数据规模->时间复杂度
<=10^4 😮(n^2)
<=10^7:o(nlogn)
<=10^8:o(n)
10^8<=:o(logn),o(1)
内容

lc 155 【剑指 30】【top100】:最小栈
https://leetcode.cn/problems/min-stack/
提示:
-2^31 <= val <= 2^31 - 1
pop、top 和 getMin 操作总是在 非空栈 上调用
push, pop, top, and getMin最多被调用 3 * 104 次
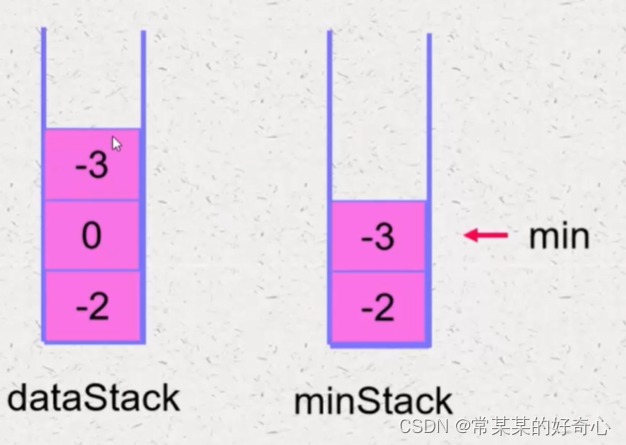
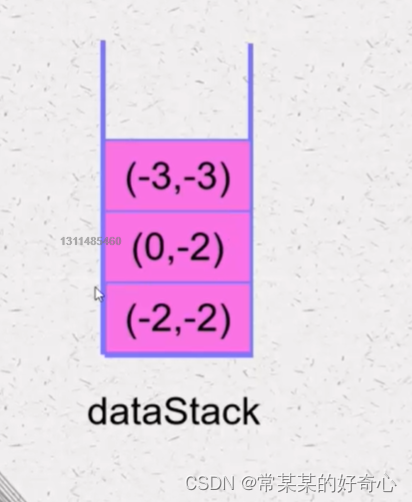

#方案一:两个栈(辅助栈)
class MinStack:
def __init__(self):
self.datastack=[]
self.minstack=[]
def push(self, val: int) -> None:
self.datastack.append(val)
#key:<=
if not self.minstack or val<=self.minstack[-1]:
self.minstack.append(val)
def pop(self) -> None:
top=self.datastack.pop()
#key
if top==self.minstack[-1]:
self.minstack.pop()
def top(self) -> int:
return self.datastack[-1]
def getMin(self) -> int:
return self.minstack[-1]
# Your MinStack object will be instantiated and called as such:
# obj = MinStack()
# obj.push(val)
# obj.pop()
# param_3 = obj.top()
# param_4 = obj.getMin()
#方案二:一个栈-存储节点
class Node:
def __init__(self,val=0,minn=0):
self.val=val
self.min=minn
class MinStack:
def __init__(self):
self.datastack=[]
def push(self, val: int) -> None:
#key:
newnode=Node()
newnode.val=val
if not self.datastack:
newnode.min=val
else:
newnode.min=min(self.datastack[-1].min,val)
#
self.datastack.append(newnode)
def pop(self) -> None:
self.datastack.pop()
def top(self) -> int:
return self.datastack[-1].val
def getMin(self) -> int:
return self.datastack[-1].min
# Your MinStack object will be instantiated and called as such:
# obj = MinStack()
# obj.push(val)
# obj.pop()
# param_3 = obj.top()
# param_4 = obj.getMin()
#方案三:自定义栈-链表结构
class ListNode:
def __init__(self,val=0,minn=0,next=None):
self.val=val
self.min=minn
self.next=next
class MinStack:
def __init__(self):
self.dummynode=ListNode()
def push(self, val: int) -> None:
#key:
newnode=ListNode()
newnode.val=val
if not self.dummynode.next:
newnode.min=val
else:
newnode.min=min(self.dummynode.next.min,val)
#key
newnode.next=self.dummynode.next
self.dummynode.next=newnode
def pop(self) -> None:
firstnode=self.dummynode.next
if firstnode:
self.dummynode.next=firstnode.next
firstnode.next=None
def top(self) -> int:
return self.dummynode.next.val
def getMin(self) -> int:
return self.dummynode.next.min
# Your MinStack object will be instantiated and called as such:
# obj = MinStack()
# obj.push(val)
# obj.pop()
# param_3 = obj.top()
# param_4 = obj.getMin()
lc 225 :用队列实现栈
https://leetcode.cn/problems/implement-stack-using-queues/
注意:
你只能使用队列的基本操作 —— 也就是 push to back、peek/pop from front、size 和 is empty 这些操作。
