系列文章目录
【收藏向】从用法到源码,一篇文章让你精通Dubbo的SPI机制
面试Dubbo ,却问我和Springcloud有什么区别?
超简单,手把手教你搭建Dubbo工程(内附源码)
Dubbo最核心功能——服务暴露的配置、使用及原理
并不简单的代理,Dubbo是如何做服务引用的
不满足于RPC,细说Dubbo的服务调用逻辑
- 系列文章目录
- 一、暴露、引用、调用
- 二、Invoker选调
- 1. 层层包装
- 2. 集群决策
- 3. 名录选调
- 可用列表
- 路由筛选
- 4. 负载均衡
- 5. 调用逻辑
- 三、网络通信
- 1. Exchange
- 2. Netty
- 四、服务执行
- 1. 消息接收
- 2. 获取服务并调用
- 五、返回结果
- 1. 提供方返回
- 2. 消费方获取结果
- 3. 事件触发
- 六、总结

经过前面一系列的铺垫,今天终于迎来Dubbo最最本质的功能了,即服务调用。前面我们不止一次的说过,Dubbo不满足于仅仅作为一个RPC框架。如图,我们甚至可以在官网看见其对自身的定义

然而前面不管是服务暴露,还是服务引用,其实都算RPC的组成部分。而Dubbo真正的花活,在服务调用这里开始展现,亦是其自诩超越普通RPC的地方,老规矩,我们先自己构思几个问题,带着问题去学习:
服务调用的底层是网络通信,这部分是靠什么实现的?Dubbo超越普通RPC框架的底气究竟是什么?服务调用是同步的还是异步的,怎么配置与实现的?
📕作者简介:战斧,多年开发及管理经验,爱好广泛,致力于创作更多高质量内容
📗本文收录于 Dubbo专栏,有需要者,可直接订阅专栏实时获取更新
📘高质量专栏 RabbitMQ、Spring全家桶 等仍在更新,欢迎指导
📙Zookeeper Redis kafka docker netty等诸多框架,以及架构与分布式专题即将上线,敬请期待
一、暴露、引用、调用
