机器学习方法与原则
评价指标
TODO
训练集、验证集与测试集
训练集与测试集
- 训练集(作业): 模型可见样本标签,用于训练模型,样本数量有限。
- 在训练集上表现好的模型, 在其它未见样本上一定表现好么? 小心过拟合
- 未见样本(所有没做过的题)往往有指数级别或者无穷多个。
测试集和训练集都属于未见样本。 - 测试集(考试): 用于评估模型在可能出现的未见样本上的表现
- 尽可能与训练集互斥,即测试样本 尽量不在训练集中出现,主要估计泛化能力
- 估计模型在整个未见样本的表现
训练集与测试集的划分方式
- 随机划分
- 按比例,例如 9:1、8:2
- 固定数目,例如测试集从全部样本中采样1w个, 其余为训练集
- 留一划分(leave- one-out)
- 适用于数据量少的
- 一个样本做测试,其余样本训练:常用于K近邻
等算法的性能评估
- 特殊划分
- 按时间划分(一般是天然有时间序列的, 而且时间很重要), 例如 1-5月气象数据作训练, 6月气象数据作测试
- 推荐系统中, 常把每个用户交互序列的最后一个样本作测试, 其余作训练。
- …
验证集
- 从训练集中额外分出的集合,一般用于超参数的调整
- 训练轮次、正则化权重、学习率等等
- 为什么不在训练集上调整超参数?过拟合训练集
- 为什么不在测试集上调整超参数?过拟合测试集
- 针对当前测试集调出的参数可能只在当前测试集上较好
- 使得测试集结果偏高,不能反映实际在所有未见样本上的效果
- 类比: 针对某场考试的知识点分布作重点复习,不能准确反映学生对所有知识的掌握程度。
- 举例: 机器学习竞赛中,针对公开部分的测试数据过度调参,不一定在隐蔽的全部测试数据上表好。
训练集、测试集与验证集

如果知识比较算法,只需要经过训练集和验证集处理就行, 不需要再经过完整训练集处理。
训练示例: 比如测试12月天气数据, 11月作为验证集,1-10月作为训练集, 经过1-10月数据的训练,并在验证集上调参, 确定 A ( α , β ) A(\alpha, \beta) A(α,β)函数好, 再经过完整训练集处理,得出 A ′ A^{'} A′, 在测试集上测试。
随机重复实验
问题
-
测试一次就足够了么?
- 极端情况: 二分类中分类器随机输出,恰好测试集都对了(效果最好?)
-
数据随机性
- 由 数据集划分带来的评价指标波动,如第一次负例都在下方, 第二次有个负例在上方

- 由 数据集划分带来的评价指标波动,如第一次负例都在下方, 第二次有个负例在上方
-
模型随机性
- 由模型或学习算法本身带来的评价指标波动
- 例如:神经网络初始化、训练批次生成 、比如局部最优的方法,起点不同会导致最终不一样,还比如使用到的random
方法
-
数据随机性
- (数据足够多时)增多测试样本
- (数据量有限时)重复多次划分数据集
-
模型随机性
- 更改随机种子重复训练、测试
-
注意: 保持每次得到的评价指标独立同分布(iid)
比如,第一次取这个好, 第二次就在这个的基础上再取,这样不符合独立同分布 -
报告结果: (多次随机试验的)评价指标的均值 X ‾ = 1 n ∑ i = 1 n X i \overline X = \frac{1}{n}\sum_{i=1}^{n}X_i X=n1∑i=1nXi
- 样本标准差(个体离散程度,反映了个体对样本均值的代表性) S = ∑ i = 1 n ( X i − X ‾ ) 2 n − 1 S = \sqrt{\sum_{i=1}^{n} \frac{(X_i -\overline X)^2}{n-1}} S=∑i=1nn−1(Xi−X)2
- 标准误差(样本均值的离散程度,反映了样本均值对总体均值的代表性)
S t a n d a r d E r r o r o f t h e M e a n , S E M = S n = ∑ i = 1 n ( X i − X ‾ ) 2 n ( n − 1 ) Standard\ Error \ of \ the \ Mean, SEM = \frac{S}{\sqrt{n}} = \sqrt{\sum_{i=1}^n\frac{(X_i - \overline{X})^2}{n(n-1)}} Standard Error of the Mean,SEM=nS=∑i=1nn(n−1)(Xi−X)2
K折交叉验证(K-fold cross validation )
- 随机把数据集分成K个相等大小的不相交子集。
选出一份作为测试集,一共k种情况, 分别训练, 得出k个测试结果,取平均得出最终结果。


优缺点
- 优点: 数据利用率高,适用于数据较少时
- 缺点: 训练集相互有交集,每一轮之间并不满足独立同分布,两轮之间至少k-2组数据相同
其它
-
增大K,一般情况下:
- 所评估的模型效果偏差(bias)下降
- 所估计的模型效果方差(variance)上升
- 计算代价上升,更多轮次、训练集需求更大
-
K 一般取5、10
统计有效性检验
问题
假设的评估检验: 问题1
- 效果估计
- 给一个假设在有限量数据上的准确率
- 该准确率是否能够准确估计其它未见数据上的效果

假设的评估检验:问题2
- h1 在数据的一个样本集上表现优于h2
- h1总体上更好的概率有多大

解答
估计假设准确率 -Q1.1 解答
🔔用到后面二项分布的知识
如何对一个假设h 在来自同一分布的未见样本上的准确率作出最好的估计?
