MySQL8 新特性——窗口函数用法
MySQL 8.0 是 MySQL 数据库管理系统的一个重要版本,引入了许多新特性和改进。以下是 MySQL 8.0 的一些主要新特性:
-
事务隔离级别改进: MySQL 8.0 引入了新的事务隔离级别
SERIALIZABLE,提供了最高级别的事务隔离,确保了数据的完整性和一致性。同时,它对其他事务隔离级别的实现也进行了改进,提高了并发性和性能。 -
Window Functions 支持: MySQL 8.0 引入了窗口函数(Window Functions)的支持,使得在查询中进行复杂的分析和聚合变得更加灵活和高效。窗口函数可以与
OVER子句一起使用,实现分组、排序、排名等操作。 -
Common Table Expressions (CTEs) 支持: MySQL 8.0 支持通用表达式(CTEs),允许在查询中使用 WITH 子句来定义临时结果集,简化了复杂查询的编写。
-
JSON 支持改进: MySQL 8.0 对 JSON 支持进行了改进,包括支持更多的 JSON 函数和操作,以及更高效的 JSON 存储格式,使得在 MySQL 中存储和查询 JSON 数据更加方便。
-
新增 Data Dictionary: MySQL 8.0 引入了 Data Dictionary 来替代之前的 .frm 文件,用于存储数据库元数据信息,提高了数据库的可靠性和扩展性。
-
InnoDB 存储引擎改进: MySQL 8.0 对 InnoDB 存储引擎进行了多项改进,包括支持更大的表空间、在线表重建、数据压缩和加密、性能优化等。
-
全局事务标识(GTID)改进: MySQL 8.0 改进了全局事务标识(GTID)的支持,简化了主从复制配置和管理,提高了复制的可靠性。
-
Persistent Configuration Variables: MySQL 8.0 引入了持久配置变量,允许将配置参数的值持久化到配置文件中,重启后仍然保持设置。
-
离线数据迁移: MySQL 8.0 支持通过
ALTER TABLE命令进行离线数据迁移,不再需要使用 pt-online-schema-change 工具。 -
二进制日志改进: MySQL 8.0 对二进制日志进行了改进,包括支持多线程写入、事务重放和文件格式改进,提高了日志的性能和可靠性。
以上只是 MySQL 8.0 的一部分新特性,该版本还有许多其他改进,如更好的性能、安全性和扩展性等。MySQL 8.0 的发布为用户提供了更多的功能和选项,使得 MySQL 数据库成为更强大和可靠的数据库解决方案。
窗口函数
窗口函数的作用类似于在查询中对数据进行分组,不同的是,分组操作会把分组的结果聚会成一条记录,而窗口函数是将结果置于每一条数据记录中。
分类
窗口函数可以根据其功能和用途进行分类。在MySQL中,根据其功能,窗口函数主要可以分为以下几类:
-
排名函数(Ranking Functions):
- ROW_NUMBER(): 返回每行在结果集中的唯一编号。
- RANK(): 计算并返回排序后的行在结果集中的排名,相同值有相同的排名,跳过相同排名。
- DENSE_RANK(): 计算并返回排序后的行在结果集中的排名,相同值有相同的排名,不跳过相同排名。
- NTILE(n): 将结果集划分为n个近似相等大小的桶,并为每行分配一个桶编号。
-
聚合函数(Aggregate Functions):
- SUM(): 对窗口中的数值列进行求和。
- AVG(): 对窗口中的数值列进行求平均值。
- MIN(): 返回窗口中数值列的最小值。
- MAX(): 返回窗口中数值列的最大值。
- COUNT(): 返回窗口中行的数量。
-
