1. 介绍

- Batch Norm: 对
NHW计算归一化参数(均值和方差),总共得到C组归一化参数, 相当于对每个channel进行归一化。BN主要缺点是对batchsize的大小比较敏感,由于每次计算均值和方差是在一个batch上,所以如果batchsize太小,则计算的均值、方差不足以代表整个数据分布 - Layer Norm: 对
CHW计算归一化参数,得到N(batch)组归一化参数,对于Batch为1,相当于对整个Feature map 做归一化。主要对RNN及Transformer作用明显,不适应输入变化很大的数据,大Batch较差 - Instance Norm: 对
HW计算归一化参数,总共输出N*C组归一化参数,相当于对每个channel和每个Batch都需要进行归一化。优点:适用图像风格迁移,缺点:不适应通道之间的相关性较强数据。 - **GroupNorm:**将channel方向分group,然后每个group内做归一化,算(C//G)HW的均值;这样与batchsize无关,不受其约束
1.1 BatchNorm
torch.nn.BatchNorm1d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
torch.nn.BatchNorm3d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
参数:
- num_features: 来自期望输入的特征数,该期望输入的大小为’batch_size x num_features [x width]’
- eps: 为保证数值稳定性(分母不能趋近或取0),给分母加上的值。默认为1e-5。
- momentum: 动态均值和动态方差所使用的动量。默认为0.1。
- affine: 布尔值,当设为true,给该层添加可学习的仿射变换参数。
- track_running_stats:布尔值,当设为true,记录训练过程中的均值和方差;
实现公式:

1.2 GroupNorm
torch.nn.GroupNorm(num_groups, num_channels, eps=1e-05, affine=True)
参数:
num_groups:需要划分为的groupsnum_features: 来自期望输入的特征数,该期望输入的大小为’batch_size x num_features [x width]’eps: 为保证数值稳定性(分母不能趋近或取0),给分母加上的值。默认为1e-5。momentum: 动态均值和动态方差所使用的动量。默认为0.1。affine: 布尔值,当设为true,给该层添加可学习的仿射变换参数。
实现公式:

1.3 InstanceNorm
torch.nn.InstanceNorm1d(num_features, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
torch.nn.InstanceNorm2d(num_features, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
torch.nn.InstanceNorm3d(num_features, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
参数:
- num_features: 来自期望输入的特征数,该期望输入的大小为’batch_size x num_features [x width]’
- eps: 为保证数值稳定性(分母不能趋近或取0),给分母加上的值。默认为1e-5。
- momentum: 动态均值和动态方差所使用的动量。默认为0.1。
- affine: 布尔值,当设为true,给该层添加可学习的仿射变换参数。
- track_running_stats:布尔值,当设为true,记录训练过程中的均值和方差;
实现公式:

1.4 LayerNorm
torch.nn.LayerNorm(normalized_shape, eps=1e-05, elementwise_affine=True)
参数:
- normalized_shape: 输入尺寸
- [∗×normalized_shape[0]×normalized_shape[1]×…×normalized_shape[−1]]
- eps: 为保证数值稳定性(分母不能趋近或取0),给分母加上的值。默认为1e-5。
- elementwise_affine: 布尔值,当设为true,给该层添加可学习的仿射变换参数。
实现公式:

2. Batch Normalization
Ioffe S, Szegedy C. Batch normalization: Accelerating deep network training by reducing internal covariate shift[C]//International conference on machine learning. PMLR, 2015: 448-456.

2.1 提出原因
1、在训练神经网络过程中,通常输入batch个数据进行训练,这样每个batch具有不同的分布,使模型训练起来相对困难。
2、Internal Covariate Shift (ICS) 问题:在训练深层网络时,激活函数会改变各层数据的分布以及量级,随着网络的加深,这种改变会越来越大,模型不稳定不容易收敛,甚至可能出现梯度消失的问题。
那我们就看看下面的两个动图, 这就是在每层神经网络有无 batch normalization 的区别