你所使用的语言也许不支持队列。 你可以使用 list (列表)或者 deque(双端队列)来模拟一个队列 , 只要是标准的队列操作即可。
提示:
1 <= x <= 9
最多调用100 次 push、pop、top 和 empty
每次调用 pop 和 top 都保证栈不为空
进阶:
你能否仅用一个队列来实现栈。
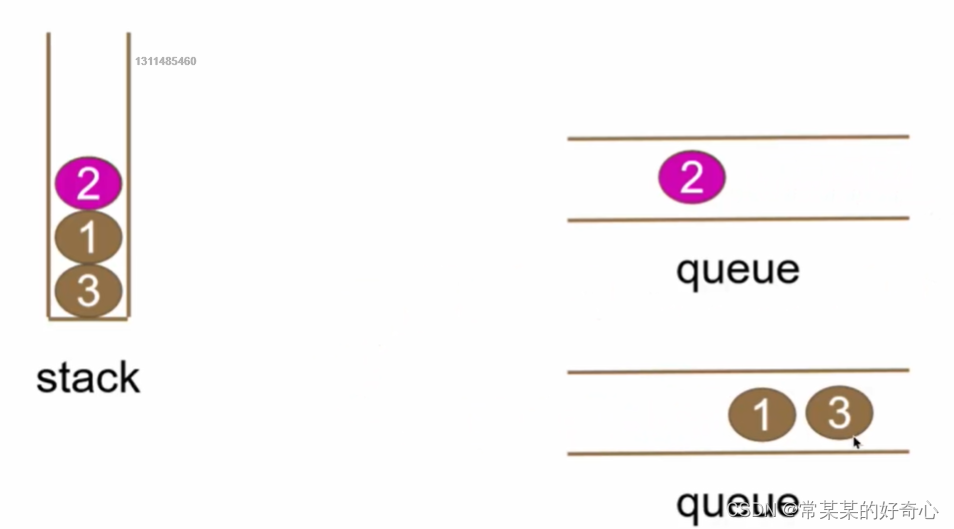


#方案一:两个队列(使用push的调用次数多)
class MyStack:
def __init__(self):
self.queue1=deque()
self.queue2=deque()
def push(self, x: int) -> None:
self.queue1.append(x)
#o(n)
def pop(self) -> int:
#key-key-key:while
if self.queue1:
while(self.queue1):
x=self.queue1.popleft()
if not self.queue1:
return x
self.queue2.append(x)#key位置(最后无head元素)
#
elif self.queue2:
while(self.queue2):
x=self.queue2.popleft()
if not self.queue2:
return x
self.queue1.append(x)#key位置(最后无head元素)
#o(n)
def top(self) -> int:
if self.queue1:
while(self.queue1):
x=self.queue1.popleft()
self.queue2.append(x)#key位置(最后有head元素)
if not self.queue1:
return x
#
elif self.queue2:
while(self.queue2):
x=self.queue2.popleft()
self.queue1.append(x)#key位置(最后有head元素)
if not self.queue2:
return x
def empty(self) -> bool:
return len(self.queue1)==0 and len(self.queue2)==0
# Your MyStack object will be instantiated and called as such:
# obj = MyStack()
# obj.push(x)
# param_2 = obj.pop()
# param_3 = obj.top()
# param_4 = obj.empty()
#方案二:两个队列(优化:适用pop与top的调用次数多)
class MyStack:
def __init__(self):
self.queue1=deque()
self.queue2=deque()
def push(self, x: int) -> None:
#key-key-key:while
self.queue2.append(x)
while(self.queue1):
self.queue2.append(self.queue1.popleft())
self.queue1,self.queue2=self.queue2,self.queue1
def pop(self) -> int:
return self.queue1.popleft()
def top(self) -> int:
return self.queue1[0]
def empty(self) -> bool:
return not self.queue1 and not self.queue2
# Your MyStack object will be instantiated and called as such:
# obj = MyStack()
# obj.push(x)
# param_2 = obj.pop()
# param_3 = obj.top()
# param_4 = obj.empty()
#方案三:一个队列
class MyStack:
def __init__(self):
self.queue1=deque()
def push(self, x: int) -> None:
#key-key-key:123->321
size=len(self.queue1)
self.queue1.append(x)
for i in range(size):
self.queue1.append(self.queue1.popleft())
def pop(self) -> int:
return self.queue1.popleft()
def top(self) -> int:
return self.queue1[0]
def empty(self) -> bool:
return not self.queue1
# Your MyStack object will be instantiated and called as such:
# obj = MyStack()
# obj.push(x)
# param_2 = obj.pop()
# param_3 = obj.top()
# param_4 = obj.empty()
【剑指 09】: 用两个栈实现队列
https://leetcode.cn/problems/yong-liang-ge-zhan-shi-xian-dui-lie-lcof/
提示:
1 <= values <= 10000
最多会对 appendTail、deleteHead 进行 10000 次调用
