全文共6500余字,预计阅读时间约13~20分钟 | 满满干货(附案例),建议收藏!
一、LLM模型的涌现能力
在GPT没有爆火之前,一直以来的共识都是:模型的规模越大,模型在下游任务上的能力越多、越强。
LLM原始训练目标是为了生成自然、连贯的文本,因为其本身接受了大量的文本进行预训练,因此根据提示补全和创造文本就是模型的原生能力。
在原生能力范畴下,LLM模型具备文本创造能力,如写小说、新闻、诗歌,GPT-3模型最早是被用来做这些事情的。
不过,仅仅能进行文本创造,并不足以让大语言模型掀起新的一轮技术革命,引爆这一轮技术革命的真正原因是:大语言模型的涌现能力
人们真正看好大语言模型技术的根本在于当模型足够大(参数足够大&训练数据足够多)时模型展示出了“涌现能力”。
随着不断有新的模型的提出,大规模的语言模型出现了很多超乎研究者意料的能力。针对这些在小模型上没有出现,但是在大模型上出现的不可预测的能力,就被称为涌现能力,在 Jason Wei 等人的研究中给出如下定义:
论文:Emergent Abilities of Large Language Models
在小模型中没有表现出来,但是在大模型中变现出来的能力(An ability is emergent if it is not present in smaller models but is present in larger models.)。
换句话说:所谓涌现能力(EmergentCapabilities),指的是模型在没有针对特定任务进行训练的情况下,仍然能够在合理提示下处理这些任务的能力,有时也可以将涌现能力理解为模型潜力,巨大的技术潜力,是LLM爆火的根本原因。
对于大语言模型(例如Completion模型)来说,本身并未接受对话语料训练,因此对话能力其实也是它涌现能力的体现,另外常用的翻译、编程、推理、语义理解等,都属于大语言模型的涌现能力。
二、如何激发大模型的涌现能力
激发大型语言模型的涌现能力有两种方法:提示工程(prompt engineering)和微调(fine-tuning)。
2.1 提示工程(prompt engineering)
提示工程是指通过设计特殊的提示来激发模型的涌现能力。这种方法不需要对模型进行额外的训练,只需要通过设计合适的提示来引导模型完成特定任务。提示工程通常用于在不更新模型参数的情况下,快速解决新问题。
通过输入更加合理的提示,引导模型进行更有效的结果输出,本质上一种引导和激发模型能力的方法