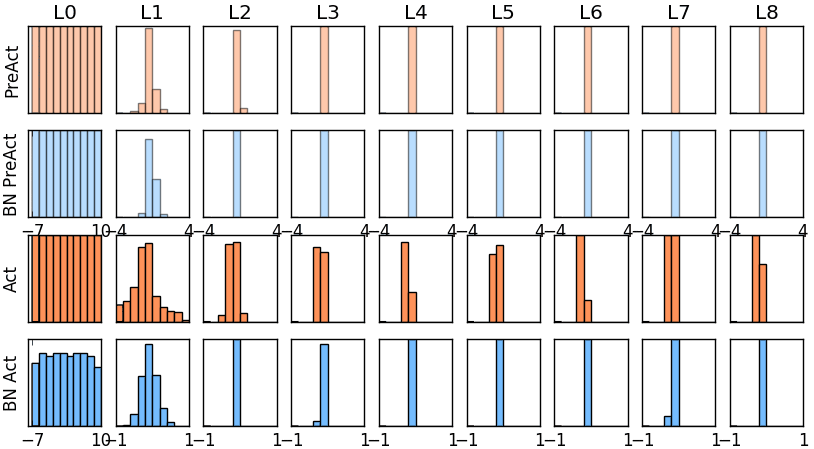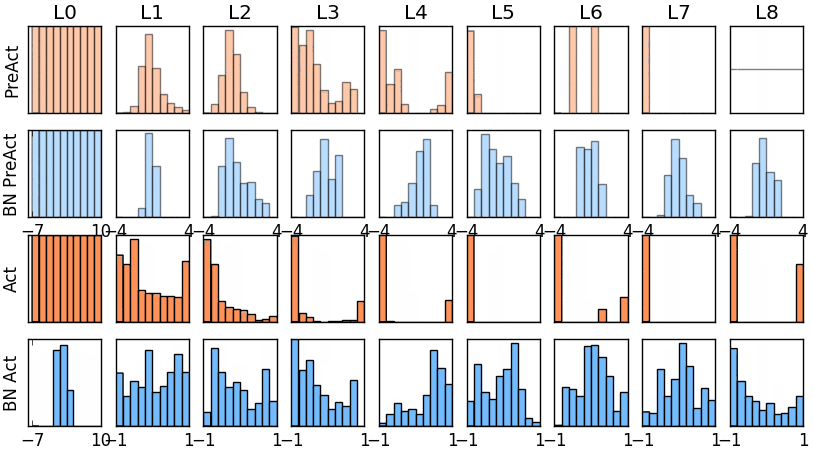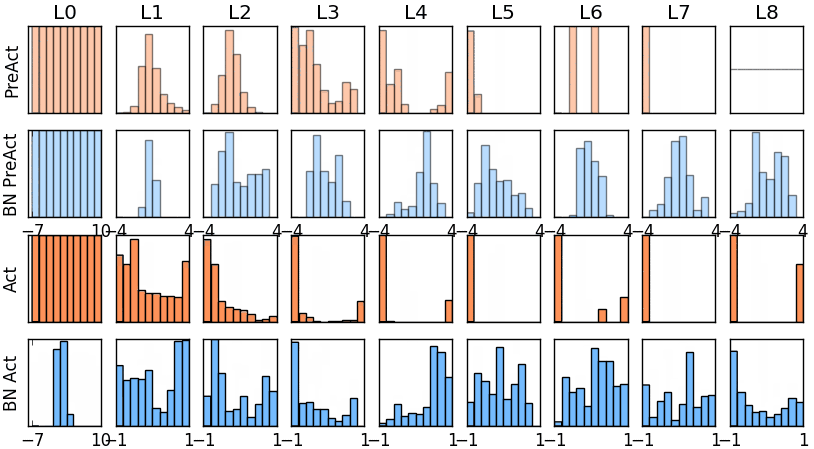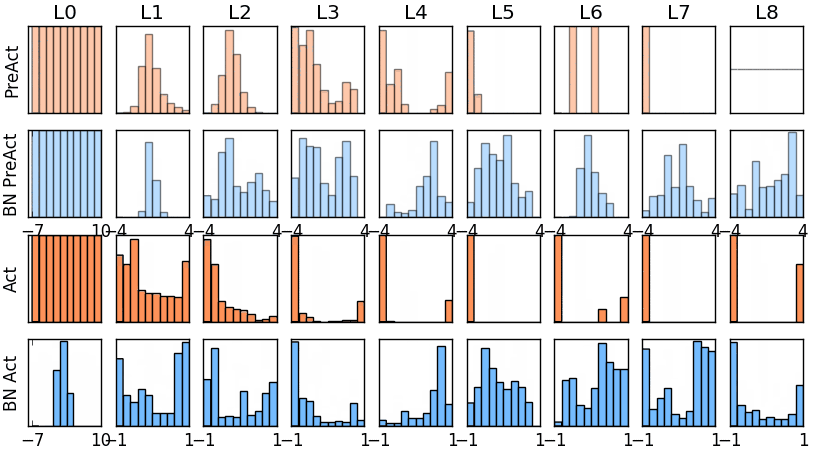
没有normalization 的输出数据很多都等于0,导致后面的神经元“死掉”,起不到任何作用。
2.2 原理
BN的主要思想:沿着通道维度,在batch维度上,计算(N, H, W)均值和方差,然后对feature map进行归一化,这样不仅数据分布一致,而且避免发生梯度消失。保证每一次数据经过归一化后还保留原有学习来的特征,同时又能完成归一化操作,加速训练。
计算过程:
- 沿着通道计算每个batch的均值 μ \mu μ和方差 σ \sigma σ
- 做归一化
- 加入缩放 γ \gamma γ和平移 β \beta β可学习变量

