1 基本概念
2 文本分类与情感分析
3 TF模型仓库的使用
本章节主要使用TensorFlow模型仓库与keras技术框架联合开发对IMDB数据集的机器学习,TensorFlow模型仓库提供模型直接下载使用,链接地址如下所示:
| https://hub.tensorflow.google.cn/ |
在TF的模型仓库中,包括不同类型用于机器学习的模型,其中包括图像分类模型、文本嵌入层模型、音频模型、视频行为识别模型,这些使用不同的开发语言实现,用户可以根据实际的需求搜素以及下载模型,这些模型可以开箱即用。
准备数据


如上所示,使用pip工具安装TensorFlow的模型仓库的支持工具集、在开发环境中导入开发库。

如上所示,加载IMDB数据集,其中15k数据量用于训练数据集、10k数据量用于验证数据集、25k数据量用于测试数据集。
探索数据
从IMDB数据集中取部分数据样本检查对照原文与标签分类是否正确。




如上所示,共从训练数据中提取10个数据样本,输出其对应的标签分类(情感分类),0表示对电影的负面评价,1表示对电影的正面评价。
构建模型
神经网络包括多个堆栈式的层,因此,构造一个神经网络需要考虑以下三个问题:
|
IMDB数据样本的输入是语句,对语句的预测是0或者1。因此,最高效的表示原文的方式是使用嵌入式向量集,也就是,在神经网络的第一层中使用已经预训练的文本嵌入向量集,其优点如下所示:
|
TensorFlow的模型仓库提供很多已经预训练的嵌入向量层模型,部分模型如下所示:
|

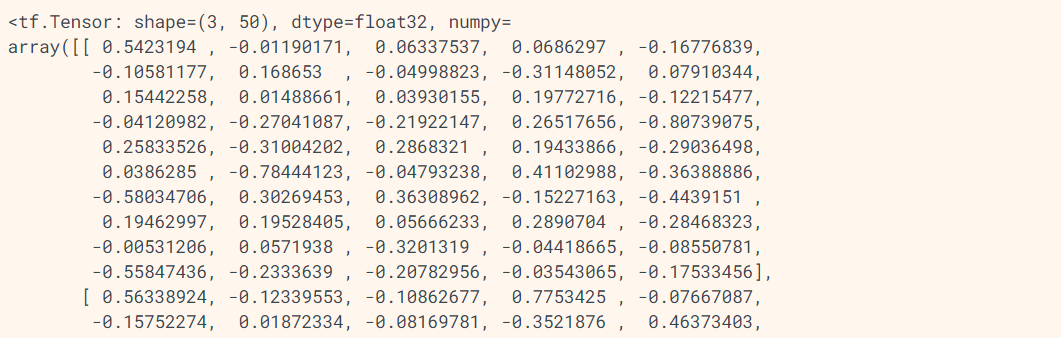
如上所示,embedding是嵌入向量层对应的模型在TensorFlow模型仓库中的下载地址,hub_layer是使用模型仓库提供的工具集引用该嵌入向量层模型用于后续的训练,下载的模型中包括已经预训练的向量集,嵌入向量集的维度等于50,展示了train_examples_batch中的三个序列向量元素,每个元素对应一个嵌入向量集。

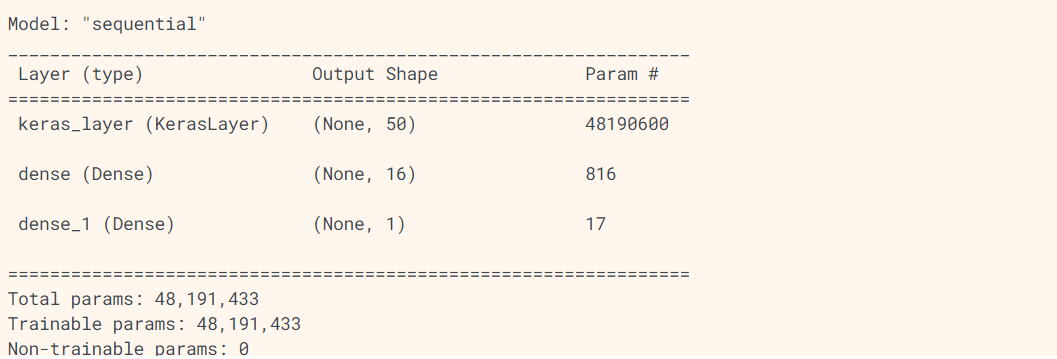
如上所示,使用模型仓库下载的嵌入向量层作为第一个隐藏层构建一个神经网络模型,该模型的描述如下所示:
| 1 第一层使用模型仓库下载的已经预训练的嵌入向量模型 2 全连接的稠密层使用16个神经元 3 最后一层全连接收敛到一个单元作为输出 |
损失函数与优化器

如上所示,使用adam作为优化器,使用binary_crossentropy作为损失函数,对模型编译。
训练模型


如上所示,对10000个数据样本以每批次512进行10次迭代的训练,输出损失值以及准确度。
评估模型


如上所示,使用测试数据集对模型进行评估, 输出accuracy准确度等于0.852,输出loss损失值等于0.360,评估完成可以部署模型与应用模型。
(未完待续)









![[趣味][人工智能生成文字]chatGPT使用教程](https://img-blog.csdnimg.cn/8fa22f507b9e4bfca523033add76fe16.png)