**n个随机样本(测试集上的)中有r个被误分类的概率–二项分布 P ( r ) = n ! r ! ( n − r ) ! p r ( 1 − p ) n − r P(r) = \frac{n!}{r!(n-r)!}p^r(1-p)^{n-r} P(r)=r!(n−r)!n!pr(1−p)n−r
e
r
r
o
r
D
(
h
)
=
p
error_D(h)=p
errorD(h)=p, 真实错误率是p
样本错误率,
e
r
r
o
r
s
(
h
)
=
r
n
error_s(h)=\frac{r}{n}
errors(h)=nr ,n次错了r次, s代表样本(sample)
E [ r ] = n p , E [ e r r o r S ( h ) ] = E [ r n ] = n p n = p = e r r o r D ( h ) E[r]=np, \ \ \ E[error_S(h)]=E[\frac{r}{n}] = \frac{np}{n}=p=error_D(h) E[r]=np, E[errorS(h)]=E[nr]=nnp=p=errorD(h) 样本错误率的期望值=真实错误率,也就是进行很多次后,样本错误率=真实错误率
σ e r r o r s ( h ) = σ r n = n p ( 1 − p ) n = e r r o r S ( h ) ( 1 − e r r o r S ( h ) ) n \sigma_{error_s(h)}=\frac{\sigma_r}{n}=\frac{\sqrt{np(1-p)}}{n}=\sqrt{\frac{error_S(h)(1-error_S(h))}{n}} σerrors(h)=nσr=nnp(1−p)=nerrorS(h)(1−errorS(h))
测试集样本数
n
=
100
,
错了
r
=
12
个 样本错误率是
12
%
,则标准差
σ
=
3.2
%
测试集样本数n=100,错了r=12个\ \ \ \ 样本错误率是12\%, 则标准差\sigma = 3.2\%
测试集样本数n=100,错了r=12个 样本错误率是12%,则标准差σ=3.2%
测试集样本数
n
=
25
,
错了
r
=
3
个 样本错误率是
12
%
,则标准差
σ
=
6.5
%
测试集样本数n=25,错了r=3个\ \ \ \ 样本错误率是12\%, 则标准差\sigma = 6.5\%
测试集样本数n=25,错了r=3个 样本错误率是12%,则标准差σ=6.5%
估计的两个重要性质
- 估计偏差 (Bias)
- 如果 S 是训练集, error_S(h) 是有偏差的(偏乐观),
b i a s ≡ E [ e r r o r S ( h ) ] − e r r o r D ( h ) bias ≡ E[errorS(h) ] - errorD(h) bias≡E[errorS(h)]−errorD(h) - 对于无偏估计(bias =0), h(训练集的模型) 和 S(测试集样例) 必须独立不相关地产生
→ 不要在训练集上测试!
- 如果 S 是训练集, error_S(h) 是有偏差的(偏乐观),
- 估计方差 (Varias)
- 即使是S 的无偏估计,
e
r
r
o
r
S
(
h
)
errorS(h)
errorS(h)可能仍然和
e
r
r
o
r
D
(
h
)
error_D(h)
errorD(h) 不同
- E.g. 之前的例子 (3.2% vs. 6.5%)
- 需要选择无偏的且有最小方差的估计
- 即使是S 的无偏估计,
e
r
r
o
r
S
(
h
)
errorS(h)
errorS(h)可能仍然和
e
r
r
o
r
D
(
h
)
error_D(h)
errorD(h) 不同
估计假设准确率 – Q1.2解答
准确率的估计可能包含多少错误?
