目录
- 摘要
- 1 引言
- 2 分子描述符和编码器 (Molecular Descriptors and Encoders)
- 3 预训练策略 (Pre-training Strategies)
- 3.1 自动编码 (AutoEncoding, AE)
- 3.2 自回归建模 (Autoregressive Modeling, AM)
- 3.3 掩蔽组件建模 (Masked Component Modeling, MCM)
- 3.4 上下文预测 (Context Prediction, CP)
- 3.5 对比学习 (Contrastive Learning, CL)
- 3.6 替换组件检测 (Replaced Components Detection, RCD)
- 3.7 去噪 (DeNoising, DN)
- 3.8 Extensions
- 4 Applications
- 4.1 分子性质预测(MPP)
- 4.2 分子生成(MG)
- 4.3 药物-靶点相互作用(DTI)
- 4.4 药物-药物相互作用(DDI)
- 5 结论和未来展望
- 5.1 改进编码器结构和预训练目标
- 5.2 建立可靠和现实的基准测试
- 5.3 扩大化学预训练模型的影响
- 5.4 建立理论基础
摘要
从零开始训练深度神经网络(DNNs)通常需要大量的标记分子。
解决 → → → 分子预训练模型(Chemical Pre-trained Models, CPMs),即DNN使用大规模的未标记分子数据库进行预先训练,然后对特定的下游任务进行微调。
首先,强调了从头开始训练分子表示模型来激励CPM研究的局限性。
接下来,从几个关键的角度系统地回顾了这一主题的最新进展,包括分子描述符、编码器架构、预训练策略和应用。
最后,强调了未来研究面临的挑战和有希望的途径,为机器学习和科学界提供了有用的资源。
1 引言

2 分子描述符和编码器 (Molecular Descriptors and Encoders)
为了将分子输入给GNNs,分子必须用数值描述符。本节简要回顾分子描述符及其相应的神经编码器结构。
Fingerprints (FP): 分子指纹利用二元字符串描述了一个分子的特定子结构的存在和缺失。例如,PubChemFP。
Sequences: 分子最常用的序列描述符是简化分子线性输入规范(Simplified Molecular-Input Line-Entry System, SMILES),因为它的多功能性和可解释性。每个原子都被表示为一个各自的ASCII符号。化学键、分支键和立体化学键都用特定的符号表示。
2D graphs: 原子作为节点,化学键作为边。每个节点和边也可以携带表示原子类型/手性和键类型/方向的特征向量。例如,GNNs,GNNs + transformers。
3D graphs: 每个原子都与它的类型和坐标加上一些可选的几何属性,如速度有关。
3 预训练策略 (Pre-training Strategies)
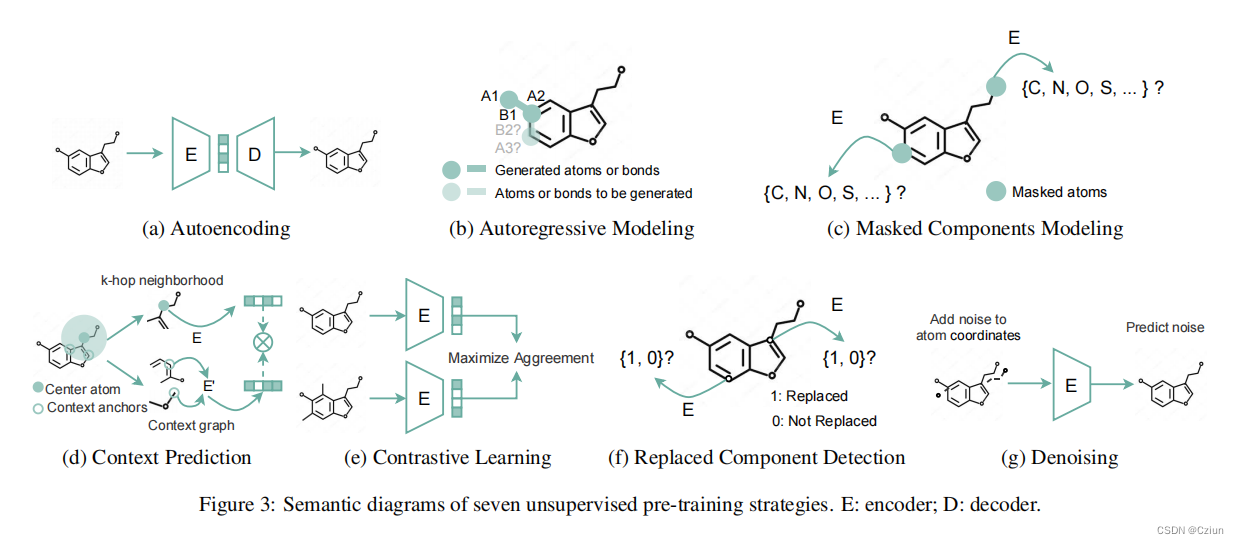
3.1 自动编码 (AutoEncoding, AE)