这种方法最早在GPT3 的论文中提出:给定一个提示(例如一段自然语言指令),模型能够在不更新参数的情况下给出回复。在此基础上,Brown等在同一篇工作中提出了Few-shot prompt,在提示里加入输入输出实例,然后让模型完成推理过程。这一流程与下游任务规定的输入输出完全相同,完成任务的过程中不存在其它的中间过程。下图展示了来自不同工作任务在不同大模型下few-shot下的测试结果。
论文:Language Models are Few-Shot Learners
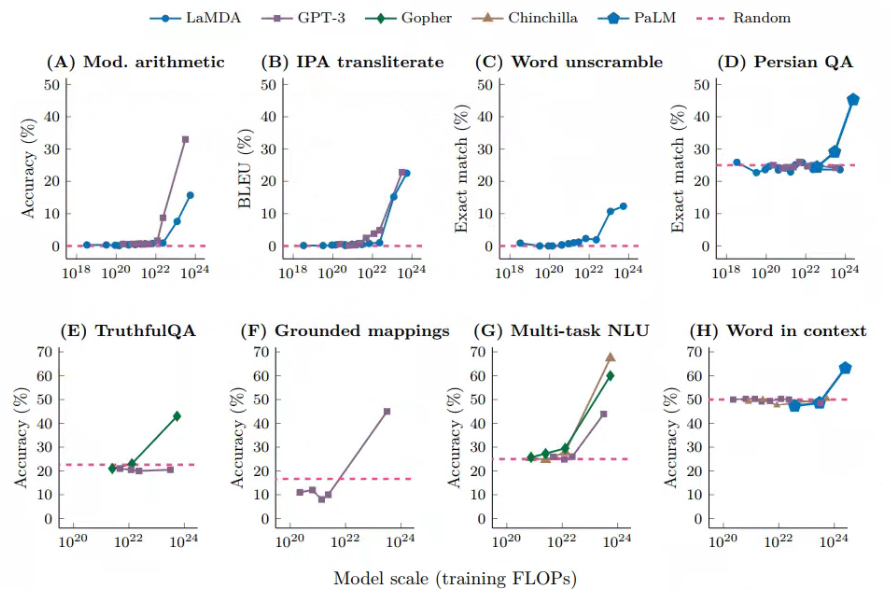
其中,横坐标为模型训练的预训练规模(FLOPs:floating point operations,浮点运算数。一个模型的训练规模不仅和参数有关,也和数据多少、训练轮数有关,因此用FLOPs综合地表示一个模型的规模),纵轴为下游任务的表现。可以发现,当模型规模在一定范围内时(大多FLOPs在 1 0 22 10^{22} 1022以内),模型的能力并没有随着模型规模的提升而提高;当模型超过一个临界值时,效果会马上提升,而且这种提升和模型的结构并没有明显的关系。
目前为大模型添加prompt的方式越来越多,主要表现出的一个趋势是,相比于普通的 few-shot 模式(只有输入输出)的 prompt 方式,新的方法会让模型在完成任务的过程中拥有更多的中间过程,例如一些典型的方法:思维链(Chain of Thought)、寄存器(Scratchpad)等等,通过细化模型的推理过程,提高模型的下游任务的效果,下图展示了各种增强提示的方法对于模型的作用效果:
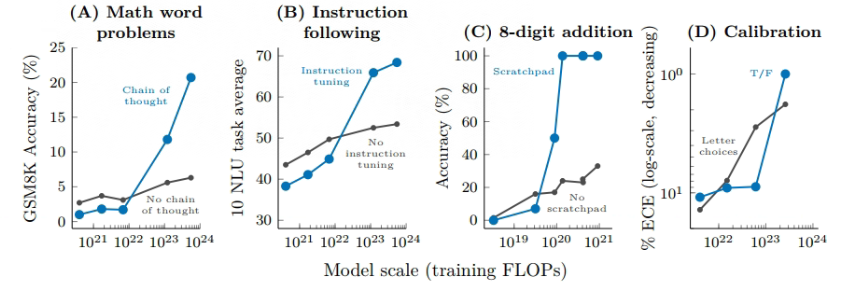
具体的任务类型包括数学问题、指令恢复、数值运算和模型校准,横轴为训练规模,纵轴为下游任务的评价方式。与上图类似,在一定的规模以上,模型的能力才随着模型的规模突然提高;在这个阈值以下的现象则不太明显。不同的任务采用的激发方式不同,模型表现出的能力也不尽相同,这是一个不断研究的过程。
对于通过提示工程来激发模型的涌现能力来说,优劣势很明显:
- 优势:它是一种更加轻量级的引导方法,尝试和实施的门槛更低。
- 劣势:受限于模型对话上下文限制,提示量有限。
2.2 微调(fine-tuning)
微调是指在预训练好的大型语言模型基础上,针对特定任务进行额外训练。这种方法需要对模型进行额外的训练,但可以提高模型在特定任务上的性能。微调通常用于解决那些无法通过提示工程解决的问题。
换句话说:它通过输入额外的样本,对模型部分参数进行修改,从而强化模型某部分能力。本质上也是一种引导和激发模型能力的方法