累积函数(Aggregate Functions with ORDER BY):
- SUM() OVER (): 对窗口中的数值列进行累积求和。
- AVG() OVER (): 对窗口中的数值列进行累积求平均值。
- MIN() OVER (): 返回窗口中数值列的累积最小值。
- MAX() OVER (): 返回窗口中数值列的累积最大值。
-
分析函数(Analytic Functions):
- LEAD(): 获取当前行后面指定偏移量的行的值。
- LAG(): 获取当前行前面指定偏移量的行的值。
- FIRST_VALUE(): 返回窗口中指定列的第一个值。
- LAST_VALUE(): 返回窗口中指定列的最后一个值。
- PERCENT_RANK(): 计算并返回排序后的行在结果集中的百分比排名。(rank - 1) / (rows - 1)
- CUME_DIST(): 计算并返回排序后的行在结果集中的累积分布百分比。
这些是窗口函数的常见分类,每个类别有不同的用途和计算功能,可以根据具体的数据处理需求选择合适的窗口函数来实现复杂的查询和分析操作。
静态/动态窗口函数
实际上,窗口函数在MySQL中并没有严格的"静态"和"动态"分类。窗口函数通常根据其特性和功能进行分类,如我之前所述的排名函数、聚合函数、累积函数和分析函数等。这些分类基于窗口函数的不同计算方式和用途。
然而,可能你提到的"静态窗口函数"和"动态窗口函数"是指窗口函数在窗口帧(Window Frame)中的范围设置方式。窗口帧定义了在计算窗口函数时,应该包含哪些行。在MySQL中,有两种常见的窗口帧设置方式:
- 静态窗口函数(Static Window Functions):在静态窗口函数中,窗口帧的范围是固定的,不随行的位置变化而改变。最常见的静态窗口帧是使用ROWS BETWEEN子句,指定相对于当前行的固定范围来定义窗口。
SELECT
column1,
column2,
SUM(column3) OVER (ORDER BY column1 ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) AS sum_column3
FROM
your_table;
在上述例子中,使用ROWS BETWEEN 2 PRECEDING AND CURRENT ROW定义了一个静态窗口帧,窗口包含当前行以及前面两行的数据。
- 动态窗口函数(Dynamic Window Functions):在动态窗口函数中,窗口帧的范围随着行的位置而变化。最常见的动态窗口帧是使用RANGE BETWEEN子句,基于值的范围来定义窗口。
SELECT
column1,
column2,
SUM(column3) OVER (ORDER BY column1 RANGE BETWEEN INTERVAL 1 HOUR PRECEDING AND CURRENT ROW) AS sum_column3
FROM
your_table;
在上述例子中,使用RANGE BETWEEN INTERVAL 1 HOUR PRECEDING AND CURRENT ROW定义了一个动态窗口帧,窗口包含当前行及其前面1小时内的数据,根据时间的变化而自动调整范围。
需要注意的是,动态窗口函数在MySQL中的支持有限,而且使用时需要谨慎,因为它可能涉及对窗口中的所有数据进行排序,对性能有一定的影响。大多数情况下,静态窗口函数已经能够满足大部分需求。
语法结构
在MySQL中,窗口函数的语法结构如下:
<窗口函数> OVER (
[PARTITION BY partition_expression]
[ORDER BY sort_expression [ASC | DESC], ...]
