25年4月来自香港中文大学和浙大的论文“ADGaussian: Generalizable Gaussian Splatting for Autonomous Driving with Multi-modal Inputs”。
提出 ADGaussian 方法,用于可泛化的街道场景重建。所提出的方法能够从单视图输入实现高质量渲染。与之前主要关注几何细化的 gaussian Splatting 方法不同,其强调联合优化图像和深度特征以实现准确的高斯预测的重要性。为此,首先将稀疏 LiDAR 深度作为一种额外的输入模态,将高斯预测过程制定为视觉信息和几何线索的联合学习框架。此外,提出一种多模态特征匹配策略,结合多尺度高斯解码模型,以增强多模态特征的联合细化,从而实现高效的多模态高斯学习。在两个大规模自动驾驶数据集 Waymo 和 KITTI 上进行的大量实验表明, ADGaussian 实现最先进的性能,并在新视图转换中表现出卓越的零样本泛化能力。
最近,3D Gaussian Splatting (3DGS) [14] 因其实时渲染速度和高质量输出而在 3D 场景重建和新视图合成领域引起了广泛关注。一个关键应用是从图像序列建模街道场景,这在自动驾驶等领域起着至关重要的作用。
在对城市场景进行建模时,一些方法遵循逐场景优化技术 [4, 17, 48],尤其是 Street-Gaussians [38],它将动态城市街道表示为一组配备语义逻辑和 3D 高斯的点云。虽然逐场景优化方法在高质量重建方面表现出色,但它往往难以应对昂贵的训练成本和大范围的新视图合成。
为了实现可泛化的街道场景重建,大多数现有方法都建立在 Pix-elSplat [3] 或 MVSplat [6] 的架构之上。例如,GGRt [19] 引入一种无姿势架构来迭代更新多视图深度图,随后基于 PixelSplat 估计高斯基元。同样,GGS [9] 通过集成多视图深度细化模块增强 MVSplat 的深度估计。