用自动编码器重建分子(图3a)可以作为学习表达性分子表征的自监督目标。在分子重建中的预测是给定分子的(部分)结构,如原子的一个子集或化学键的属性。一个典型的例子是SMILES transformer,它利用基于transformer的编码-解码器网络,通过重建由SMILES表示的分子来学习表示。最近,与传统的输入和输出数据类型相同的自动编码器不同,*[Lin et al., 2022]*预训练一个图到序列的非对称条件变分自编码器来学习分子表示。虽然自动编码器可以学习分子的有意义的表示,但它们专注于单个分子,而不能捕获分子间的关系,这限制了它们在某些下游任务中的表现。
3.2 自回归建模 (Autoregressive Modeling, AM)
AM将分子输入分解为一系列子成分序列,然后以序列中先前的子成分为条件,逐个预测子成分。根据NLP中GPT的想法,MolGPT 预训练了一个transformer网络,以这种自回归的方式预测SMILES串中的下一个token。对于分子图,GPT-GNN以一系列步骤重建分子图(图3b),而图自动编码器一次重建整个图。特别地,给定一个其节点和边被随机掩码的图,GPT-GNN每次生成一个掩码节点及其边,并使每次迭代中生成的节点和边的可能性最大化。然后,迭代生成节点和边,直到生成所有掩码节点。类似地,MGSSL自回归地生成分子图图案,而不是单个原子或键。在形式上,这种自回归建模目标可以写为
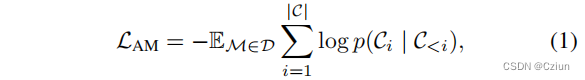
与其他策略相比,AM使CPM在生成分子方面表现得更好——其训练过程类似于分子生成。然而,AM在计算上更昂贵,并且需要预先设定原子或键的顺序,这可能不合适,因为原子或键不呈现固有的顺序。
3.3 掩蔽组件建模 (Masked Component Modeling, MCM)
在语言领域,掩蔽语言建模(Masked Language Modeling, MLM)已经成为一个主要的预训练目标。具体来说,MLM从输入的句子中随机掩码出tokens,其中模型可以被训练来使用剩余的tokens来预测这些掩码tokens。MCM掩蔽分子的一些成分(例如,原子、键和碎片),然后训练模型根据给定剩余的成分来预测它们。一般来说,其目标可以表述为
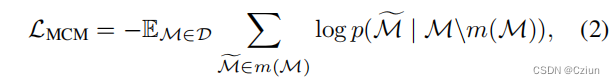
对于基于序列的预训练,ChemBERTa, SMILES-BERT和Molformer掩盖SMILES串中的随机字符,然后根据损坏的SMILES串的transformer的输出恢复它们。对于分子图的预训练,[Hu et al., 2020a]提出随机屏蔽输入的原子/化学键属性,并对GNN进行预训练以预测它们。类似地,GROVER试图预测掩蔽的子图,以捕获分子图中的上下文信息。最近,Mole-BERT认为,由于自然界中极小且不平衡的原子集合,掩盖原子类型可能会有问题。为了缓解这个问题,他们设计了一个上下文感知的分词器,将原子编码为具有化学意义的离散值来进行掩蔽。