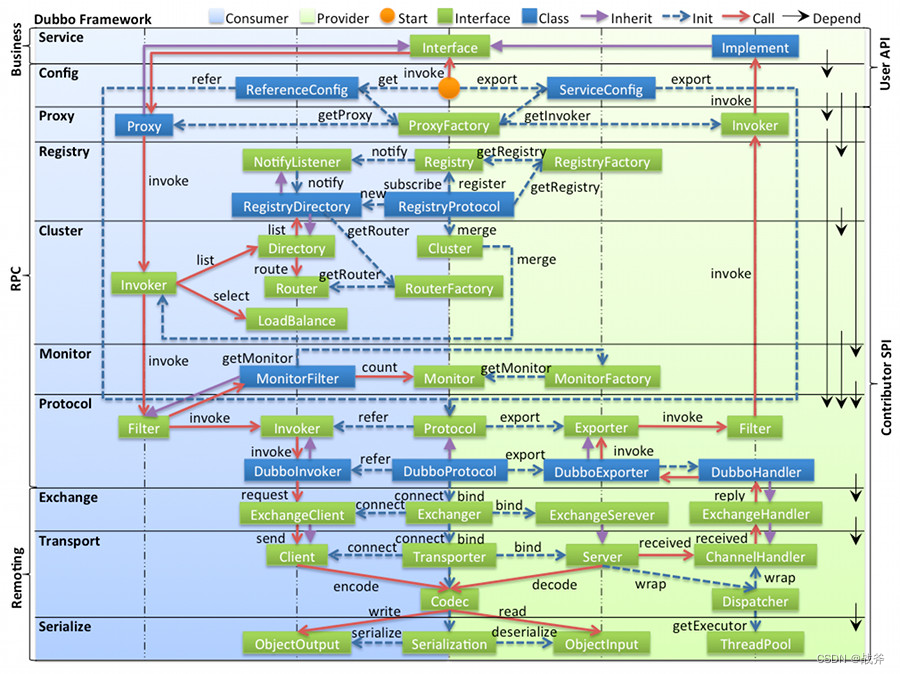
经过前面两期的详细介绍,各位应该明白了,服务的暴露与引用,其实对应着提供者和消费者。而今天要说的引用,则是由消费者发起,贯穿消费者与提供方的操作了。在此之前,我们将模型简化了,把服务暴露简化成一个exporter对象,而服务引用简化成Invoker对象,得到了下面的示意图:
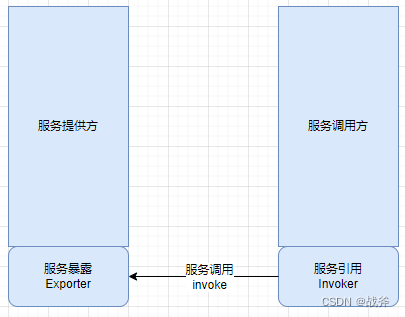
但真实情况远比这复杂,我们回头看一看我们在第一篇介绍Dubbo时的就贴过的全景图,我们其实只讲了两条箭头覆盖的部分,即从ReferenceConfig创建Invoker,和从ServiceConfig创建Exporter
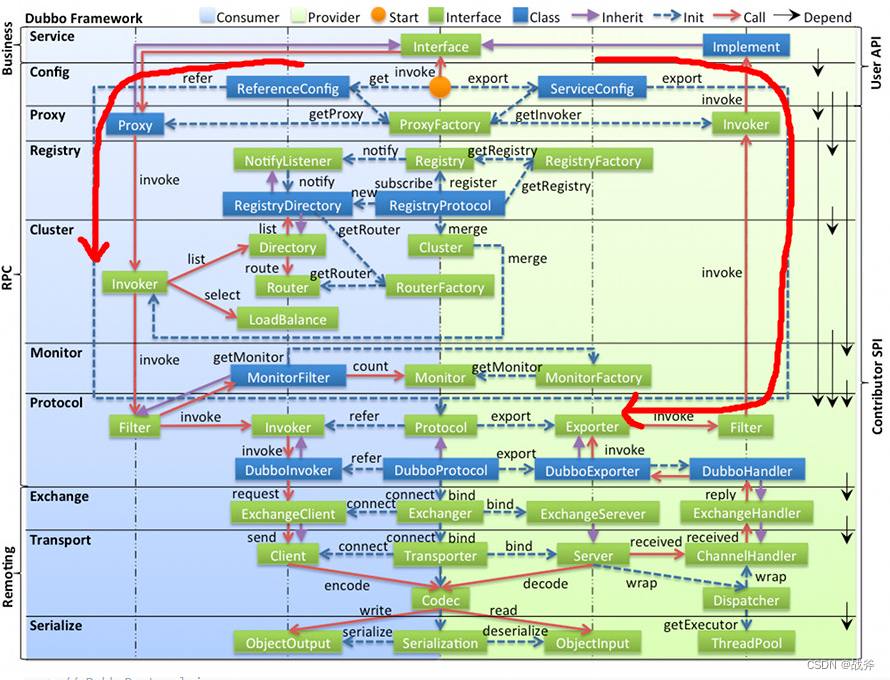
我么今天要说的部分其实就是从Invoker出发,到Exporter。
二、Invoker选调
在开始之前,我们必须先明白Dubbo中存在多个层级的Invoker,通过上面的图你也可以看见多个Invoker,事实上,这是Dubbo的一个设计特点,这里的Invoker是实体域,是 =Dubbo 的核心模型,其它模型都向它靠扰,或转换成它,它代表一个可执行体,你可以向它发起 invoke 调用,其接口信息如下:
public interface Invoker<T> extends Node {
Class<T> getInterface();
Result invoke(Invocation invocation) throws RpcException;
}
public interface Node {
URL getUrl();
boolean isAvailable();
void destroy();
}
它有可能是一个本地的实现,也可能是一个远程的实现,也可能一个集群实现。其有两个实现抽象类 AbstractClusterInvoker 和 AbstractInvoker,分别管理 cluster 层 和 方法包装体 invoker,如下图(dubbo 3.1.8):