微调是后面要花大量篇幅写的内容,所以这里就不详细说了
微调方法与提示工程相比:
优势:可以让模型永久的强化某方面能力。
劣势:需要重新训练模型部分,训练成本较大,需要精心准备数据,技术实施难度更大
对于这两种方法各自有各自使用的应用场景,提示工程解决的问题,往往不会用微调(如小语义空间内的推理问题),微调通常用于解决那些无法通过特征工程解决的问题。
它们更多的时候是作为上下游技术关系,例如要进行本地知识库的定制化问答,最好的方法就是借助提示工程进行数据标注,然后再利用标注好的数据进行微调。
相比模型的原生能力,模型的涌现能力是非常不稳定的,要利用提示工程和微调技术来引导和激发模型的涌现能力,难度很大。
三、提示工程的概念
3.1 提示工程的理解误区
很多人以为的提示工程是这样的:
- 添加提示词尾缀:如 “请模型一步步思考、一步步解答…”。
- 给出一份示例模版:请“参照示例进行回答”。
- 做身份、角色设定:“请以XXX身份进行回答”…
几乎没有技术含量,主要靠记忆大量的提示词模板,或者网上导航站那些所谓的《几万个提示模板》,属于有手就会的技术。
实际上真实场景下的提示工程技术要做到:
- 合理的引导思考
- 复杂串联或嵌套的提示流程,高度依赖人工经验和技术灵感的提示示例设计
需要做到人工经验和复杂计算的完美结合,才能够大幅激发模型的涌现能力,解决业内很多复杂问题,是非常高价值的技术方向。
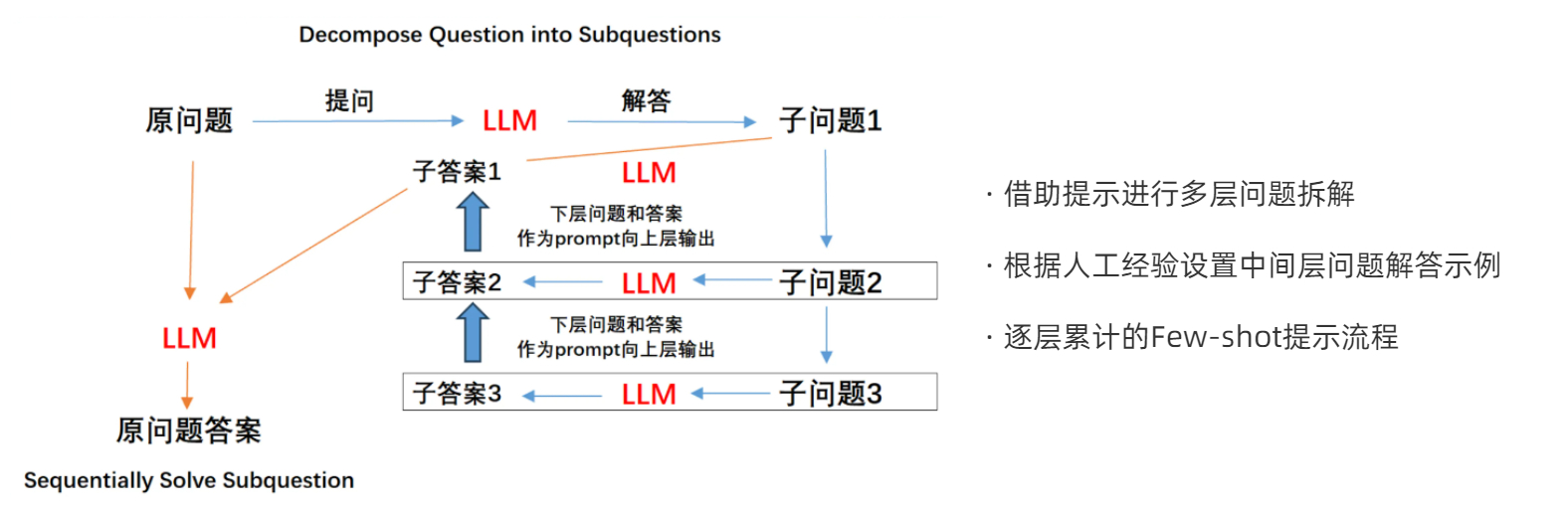
比如一个工业级的提示工程流程是这样的:
3.2 语言提示工程(LanguagePrompting)
提示工程可以进一步分为语言提示工程(LanguagePrompting)和代码提示工程(Code Prompting)。
对于语言提示工程来说,其实可以理解为使用ChatGPT的过程,通过自然语言表达复杂的问题和意图,进行多轮对话。
它比较友好,适合于非技术人员,但是缺点也是存在的,比如,自然语言存在歧义,可能导致模型理解错误或产生误导性的回答;可能存在语法错误或不规范的用词,导致模型难以正确理解问题;交互方式可能难以准确理解用户意图和推理过程,可解释性较差,这些问题都是存在的,所以优秀的提示工程应该具备以下的一些基本原则:
- 清晰明确的问题描述:提供清晰、明确的问题描述,使模型能够准确理解问题的意图并给出准确的回答。避免模糊、含糊不清或歧义性的问题描述,
比如:目的是希望输出是一个逗号分隔的列表,请要求它返回一个逗号分隔的列表。
Prompt思路:如果希望它在不知道答案时说“我不知道”,请告诉它“如果您不知道答案,请说“我不知道”。
