场景
CentOS7安装Mysql8并进行主从复制配置:
CentOS7安装Mysql8并进行主从复制配置_霸道流氓气质的博客-CSDN博客
在上面搭建起来Mysql之间的主从复制的基础上,在SpringBoot项目中实现Mysql数据的
读写分离,即写入操作一个库,读取操作一个库。
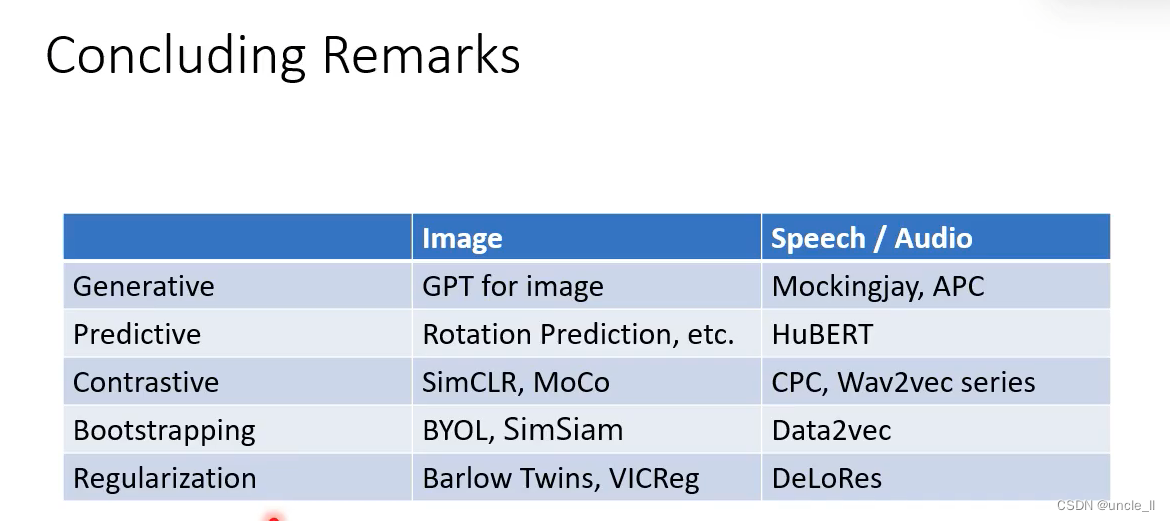
Apache ShardingShpere
Apache ShardingSphere 是一款分布式 SQL 事务和查询引擎,可通过数据分片、弹性伸缩、加密
等能力对任意数据库进行增强。
Apache ShardingSphere


注:
博客:
霸道流氓气质的博客_CSDN博客-C#,架构之路,SpringBoot领域博主
实现
1、添加shardingsphere的maven依赖
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>这里使用mybatis,所以完整的依赖为
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!--MySQL驱动-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.2.1</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.75</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
</dependencies>2、修改application.yml配置文件,将数据源修改为如下,详细配置见注释和官网文档
# 数据源
spring:
application:
name: Demo
main:
allow-bean-definition-overriding: true
shardingsphere:
# 参数配置 ,显示SQL
props:
sql:
show: true
# 配置数据源
datasource:
# 给每个数据源取别名 任意取
names: ds1,ds2
# 给master-ds1配置数据库连接信息
ds1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
jdbc-url:jdbc:mysql://192.168.148.141:3306/test?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B8
username: root
password: Aa_123456
ds2:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
jdbc-url:jdbc:mysql://192.168.148.142:3306/test?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B8
username: root
password: Aa_123456
#配置默认数据源ds1
sharding:
# 默认数据源,主要用于写,注意一定要配置读写分离;如果不配置就会把三个节点都当作从slave节点,新增,修改和删除会出错。
default-data-source-name: ds1
# 配置数据源的读写分离;前提需要做数据库的主从复制;可以不写,会按照默认随机策略
masterslave:
# 配置主从名称,任意取名字
name: ms
# 配置主库 ,负责数据的写入
master-data-source-name: ds1
# 配置从库
slave-data-source-names: ds2
# 配置 slave 节点的负载均衡策略 :轮询机制
load-balance-algorithm-type: round_robin上面配置两个数据库的数据源以及主库等操作。
完整配置文件
# 开发环境配置
server:
# 服务器的HTTP端口,默认为8080
port: 996
servlet:
# 应用的访问路径
context-path: /
tomcat:
# tomcat的URI编码
uri-encoding: UTF-8
# tomcat最大线程数,默认为200
max-threads: 800
# Tomcat启动初始化的线程数,默认值25
min-spare-threads: 30
# 数据源
spring:
application:
name: Demo
main:
allow-bean-definition-overriding: true
shardingsphere:
# 参数配置 ,显示SQL
props:
sql:
show: true
# 配置数据源
datasource:
# 给每个数据源取别名 任意取
names: ds1,ds2
# 给master-ds1配置数据库连接信息
ds1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
jdbc-url:jdbc:mysql://192.168.148.141:3306/test?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B8
username: root
password: Aa_123456