MCM对注释丰富的分子尤其有益。例如,掩蔽原子属性使GNN能够学习简单的化学规则,如价性,以及潜在的其他复杂的化学描述符,如官能团的电子或空间效应。此外,与上述AM策略相比,MCM基于周围环境预测掩蔽组件,而AM仅依赖于预定义序列中的前面组件。因此,MCM可以捕获更完整的化学语义。然而,由于MCM在BERT之后的预训练过程中经常掩盖每个分子的固定部分,因此它不能对每个分子中的所有成分进行训练,这导致样本利用效率较低。
3.4 上下文预测 (Context Prediction, CP)
CP旨在以一种明确的、上下文感知的方式捕获分子/原子的语义。通常,CP可以表述为
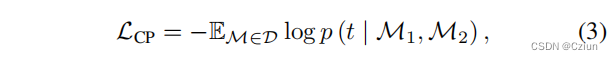
如果邻域分量
M
1
\mathcal{M}1
M1和周围上下文
M
2
\mathcal{M}2
M2共享相同一个中心原子,那么
t
=
1
t=1
t=1,否则
t
=
0
t=0
t=0。例如,[Hu et al., 2020a]使用了一种对分子的子图和周围的上下文结构是否属于同一节点的二元分类。虽然简单而有效,但CP需要一个辅助的神经模型来将上下文编码为一个固定的向量,这为大规模的预训练增加了额外的计算开销。
3.5 对比学习 (Contrastive Learning, CL)
CL通过最大限度地提高一对相似输入之间的一致性来对模型进行预训练,例如同一分子的两个不同的增强量或描述符。根据对比粒度(如分子或子结构级),本文在CPMs中引入了两类CL:交叉尺度对比(Cross-Scale Contrast, CSC)和同尺度对比(Same-Scale Contrast, SSC)。
Cross-Scale Contrast (CSC). Deep InfoMax是一个代表性的CSC模型,最初是通过对比一对图像及其局部区域与其他负对来学习图像表示。对于分子图,InfoGraph通过对比分子和子结构级的表示来遵循这一想法,这可以正式描述为
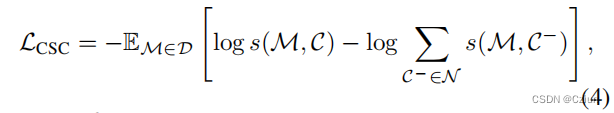
后续工作MVGRL执行节点扩散来生成一个增强的分子图,然后通过对比一个视图的原子表示与另一个视图的分子表示,来最大化原始视图和增强视图之间的相似性,反之亦然。
Same-Scale Contrast (SSC). SSC通过将增强分子推向锚定分子(正对)和远离其他分子(负对),对单个分子进行对比学习。例如,GraphCL及其变体提出了用图表示的分子级预训练的各种增强策略。此外,最近的一些工作最大限度地提高了相同分子的不同描述符之间的一致性,并排斥了不同的描述符。例如,SMICLR联合利用一个图编码器和一个SMILES字符串编码器来执行SSC;MM-Deacon利用两个独立的transformer来编码SMILES和国际纯化学和应用化学联盟( International Union of Pure and Applied Chemistry, IUPAC)的分子,之后使用一个对比目标来促进来自同一个分子的SMILES和IUPAC表示的相似性。3DInfoMax提出最大限度地提高学习到的三维几何和二维图表示之间的一致性;GeomGCL采用双视图几何消息传递神经网络(GeomMPNN)对一个分子的二维和三维图进行编码,并设计一个几何对比目标。SSC预训练目标的一般表述是