[window_frame]
)
让我们逐个解释每个部分的含义:
-
<窗口函数>:这是要执行的窗口函数,可以是聚合函数(如SUM()、AVG()、MIN()、MAX()、COUNT()等)、排名函数(如ROW_NUMBER()、RANK()、DENSE_RANK()、NTILE()等)或其他分析函数(如LEAD()、LAG()、FIRST_VALUE()、LAST_VALUE()、PERCENT_RANK()、CUME_DIST()等)。 -
OVER ():这是定义窗口的关键字,它后面跟着圆括号,用于包含窗口的设置。 -
PARTITION BY partition_expression:这是可选的子句,用于将结果集分成不同的分区(组)。partition_expression是一个表达式,根据它的值来划分不同的分区。窗口函数将在每个分区内独立计算。 -
ORDER BY sort_expression [ASC | DESC], ...:这也是可选的子句,用于在每个分区内对数据进行排序。sort_expression是一个表达式,用于指定排序的规则。可以指定多个排序表达式,并可以指定升序(ASC)或降序(DESC)。 -
window_frame:这是可选的子句,用于指定在每个分区中用于窗口函数的行范围。它决定了哪些行包含在计算中。窗口帧可以基于当前行的相对位置(ROWS [n] PRECEDING或FOLLOWING)或基于列的值(RANGE BETWEEN value1 AND value2)。如果未指定window_frame,则窗口函数默认使用所有分区中的所有行。
请注意,窗口函数的具体语法可能因数据库管理系统的版本而有所不同。以上语法适用于MySQL 8.0及以上版本,其他数据库系统(如SQL Server、PostgreSQL等)的语法可能稍有不同。在使用时请根据具体的数据库版本和语法规则进行相应调整。
部分函数用法介绍
#准备工作
CREATE TABLE goods
(
id INT PRIMARY KEY AUTO_INCREMENT,
category_id INT,
category VARCHAR(15),
NAME VARCHAR(30),
price DECIMAL(10, 2),
stock INT,
upper_time DATETIME
);
INSERT INTO goods (category_id, category, NAME, price, stock, upper_time)
VALUES (1, '女装/女士精品', 'Th', 39.90, 1000, '2023-7-23 00:00:00'),
(1, '女装/女士精品', '连衣裙', 79.98, 2500, '2023-7-23 00:00:00'),
(1, '女装/女士精品', '卫衣', 89.98, 1500, '2023-7-23 00:00:00'),
(1, '女装/女士精品', '牛仔裤', 89.98, 3500, '2023-7-23 00:00:00'),
(1, '女装/女士精品', '百智精', 29.98, 500, '2023-7-23 00:00:00'),
(1, '女装/女士精品', '呢绒外套', 399.98, 128, '2023-7-23 00:00:00'),
(2, '户外运动', '自行车', 399.98, 2300, '2023-7-23 00:00:00'),
(2, '户外运动', '山地自行车', 1399.98, 2500, '2023-7-23 00:00:00'),