(
e
r
r
o
r
S
(
h
)
对
e
r
r
o
r
D
(
h
)
的估计有多好
?
error_S(h) 对 error_D(h)的估计有多好?
errorS(h)对errorD(h)的估计有多好?)
🔔用到后面的正态知识
均值 μ 均值\mu 均值μ其实就是样本的错误率
- 如果如果满足以下条件,估计更准确:
- (测试集)S 包含 n >= 30个样本, 与h独立产生,且每个样本独立采样
- 那么有大约95%的概率**𝑒𝑟𝑟𝑜𝑟𝑆(ℎ)**落在区间 e r r o r D ( h ) + ‾ 1.96 e r r o r D ( h ) ( 1 − e r r o r D ( h ) ) n error_D(h)\underline+ 1.96\sqrt{\frac{error_D(h)(1-error_D(h))}{n}} errorD(h)+1.96nerrorD(h)(1−errorD(h))
- 等价于, e r r o r D error_D errorD落在区间 e r r o r S ( h ) + ‾ 1.96 e r r o r D ( h ) ( 1 − e r r o r D ( h ) ) n error_S(h)\underline+1.96\sqrt{\frac{error_D(h)(1-error_D(h))}{n}} errorS(h)+1.96nerrorD(h)(1−errorD(h)) (用到后面正态的等价,y: μ + ‾ z σ \mu\underline+ z\sigma μ+zσ => μ : y + ‾ z σ \mu: y\underline+z\sigma μ:y+zσ
- 近似等于, e r r o r S ( h ) + ‾ 1.96 e r r o r S ( h ) ( 1 − e r r o r S ( h ) ) n error_S(h)\underline+1.96\sqrt{\frac{error_S(h)(1-error_S(h))}{n}} errorS(h)+1.96nerrorS(h)(1−errorS(h)) (无偏估计下,期望E(errors)=errorD)
问题1解答总结
-
问题设定:
- S(测试集): n 随机独立样本, 且独立于假设 h(即bias=0)
- n >= 30 & h 有 r 个错误
-
**真实错误率 e r r o r D error_D errorD**落在以下区间有N% 置信度
e r r o r S ( h ) + ‾ z N e r r o r S ( h ) ( 1 − e r r o r S ( h ) ) n error_S(h)\underline+z_N\sqrt{\frac{error_S(h)(1-error_S(h))}{n}} errorS(h)+zNnerrorS(h)(1−errorS(h))

推导置信区间的一般方法
- 一般地,
- 确定需要估计的变量 p, e.g. e r r o r D ( h ) error_D(h) errorD(h)
- 确定估计量Y (偏差, 方差), e.g.
e
r
r
o
r
S
(
h
)
error_S(h)
errorS(h)
- 希望 : 小方差, 无偏估计
- 确定Y 的分布 D (包括均值 & 方差)
- 确定N% 置信区间 (L…U) •
- 可能有 L=-∞ or U=∞
- E.g. (对于正态分布)利用 z n z_n zn 表查询相关值
- 一般地,
-
也可应用在其他问题上
中心极限定理
-
简化了求解置信区间的过程
-
问题设定
- 独立同分布Independent, identically distributed (iid)
的随机变量 Y 1 , . . . , Y n Y_1, ... , Y_n Y1,...,Yn - 未知分布, 有均值 μ 和有限方差 σ2
- 估计均值: Y ‾ ≡ 1 n ∑ i = 1 n Y i \overline Y \equiv \frac{1}{n} \sum_{i=1}^{n} Y_i Y≡n1∑i=1nYi
- 独立同分布Independent, identically distributed (iid)
-
中心极限定理
- Y ‾ \overline Y Y服从正态分布 (n →∞)
- 均值 μ \mu μ , 方差 σ 2 / n \sigma^2/n σ2/n
- 可以被归一化到标准正态分布,即 μ = 0 , σ = 1 \mu = 0, \sigma = 1 μ=0,σ=1
-
样本均值 Y ‾ \overline Y Y 的分布
- 是已知的
- 即使 Y i Y_i Yi 的分布是未知的
- 可以用来确定的 Y i Y_i Yi均值方差
-
提供了估计的基础
- 估计量的分布
- 一些样本的均值
问题2的解答
- h1 在数据的一个样本集上表现优于 h2
- h1 总体上更好的概率有多大?