ds2:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
jdbc-url:jdbc:mysql://192.168.148.142:3306/test?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B8
username: root
password: Aa_123456
#配置默认数据源ds1
sharding:
# 默认数据源,主要用于写,注意一定要配置读写分离;如果不配置就会把三个节点都当作从slave节点,新增,修改和删除会出错。
default-data-source-name: ds1
# 配置数据源的读写分离;前提需要做数据库的主从复制;可以不写,会按照默认随机策略
masterslave:
# 配置主从名称,任意取名字
name: ms
# 配置主库 ,负责数据的写入
master-data-source-name: ds1
# 配置从库
slave-data-source-names: ds2
# 配置 slave 节点的负载均衡策略 :轮询机制
load-balance-algorithm-type: round_robin
# mybatis配置
mybatis:
mapper-locations: classpath:mapper/*.xml # mapper映射文件位置
type-aliases-package: com.badao.demo.entity # 实体类所在的位置
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl #用于控制台打印sql语句
3、编写各层代码进行读写分离测试
主库新建一个测试表t_user
DROP TABLE IF EXISTS `t_user`;
CREATE TABLE `t_user` (
`id` int NOT NULL AUTO_INCREMENT,
`user_id` int NOT NULL,
`name` varchar(255) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL,
`age` int NOT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 9 CHARACTER SET = utf8mb3 COLLATE = utf8mb3_general_ci ROW_FORMAT = Dynamic;
SET FOREIGN_KEY_CHECKS = 1;新建实体类
@Data
public class User implements Serializable {
private static final long serialVersionUID = -5514139686858156155L;
private Integer id;
private Integer userId;
private String name;
private Integer age;
}其他mapper和service等层代码省略。直接新建controller包含新增和查询接口
@RequestMapping("user")
@RestController
public class UserController {
@Autowired
private UserService userService;
@RequestMapping("save")
public String save() {
User user = new User();
user.setUserId(new Random().nextInt( 1000 ) + 1);
user.setName("张三"+user.getUserId());
user.setAge(new Random().nextInt( 80 ) + 1);
userService.insert(user);
return "save success";
}
@RequestMapping("findAll")
public String findAll() {
List<User> all = userService.findAll();
return all.toString();
}
}4、测试以上两个接口
分别调用新增和查询所有的接口,可以发现走的是不同的数据库。


5、读写分离读延迟的问题如何解决
刚插入一条数据,然后马上就要去读取,这个时候有可能会读取不到?
归根到底是因为主节点写入完之后数据是要复制给从节点的,读不到的原因是复制的时间比较长,
也就是说数据还没复制到从节点,你就已经去从节点读取了。
除了业务层面妥协,是否操作完之后马上要进行读取,可以对于这类的读取直接走主库,
当然Sharding-JDBC也是考虑到这个问题的存在,所以给我们提供了一个功能,
可以让用户在使用的时候指定要不要走主库进行读取。在读取前使用下面的方式进行设置
@RequestMapping("findMasterAll")
public String findMasterAll() {
// 强制路由主库
HintManager.getInstance().setMasterRouteOnly();
List<User> all = userService.findAll();
return all.toString();
}可以看到此时强制查询时也走主库