(2, '户外运动', '连山秋', 59.98, 1599, '2023-7-23 00:00:00'),
(2, '户外运动', '骑行装备', 399.98, 3568, '2023-7-23 00:00:00'),
(2, '户外运动', '运动外套', 799.98, 500, '2023-7-23 00:00:00'),
(2, '户外运动', '滑板', 499.9, 1200, '2023-7-23 00:00:00');
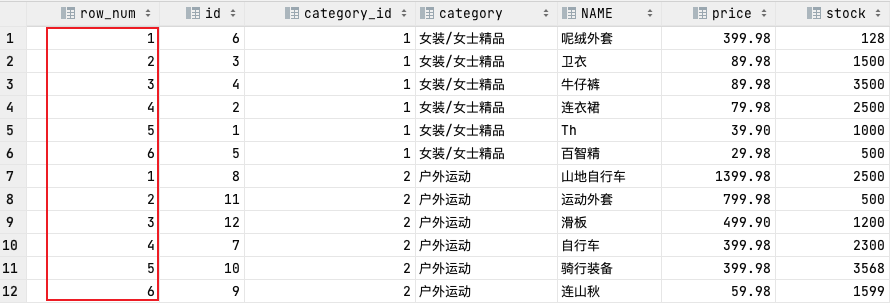
ROW_NUMBER()
## ROW_NUMBER()
# 查询每个商品分类下 再按价格降序排序信息
SELECT ROW_NUMBER() OVER (PARTITION BY category_id ORDER BY price DESC) AS row_num, id, category_id, category, NAME, price, stock
FROM goods;
# 查询每个商品分类下价格最高的3种商品信息
SELECT *
FROM (SELECT ROW_NUMBER() over (PARTITION BY category ORDER BY price DESC) AS row_num, id, category_id, category, NAME, price, stock FROM goods) t
WHERE row_num <= 3;

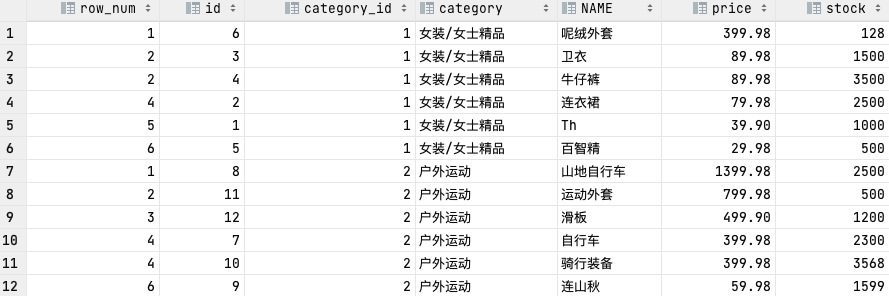
RANK()
# 和 ROW_NUMBER() 区别 当price价格一样时,ROW_NUMBER()返回1,2,3;而 RANK() 返回1,2,2,4
# 获取各个类别的价格从高到低排序
SELECT RANK() OVER (PARTITION BY category_id ORDER BY price DESC) AS row_num, id, category_id, category, NAME, price, stock
FROM goods;
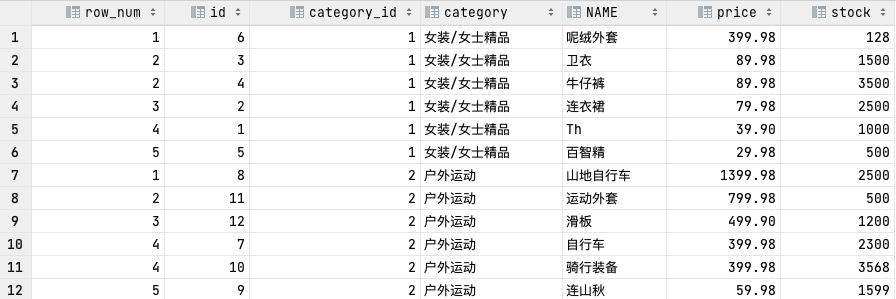
DENSE_RANK()
# 返回的序号不会跳过重复的序号,比如返回1,2,2,3
SELECT DENSE_RANK() OVER (PARTITION BY category_id ORDER BY price DESC) AS row_num, id, category_id, category, NAME, price, stock
FROM goods;
PERCENT_RANK()
## PERCENT_RANK()
# 计算名称为"女装/女士精品"的类别下的商品的PERCENT_RANK值
SELECT RANK() OVER w AS r,
PERCENT_RANK() OVER w AS pr,
id,
category_id,
category,
NAME,
price,
stock
FROM goods
WHERE category_id = 1 WINDOW w AS (PARTITION BY category_id ORDER BY price DESC);
# 写法方式二:
SELECT RANK() OVER (PARTITION BY category_id ORDER BY price DESC) AS r,
PERCENT_RANK() OVER (PARTITION BY category_id ORDER BY price DESC) AS pr,
id,
