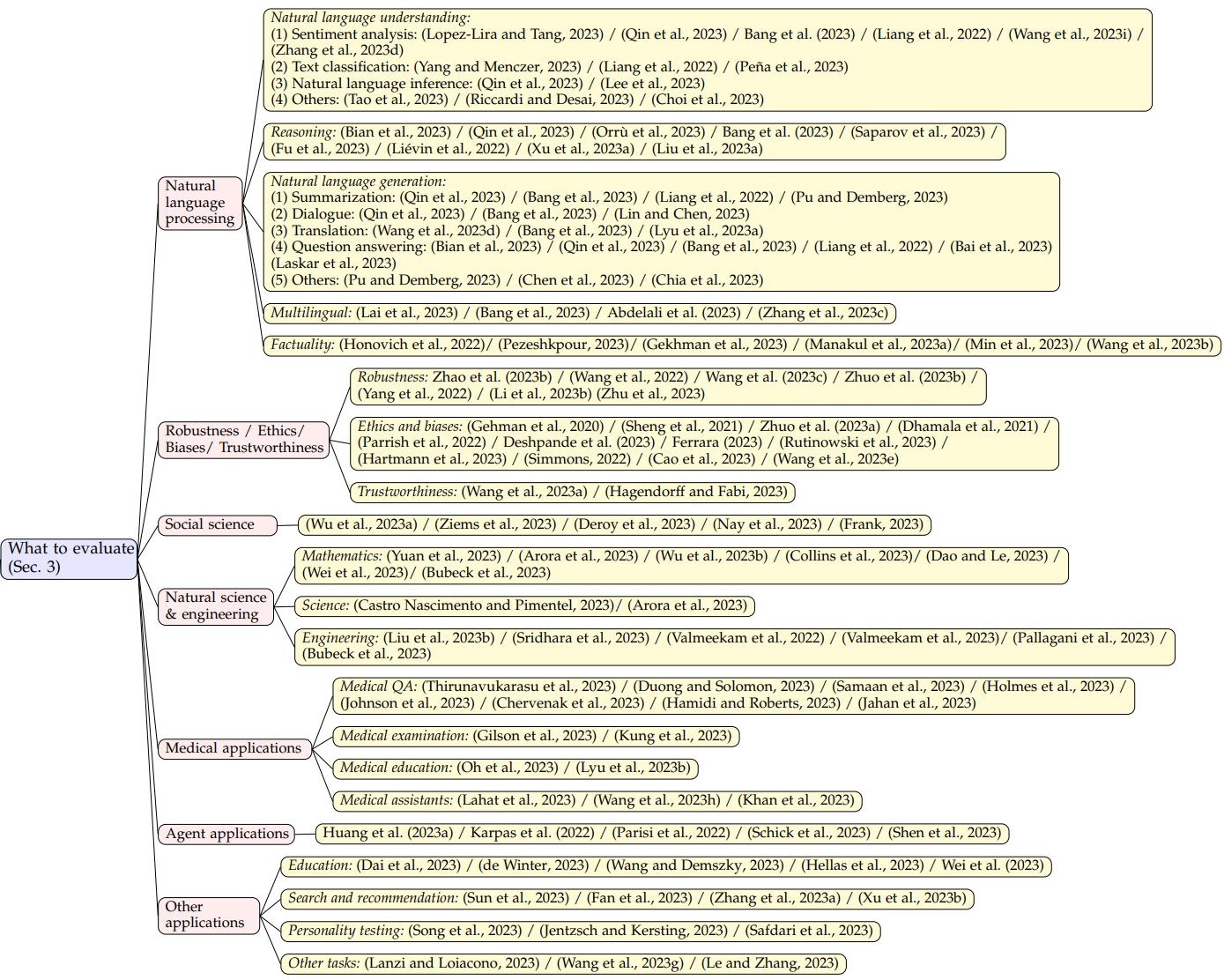
本文的主要目的是总结和讨论目前在大型语言模型上的评测工作。在评测 LLMs 的性能时,选择合适的任务和领域对于展示大型语言模型的表现、优势和劣势至关重要。为了更清晰地展示 LLMs 的能力水平,文章将现有的任务划分为以下7个不同的类别:
1. 自然语言处理:包括自然语言理解、推理、自然语言生成和多语言任务
2. 鲁棒性、伦理、偏见和真实性
3. 医学应用:包括医学问答、医学考试、医学教育和医学助手
4. 社会科学
5. 自然科学与工程:包括数学、通用科学和工程
6. 代理应用:将 LLMs 作为代理使用
7. 其他应用
这样的分类方式能够更好地展示 LLMs 在各领域的表现。需要注意的是,几个自然语言处理领域有交叉点,因此这种领域的分类只是一种可能的分类方式。
评测内容
在哪评测
我们通过深入探讨评测基准来回答在哪里评测的问题,如下图所示,评测基准主要分为通用基准(General benchmarks)和具体基准(Specific benchmarks)。

评测领域
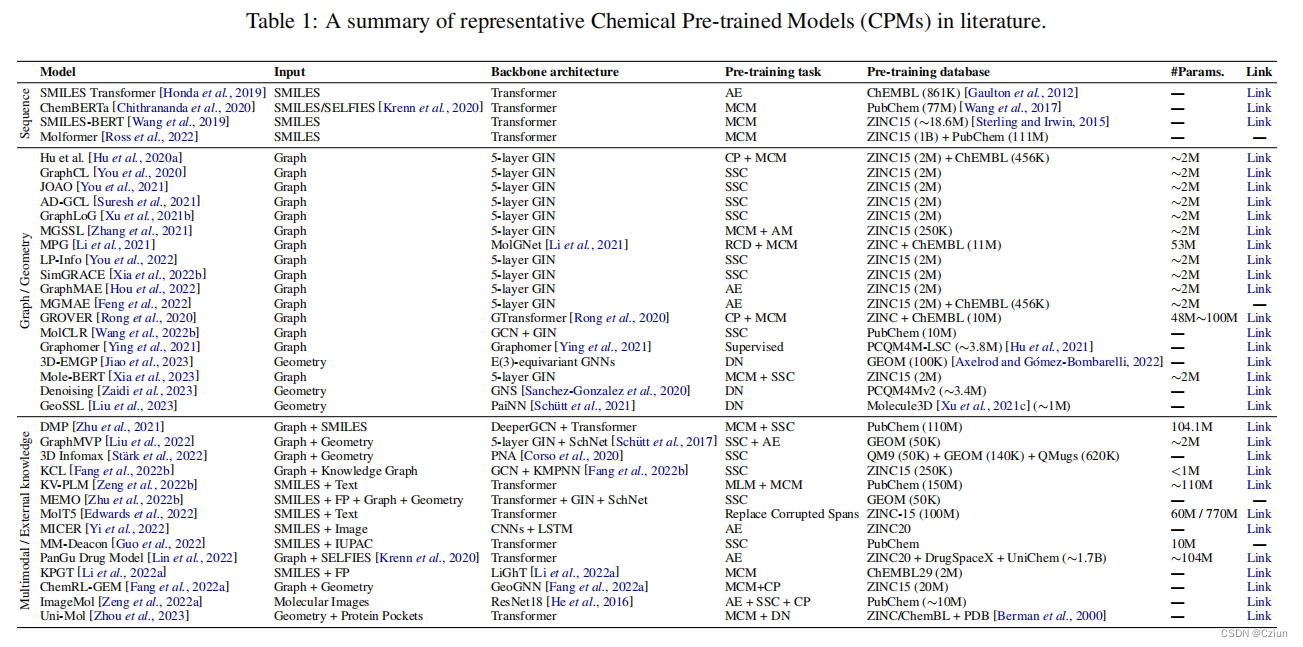
随着 LLMs 基准测试的不断发展,目前已有许多受欢迎的评测基准。下表综述总结了19个流行的基准测试,每个基准关注不同的方面和评测标准,为各自的领域做出了贡献。
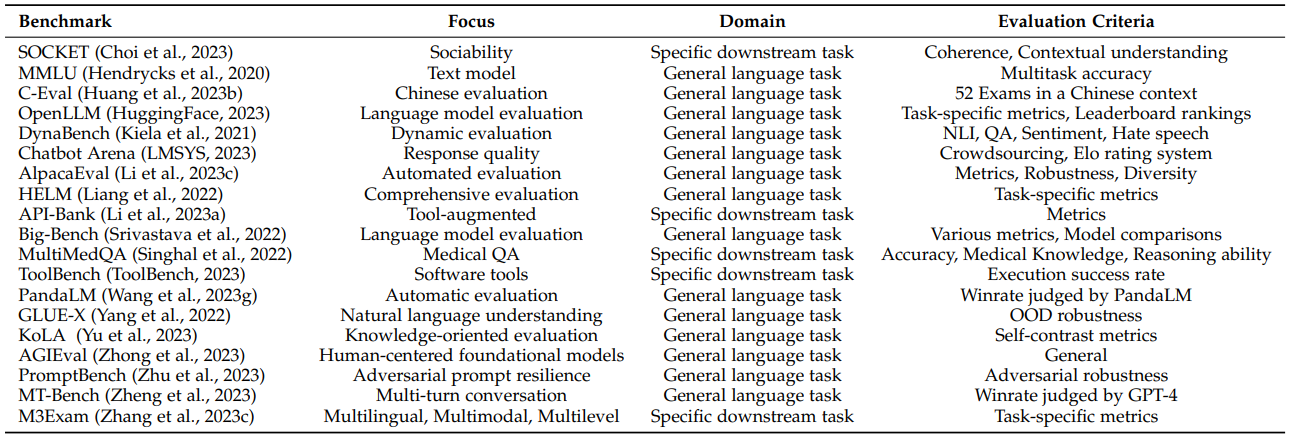
评测基准
如何评测
在本节中,文章介绍了两种常用的评测方法:自动评测和人工评测。这两种方法在评测语言模型和机器翻译等任务时起着重要的作用。自动评测方法基于计算机算法和自动生成的指标,能够快速且高效地评测模型的性能。而人工评测则侧重于人类专家的主观判断和质量评测,能够提供更深入、细致的分析和意见。了解和掌握这两种评测方法对准确评测和改进语言模型的能力十分重要。