2.3 BN的使用
BN的一个问题是训练时batch size一般较大,但是测试时batch size一般为1,而均值和方差的计算依赖batch,这将导致训练和测试不一致。BN的解决方案是在训练时估计一个均值和方差量来作为测试时的归一化参数,一般对每次mini-batch的均值和方差进行指数加权平均来得到这个量。这样一来就解决了训练和测试的不一致性,在训练的时候计算均值和方差,在推理的使用使用均值和方差
BN的使用位置:激活函数之前,ResNet V1:conv>BN>Relu结构;resnet v2采用BN>Relu>conv结构。但无论如何都是在激活前使用BN。
torch.nn.BatchNorm1d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True, device=None, dtype=None) # 1维
torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True, device=None, dtype=None) # 2维
优点
- BN使得网络中每层输入数据的分布相对稳定,不仅极大提升了训练速度,收敛过程大大加快;
- BN使得模型对网络中的参数不那么敏感,减弱对初始化的强依赖性,简化调参过程,使得网络学习更加稳定
- BN允许网络使用饱和性激活函数(例如sigmoid,tanh等),缓解梯度消失问题
- 允许较大的学习率
- 有轻微的正则化作用(相当于给隐藏层加入噪声,类似Dropout),能缓解 过拟合:深层网络容易过拟合,有时候dropout可能也解决不了。所以有时候BN可以替代dropout
缺点
- 1、如果Batch Size太小,则BN效果明显下降。
如果batch size太小,则计算的均值、方差不足以代表整个数据分布。小的 bath size 引入的随机性更大,难以达到收敛。对于一个比较大的模型,由于显存限制,batch size难以很大,比如目标检测模型,这时候BN层可能会成为一种限制。
-
2、如果batch size太大:会超过内存容量;需要跑更多的epoch,导致总训练时间变长;深度学习的优化(training loss降不下去)和泛化(generalization gap很大)都会出问题。可能会出现局部最优的情况
-
3、RNN等动态网络使用BN效果不佳且使用起来不方便
BN实际使用时需要计算并且保存某一层神经网络batch的均值和方差等统计信息,对于固定深度的前向神经网络(DNN,CNN)使用BN,很方便;
对于RNN来说,尽管其结构看上去是个静态网络,但在实际运行展开时是个动态网络结构,因为输入的Sequence序列是不定长的,这源自同一个Mini-Batch中的训练实例有长有短。对于类似RNN这种动态网络结构,BN使用起来不方便,因为要应用BN,那么RNN的每个时间步需要维护各自的统计量,而Mini-Batch中的训练实例长短不一,这意味着RNN不同时间步的隐层会看到不同数量的输入数据,而这会给BN的正确使用带来问题。假设Mini-Batch中只有个别特别长的例子,那么对较深时间步深度的RNN网络隐层来说,其统计量不方便统计而且其统计有效性也非常值得怀疑。另外,如果在推理阶段遇到长度特别长的例子,也许根本在训练阶段都无法获得深层网络的统计量。综上,在RNN这种动态网络中使用BN很不方便,而且很多改进版本的BN应用在RNN效果也一般。
-
4、例如图像分割这类任务,可能 batch size 只能是个位数,再大显存就不够用了。而当 batch size 是个位数时,BN 的表现很差,因为没办法通过几个样本的数据量,来近似总体的均值和标准差。GN 也是不依赖于batch。
-
5、对于有些像素级图片生成任务来说,BN效果不佳;
对于图片分类等任务,只要能够找出关键特征,就能正确分类,这算是一种粗粒度的任务,在这种情形下通常BN是有积极效果的。但是对于有些输入输出都是图片的像素级别图片生成任务,比如图片风格转换等应用场景,使用BN会带来负面效果,这很可能是因为在Mini-Batch内多张无关的图片之间计算统计量,弱化了单张图片本身特有的一些细节信息。
3. Layer Normalizaiton
Ba J L, Kiros J R, Hinton G E. Layer normalization[J]. arXiv preprint arXiv:1607.06450, 2016.