-
提供必要的上下文信息:根据具体情况,提供适当的上下文信息,以帮助模型更好地理解问题。上下文信息可以是相关背景、之前提及的内容或其他相关细节。
-
将复杂任务拆分为更简单的子任务和提供关键信息:如果问题较为复杂或需要特定的答案,可以将复杂任务拆分为更简单的子任务,逐步提供关键信息,以帮助模型更好地理解和解决问题。
-
避免亢余或多余的信息:尽量避免提供亢余或不必要的信息,以免干扰模型的理解和回答。保持问题简洁明了,并提供与问题相关的关键信息
-
验证和追问回答:对于模型给出的答案,进行验证和追问,确保回答的准确性和合理性。如有需要,提供反馈或额外的说明,以进一步指导模型的回答。
-
尝试不同的表达方式:如果模型对于某个特定问题无法准确回答,尝试以不同的表达方式或角度提问,给出更多的线索,帮助模型理解并给出正确的回答。
-
生成多种输出,然后使用模型选择最好的一个
-
…
3.3 代码提示工程(Code Prompting)
对于代码提示工程来说,是指通过设计特殊的代码提示来激发模型的涌现能力。这种方法不需要对模型进行额外的训练,只需要通过设计合适的代码提示来引导模型完成特定任务,代码提示工程通常用于解决那些无法通过语言提示工程解决的问题,也是后续模型开发中的重中之重。后面会多篇幅解释,此处先不详细展开。
3.4 经典小样本提示(Few-shot)
最简单的提示工程的方法就是通过输入一些类似问题和问题答案,让模型参考学习,并在同一个prompt的末尾提出新的问题,依次提升模型的推理能力。这种方法也被称为One-shot或者Few-shot提示方法。
One-shot和Few-shot最早由OpenAI研究团队在论文《Language Models are Few-Shot Learners》中率先提出,这篇论文也是提示工程方法开山鼻祖,不仅介绍了提示工程的两大核心方法,同时也详细介绍这么做背后的具体原因。
这篇论文大致是这样:OpenAI研究团队增大了GTP3语言模型的规模,有175b参数,然后在这个模型上测了它的few-shot能力,没更新梯度,也没微调,纯纯的就是测试,得到的结果是猛地一匹。给了三个图一通分析:
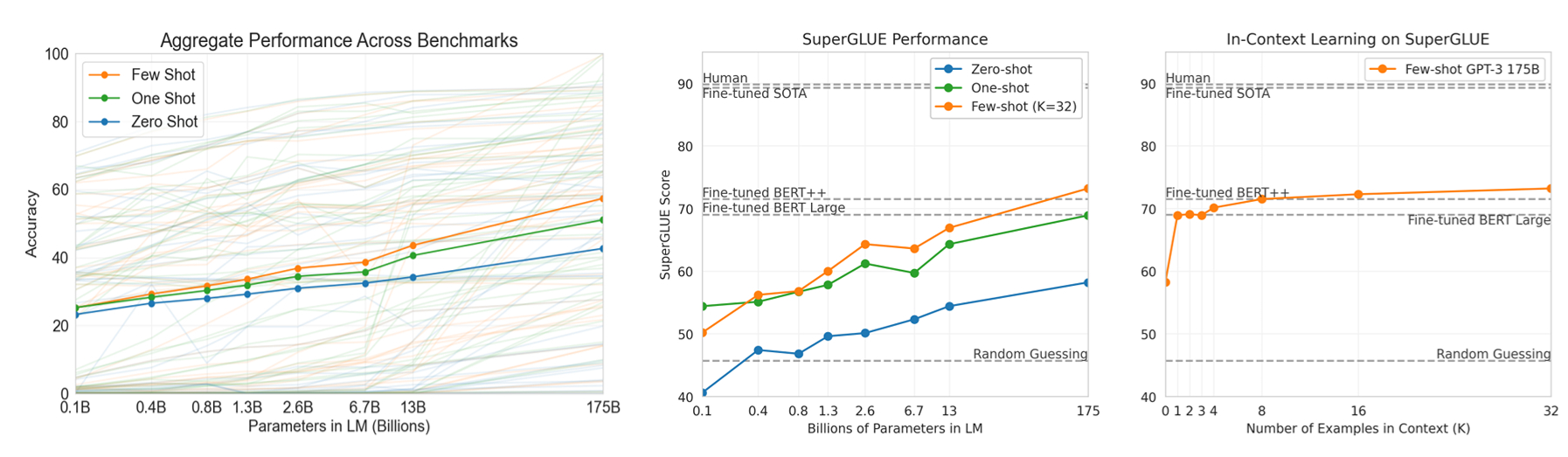
论文结论大概一下两点:
- 在zero-shot、one-shot、few-shot 上,规模越大,效果越好
- few-shot只要参数够不比fine-tuned差
喜欢钻原理的可以自己看看论文,很精彩。
就具体应用来说。Few-shot提示方法并不复杂,只需要将一些类似的问题+答案作为prompt的一部分进行输入即可。