category_id,
category,
NAME,
price,
stock
FROM goods
WHERE category_id = 1;

CUME_DIST()
# 主要用于查询小于或等于当前价格的比例
SELECT CUME_DIST() OVER (PARTITION BY category_id ORDER BY price DESC) AS row_num, id, category_id, category, NAME, price, stock
FROM goods;
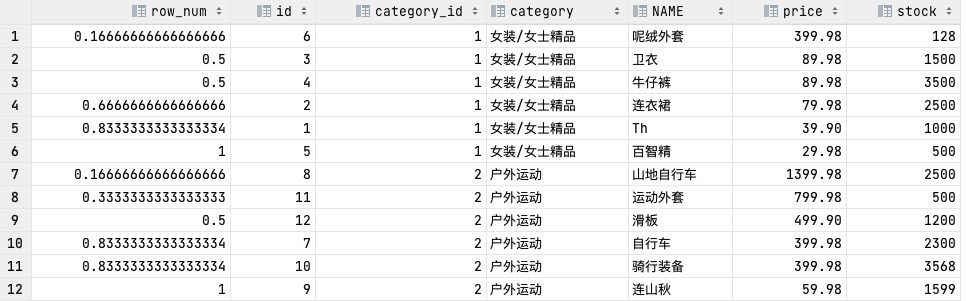
LAG(expr, n)、LEAD(expr, n)
## LAG(expr, n)
# 返回当前行的前n行的expr的值
# 查询前一个商品与当前商品价格的差值
# 之前遇到过一个求历史修改记录差异可以用这个!!!,当时听负责人的加了parent_id
SELECT id,
category_id,
category,
NAME,
price,
price - pre_price AS diff_prive,
pre_price,
pre_id
FROM (SELECT id, category_id, category, NAME, price, LAG(price, 1) OVER (ORDER BY price) AS pre_price, LAG(id, 1) OVER ( ORDER BY price) AS pre_id
FROM goods) t;
## LEAD(expr, n)
# 返回当前行的后n行的expr的值,类似⬆️
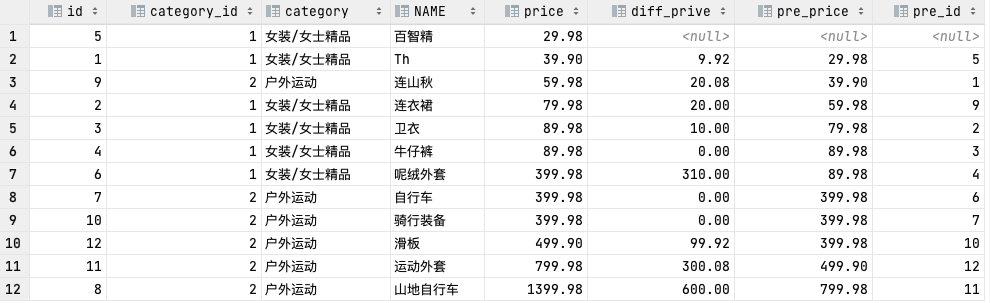
FIRST_VALUE(expr)、LAST_VALUE(expr)
## FIRST_VALUE(expr)
# 返回第一个expr的值
SELECT id, category_id, category, NAME, price, stock, FIRST_VALUE(price) OVER (PARTITION BY category_id ORDER BY price) AS first_price
FROM goods;
## LAST_VALUE(expr)
# 返回最后一个expr的值
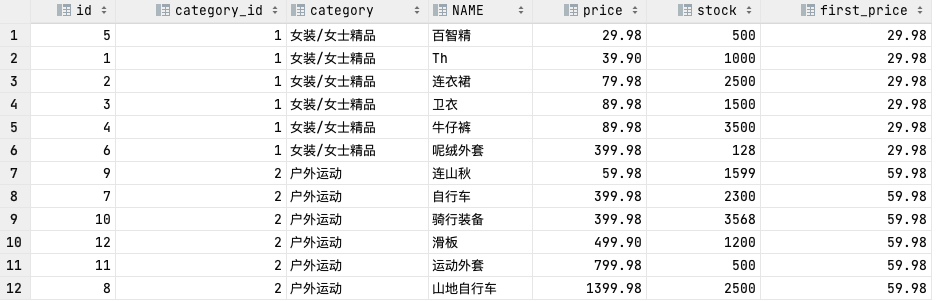
NTH_VALUE(expr, n)
## NTH_VALUE(expr, n)
# 查询排名第2和第3的价格信息
SELECT id,
category,
NAME,
price,
NTH_VALUE(price, 2) OVER (PARTITION BY category_id ORDER BY price) AS second_price,
NTH_VALUE(price, 3) OVER (PARTITION BY category_id ORDER BY price) AS third_price
FROM goods;
NTILE(n)
## NTILE(n) 分为n组
SELECT NTILE(4) OVER (PARTITION BY category_id ORDER BY price DESC) AS row_num, id, category_id, category, NAME, price, stock
FROM goods;
总结
窗口函数的特点是可以分组,而且可以在分组内排序。另外,窗口函数不会因为分组减少原表中的行数,这对我们在原表数据的基础上进行统计和排序非常有用。