#方案一:
class CQueue:
def __init__(self):
self.stack1=[]
self.stack2=[]
def appendTail(self, value: int) -> None:
while self.stack2:
self.stack1.append(self.stack2.pop())
self.stack1.append(value)
def deleteHead(self) -> int:
while self.stack1:
self.stack2.append(self.stack1.pop())
if not self.stack2:
return -1
return self.stack2.pop()
# Your CQueue object will be instantiated and called as such:
# obj = CQueue()
# obj.appendTail(value)
# param_2 = obj.deleteHead()
#方案二:优化
class CQueue:
def __init__(self):
self.stack1=[]
self.stack2=[]
def appendTail(self, value: int) -> None:
while self.stack2:
self.stack1.append(self.stack2.pop())
self.stack1.append(value)
def deleteHead(self) -> int:
#key-key-key:stack2已经把stack1的前入元素变成前出元素
if not self.stack2:
while self.stack1:
self.stack2.append(self.stack1.pop())
#
if not self.stack2:
return -1
return self.stack2.pop()
# Your CQueue object will be instantiated and called as such:
# obj = CQueue()
# obj.appendTail(value)
# param_2 = obj.deleteHead()
lc 622 :设计循环队列
提示:
-2^31 <= val <= 2^31 - 1
最多调用 insert、remove 和 getRandom 函数 2 * 105 次
在调用 getRandom 方法时,数据结构中 至少存在一个 元素。
注意:你必须实现类的所有函数,并满足每个函数的 平均 时间复杂度为 O(1)



class MyCircularQueue:
def __init__(self, k: int):
self.k=k
self.data=[None]*(k+1)#k=2,5-None-1为满
self.head=0
self.tail=0#队尾元素下一位
def enQueue(self, value: int) -> bool:
#
if self.isFull():return False
#
self.data[self.tail]=value
self.tail=(self.tail+1)%(self.k+1)
return True
def deQueue(self) -> bool:
#
if self.isEmpty():return False
#
self.data[self.head]=None #可以略去这一行
self.head=(self.head+1)%(self.k+1)
return True
def Front(self) -> int:
if self.isEmpty(): return -1
return self.data[self.head]
def Rear(self) -> int:
if self.isEmpty(): return -1
return self.data[self.tail-1]
def isEmpty(self) -> bool:#key
return self.head==self.tail
def isFull(self) -> bool: #key
return (self.tail+1)%(self.k+1)==self.head
# Your MyCircularQueue object will be instantiated and called as such:
# obj = MyCircularQueue(k)
# param_1 = obj.enQueue(value)
# param_2 = obj.deQueue()
# param_3 = obj.Front()
# param_4 = obj.Rear()
# param_5 = obj.isEmpty()
# param_6 = obj.isFull()
lc 380【剑指 030】:O(1) 时间插入、删除和获取随机元素
https://leetcode.cn/problems/insert-delete-getrandom-o1/
提示:
-2^31 <= val <= 2^31 - 1
最多调用 insert、remove 和 getRandom 函数 2 * 105 次
在调用 getRandom 方法时,数据结构中 至少存在一个 元素。
注意:您必须实现类的函数,使每个函数的 平均 时间复杂度为 O(1) ;
class RandomizedSet:
def __init__(self):
self.idxmap={}
self.data=[]
def insert(self, val: int) -> bool:
if val in self.idxmap:return False #self.idxmap也对
#
self.idxmap[val]=len(self.data)
self.data.append(val)
return True
def remove(self, val: int) -> bool:
#hashset/map:指定data/key->o(1)
#数组:根据随机索引->o(1)
if val not in self.idxmap:return False
#
idx=self.idxmap[val]
lastnum=self.data[-1]
self.data[idx]=lastnum
self.data.pop()
#
self.idxmap[lastnum]=idx
del self.idxmap[val]
return True
def getRandom(self) -> int:
#randint(0,9):0-9
return self.data[random.randint(0,len(self.data)-1)]#choice(self.data)
# Your RandomizedSet object will be instantiated and called as such:
# obj = RandomizedSet()
# param_1 = obj.insert(val)
# param_2 = obj.remove(val)
# param_3 = obj.getRandom()
lc 381 :O(1) 时间插入、删除和获取随机元素 - 允许重复
https://leetcode.cn/problems/insert-delete-getrandom-o1-duplicates-allowed/
提示:
-2^31 <= val <= 2^31 - 1
insert, remove 和 getRandom 最多 总共 被调用 2 * 10^5 次
当调用 getRandom 时,数据结构中 至少有一个 元素
注意:您必须实现类的函数,使每个函数的 平均 时间复杂度为 O(1) ;
生成测试用例时,只有在 RandomizedCollection 中 至少有一项 时,才会调用 getRandom

class RandomizedCollection:
def __init__(self):
self.idsmap=defaultdict(set) #for remove o(1) #list也可以
self.data=[]
def insert(self, val: int) -> bool:
self.idsmap[val].add(len(self.data)) #允许重复插入
self.data.append(val)
return len(self.idsmap[val])==1 #但,重复插入返回False
def remove(self, val: int) -> bool:
if val not in self.idsmap:return False
#
idx=self.idsmap[val].pop()
lastnum=self.data[-1]
self.data[idx]=lastnum
self.data.pop() #注意:此时k->k-1
#key
#idx已经被pop
if len(self.idsmap[val])==0:
del self.idsmap[val]
if idx<len(self.data):#只有val!=lastnum,才有更新必要
self.idsmap[lastnum].remove(len(self.data))
self.idsmap[lastnum].add(idx)
return True
def getRandom(self) -> int:
return choice(self.data)
# Your RandomizedCollection object will be instantiated and called as such:
# obj = RandomizedCollection()
# param_1 = obj.insert(val)
# param_2 = obj.remove(val)
# param_3 = obj.getRandom()
缓存机制:三种数据淘汰机制
key:数据Cache【HashMap】+存储顺序【队列/双向链表】
FIFO 缓存机制
FIFO Cache 代码实现


# class LocalCache:
# def __init__(self):
# self.cache = dict()
# def get(self, key):
# return self.cache[key]
# def put(self, key, value):
# self.cache[key] = value
class FIFOCache:
def __init__(self,capacity):
self.queue=deque() #key:存键的顺序
self.cache={} #dict()
self.capacity=capacity
def get(self,key):
if key in self.cache:
return self.cache[key]
return None
def put(self,key,value):#key-put、change一个逻辑
#存在->改值
#不存在->判满->添加
if key not in self.cache:
#
if len(self.cache)==self.capacity:
del self.cache[self.queue.popleft()]
#
self.queue.append(key)