假设之间的差异

- h1 总体上更好的概率有多大?
假设间的差异
- 在样本集合 S 1 S_1 S1 ( n 1 n_1 n1个随机样本)上测试 h 1 h_1 h1, 在 S 2 ( n 2 ) S_2 (n_2) S2(n2)上测试 h 2 h_2 h2
- 选择要估计的参数 d ≡ e r r o r D ( h 1 ) − e r r o r D ( h 2 ) d\equiv error_D(h1) - error_D(h2) d≡errorD(h1)−errorD(h2)
- 选择估计量
- 无偏的 d ^ ≡ e r r o r S 1 ( h 1 ) − e r r o r S 2 ( h 2 ) \hat d \equiv error_{S_1}(h1) - error_{S_2}(h2) d^≡errorS1(h1)−errorS2(h2)
- 确定估计量
d
^
\hat d
d^ 所服从的概率分布
- e r r o r S 1 ( h 1 ) error_{S_1}(h1) errorS1(h1) , e r r o r S 2 ( h 2 ) error_{S_2}(h2) errorS2(h2) 近似服从正态分布
-
d
^
\hat d
d^ 也近似正态分布
- 均值 = d
- 方差: 加和
σ d ^ ≈ e r r o r S 1 ( h 1 ) ( 1 − e r r o r S 1 ( h 1 ) ) n 1 + e r r o r S 2 ( h 2 ) ( 1 − e r r o r S 2 ( h 2 ) ) n 2 \sigma_{\hat d} \approx \sqrt{\frac{error_{S_1}(h_1)(1-error_{S_1}(h_1))}{n_1} + \frac{error_{S_2}(h_2)(1-error_{S_2}(h_2))}{n_2}} σd^≈n1errorS1(h1)(1−errorS1(h1))+n2errorS2(h2)(1−errorS2(h2))
证明正态分布和也是正态分布: http://en.wikipedia.org/wiki/Sum_of_normally_distributed_random_variables
- 确定区间(L,U)满足N%的概率落在区间
d ^ + ‾ z N e r r o r S 1 ( h 1 ) ( 1 − e r r o r S 1 ( h 1 ) ) n 1 + e r r o r S 2 ( h 2 ) ( 1 − e r r o r S 2 ( h 2 ) ) n 2 \hat d \underline+ z_N\sqrt{\frac{error_{S_1}(h_1)(1-error_{S_1}(h_1))}{n_1} + \frac{error_{S_2}(h_2)(1-error_{S_2}(h_2))}{n_2}} d^+zNn1errorS1(h1)(1−errorS1(h1))+n2errorS2(h2)(1−errorS2(h2))
假设检验
- 某些陈述可能是真的概率
- E.g. 例如 e D ( h 1 ) > e D ( h 2 ) e_D(h_1) >e_D(h_2) eD(h1)>eD(h2)的概率
- 例子(
n
1
=
n
2
=
100
n_1=n_2=100
n1=n2=100)
- 错误率 e S 1 ( h 1 ) = 0.3 , 错误率 e S 2 ( h 2 ) = 0.2 , 求 e D ( h 1 ) > e D ( h 2 ) 错误率e_{S_1}(h_1)=0.3, 错误率e_{S_2}(h_2)=0.2,求e_D(h_1)>e_D(h_2) 错误率eS1(h1)=0.3,错误率eS2(h2)=0.2,求eD(h1)>eD(h2)的概率
- d ^ ≡ e r r o r S 1 ( h 1 ) − e r r o r S 2 ( h 2 ) \hat d \equiv error_{S_1}(h_1) -error_{S_2}(h_2) d^≡errorS1(h1)−errorS2(h2)