3.1 提出原因
前面介绍了Batch Normalization的原理,我们知道,BN层在CNN中可以加速模型的训练,并防止模型过拟合和梯度消失。但是,如果将BN层直接应用在RNN中可不可行呢,原则上也是可以的,但是会出现一些问题,因为我们知道Batch Normalization是基于mini batch进行标准化,在文本任务中(NLP),不同的样本其长度往往是不一样的,因此,如果在每一个时间步也采用Batch Normalization时,则在不同的时间步其规范化会强行对每个文本都执行,因此,这是不大合理的,另外,在测试时,如果一个测试文本比训练时的文本长度长时,此时Batch Normalization也会出现问题。因此,在RNN中,我们一般比较少使用Batch Normalization,但是我们会使用一种非常类似的做法,即Layer Normalization。
3.2 原理
Layer Normalization的思想与Batch Normalization非常类似,只是Batch Normalization是在每个神经元对一个mini batch大小的样本进行规范化,而Layer Normalization则是在每一层对单个样本的所有神经元节点进行规范化,即C,W,H维度求均值方差进行归一化(当前层一共会求batch size个均值和方差,每个batch size分别规范化)。 LN 不需要批训练,在单条数据内部就能归一化。
3.3 计算过程

torch.nn.LayerNorm(normalized_shape, eps=1e-05, elementwise_affine=True, device=None, dtype=None)
优点
LN的一个优势就说不需要批训练。在单条数据内部就能完成归一化操作,因此可以用于batch_size=1和RNN训练中,在RNN中,使用Layer Normalization的效果要比Batch Normalization更优,不同的输入样本有不同的均值和方差,可以更快、更好地达到最优效果。LN 不需要保存 mini-batch 的均值和方差,节省了额外的存储空间。
缺点
LN与batch size无关,在小batchsize上效果可能会比BN好,但是大batch size的话还是BN效果好。LN 对于一整层的神经元训练得到同一个转换——所有的输入都在同一个区间范围内。如果不同输入特征不属于相似的类别(比如颜色和大小),那么 LN 的处理可能会降低模型的表达能力。
4. Instance Normalization
Ulyanov D, Vedaldi A, Lempitsky V. Instance normalization: The missing ingredient for fast stylization[J]. arXiv preprint arXiv:1607.08022, 2016.

3.1 提出原因
BN注重对batch size数据归一化,但是在图像风格化任务中,生成的风格结果主要依赖于某个图像实例,所以对整个batchsize数据进行归一化是不合适的,因而提出了IN只对HW维度进行归一化。
3.2 原理
IN保留了N、C的维度,只在Channel内部对于H和W进行求均值和标准差的操作。
3.3 计算过程

优点
IN适用于生成模型中,比如图片风格迁移。因为图片生成的结果主要依赖于某个图像实例,所以对整个Batch进行Normalization操作并不适合图像风格化的任务,在风格迁移中适用IN不仅可以加速模型收敛,并且可以保持每个图像实例之间的独立性。IN的计算就是把每个HW单独拿出来归一化处理,不受通道和batch size 的影响
缺点
如果特征图可以用到通道之间的相关性,那么就不建议使用它做归一化处理
5.Group Normalization
Wu Y, He K. Group normalization[C]//Proceedings of the European conference on computer vision (ECCV). 2018: 3-19.