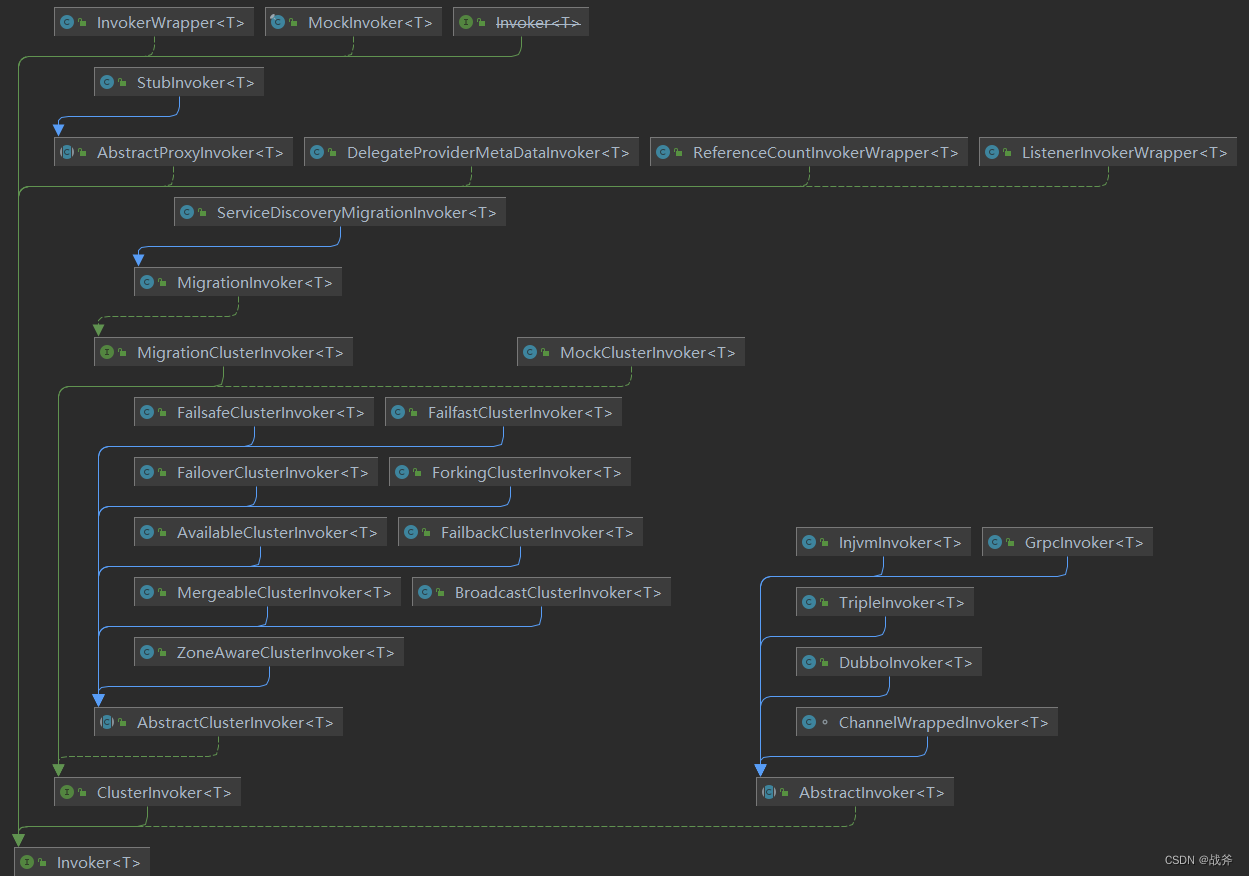
因此,这里必须先打个预防针,就是后续可能会出现大量invoker,甚至互相嵌套,所以希望大家先在脑海中建立一个层级观念,不要绕昏了。
1. 层层包装
我们上次说了服务引用,是在服务消费端建了代理,由代理全权负责进行RPC调用,上次在我们的Demo中,我们可以看到示例的代理内核其实是一个 MigrationInvoker对象,那么我们就从这个Invoker的产生及其作用来讲。
(强烈建议没有阅读过 《并不简单的代理,Dubbo是如何做服务引用的》的朋友先去看一下前文,尤其是第三章——引用的具体实现部分)
本次我们直接来看关键代码:
private void createInvokerForRemote() {
// ...
URL curUrl = urls.get(0);
// 通过指定的协议,寻找对应的SPI,产生调用器
invoker = protocolSPI.refer(interfaceClass, curUrl);
// 向注册中心注册性质的url, 不需要使用集群式的调用方式
if (!UrlUtils.isRegistry(curUrl) &&
!curUrl.getParameter(UNLOAD_CLUSTER_RELATED, false)) {
List<Invoker<?>> invokers = new ArrayList<>();
invokers.add(invoker);
invoker = Cluster.getCluster(getScopeModel(), Cluster.DEFAULT).join(new StaticDirectory(curUrl, invokers), true);
}
// ...
