MySQL执行过程与bufferPool缓存机制
- 一、SQL执行流程图
- 二、个人理解的Innodb执行引擎执行顺序
- 1、去磁盘文件查找id为1的整页数据,加载到Buffer Pool缓存池中;
- 2、然后写入更新数据的旧值(这里指name=zhuge的数据),写入到undo日志;
- 3、然后更新内存数据,也就是把缓存池中的数据为name=zhuge666;
- 4、写入redo日志,也是先写入到一个缓冲池中;
- 5、mysql准备提交事务(客户端发起了commit命令)、redo日志写入磁盘(name=zhuge666);
- 6、准备提交事务,binlog日志写入磁盘;
- 7、binlog日志写入磁盘成功后,把commit标记到redo磁盘日志文件,然后提交事务完成;
- 8、Buffer Pool缓存池数据,随机写入磁盘、以Page为单位写入。(这一步骤完成后,磁盘文件的name=zhuge666),到此一个完整的流程就结束了;
- 三、为什么MYSQL要设计这么复杂的读写机制?
- 1、为什么磁盘文件就是随机读写?
- 2、redo日志为什么是有顺序的?
- 3、为什么要有 redo log 日志?
- 4、为什么要写 binlog日志?
- 5、为什么要写 undo log日志?
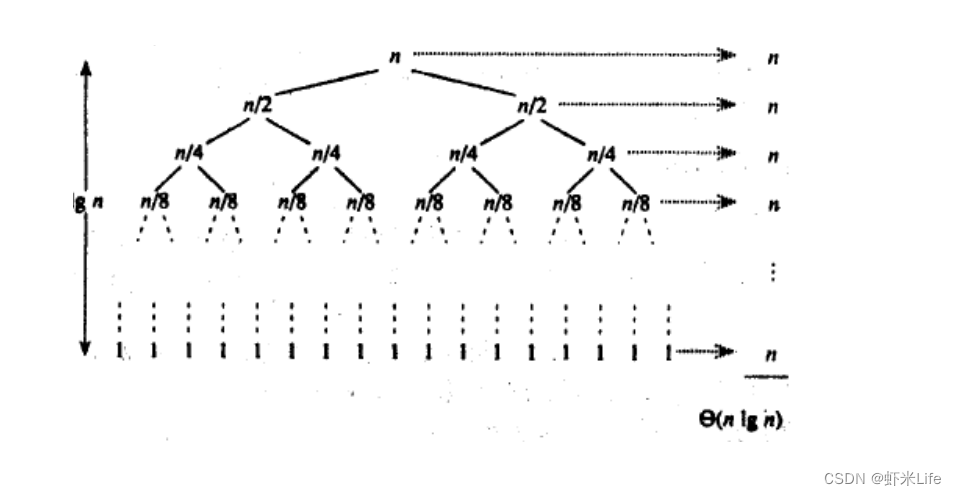
一、SQL执行流程图
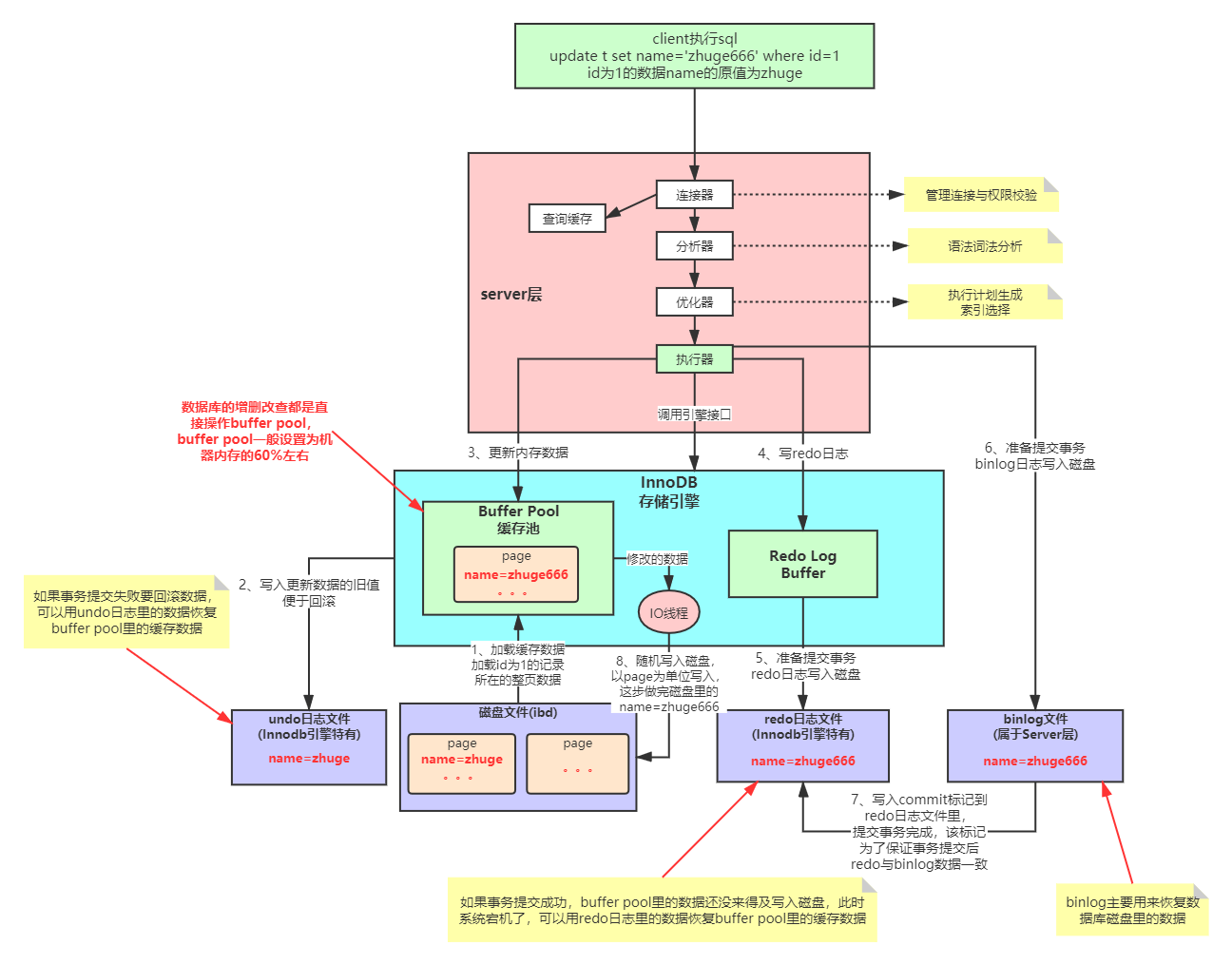
上图案例以客户端执行一条sql进行
update table set name ='zhuge666' where id =1
id为1的未修改前的数据为zhuge
在通过了mysqlserver层的连接器、查询缓存、分析器、优化器、之后,到达执行器开始,这里主要说明的是以Innodb执行引擎执行流程顺序;
二、个人理解的Innodb执行引擎执行顺序
1、去磁盘文件查找id为1的整页数据,加载到Buffer Pool缓存池中;
注意可能拿一页,也可能拿多页
mysql底层是按页为单位的,他不是一条条记录去拿的;
通过索引定位到磁盘里这条数据,把整页数据加载到缓存里;
2、然后写入更新数据的旧值(这里指name=zhuge的数据),写入到undo日志;
undo日志也就是回滚日志,主要用于事务失败时,就可以用undo的日志数据回滚Buffer Pool缓存池的数据
undo日志是Innodb独有的
3、然后更新内存数据,也就是把缓存池中的数据为name=zhuge666;
4、写入redo日志,也是先写入到一个缓冲池中;
这里是写redo的缓冲区里,通过缓存机制,底层批量去做写到redo日志里;