尽管如此,基于多视图特征匹配的深度估计,可能会在无纹理区域和反射表面等具有挑战性的条件下失败。为了解决这个问题,并行工作 DepthSplat [36] 将 Depth Anything V2 [40] 中预训练的深度特征与多视图深度估计相结合,以实现准确的深度回归,其中估计的深度特征进一步用于高斯预测。鉴于 Depth Anything V2 强大的泛化能力,将 DepthSplat 扩展到城市街道场景是合理的。然而,DepthSplat 在应用于这些环境时面临特定的限制。首先,视觉渲染质量受到预训练深度模型的有效性限制。此外,即使在深度质量较高的情况下,直接将图像和深度特征连接起来进行高斯预测也会导致在复杂的自动驾驶情况下视觉重建不令人满意(如图所示)。
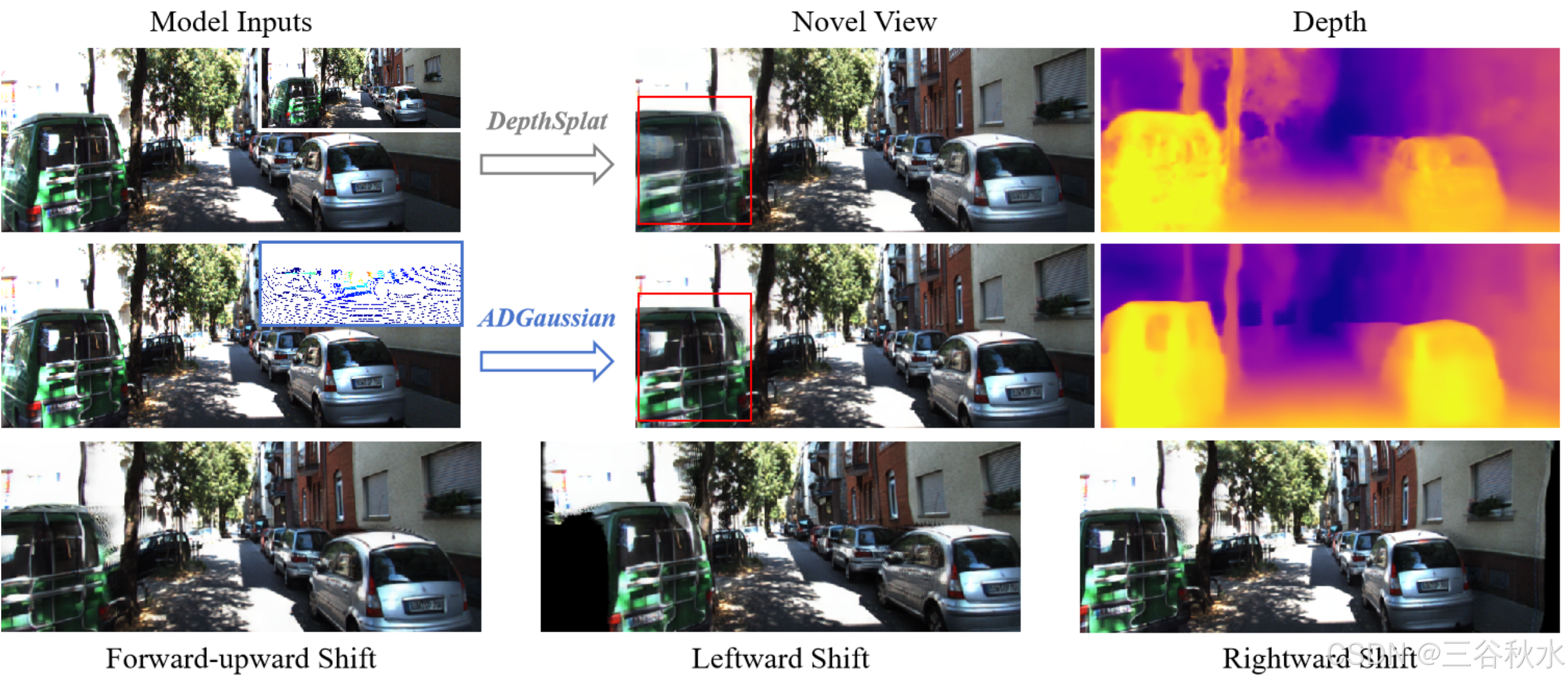
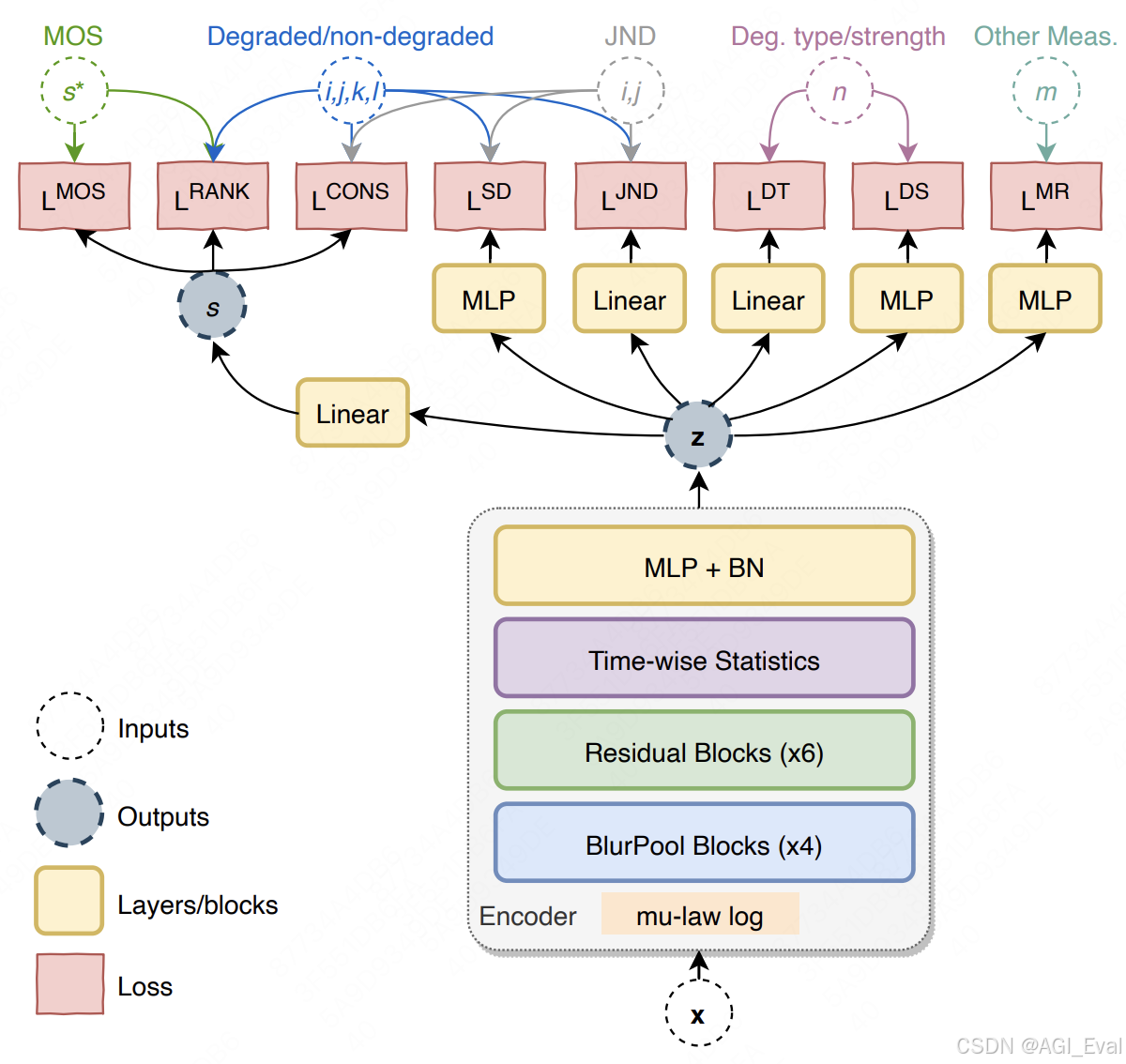
为此,提出一种多模态表示框架 ADGaussian,如上图所示,旨在增强街道场景中的几何建模和视觉渲染。
深度基础模型 [1、2、39、40、42] 已被集成到Gaussian Splatting 中以改进几何重建。然而,由于光度和几何线索之间的相互作用不足,这种框架的渲染质量往往不理想。为了解决这个问题,提出 ADGaussian,这是一种同步多模态优化架构,它将稀疏深度数据与单目图像相结合,以增强街景建模。
Gaussian Splatting 的深度基础模型
最近,DepthSplat 等工作已经研究使用预训练的深度基础模型进行图像条件 3D 高斯重建的优势,并充分利用其在各种真实世界数据集中的出色性能。所有这些方法都利用预训练的单目深度特征来增强最终的深度估计,从而提高高斯渲染的质量。
例如,DepthSplat 使用两个并行分支处理多视图图像 {Ii} 以提取密集的每像素深度。一个分支专注于从多视图输入中建模成本体的特征 Ci,而另一个分支采用预训练的单目深度主干,特别是 Depth Anything V2,以获得单目深度特征 F^i_mono。随后,将每视图成本体和单目深度特征连接起来进行 3D 高斯预测。
直观地说,这种模型可以轻松适应城市场景。尽管如此,重建的有效性在很大程度上取决于预训练的深度基础模型的性能,导致不同街道数据集和场景的准确性不一致。此外,图像和深度特征的处理总是在每个视图中并行进行,没有任何信息共享或同步优化,这限制了模型的学习能力。