}

因为我们这是在进行注册,所以这里就转到了 RegistryProtocol.java实现类来进行处理,最终得到 migrationInvoker
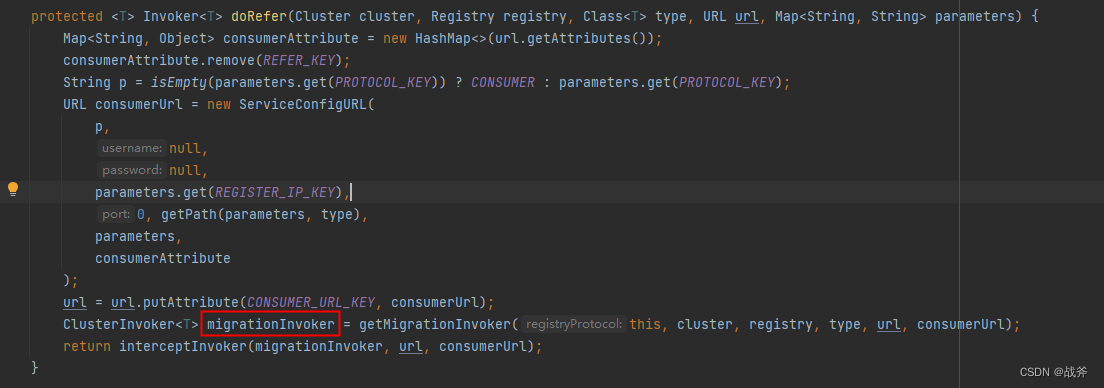
这里的 migrationInvoker 是Dubbo3特有的改造,其主要是用于在同一注册中心进行接口级迁移到实例级(早先版本的Dubbo登记在注册中心的都是一个个接口粒度的信息,3.0后升级为应用粒度,该类就有此兼容作用),我们至此获取了第一个Invoker,这个Invoker还会被包装在消费端的代理对象里。我们关心的是,当调用发生时,它做了什么呢?
public Result invoke(Invocation invocation) throws RpcException {
if (currentAvailableInvoker != null) {
if (step == APPLICATION_FIRST) {
// 基于随机值的调用率计算,默认就是100
if (promotion < 100 && ThreadLocalRandom.current().nextDouble(100) > promotion) {
// fall back to interface mode
return invoker.invoke(invocation);
}
// 从migrationInvoker获取可用的下一级的invoker,然后进行调用,当前其下一级invoker为MockClusterInvoker
return decideInvoker().invoke(invocation);
}
return currentAvailableInvoker.invoke(invocation);
}
// ...
}
我们可以看到,这里Invoker不出所料的发生了嵌套的情况,我们因此获得了MockClusterInvoker,这是Dubbo提供的一种Cluster Invoker的实现,如果你曾经接触过Mock相关的概念,不难理解它的作用是在服务调用失败时,返回一个预先定义好的Mock结果,当然,我们这里并没有预设任何东西。
然后又是一连串的过滤器链路: MockClusterInvoker - ClusterFilterInvoker - CallbackRegistrationInvoker - ConsumerContextFilter …。我们知道,随着设置的不同,这些链路可能随时改变,我们不会在此处细究
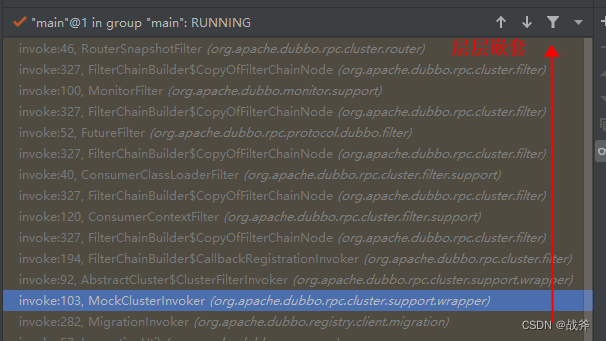
2. 集群决策
紧接着上方一大堆过滤器,我们再次遇见一个熟悉的东西 —— Invoker,这次它的名字叫做 FailoverClusterInvoker,如果翻译成中文,可以称之为故障转移集群调用器。
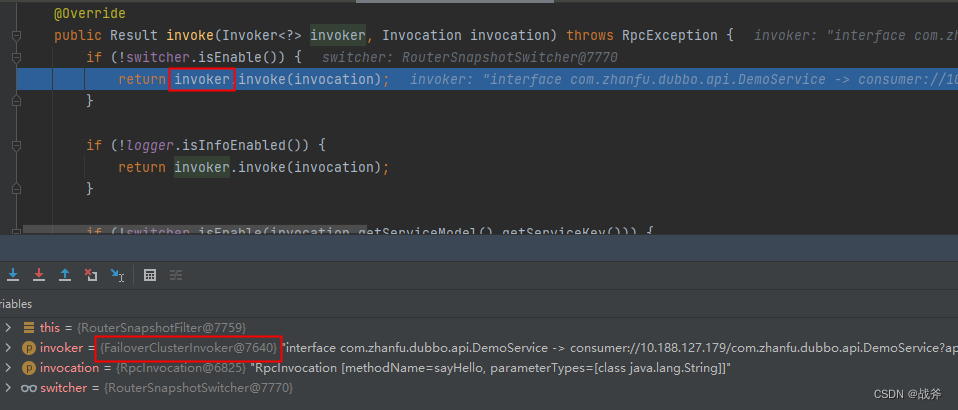
其实它的作用也很好猜,就是当调用失败时,会自动切换到集群其他可用的节点上进行调用,保障服务的可用性和稳定性,回顾上面的类图,还有像FailfastClusterInvoker、FailsafeClusterInvoker等类似的Invoker,这些Invoker都有一个共同的目的——集群容错处理,我们介绍其中最常用的几种:
- FailfastClusterInvoker
一旦某个节点出现故障,就立即返回失败,不做任何重试操作 - FailsafeClusterInvoker