self.cache[key]=value
lc 146【剑指 031】【top100】:LRU 缓存机制
https://leetcode.cn/problems/lru-cache/
提示:
1 <= capacity <= 3000
0 <= key <= 10000
0 <= value <= 10^5
最多调用 2 * 10^5 次 get 和 put
注意:函数 get 和 put 必须以 O(1) 的平均时间复杂度运行
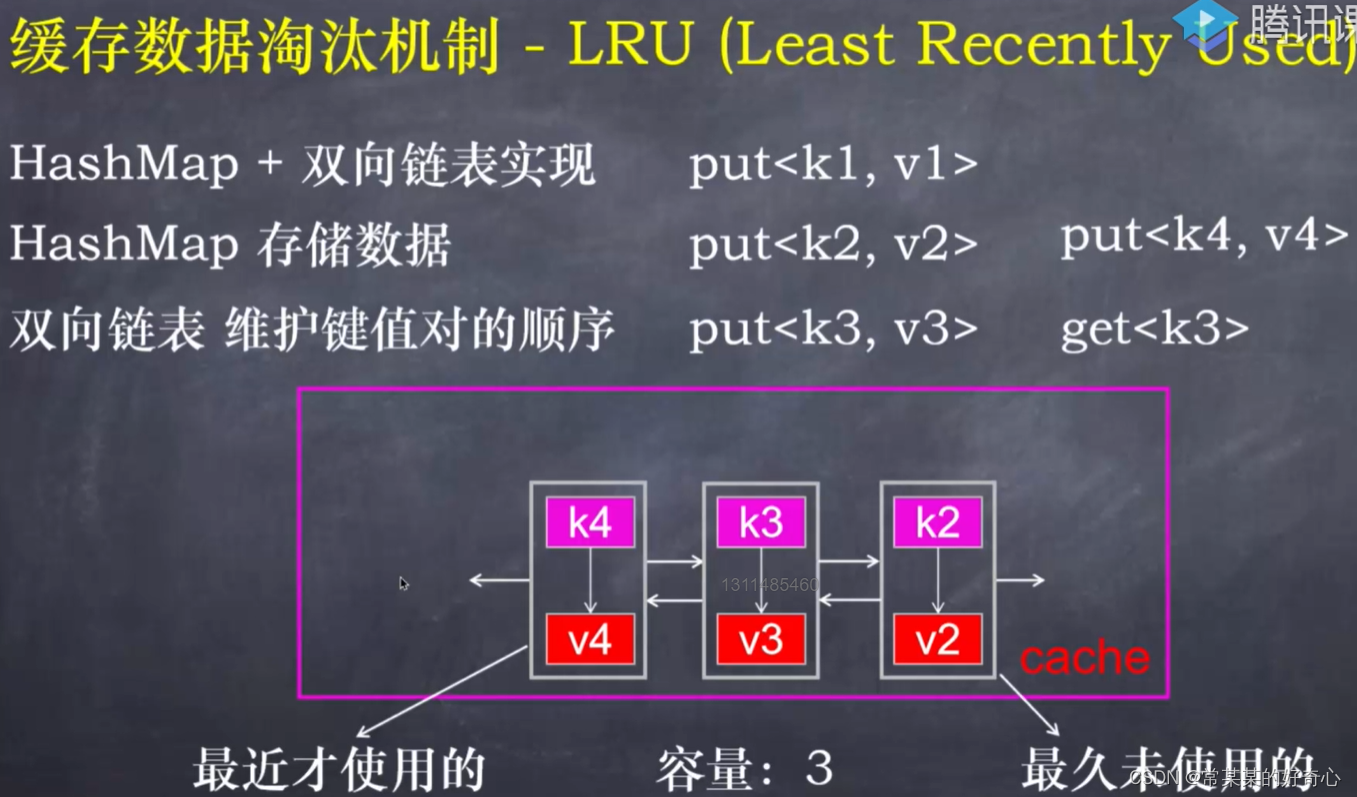
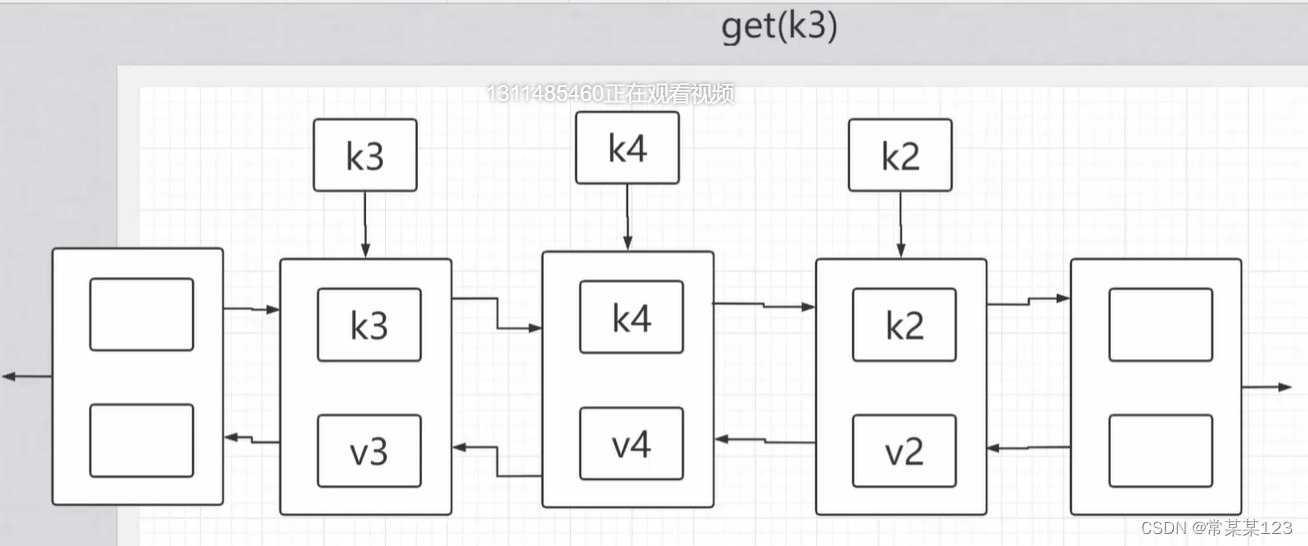
#map+双向链表
#时间:近->久
class Node:
def __init__(self,key=0,value=0,next=None,prev=None):
self.key=key
self.val=value
self.next=next
self.prev=prev
class LRUCache:
def __init__(self, capacity: int):
#key:维护时间顺序
self.dummyhead=Node()
self.dummytail=Node()
self.dummyhead.next=self.dummytail
self.dummytail.prev=self.dummyhead
#
self.cache={}
self.capacity=capacity
def get(self, key: int) -> int:
if key not in self.cache:return -1
#
node=self.cache[key]
#key
self.move_node_to_head(node)
return node.val
def put(self, key: int, value: int) -> None:
if key not in self.cache:
#判满
if len(self.cache)==self.capacity:
del_node=self.remove_tailnode()
del self.cache[del_node.key] #或者self.cache.pop(node.key)
#
putnode=Node()
putnode.key=key
putnode.val=value
self.to_head(putnode)
self.cache[key]=putnode
else:
self.cache[key].val=value
self.move_node_to_head(self.cache[key])
def move_node_to_head(self,node):
self.move_node(node)
self.to_head(node)
def move_node(self,node):
prevnode,nextnode=node.prev,node.next
#
node.prev=None
node.next=None
prevnode.next=nextnode
nextnode.prev=prevnode
def to_head(self,node):
node1=self.dummyhead.next
self.dummyhead.next=node
node.prev=self.dummyhead
node.next=node1
node1.prev=node
def remove_tailnode(self):
del_node=self.dummytail.prev
self.move_node(del_node)
return del_node
# Your LRUCache object will be instantiated and called as such:
# obj = LRUCache(capacity)
# param_1 = obj.get(key)
# obj.put(key,value)
lc 460 :LFU 缓存
https://leetcode.cn/problems/lfu-cache/
提示:
0 <= capacity <= 10^4
0 <= key <= 10^5
0 <= value <= 10^9
最多调用 2 * 10^5 次 get 和 put 方法
注意:函数 get 和 put 必须以 O(1) 的平均时间复杂度运行

#map+双向链表
#次数同:久->近
#cache元:key->Node(key,val,count)
#计数维护元:count->doublelinkedNode
class Node:
def __init__(self, key=None,val =None,count =None):
self.key = key
self.val = val
self.count = count
#
self.next = None
self.prev = None
class DoubleLinkedNode:
def __init__(self):
self.dummyhead = Node()
self.dummytail = Node()
self.dummyhead.next = self.dummytail
self.dummytail.prev = self.dummyhead
def remove(self, node) -> Node:
prevnode,nextnode=node.prev,node.next
prevnode.next = nextnode
nextnode.prev = prevnode
#
node.prev = None
node.next = None