多模态特征匹配
这里找到一种有效的方法,将稀疏的 LiDAR 深度集成到 Gaussian Splatting 中,充分利用多模态特征。为此,提出了一种针对城市场景定制的多模态特征匹配架构,以实现稀疏深度信息和彩色图像数据的同步集成。在此过程中,深度引导位置嵌入将深度线索纳入位置嵌入,增强 3D 空间感知并提高多模态上下文理解。
多模态特征匹配。如图所示,模型的核心是图像中的光度特征和深度数据几何线索的多模态特征匹配。这是通过 Siamese 式编码器和信息交叉注意解码器实现的,灵感来自 DUSt3R 系列 [18, 30]。
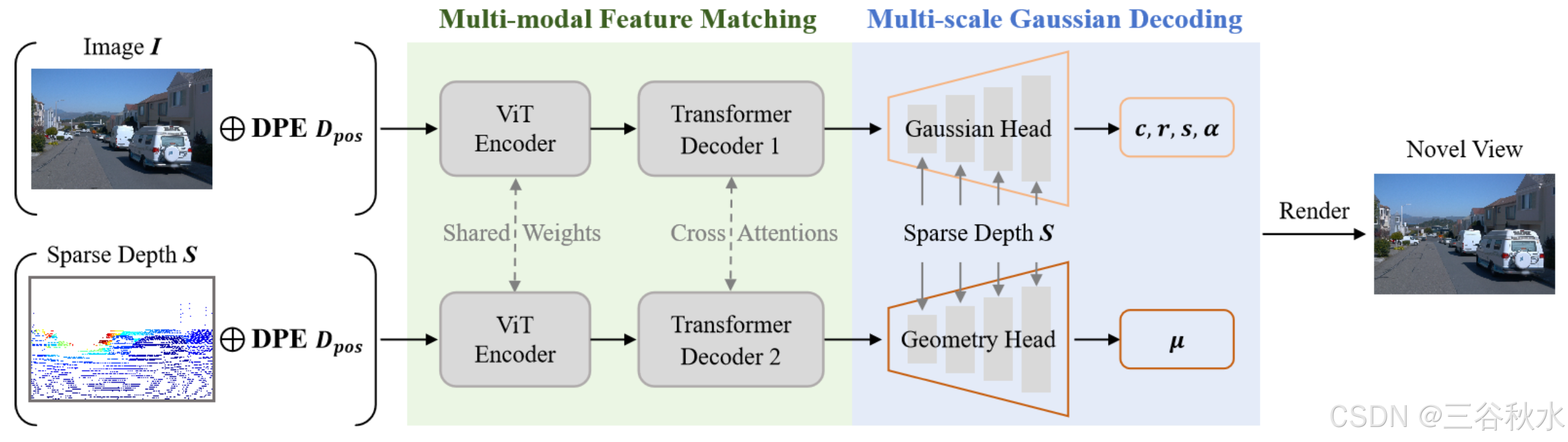
具体来说,单目图像 I 和同步稀疏深度图 S 以 Siamese 配置输入权重共享 ViT 编码器,产生两个 token 表示 F_I 和 F_S 。两个相同的编码器以权重共享的方式协作处理多模态特征,从而实现相似特征的自动学习。
之后,配备交叉注意的 Transformer 解码器用于增强两个多模态分支之间的信息共享和同步优化。此步骤对于生成融合良好的多模态特征图至关重要。
深度引导位置嵌入 (DPE)。 Vision Transformers 中的传统位置嵌入对 2D 图像平面上的相对或绝对空间位置进行编码,以确保图像内的空间感知。然而,仅仅依靠 2D 图像平面的几何特性不足以实现同步多模态设计。为此,提出一种直接的深度引导位置嵌入 (DPE),将深度位置与基于图像的空间位置相结合。具体而言,给定下采样的图像和稀疏深度图,首先将 2D 空间位置网格展平为 1D 矢量,其中每个元素对应于图像中的特定空间位置。随后,对稀疏深度图进行下采样以匹配图像分辨率,从而生成一组独立的深度索引来补充空间位置。最终的位置嵌入 D_pos 是通过将展平的空间位置与深度位置连接起来构建的,从而有效地在 xy-z 平面中编码位置信息。通过整合空间和深度几何,该模块为有效的多模态特征匹配提供了全面的位置先验。
多尺度高斯解码