出现故障时,直接忽略并记录日志,不做任何处理,适用于写操作等不需要保证一定执行成功的场景。 - FailbackClusterInvoker
出现故障时,会在后台进行重试,直到成功为止 - ForkingClusterInvoker
同时向多个节点发起调用,只要有一个节点成功返回就立即返回结果 - BroadcastClusterInvoker
向所有节点发起调用,所有节点都必须成功返回才能返回最终结果
上述这些invoker有着承上启下的作用,对上表现出只是一个Invoker对象,实际却控制着可用的集群及集群动作
3. 名录选调
可用列表
紧接着上面的集群invoker来讲,上述的那些具体的ClusterInvoker,都继承自 AbstractClusterInvoker,而且他们都没有实现 invoker 方法,这意味着他们都使用的是 AbstractClusterInvoker 的 invoker 方法,而这个方法接下来我们会反复回顾:
public Result invoke(final Invocation invocation) throws RpcException {
checkWhetherDestroyed();
InvocationProfilerUtils.enterDetailProfiler(invocation, () -> "Router route.");
// 罗列可用的远程调用
List<Invoker<T>> invokers = list(invocation);
InvocationProfilerUtils.releaseDetailProfiler(invocation);
LoadBalance loadbalance = initLoadBalance(invokers, invocation);
RpcUtils.attachInvocationIdIfAsync(getUrl(), invocation);
InvocationProfilerUtils.enterDetailProfiler(invocation, () -> "Cluster " + this.getClass().getName() + " invoke.");
try {
return doInvoke(invocation, invokers, loadbalance);
} finally {
InvocationProfilerUtils.releaseDetailProfiler(invocation);
}
}
这里我们看到个非常简洁的方法 list ,即从名录中获取可用的远程调用
protected List<Invoker<T>> list(Invocation invocation) throws RpcException {
return getDirectory().list(invocation);
}
这里的 Directory 其实有两种 StaticDirectory 和 DynamicDirectory,我们简单介绍下
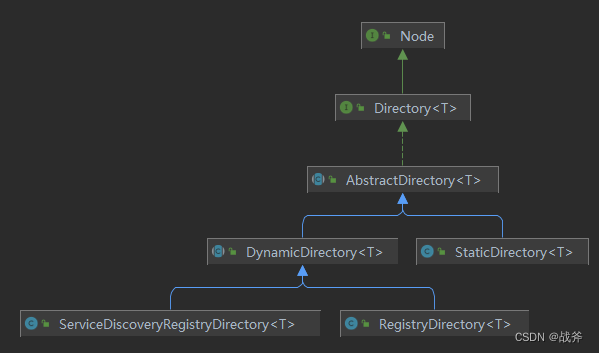
- StaticDirectory
静态目录,是在服务启动时就确定下来的目录,其中的服务提供者列表是静态的,不会在运行时发生变化,性能高 - DynamicDirectory
动态目录,会向注册中心订阅变化信息,然后根据变化信息动态更新服务提供者列表。动态目录的重建工作由RegistryDirectory和Cluster完成,性能低但灵活。