- **先看下zero-shot **
Prompt 1 :
Classify the text into neutral, negative or positive.
Text: I think the vacation is okay
Sentiment:
结果如下:
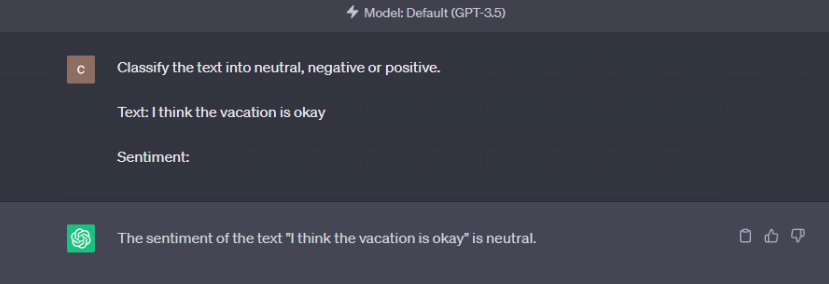
可以看到没有告诉 ChatGPT 任何情感分类的应该怎么做的描述,它就已经“理解”了“情绪分类”这件事。
Prompt 2:
准确的翻译文本如下:
Got this panda plush toy for my daughter’s birthday, who loves it and takes it
everywhere. It’s soft and super cute, and its face has a friendly look. It’s a bit small for what I paid though. I think there might be other options that are bigger for the same price. It arrived a day earlier than expected, so I got to play with it myself before I gave it to her.
翻译:
结果如下:

对于Zero-shot 来说,它复杂任务上的表现不佳,
Prompt 3:
- **Few-shot **
Prompt 1:
文本:A “whatpu” is a small, furry animal native to Tanzania.
用 “whatpu” 造句:We were traveling in Africa and we saw these very cute whatpus.
文本:To do a “farduddle” means to jump up and down really fast.
用 "farduddle"造句:
结果如下:
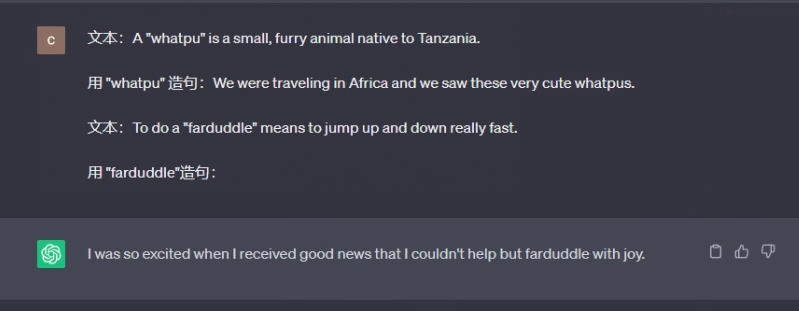
仅用一个示例就学会了如何进行一个任务
few-shot 虽然能解决了 zero-shot 的问题,如果遇到了需要推理的复杂任务时,依旧无能为力。
Prompt 2:
我现在有以下几个数字:1,3,5,23,69,70,10,84,923,32,这些数中,存在多少个奇数,存在多少个偶数?