- d ≡ e r r o r D 1 ( h 1 ) − e r r o r D 2 ( h 2 ) d \equiv error_{D_1}(h_1) -error_{D_2}(h_2) d≡errorD1(h1)−errorD2(h2)
- 给定 d ^ = 0.1 , 求 e D ( h 1 ) > e D ( h 2 ) \hat d = 0.1, 求e_D(h_1)>e_D(h_2) d^=0.1,求eD(h1)>eD(h2)的概率
- 给定 d ^ = 0.1 , 求 d > 0 \hat d = 0.1,求d > 0 d^=0.1,求d>0的概率, 也就是d + 0.1 > 0.1的概率,也就是d + 0.1 > d ^ \hat d d^
-
d
^
\hat d
d^在区间d + 0.1 >
d
^
\hat d
d^的概率
- 注意: d是 d ^ \hat d d^概率分布的均值
-
d
^
\hat d
d^在区间
d
^
<
μ
d
^
+
0.1
\hat d < \mu_{\hat d} + 0.1
d^<μd^+0.1的概率
μ + ‾ z n σ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \mu \underline+ z_n\sigma μ+znσ
统计有效性检验: z检验(举例1)
- z 检验适用于(独立同分布)
- n 1 = n 2 = 100 , a c c S 1 ( h 1 ) = 0.3 , a c c S 2 ( h 2 ) = 0.2 n_1=n_2=100, acc_{S_1}(h_1)=0.3, acc_{S_2}(h_2)=0.2 n1=n2=100,accS1(h1)=0.3,accS2(h2)=0.2
- 则 d ^ ≡ a c c S 1 ( h 1 ) − a c c S 2 ( h 2 ) = 0.1 \hat d \equiv acc_{S_1}(h_1) -acc_{S_2}(h_2) =0.1 d^≡accS1(h1)−accS2(h2)=0.1
- 求 d ≡ a c c D 1 ( h 1 ) − a c c D 2 ( h 2 ) > 0 d \equiv acc_{D_1}(h_1) -acc_{D_2}(h_2) > 0 d≡accD1(h1)−accD2(h2)>0的置信度
- 即求 d ^ < d + 0.1 \hat d < d + 0.1 d^<d+0.1的概率(d>0,两边同时+0.1, 用 d ^ = 0.1 \hat d=0.1 d^=0.1推出)
- 又有 σ d ^ ≈ e r r o r S 1 ( h 1 ) ( 1 − e r r o r S 1 ( h 1 ) ) n 1 + e r r o r S 2 ( h 2 ) ( 1 − e r r o r S 2 ( h 2 ) ) n 2 = 0.061 \sigma_{\hat d} \approx \sqrt{\frac{error_{S_1}(h_1)(1-error_{S_1}(h_1))}{n_1} + \frac{error_{S_2}(h_2)(1-error_{S_2}(h_2))}{n_2}} = 0.061 σd^≈n1errorS1(h1)(1−errorS1(h1))+n2errorS2(h2)(1−errorS2(h2))=0.061
- 则 d ^ < d + 0.1 → d ^ < d + 1.64 σ d ^ \hat d < d + 0.1 \rightarrow \hat d < d + 1.64\sigma_{\hat d} d^<d+0.1→d^<d+1.64σd^ (是由 d ^ < d + Z n σ \hat d < d + Z_n\sigma d^<d+Znσ, Z n = 0.1 / 0.061 ≈ 1.64 Z_n = 0.1 /0.061 \approx1.64 Zn=0.1/0.061≈1.64推出)