当然,自Dubbo 2.7后,DynamicDirectory又分为 RegistryDirectory 和 ServiceDiscoveryRegistryDirectory两种实现。
RegistryDirectory 依赖于注册中心的API来拉取服务提供者的列表,通过调用注册中心的API获取和监听当前的服务提供者列表。
而 ServiceDiscoveryRegistryDirectory来自2.7.*版本,基于服务发现,不依赖于具体的注册中心协议,而是使用了ServiceDiscovery这个抽象层来获取服务提供者列表,有着更好的动态更新和扩展性,提供了更高级的服务发现和治理功能
而我们这里使用的依然是 RegistryDirectory,如下图,最终获得所有可用的调用列表,因为Demo,我只起了一个服务提供者,这里自然也只有一个可用的远程调用。
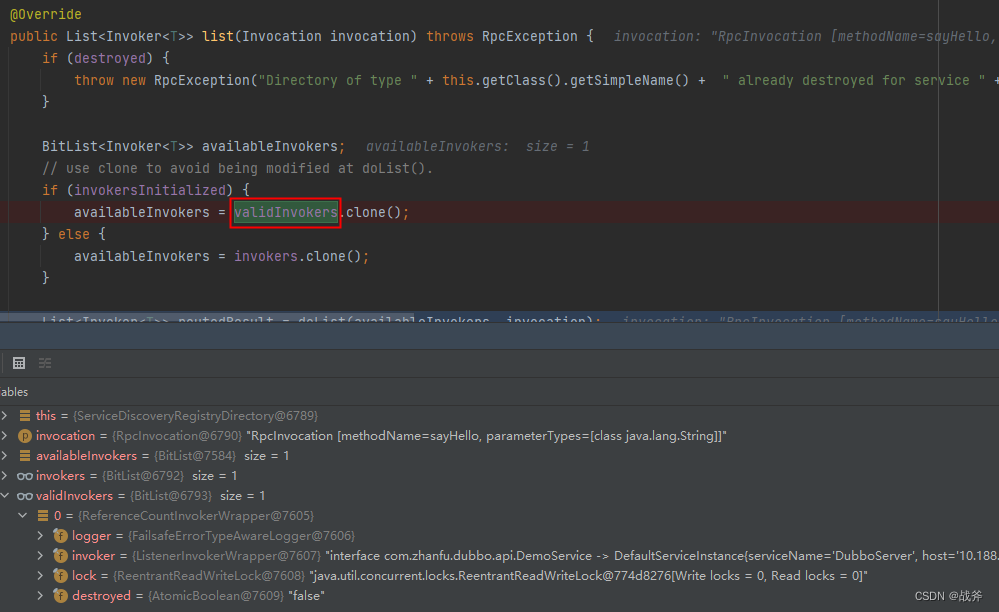
路由筛选
获取到所有可用的远程后,并没有结束,我们还可以通过配置路由规则来对这些服务提供方进行筛选,拿到子集。路由的配置也有很多种,如条件路由 、标签路由、 脚本路由,以官方条件路由的例子来说明:
如果要将所有 org.apache.dubbo.samples.CommentService 服务 getComment 方法的调用都将被转发到有region=Hangzhou 标记的地址子集
你需要这么配置:
configVersion: v3.0
scope: service
force: true
runtime: true
enabled: true
key: org.apache.dubbo.samples.CommentService
conditions:
- method=getComment => region=Hangzhou
当然,如果你有使用monitor,可以直接在页面上进行设置,会更加直观
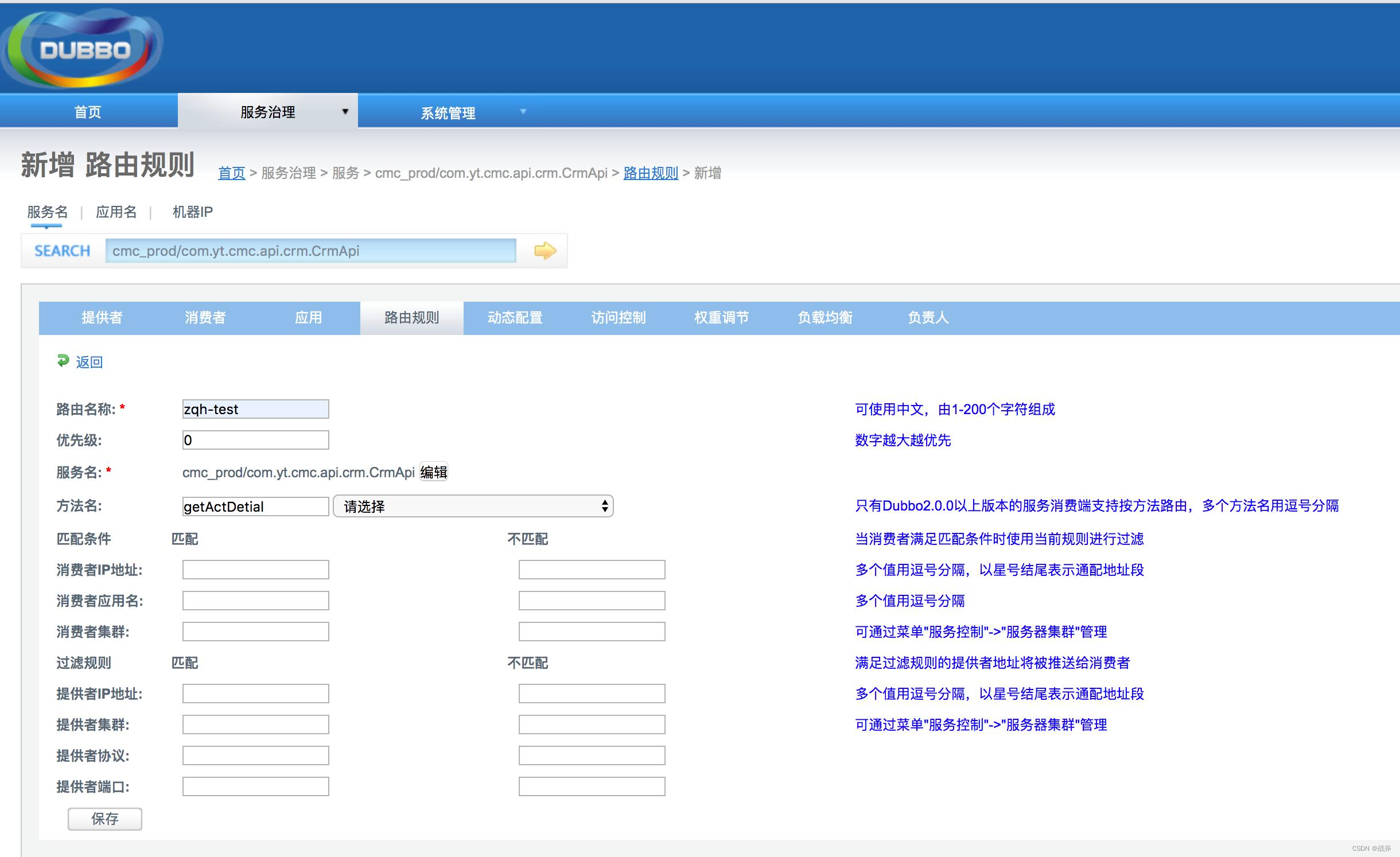
在代码中定位的话,同样就是在AbstractDirectory中的 doList:
public List<Invoker<T>> doList(BitList<Invoker<T>> invokers, Invocation invocation) {
// ...
try {
// 拿当前运行中的所有路由筛一遍,全部满足的才能加入路由筛选的子集
List<Invoker<T>> result = routerChain.route(getConsumerUrl(), invokers, invocation);
return result == null ? BitList.emptyList() : result;
} catch (Throwable t) {
// 2-1 - Failed to execute routing.
logger.error(CLUSTER_FAILED_SITE_SELECTION, "", "",
"Failed to execute router: " + getUrl() + ", cause: " + t.getMessage(), t);
return BitList.emptyList();
}
}
其中核心方法就是RouterChain的遍历筛选,并返回最终结果
public List<Invoker<T>> simpleRoute(URL url, BitList<Invoker<T>> availableInvokers, Invocation invocation) {