return node
#拼到表尾
def append(self, node):
prevnode = self.dummytail.prev
prevnode.next=node
node.prev=prevnode
node.next = self.dummytail
self.dummytail.prev = node
def pop_first(self) -> Node:
if self.dummyhead.next == self.dummytail:
return None
return self.remove(self.dummyhead.next)
def is_empty(self) -> bool:
return self.dummyhead.next == self.dummytail
class LFUCache:
def __init__(self, capacity: int):
self.used_count_to_nodes = collections.defaultdict(DoubleLinkedNode)
self.cache = {}
#
self.capacity = capacity
self.min_used_count = 0
def get(self, key: int) -> int:
if key not in self.cache:return -1
node=self.cache[key]
######################count的维护和cache的count更新
count=node.count
#node.count=count+1 #注意;如果放在这里,node的属性改变,后面remove(node)不通
self.used_count_to_nodes[count].remove(node)
if self.min_used_count==count and self.used_count_to_nodes[count].is_empty():#涉及最小值的更新
self.min_used_count+=1
self.used_count_to_nodes[count+1].append(node)
node.count=count+1
#
return node.val
def put(self, key: int, value: int) -> None:
if self.capacity == 0: return -1 #注意:此时,del_node(dummytail).key不存在
if key not in self.cache:
#判满
if len(self.cache)==self.capacity:
del_node=self.used_count_to_nodes[self.min_used_count].pop_first()
del self.cache[del_node.key] #key
#
putnode=Node(key,value,1)
self.cache[key]=putnode
#
self.used_count_to_nodes[1].append(putnode)
self.min_used_count=1
else:
node=self.cache[key]
node.val=value
#self.cache[key]=node
self.get(key)#key:还差count的维护和cache的count的更新
# Your LFUCache object will be instantiated and called as such:
# obj = LFUCache(capacity)
# param_1 = obj.get(key)
# obj.put(key,value)
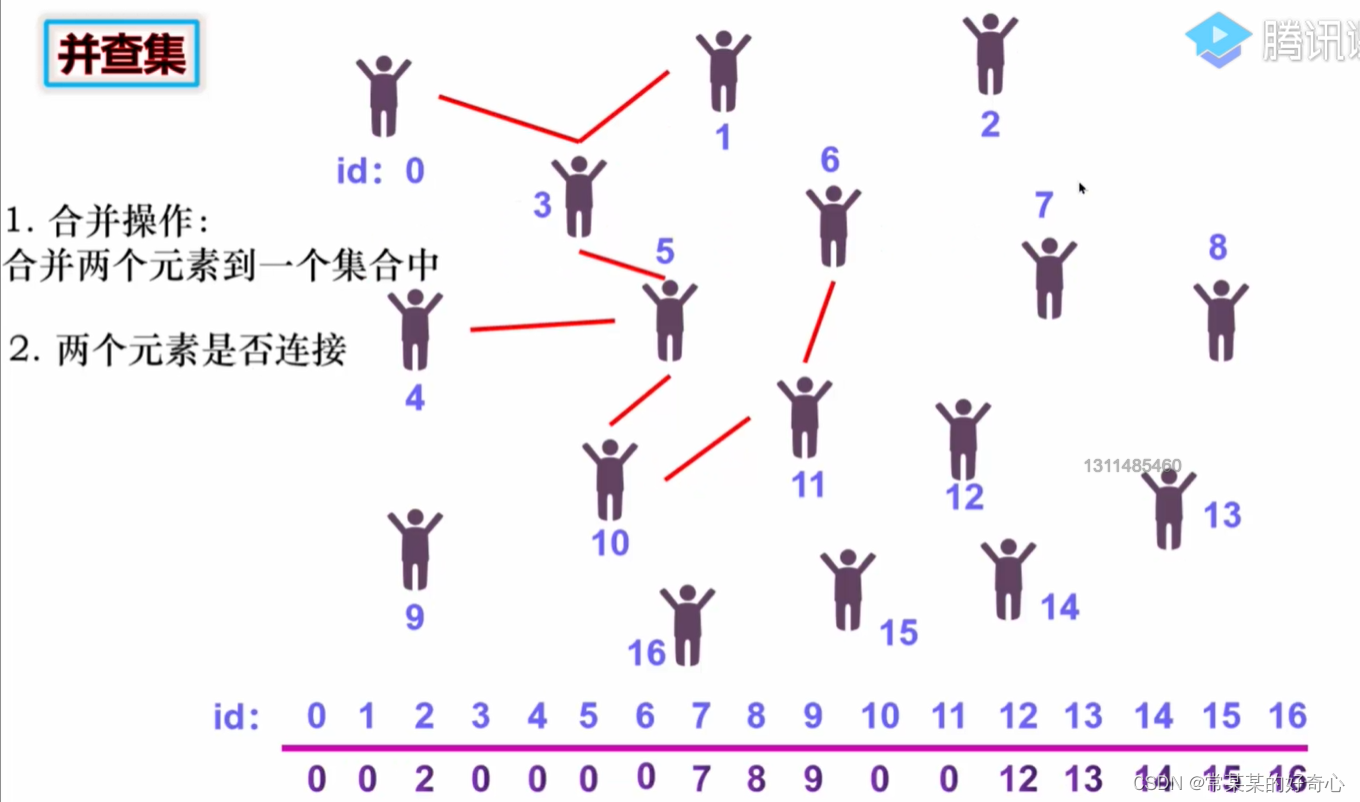
并查集
并查集解决的问题:连接问题
并查集需要支持的两个操作:
使用数组实现并查集(数组的顺序访问的话,JVM会优化,CPU)
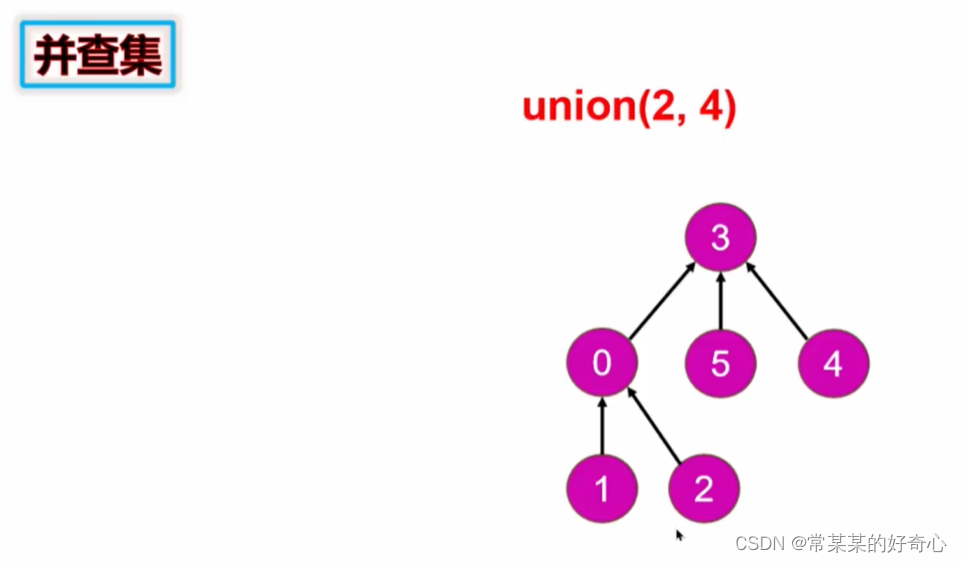
树形结构实现并查集 (优化:降低合并的时间复杂度)
使用数组实现并查集
树形结构实现并查集:
并查集优化
基于size(总节点数)优化1:缺点-依然可能增加层数,从而增大时间复杂度
基于rank(总层数)优化(+路径压缩)2:


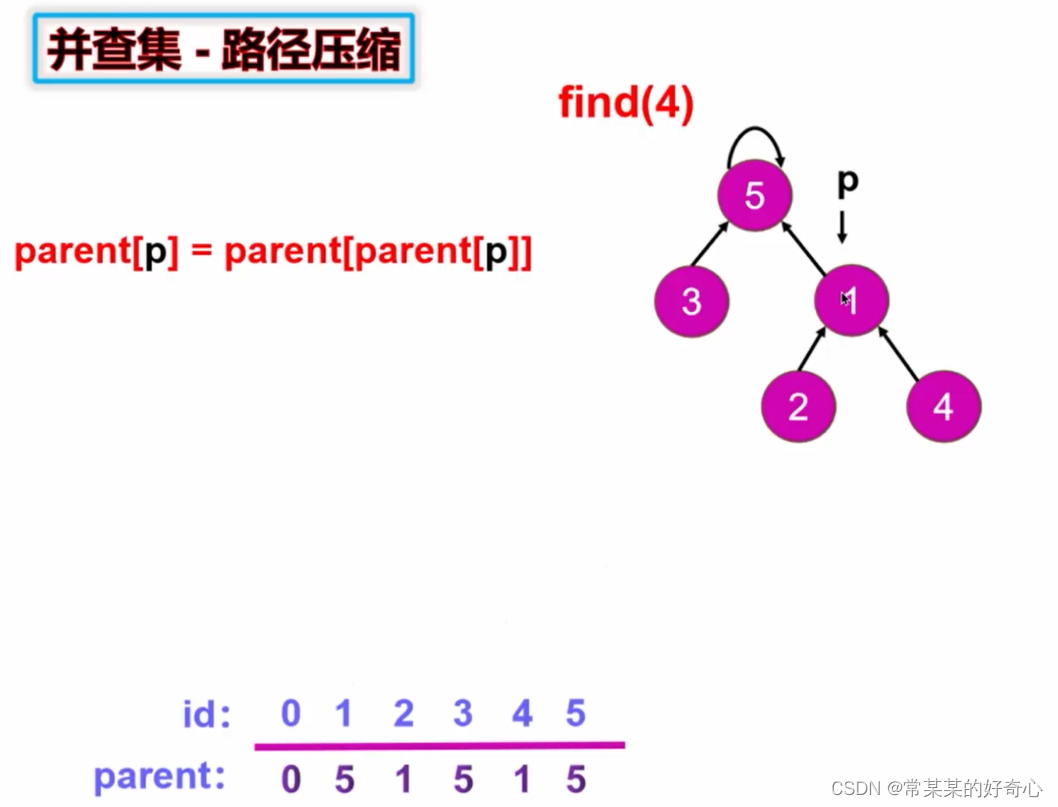
class UnionFind:
def __init__(self, capacity):
self.parent=[0]*capacity
self.rank=[0]*capacity
#初始化
for i in range(capacity):
self.parent[i]=i
self.rank[i]=1
def find(self, p):
if p<0 or p>=len(self.parent):
raise Exception('p out the range')
#写法1:迭代
while (p != self.parent[p]):
self.parent[p]=slef.parent[slef.parent[p]]#key:路径压缩
p=self.parent[p]
return p
# #写法2:递归
# if p==self.parent[p]:return self.parent[p]
# self.parent[p]=self.find[self.parent[p]]#key:路径压缩
# return parent[p]
def is_connected(self, p, q):
return self.find[p]==self.find[q]
#难点