- 即 Z N = 1.64 Z_N=1.64 ZN=1.64, 查正态分布表可知,双边置信度为90%,
- 则单边置信度95%
- 即 a c c D 1 ( h 1 ) > a c c D 2 ( h 2 ) acc_{D_1}(h_1) > acc_{D_2}(h_2) accD1(h1)>accD2(h2)的置信度为95%
统计有效性检验: z检验(举例1)
- z 检验适用于(独立同分布)
- n 1 = n 2 = 30 , a c c S 1 ( h 1 ) = 0.3 , a c c S 2 ( h 2 ) = 0.2 n_1=n_2=30, acc_{S_1}(h_1)=0.3, acc_{S_2}(h_2)=0.2 n1=n2=30,accS1(h1)=0.3,accS2(h2)=0.2
- 则 d ^ ≡ a c c S 1 ( h 1 ) − a c c S 2 ( h 2 ) = 0.1 \hat d \equiv acc_{S_1}(h_1) -acc_{S_2}(h_2) =0.1 d^≡accS1(h1)−accS2(h2)=0.1
- 求 d ≡ a c c D 1 ( h 1 ) − a c c D 2 ( h 2 ) > 0 d \equiv acc_{D_1}(h_1) -acc_{D_2}(h_2) > 0 d≡accD1(h1)−accD2(h2)>0的置信度
- 即求 d ^ < d + 0.1 \hat d < d + 0.1 d^<d+0.1的概率(d>0,两边同时+0.1, 用 d ^ = 0.1 \hat d=0.1 d^=0.1推出)
- 又有 σ d ^ ≈ e r r o r S 1 ( h 1 ) ( 1 − e r r o r S 1 ( h 1 ) ) n 1 + e r r o r S 2 ( h 2 ) ( 1 − e r r o r S 2 ( h 2 ) ) n 2 = 0.111 \sigma_{\hat d} \approx \sqrt{\frac{error_{S_1}(h_1)(1-error_{S_1}(h_1))}{n_1} + \frac{error_{S_2}(h_2)(1-error_{S_2}(h_2))}{n_2}} = 0.111 σd^≈n1errorS1(h1)(1−errorS1(h1))+n2errorS2(h2)(1−errorS2(h2))=0.111
- 则 d ^ < d + 0.1 → d ^ < d + 0.90 σ d ^ \hat d < d + 0.1 \rightarrow \hat d < d + 0.90\sigma_{\hat d} d^<d+0.1→d^<d+0.90σd^ (
- 即 Z N = 0.90 Z_N=0.90 ZN=0.90, 查正态分布表可知,双边置信度为68%,
- 则单边置信度84%
- 即 a c c D 1 ( h 1 ) > a c c D 2 ( h 2 ) acc_{D_1}(h_1) > acc_{D_2}(h_2) accD1(h1)>accD2(h2)的置信度为84%
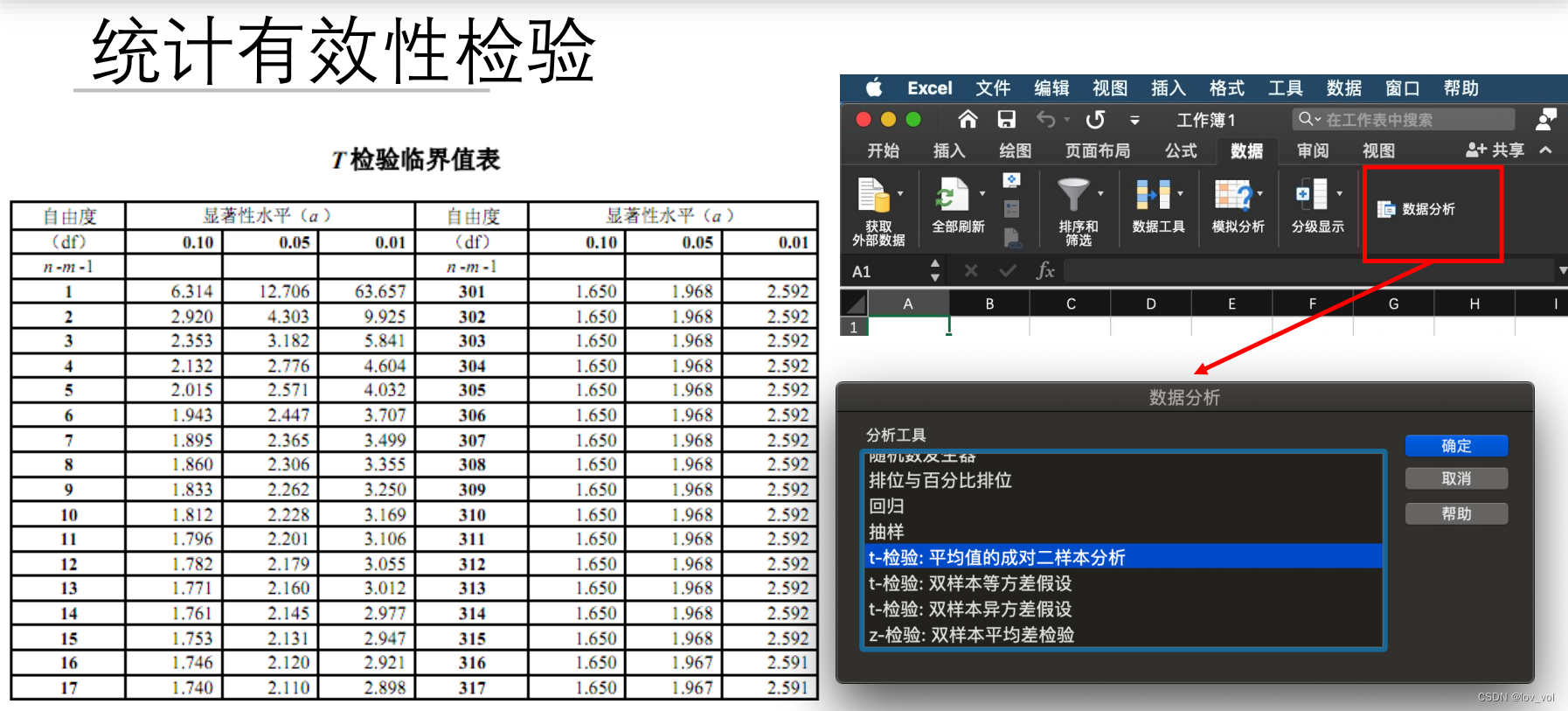
统计有效性检验:t检验
z检验只适合独立同分布, 非独立同分布可以使用t检验
交叉验证如果测试题不同可以用z检验,否则只能用t检验
- 记模型
h
1
h_1
h1的
n
1
n_1
n1次重复实验结果为
x
11
,
x
12
,
…
,
x
1
n
1
x_{11}, x_{12}, … , x_{1n_{1}}
x11,x12,…,x1n1