5.1 提出原因
GN是为了解决BN对较小的batch size效果差的问题。LN虽然不依赖batch size,但是在CNN中直接对当前层所有通道数据进行规范化也不太好。
BN在在batch上进行归一化时维度并不是固定不变的,就比如在训练时,它是通过在训练集上计算好归一化的值,而在测试时则会直接使用,但是训练集和测试集的数据分布存在偏差,就会存在不一致?GN计算步骤与BN一样,只不过与batch size大小无关。
论文中作者在ImageNet数据集上设置batch size为32和GN进行对比,结果发现在训练时候GN的表现要优于BN,但是在验证时却要比BN差一些。
5.2 原理
Group Normalization 将 channel 分成 num_groups组,每组包含channel / num_groups通道,则feature map变为(N, G, C//G, H, W),然后计算每组 (C//G, H, W)维度平均值和标准差。这样就与batch size无关,不受其约束。事实上,GN的极端情况就是LN和I N,分别对应G等于C和G等于1。

5.3 计算过程

torch.nn.GroupNorm(num_groups, num_channels, eps=1e-05, affine=True, device=None, dtype=None)
def GroupNorm(x, gamma, beta, G, eps=1e-5):
# x:input features with shape [N,C,H,W]
# gamma,beta:scale and offset,with shape [1,C,1,1]
# G:number of groups for GN
N, C, H, W = x.shape
x = tf.reshape(x, [N, G, C / G, H, W])
mean, var = tf.nn.moments(x, [2, 3, 4], keep_dims=True)
x = (x - mean) / tf.sqrt(var + eps)
x = tf.reshape(x, [N, C, H, W])
return x, gamma, beta
优点
GN不依赖Batch Size,同时还带来依然令人惊奇的效果。GN是在channel维度上进行的norm,可以很好适用于RNN,这是GN的巨大优势。虽然文中没做关于RNN的实验,但这无疑提供了一条新思路。
缺点
GN对比的BN并不是BN最强的状态。旷视科技提出的MegDet用了一种超大的batch size=256,BN效果比batch_size=32的时候好很多,并且顺便拿下COCO2017检测的冠军。
6 Weight Normalization
6.1 原理


torch.nn.utils.weight_norm(module, name='weight', dim=0)
优点
WN的归一化操作作用在了权值矩阵之上。从其计算方法上来看,WN完全不像是一个归一化方法,更像是基于矩阵分解的一种优化策略,它带来的好处有:
更快的收敛速度;
更强的学习率鲁棒性;
可以应用在RNN等动态网络中;
WN也是和样本量无关的,所以可以使用较小的batch size
WN 的规范化不直接使用输入数据的统计量,因此避免了 BN 过于依赖 mini-batch 的不足,以及 LN 每层唯一转换器的限制,
另外BN使用的基于mini-batch的归一化统计量代替全局统计量,相当于在梯度计算中引入了噪声。而WN则没有这个问题,所以在生成模型,强化学习等噪声敏感的环境中WN的效果也要优于BN。
WN没有一如额外参数,这样更节约显存。同时WN的计算效率也要优于要计算归一化统计量的BN。
缺点
说WN不像归一化的原因是它并没有对得到的特征范围进行约束的功能,所以WN依旧对参数的初始值非常敏感,这也是WN一个比较严重的问题
总结
BN通常可以在中、大批量中取得良好的性能。然而在小批量他的性能会下降比较多;GN在不同Batch Size下具有较大的稳定性,而GN在中、大Batch Size下性能略差于BN。IN、LN、PN、CBN在特定任务中表现良好,例如:IN在图像风格迁移中表现较好,LN在RNN中表现较好,PN在生成网络中表现较好,CBN在目标检测任务中较好,但这几个在其他视觉任务中泛化性能较差。SN集万千宠爱为一身,但训练过于复杂。FRN和BGN比其他归一化方法占据明显优势,但是目前还没大范围采用。
在这些归一化方法中,BN通常可以在中、大批量中取得良好的性能。然而,在小批量它的性能便会下降比较多;GN在不同的Batch Size下具有较大的稳定性,而GN在中、大Batch Size下的性能略差于BN。其他归一化方法,包括IN、LN和PN在特定任务中表现良好,但在其他视觉任务中泛化性比较差。
BGN:超大Batch下BN会出现饱和(比如,Batch为128),并提出在小/超大Batch下BN的退化/饱和是由噪声/混淆的统计计算引起的。因此,在不增加新训练参数和引入额外计算的情况下,通过引入通道、高度和宽度维度来补偿,解决了批量标准化在小/超大Batch下BN的噪声/混淆统计计算问题。
参考:https://www.cnblogs.com/lxp-never/p/11566064.html