综述总结
在这一部分,文章总结了 LLMs 在不同任务中的成功和失败案例。
LLMs 能够在哪些方面表现出色?1. LLMs 在生成文本方面展现出熟练度,能够产生流畅且准确的语言表达。2. LLMs 在语言理解方面表现出色,能够进行情感分析和文本分类等任务。3. LLMs 具备强大的语境理解能力,能够生成与输入一致的连贯回答。4. LLMs 在多个自然语言处理任务中表现出令人称赞的性能,包括机器翻译、文本生成和问答任务。
LLMs 在什么情况下可能会失败?1. LLMs 在生成过程中可能会表现出偏差和不准确性,导致产生有偏差的输出。2. LLMs 在理解复杂的逻辑和推理任务方面能力有限,在复杂的环境中经常出现混乱或错误。3. LLMs 在处理大量数据集和长期记忆方面面临限制,这可能会在处理冗长的文本和涉及长期依赖的任务方面带来挑战。4. LLMs 在整合实时或动态信息方面存在局限性,使得它们不太适合需要最新知识或快速适应变化环境的任务。5. LLMs 对提示非常敏感,尤其是敌对提示 ,这些提示会触发新的评测和算法,提高其鲁棒性。6. 在文本摘要领域,可以观察到 LLMs 可能在特定的评测指标上表现出低于标准的性能,这可能归因于那些特定指标的内在限制或不足。7. LLMs 在反事实任务中 的表现不令人满意。

重大挑战
评测作为一门新学科:我们对大模型评测的总结启发我们重新设计了许多方面。在本节中,我们介绍了以下7个重大挑战。
1. 设计 AGI 基准测试。什么是可靠、可信任、可计算的能正确衡量 AGI 任务的评测指标?
2. 设计 AGI 基准完成行为评测。除去标准任务之外,如何衡量 AGI 在其他任务,如机器人交互中的表现?
3. 稳健性评测。目前的大模型对输入的 prompt 非常不鲁棒,如何构建更好的鲁棒性评测准则?