给定多模态 token G_I 和 G_S,目标是预测像素对齐的高斯参数 {(μ, α, Σ, c)},其中 μ、α、Σ 和 c 是 3D 高斯的中心位置、不透明度、协方差和颜色信息。为了充分利用图像 token G_I 和深度 token G_S 提供的外观线索和几何先验,实现两个具有相同架构的独立回归头,即高斯头和几何头,以生成不同的高斯参数。
两个回归头遵循 DPT [22] 架构,并通过额外的多尺度深度编码增强,为高斯预测提供精确的尺度先验。具体而言,在 DPT 解码器中的每个尺度上,最初调整输入稀疏深度图的大小以与当前特征尺度的空间大小对齐。之后,调整过大小的深度图,通过由两个卷积层组成的浅层网络进行处理,以提取深度特征,然后将其添加到 DPT 中间特征中。最后,输入图像和深度图(每个都由单个卷积层处理)分别合并到高斯头和几何头的最终特征中,以促进基于外观或基于几何的高斯解码。
训练损失
模型使用视图合成损失和深度损失的组合进行训练。
新视图合成损失。用渲染和真值图像颜色之间的均方误差 (MSE) 和 LPIPS 损失的组合来训练完整模型。
深度损失。利用深度损失来平滑相邻像素的深度值,从而最大限度地减少小区域的突然变化。
数据集。在两个广泛使用的自动驾驶数据集上评估提出的方法:Waymo 开放数据集 [24] 和 KITTI 跟踪基准 [8]。对于这两个数据集,采用大约 1:7 的训练-测试分割比。具体来说,在 Waymo 数据集上,主要关注静态和动态场景,其中每种场景类型分为 4 个测试场景和 28 个训练场景。同样,对于 KITTI 数据集,分割由 5 个测试场景和 37 个训练场景组成。这种划分确保方法在不同场景中的平衡评估,同时也为有效的模型训练提供足够的训练数据。
训练细节。实现基于 Py-Torch 框架。采用 Adam [16] 优化器和余弦学习率策略,初始学习率为 1e-4。在 3090 Ti GPU 上训练模型,在 Waymo 和 KITTI 数据集上均运行 150k 次迭代,批量大小为 1。为了确保公平比较,所有实验均在 Waymo 数据集分辨率为 320×480 图像和 KITTI 数据集分辨率为 256×608 图像进行。