def union_element(self, p, q):
proot,qroot=self.find[p],self.find[q]
if proot==qroot:return
if self.rank[proot]<self.rank[qroot]:
self.parent[proot]=qroot
elif self.rank[proot]>self.rank[qroot]:
self.parent[qroot]=proot
else:
self.parent[proot]=qroot
self.rank[qroot]+=1
lc 547【剑指 116】:省份数量
https://leetcode.cn/problems/number-of-provinces/
提示:
1 <= n <= 200
n == isConnected.length
n == isConnected[i].length
isConnected[i][j] 为 1 或 0
isConnected[i][i] == 1
isConnected[i][j] == isConnected[j][i]
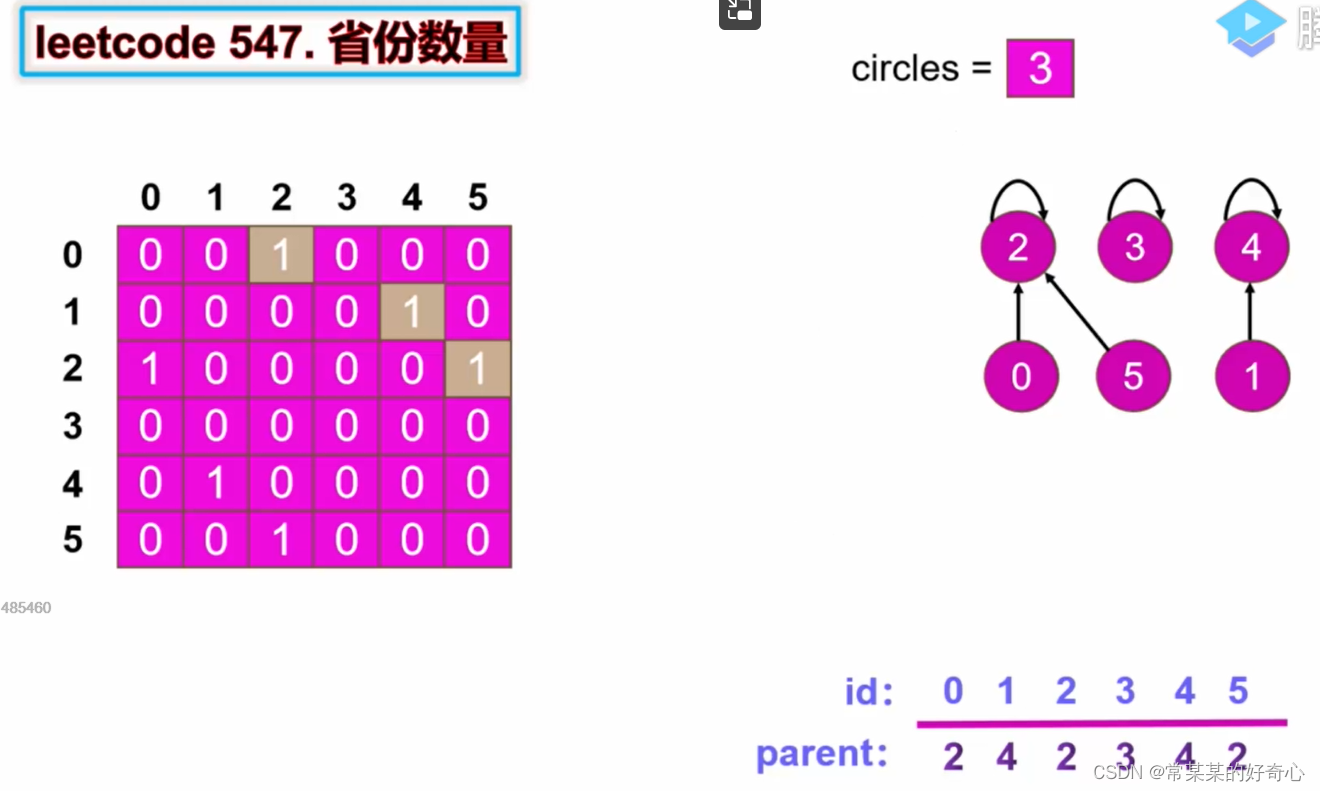
class Solution:
def findCircleNum(self, isConnected: List[List[int]]) -> int:
rows=len(isConnected)
cols=len(isConnected[0])
#
uf=UnionFind(rows)
for i in range(rows):
for j in range(i+1,cols): #右对角
if isConnected[i][j]==1:
uf.union_element(i,j)
#
return uf.getcicles()
class UnionFind:
def __init__(self, capacity):
self.parent=[0]*capacity
self.rank=[0]*capacity
#初始化
self.cycles=0
for i in range(capacity):
self.parent[i]=i
self.rank[i]=1
#key假设省份:最多的状态
self.cycles+=1
def find(self, p):
while p!=self.parent[p]:
self.parent[p]=self.parent[self.parent[p]]#路径压缩
p=self.parent[p]
return self.parent[p]
def is_connected(self, p, q):
return slef.find(p)==self.find(q)
def union_element(self, p, q):
proot,qroot=self.find(p),self.find(q)
if proot==qroot:return
if self.rank[proot]<self.rank[qroot]:
self.parent[proot]=qroot
elif self.rank[proot]>self.rank[qroot]:
self.parent[qroot]=proot
else:
self.parent[proot]=qroot
self.rank[qroot]+=1
#key每合并一次代表少一个省份
self.cycles-=1
def getcicles(self):
return self.cycles
lc 200【top100】:岛屿数量
https://leetcode.cn/problems/number-of-islands/
提示:
m == grid.length
n == grid[i].length
1 <= m, n <= 300
grid[i][j] 的值为 ‘0’ 或 ‘1’
class Solution:
def numIslands(self, grid: List[List[str]]) -> int:
self.rows=len(grid)
self.cols=len(grid[0])
self.dirs=[[-1,0],[1,0],[0,1],[0,-1]]
#
uf=UnionFind(grid)
for i in range(self.rows):
for j in range(self.cols):
#key:在‘岛屿’中统计,区别于LC547省份数量
if grid[i][j]=='1':
grid[i][j]='0'
for d in self.dirs:
nexti,nextj=i+d[0],j+d[1]
if self.inarea(nexti,nextj) and grid[nexti][nextj]=='1':
uf.union_element(i*self.cols+j,nexti*self.cols+nextj)
#
return uf.getcicles()
def inarea(self,row,col):
return 0<=row<self.rows and 0<=col<self.cols
class UnionFind:
def __init__(self, grid):
rows=len(grid)
cols=len(grid[0])
self.parent=[0]*(rows*cols)
self.rank=[0]*(rows*cols)
#key初始化
self.cycles=0
for i in range(rows):
for j in range(cols):
#key:在‘岛屿’中统计,区别于LC547省份数量
if grid[i][j]=='1':
self.parent[i*cols+j]=i*cols+j