BitList<Invoker<T>> resultInvokers = availableInvokers.clone();
// 1. route state router
resultInvokers = headStateRouter.route(resultInvokers, url, invocation, false, null);
if (resultInvokers.isEmpty() && (shouldFailFast || routers.isEmpty())) {
printRouterSnapshot(url, availableInvokers, invocation);
return BitList.emptyList();
}
if (routers.isEmpty()) {
return resultInvokers;
}
List<Invoker<T>> commonRouterResult = resultInvokers.cloneToArrayList();
// 2. route common router
for (Router router : routers) {
// 一次次遍历后,剩下的结果赋值到 commonRouterResult,并最终返回
RouterResult<Invoker<T>> routeResult = router.route(commonRouterResult, url, invocation, false);
commonRouterResult = routeResult.getResult();
if (CollectionUtils.isEmpty(commonRouterResult) && shouldFailFast) {
printRouterSnapshot(url, availableInvokers, invocation);
return BitList.emptyList();
}
// stop continue routing
if (!routeResult.isNeedContinueRoute()) {
return commonRouterResult;
}
}
if (commonRouterResult.isEmpty()) {
printRouterSnapshot(url, availableInvokers, invocation);
return BitList.emptyList();
}
return commonRouterResult;
}
4. 负载均衡
经过目录选调之后,剩下的子集都是符合规则的了,但是Dubbo并没有就直接按照集群决策,就随意使用这些子集,而是提供了另一个功能——负载均衡,我们再来看名录选调中看过的那块代码:
// AbstractClusterInvoker.java
public Result invoke(final Invocation invocation) throws RpcException {
checkWhetherDestroyed();
InvocationProfilerUtils.enterDetailProfiler(invocation, () -> "Router route.");
// 罗列可用的远程调用
List<Invoker<T>> invokers = list(invocation);
InvocationProfilerUtils.releaseDetailProfiler(invocation);
// 获取负载均衡实现