4. 动态演化评测。大模型的能力在不断进化、也存在记忆训练数据的问题。如何设计更动态更进化式的评测方法?
5. 可信赖的评测。如何保证所设计的评测准则是可信任的?
6. 支持所有大模型任务的统一评测。大模型的评测并不是终点、如何将评测方案与大模型有关的下游任务进行融合?
7. 超越单纯的评测:大模型的增强。评测出大模型的优缺点之后,如何开发新的算法来增强其在某方面的表现?
研究的重点是,评测应该被视为推动 LLMs 和其他人工智能模型成功的基本学科。现有的研究方案不足以对 LLMs 进行全面的评测,这可能为未来的 LLMs 评测研究带来新的机遇。
结论
评测具有深远的意义,在人工智能模型的发展中变得势在必行,在 LLMs 不断发展的背景下尤其如此。本文首次从评测什么、如何评测、在哪里评测三个方面对 LLMs 的评测进行了全面的概述。通过封装评测任务、协议和基准,研究的目标是增强对 LLMs 当前状态的理解,阐明它们的优势和局限性,并为未来 LLMs 的发展提供见解。
研究的调查显示,目前的 LLMs 在许多任务中都存在一定的局限性,尤其是推理和鲁棒性任务。与此同时,对当代评测系统进行调整和发展的需求依然明显,以确保对 LLMs 的内在能力和局限性进行准确评测。最后,本文确定了未来研究应该解决的几个重大挑战,并希望 LLMs 能够逐步提高大语言模型为人类服务的水准。
我们还在以下网站中汇总了本团队所有的大模型评测相关研究,欢迎关注:
https://llm-eval.github.io/
https://github.com/microsoft/promptbench



![[23] TriPlaneNet: An Encoder for EG3D Inversion](https://img-blog.csdnimg.cn/f0f3b565861042ae95284c2974cfe7b7.png)