论文发版:CVPR2023
应用:
Over the discrete motion space, a temporal autoregressive model is employed to sequentially synthesize facial motions from the input speech signal, which guarantees lip-sync as well as plausible facial expressions。语音信号->唇同步&面部表情
仓库地址:https://github.com/Doubiiu/CodeTalker
方法:
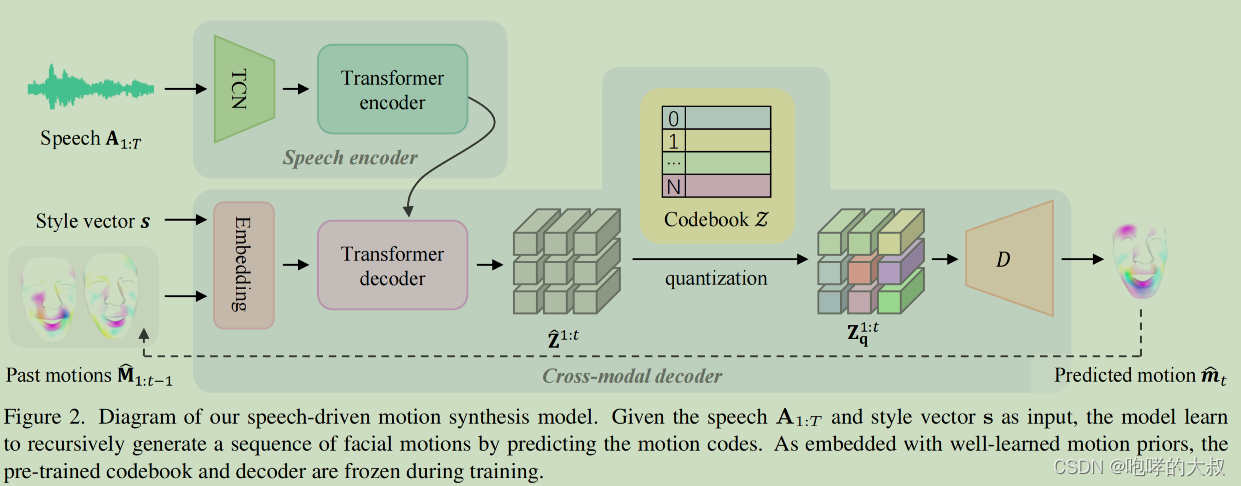
cross-modal decoder :embedding block +multi-layer transformer decoder+ pre-trained codebook +VQ-VAE decoder
训练过程两部分:1)Discrete Facial Motion Space
VQ-VAE : encoder E+ decoder D+ context-rich codebook Z
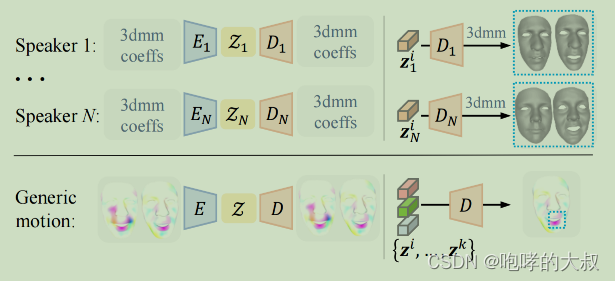

输入:x = x - template;x:头模的顶点(vertices),shape[1,69,15069]
template:标准头模 ,shape[1,15069]
2)Speech-Driven Motion Synthesis
这部分包括:audio feature extractor(TCN)+transformer encoder+embedding block +multi-layer transformer decoder,其中
audio feature extractor(TCN)+transformer encoder,使用wav2vec 2.0作预训练模型,冻结第一步训练好的pre-trained codebook 和VQ-VAE decoder,训练embedding block +multi-layer transformer decoder。
评价指标:
1)Lip vertex error:计算每个帧的所有嘴唇顶点的最大L2误差,并取所有帧的平均值。
2)Upper-face dynamics deviation:measure the variation of facial dynamics for a motion sequence in comparison with that of the ground truth
驱动效果:
FaceTalk__audio
不同的人,说同一段话,嘴形驱动效果稍微有些差异。

使用chinese-wav2vec2-base替代wav2vec2-base-960h,同一段音频,嘴形驱动效果差不多。