redo日志是innodb特有的
5、mysql准备提交事务(客户端发起了commit命令)、redo日志写入磁盘(name=zhuge666);
6、准备提交事务,binlog日志写入磁盘;
binlog日志属于server层,所以不管是什么执行引擎都有一套实现
7、binlog日志写入磁盘成功后,把commit标记到redo磁盘日志文件,然后提交事务完成;
这里写入的commit该标记,是为了保证事务提交后redo与binlog数据一致
做到这一步,对于方法而言,已经事务提交成功了,java端已经认为成功了
8、Buffer Pool缓存池数据,随机写入磁盘、以Page为单位写入。(这一步骤完成后,磁盘文件的name=zhuge666),到此一个完整的流程就结束了;
数据库他会有一个io线程,不定期的把缓存池中的页数据,统一刷到磁盘里;
三、为什么MYSQL要设计这么复杂的读写机制?
在看完上面全流程后,一定会有一个疑问,为什么要设计的这么复杂?直接更新到磁盘不行吗?
个人理解原因主要是考虑到性能问题,内存操作肯定比磁盘操作快的多。
原因
因为如果来一个请求就直接对磁盘文件进行随机读写,然后更新磁盘文件里的数据性能可能相当差。
因为磁盘随机读写的性能是非常差的,所以直接更新磁盘文件是不能让数据库抗住很高并发的。
Mysql这套机制看起来复杂,但它可以保证每个更新请求都是更新内存BufferPool,然后顺序写日志文件,同时还能保证各种异常情况下的数据一致性。
更新内存的性能是极高的,然后顺序写磁盘上的日志文件的性能也是非常高的,要远高于随机读写磁盘文件。
正是通过这套机制,才能让我们的MySQL数据库在较高配置的机器上每秒可以抗下几干的读写请求。
1、为什么磁盘文件就是随机读写?
可能会进行更新、删除等操作,可能不在同一个数据页
2、redo日志为什么是有顺序的?
因为redo是按顺序写,不会删除;
磁盘的顺序IO和内存操作性能相媲美,随机读写,相当低;
写redo日志是顺序io,写磁盘是随机io;
3、为什么要有 redo log 日志?
其实也是为了防止特殊的异常情况:
如事务提交成功,但是数据库宕机了,这时候还可以用redo日志来恢复缓存区数据。
4、为什么要写 binlog日志?
万一数据库挂了(宕机了),磁盘里还是老数据,还未更新。
等数据去重启的时候,他会用这个redo日志恢复buffer pool里面的数据,最终执行第8步)
其次binlog可以恢复误删的数据(生产环境尤其重要,一般都会开启)。
5、为什么要写 undo log日志?
一个事务开始,进行增删改的时候,会把原数据写到undo日志,方便在事务失败的时候,进行数据回滚(这里主要是回滚BufferPool缓存池的数据)。