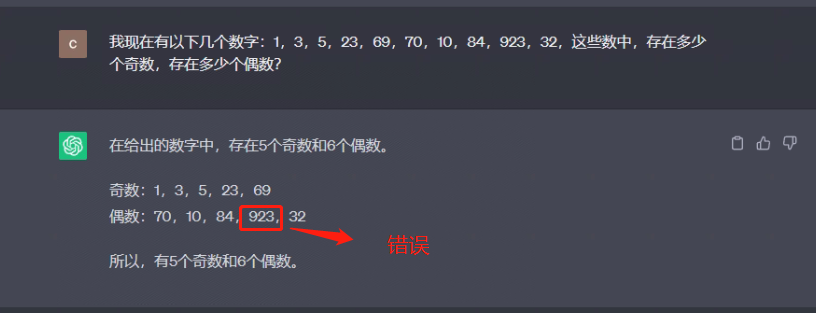
3.5 思维链(CoT)提示
思维链的本质是将复杂任务拆解为多个简单的子任务。
思维链(Chain of Thought)是指一个思维过程中的连续逻辑推理步骤或关联的序列。它是思维过程中一系列相互关联的想法、观点或概念的串联。思维链通常用于解决问题、做决策或进行推理。它可以按照逻辑顺序连接和组织思维,将复杂的问题分解为更简单的步骤或概念,从而更好地理解和解决问题。
人类在解决数学数学难题时,经过一步步推导,大概率能得出正确的答案,对于模型来说,也是这样,所以在这篇论文中提出了逐步 Zero-shot思想,
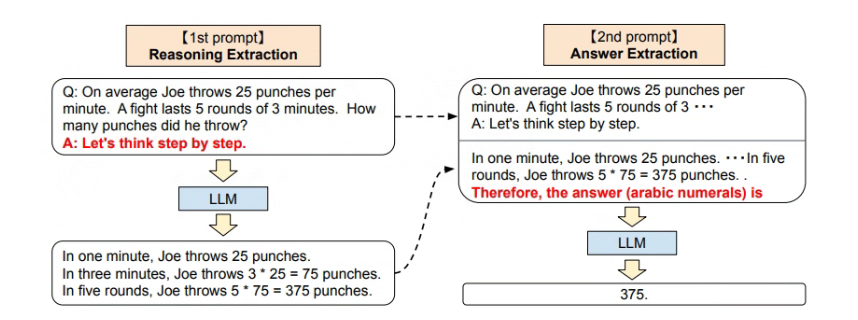
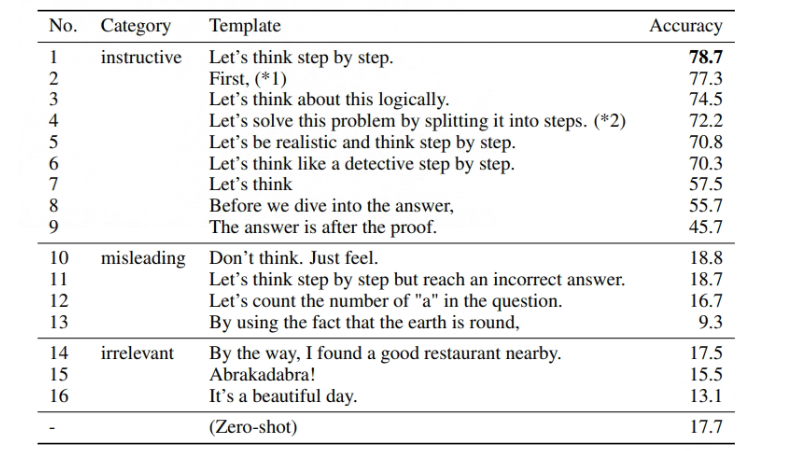
Large Language Models are Zero-Shot Reasoners
利用大模型进行两阶段推理的设想,即第一个阶段先进行问题的拆分并分段解答问题(Reasoning Extraction),然后第二阶段再进行答案的汇总(Answer Extraction),如图:
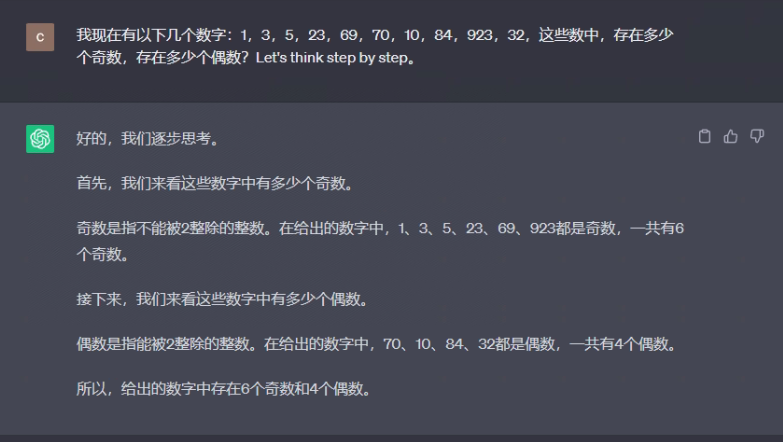
使用逐步 Zero-shot再次解决一下这个问题