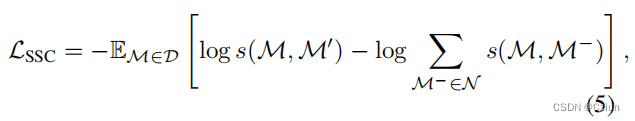
缺点:首先,在分子增强过程中保留语义是很难的。现有的解决方案选择人工试验和增强,繁琐的优化,或通过昂贵的领域知识的指导,但仍然缺乏一种有效和有原则的方法来设计化学上合适的分子预训练增强。此外,CL背后的假设,拉近相似的表征可能并不总是适用于分子表征学习。例如,在分子活性悬崖的情况下,相似的分子具有完全不同的性质。此外,大多数CPM中的CL目标随机选择一个batch中的所有其他分子作为负样本,而不管它们的真实语义如何,这将排斥具有相似性质的分子,并由于假阴性而破坏性能。
3.6 替换组件检测 (Replaced Components Detection, RCD)
RCD提出识别输入分子中随机替换的组件。例如,MPG将每个分子分成两部分,通过结合两个分子的部分来打乱其结构,并训练编码器检测合并后的部分是否属于同一分子。
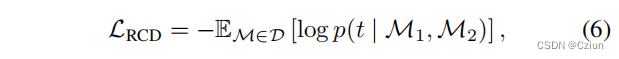
虽然RCD可以揭示分子结构中的内在模式,但编码器经过预训练,总是对所有自然分子产生相同的“非替换”标签,对随机组合的分子产生“替换”标签。然而,在下游任务中,输入的分子都是自然的,导致RCD产生的分子表征不太容易区分。
3.7 去噪 (DeNoising, DN)
例如,Denoising,Uni-Mol,GeoSSL。
3.8 Extensions
Knowledge-enriched pre-training. 缺乏特定领域的知识,so将外部知识注入到CPMs中。
Multimodal pre-training. 除了在第二节中提到的描述符之外,分子也可以使用其他形式来描述,包括图像和生化文本。最近的一些工作是对分子进行了多模态预训练。
4 Applications
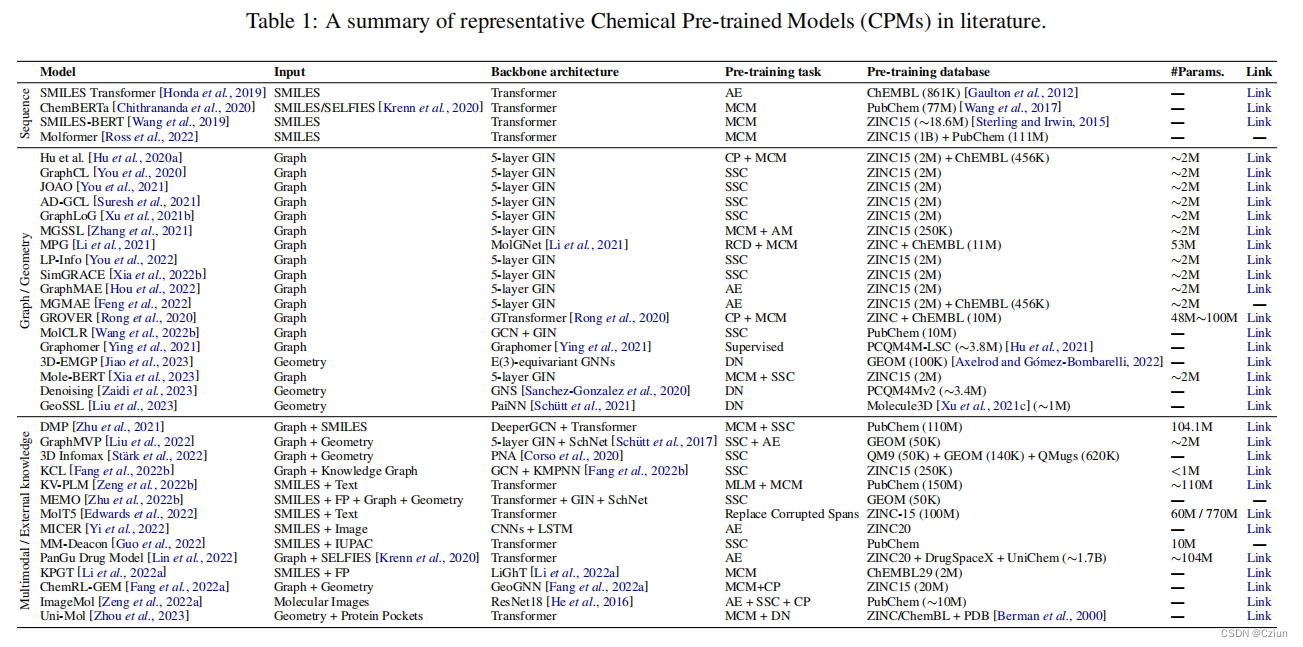
下一节以药物发现作为案例研究,并展示了CPMs的几个有前途的应用(表1)。
4.1 分子性质预测(MPP)
4.2 分子生成(MG)
4.3 药物-靶点相互作用(DTI)
4.4 药物-药物相互作用(DDI)
5 结论和未来展望
5.1 改进编码器结构和预训练目标
在确定高度结构化分子的最佳设计时缺乏特异性
目前迫切需要探索将消息传递技术无缝集成到transformer中,作为一个统一的编码器,以适应大规模分子图的预训练
预培训的目标仍有很大的改进空间
5.2 建立可靠和现实的基准测试
由于使用的不一致的评估设置(例如,随机种子和数据集分割),实验结果有时可能是不可靠的
同样至关重要的是,要为CPMs建立更可靠和更现实的基准,并考虑到分布外的泛化。一种解决方案是通过支架拆分来评估CPMs,这包括基于分子的子结构来拆分分子。



![[Linux] CentOS7 中 pip3 install 可能出现的 ssl 问题](https://img-blog.csdnimg.cn/img_convert/29c830d4f53c9cf7208604914d0e34a2.png)