x ‾ 1 = 1 n 1 ∑ i = 1 n 1 x 1 i , s 1 2 = 1 n 1 − 1 ∑ i = 1 n 1 ( x 1 i − x ‾ 1 ) 2 \overline x_1 = \frac{1}{n_1} \sum_{i=1}^{n_1}x_{1i}, s_1^2 = \frac{1}{n_1-1}\sum_{i=1}^{n_1}(x_{1i}-\overline x_1)^2 x1=n11∑i=1n1x1i,s12=n1−11∑i=1n1(x1i−x1)2 - 记模型
h
2
h_2
h2的
n
2
n_2
n2次重复实验结果为
x
21
,
x
22
,
…
,
x
2
n
2
x_{21}, x_{22}, … , x_{2n_{2}}
x21,x22,…,x2n2
x ‾ 2 = 1 n 2 ∑ i = 1 n 2 x 2 i , s 2 2 = 1 n 2 − 1 ∑ i = 1 n 2 ( x 2 i − x ‾ 2 ) 2 \overline x_2 = \frac{1}{n_2} \sum_{i=1}^{n_2}x_{2i}, s_2^2 = \frac{1}{n_2-1}\sum_{i=1}^{n_2}(x_{2i}-\overline x_2)^2 x2=n21∑i=1n2x2i,s22=n2−11∑i=1n2(x2i−x2)2 - 在样本量及方差均不相等的假设下有
- 检验量 t = ( x ‾ 1 − x ‾ 2 ) / s 1 2 n 1 + s 2 2 n 2 t = (\overline x_1 - \overline x_2)/\sqrt{\frac{s_1^2}{n_1} + \frac{s_2^2}{n_2}} t=(x1−x2)/n1s12+n2s22, 自由度 d f = ( s 1 2 n 1 + s 2 2 n 2 ) 2 / ( s 1 4 n 1 2 ( n 1 − 1 ) + s 2 4 n 2 2 ( n 2 − 1 ) ) df=(\frac{s_1^2}{n_1} + \frac{s_2^2}{n_2})^2/(\frac{s_1^4}{n_1^2(n_1-1)}+\frac{s_2^4}{n_2^2(n_2-1)}) df=(n1s12+n2s22)2/(n12(n1−1)s14+n22(n2−1)s24)
- 若𝑛1 = 𝑛2 = 𝑛且 d i = x 1 i − x 2 i d_i = x_{1i} − x_{2i} di=x1i−x2i独立且来自正态分布
- 可采用配对t检验(paired t-test),例如两组结果测试集依次相同时
- 即两个模型在同样划分的交叉验证或同样测试集的重复对比实验
检验量 t = ( x ‾ 1 − x ‾ 2 ) / ∑ i = 1 n ( d i − d ‾ ) 2 n ( n − 1 ) t = (\overline x_1 - \overline x_2)/\sqrt{\frac{\sum_{i=1}^{n}(d_i-\overline d)^2}{n(n-1)}} t=(x1−x2)/n(n−1)∑i=1n(di−d)2, 自由度为𝑛 − 1
• 根据检验量和自由度查t分布表可得置信度(类似根据 z N z_N zN查正态分布表)
统计有效性
统计有效性检验(总结)
- 比较算法A和B的优劣
- 准确率均值高就一定好?有随机性
- A比B高多少才能有把握说A算法更好?显著性检验(N > 90% 95 % 99% 一般是选择大于99%
- 随机变量的样本个数较多时(一般>30): z检验(利用中心极限定理)
- 一般用于单次评测,随机变量为每个测试样本的对错
- 随机变量的样本个数较少时(一般<=30):t检验
- 一般用于多次评测如重复实验,随机变量为每次测试集上的指标
小结
- 评价指标:回归任务, 分类任务, 特定任务
- 训练集、验证集与测试集:随机划分, 留一划分,特殊划分
- 随机重复实验
- K折交叉验证
- 统计有效性检验:z检验,t检验
##抽样理论基础(Sample theory)
二项分布(Binomial Distribution)
- 伯努利实验
- 只有 2 种输出:
成功概率: p p p,失败概率: q = 1 − p q =1-p q=1−p - 用随机变量 X X X 记录成功的次数
- 只有 2 种输出:
- 伯努利分布:
- 抛硬币: 正面朝上的概率为 p p p, 抛 n n n 次, 观察到 r r r 次正面朝上
- 若计
X
X
X~
B
(
n
,
p
)
B(n, p)
B(n,p),
P
r
(
X
=
r
)
=
P
(
r
)
P_r(X= r) = P(r)
Pr(X=r)=P(r) ,则
P ( r ) = n ! r ! ( n − r ) ! p r ( 1 − p ) n − r P(r) = \frac{n!}{r!(n-r)!}p^r(1-p)^{n-r} P(r)=r!(n−r)!n!pr(1−p)n−r

二项分布的应用场景
- 两个可能的输出 (成功/失败) ( Y = 0 或 Y = 1 Y=0 或 Y=1 Y=0或Y=1)
- 每次尝试成功的概率相等 P r ( Y = 1 ) = p , 其中 p 是一个常数 Pr(Y = 1) = p , 其中 p 是一个常数 Pr(Y=1)=p,其中p是一个常数
-
n
n
n 次独立尝试
- 随机变量 Y 1 , . . . , Y n Y_1,...,Y_n Y1,...,Yn
- iid (independent identically distribution,独立同分布)
- R: 随机变量, n 次尝试中 Y i = 1 Y_i= 1 Yi=1的次数,
- P r ( R = r ) P_r(R = r) Pr(R=r) ~ 二项分布
- 平均 (期望值):
E
[
R
]
,
µ
E[R], µ
E[R],µ
- 二项分布: µ = n p µ= np µ=np
- 方差:
V
a
r
[
R
]
=
E
[
(
R
−
E
[
R
]
)
2
]
,
σ
2
(
标准差
σ
)
Var[R]=E[(R-E[R])^2], \sigma^2 (标准差\sigma)
Var[R]=E[(R−E[R])2],σ2(标准差σ)
- 二项分布:
σ
2
=
n
p
(
1
−
p
)
\sigma^2 = np(1- p)
σ2=np(1−p)

- 二项分布:
σ
2
=
n
p
(
1
−
p
)
\sigma^2 = np(1- p)
σ2=np(1−p)
置信区间(confidence interval)
- 定义
- 参数p 的N %置信区间是一个以N %的概率包含p 的区间, N% : 置信度
✓ 90.0%的置信度 ,年龄:[12, 24], p是年龄
✓ 99.9%的置信度,年龄:[3, 60]
如 95%的错误率在12%~17%之间
- 参数p 的N %置信区间是一个以N %的概率包含p 的区间, N% : 置信度
置信度与置信区间
- 如何得到置信区间?
- 坏消息: 对二项分布来说很难
- 好消息: 对正态分布来说很简单
- 通过正态分布的某个区间(面积)来获得

- 通过正态分布的某个区间(面积)来获得
- 指标y有 N % N\% N% 的可能性落在区间 μ + ‾ Z N σ \mu\underline+Z_N\sigma μ+ZNσ
- 等价于, 均值
μ
\mu
μ 有
N
%
N\%
N% 的可能性落在区间
y
+
‾
z
N
σ
y\underline+ z_N\sigma
y+zNσ
均值 μ 均值\mu 均值μ其实就是样本的错误率

正态分布
- 正态分布的概率密度函数
p ( x ) = 1 2 π σ 2 e − 1 2 ( x − μ σ ) 2 p(x)=\frac{1}{\sqrt{2\pi\sigma^2}}e^{-\frac{1}{2}(\frac{x-\mu}{\sigma})^2} p(x)=2πσ21e−21(σx−μ)2

正态分布&二项分布
- 对于足够大的采样大小
二项分布 ---->>>可以通过正态分布近似表示 - 经验法则: n>30, np(1-p)> 5 同时满足