Prompt 1:
在这些数字中1,3,5,23,69,70,10,84,923,32有多少个奇数多少个偶数?Let’s think step by step。
3.6 CoT+Few-shot 提示
在某些情况下,两者结合能得到准确的推理。
单独使用zero-shot时:
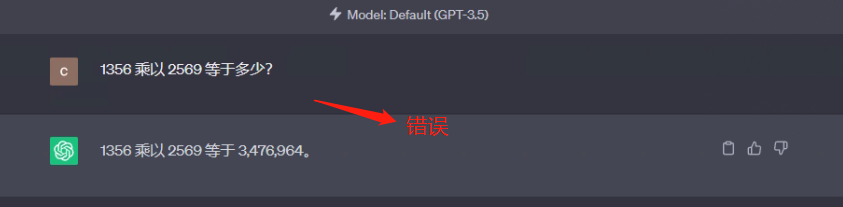
prompt 1:
1356 乘以 2569 等于多少?
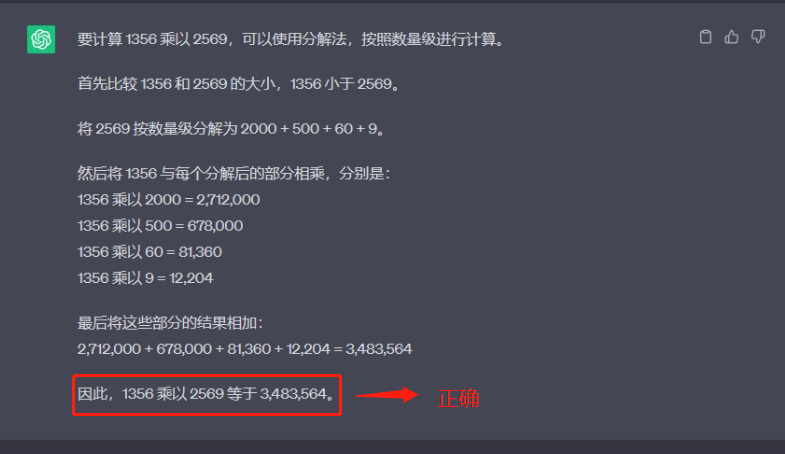
使用CoT + Few-shot时:
prompt 2:
示例:
13乘以17等于多少?首先比较13和17的大小,13小于17,将17按数量级分解为10+7,再将13与17
按数量级分解后的结果相乘,13乘以(10+7)=221
256乘以36等于多少?首先比较256和36的大小,256大于36,将256按数量级分解为
200+50+6,再将36与256按数量级分解后的结果相乘,36乘以(200+50+6)=9216 325乘以
559等于多少?首先比较325和559的大小,320小于559,将559按数量级分解为500+50+9,再将325与559按数量级分解后的结果相乘,325 乘以(500+50+9)=181675
问题:1356 乘以 2569 等于多少?