self.rank[i*cols+j]=1
#key假设省份:最多的状态
self.cycles+=1
def find(self, p):
while p!=self.parent[p]:
self.parent[p]=self.parent[self.parent[p]]#路径压缩
p=self.parent[p]
return self.parent[p]
def is_connected(self, p, q):
return slef.find(p)==self.find(q)
def union_element(self, p, q):
proot,qroot=self.find(p),self.find(q)
if proot==qroot:return
if self.rank[proot]<self.rank[qroot]:
self.parent[proot]=qroot
elif self.rank[proot]>self.rank[qroot]:
self.parent[qroot]=proot
else:
self.parent[proot]=qroot
self.rank[qroot]+=1
#key每合并一次代表少一个省份
self.cycles-=1
def getcicles(self):
return self.cycles
lc 721 :账户合并
https://leetcode.cn/problems/accounts-merge/
提示:
1 <= accounts.length <= 1000
2 <= accounts[i].length <= 10
1 <= accounts[i][j].length <= 30
accounts[i][0] 由英文字母组成
accounts[i][j] (for j > 0) 是有效的邮箱地址
注意:
合并账户后,按以下格式返回账户:每个账户的第一个元素是名称,其余元素是 按字符 ASCII 顺序排列 的邮箱地址。账户本身可以以 任意顺序 返回。

class Solution:
def accountsMerge(self, accounts: List[List[str]]) -> List[List[str]]:
#1)建立Map映射-index
email_to_index,email_to_name={},{}
index=0
for account in accounts:
name=account[0]
for i in range(1,len(account)):
if account[i] not in email_to_index:
email_to_index[account[i]]=index
index+=1
email_to_name[account[i]]=name
#2)建立并查集-index
uf=UnionFind(index)#非重复总邮件数
for account in accounts:
firstindex=email_to_index[account[1]]
for i in range(2,len(account)):
nextindex=email_to_index[account[i]]
uf.union_element(firstindex,nextindex)
#3)合并账户->index
rootindex_to_emails=collections.defaultdict(list)
for email,index in email_to_index.items():
rootindex=uf.find(index)
rootindex_to_emails[rootindex].append(email)
#4)合并账户->name
name_to_emails=list()
for emails in rootindex_to_emails.values():
name_to_emails.append([email_to_name[emails[0]]]+sorted(emails))
return name_to_emails
class UnionFind:
def __init__(self, capacity):
self.parent = [0] * capacity
self.rank = [0] * capacity
for i in range(capacity):
self.parent[i] = i
self.rank[i] = 1
def find(self, p):
if p < 0 or p >= len(self.parent):
raise Exception("p 超出了范围")
while p != self.parent[p]:
self.parent[p] = self.parent[self.parent[p]]
p = self.parent[p]
return p
def is_connected(self, p, q):
return self.find(p) == self.find(q)
def union_element(self, p, q):
p_root, q_root = self.find(p), self.find(q)
if p_root == q_root:
return
if self.rank[p_root] < self.rank[q_root]:
self.parent[p_root] = q_root
elif self.rank[p_root] > self.rank[q_root]:
self.parent[q_root] = p_root
else:
self.parent[q_root] = p_root
self.rank[p_root] += 1