3.7 STaR Fine-Tune提示法
STaR Fine-Tune 提示法(Self-taught Reasoner)是通过 few-shot 的提示方式,产生大量可以用于微调模型的有标签的数据集
论文在这里
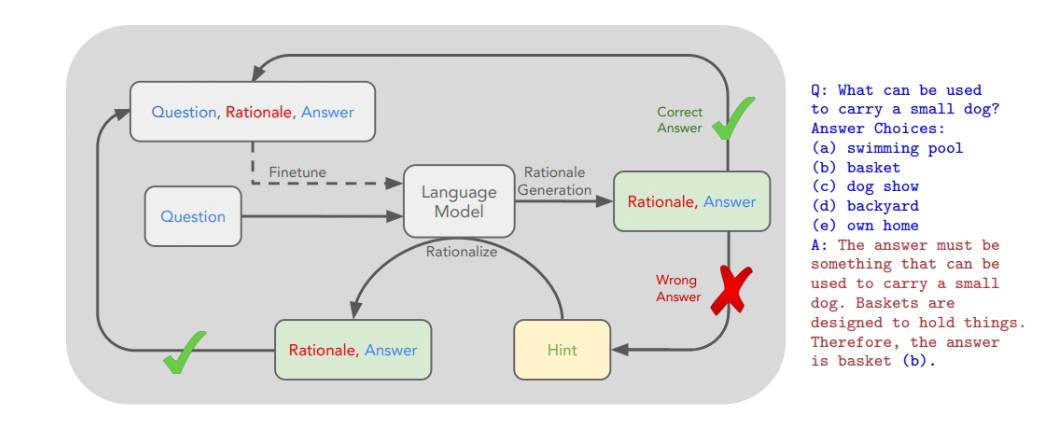
其大致的过程是:
-
将少量有标签的样本作为示例
-
利用模型生成无标签数据的答案以及得出这个答案的理由
-
保留正确答案以及答案的理由作为微调数据集的一部分
-
对于没有回答正确的问题,重新将正确答案作为问题的一部分输入,重新使用 few-shot prompt 生成正确的答案以及相应的理由,汇总到微调数据集中
-
最终使用最后的数据集微调模型
这部分我还没研究,后续看微调的部分可能会搞这个,感兴趣的可以先自己看看。
四、模型的推理能力
模型的推理能力是指模型在面对新问题时,能够根据已有的知识和经验进行推理和判断的能力,也就是模型的逻辑理解能力。例如模型是否能够很好的解决一些逻辑推理题,或者根据语境中的提示,找到并挖掘背后隐藏的逻辑关系等。
从更加学术的角度进行理解,大模型的推理能力也被称为组合泛化能力,指的是模型能够理解并应用在训练数据中看到的概念和结构,以处理在训练数据中未曾见过的情况或问题。
**提示工程的根本目的就是提升模型的推理能力。**所以无论是语言提示工程,还是代码提示工程,是解决问题的关键因素。
五、总结
本文揭示了LLM模型的涌现能力,阐述了如何通过提示工程和微调来激发大模型的涌现能力。接着深入讨论了提示工程的各个方面,包括其误区、语言提示工程、代码提示工程,以及多种提示方法,如经典的小样本提示、思维链提示、CoT+Few-shot提示和STaR Fine-Tune提示法。对于理解和应用LLM模型来说,这些知识都具有重要的参考价值。
最后,感谢您阅读这篇文章!如果您觉得有所收获,别忘了点赞、收藏并关注我,这是我持续创作的动力。您有任何问题或建议,都可以在评论区留言,我会尽力回答并接受您的反馈。如果您希望了解某个特定主题,也欢迎告诉我,我会乐于创作与之相关的文章。谢谢您的支持,期待与您共同成长!