LoadBalance loadbalance = initLoadBalance(invokers, invocation);
RpcUtils.attachInvocationIdIfAsync(getUrl(), invocation);
InvocationProfilerUtils.enterDetailProfiler(invocation, () -> "Cluster " + this.getClass().getName() + " invoke.");
try {
return doInvoke(invocation, invokers, loadbalance);
} finally {
InvocationProfilerUtils.releaseDetailProfiler(invocation);
}
}
所谓负载均衡实现,其实又是一个SPI设计,试图从子集第一个元素的url中获取设置的负载均衡信息,倘若没有,则走的默认的负载均衡类型 —— 随机
protected LoadBalance initLoadBalance(List<Invoker<T>> invokers, Invocation invocation) {
ApplicationModel applicationModel = ScopeModelUtil.getApplicationModel(invocation.getModuleModel());
if (CollectionUtils.isNotEmpty(invokers)) {
return applicationModel.getExtensionLoader(LoadBalance.class).getExtension(
invokers.get(0).getUrl().getMethodParameter(
RpcUtils.getMethodName(invocation), LOADBALANCE_KEY, DEFAULT_LOADBALANCE
)
);
} else {
return applicationModel.getExtensionLoader(LoadBalance.class).getExtension(DEFAULT_LOADBALANCE);
}
}
而Dubbo 同样内置了多种负载均衡,这是官网的一张表格

5. 调用逻辑
经过一系列的筛选,并且确定了集群策略和负载均衡策略后,我们终于来到了真实调用的位置,以下就是
FailoverClusterInvoker 的 doInvoke 方法,可以看到计算了重试次数和通过负载均衡找到服务提供方后,我们开始了远程调用
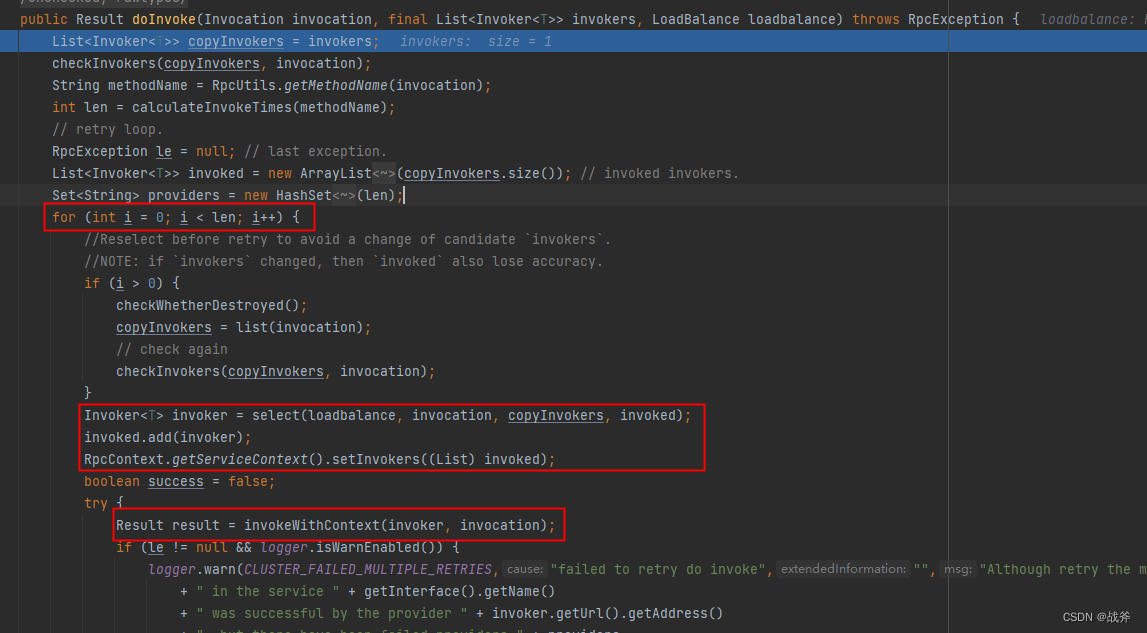
此时又开始了Invoker的链路,这里的 invoker 为 ReferenceCountInvokerWrapper - ListenerInvokerWrapper,这里仅简单介绍下这两层Wrapper(也是Invoker的实现类)
ReferenceCountInvokerWrapper是一个包装器,用于管理远程服务对象的引用计数。它可以确保在远程服务不再使用时,正确地释放和销毁服务对象,以避免资源泄漏和性能问题
ListenerInvokerWrapper则用于监听Dubbo的服务注册、注销、调用等事件。由它实现一个分布式的事件通知机制,用于协调和管理系统中的各个组件
最终的最终,我们得到了关键的DubboInvoker,这也是我们在上面整体结构图中RPC层级的最底层了

我们可以看到,到这里为止,方法已经转变成了贴近网络通信语境的 request
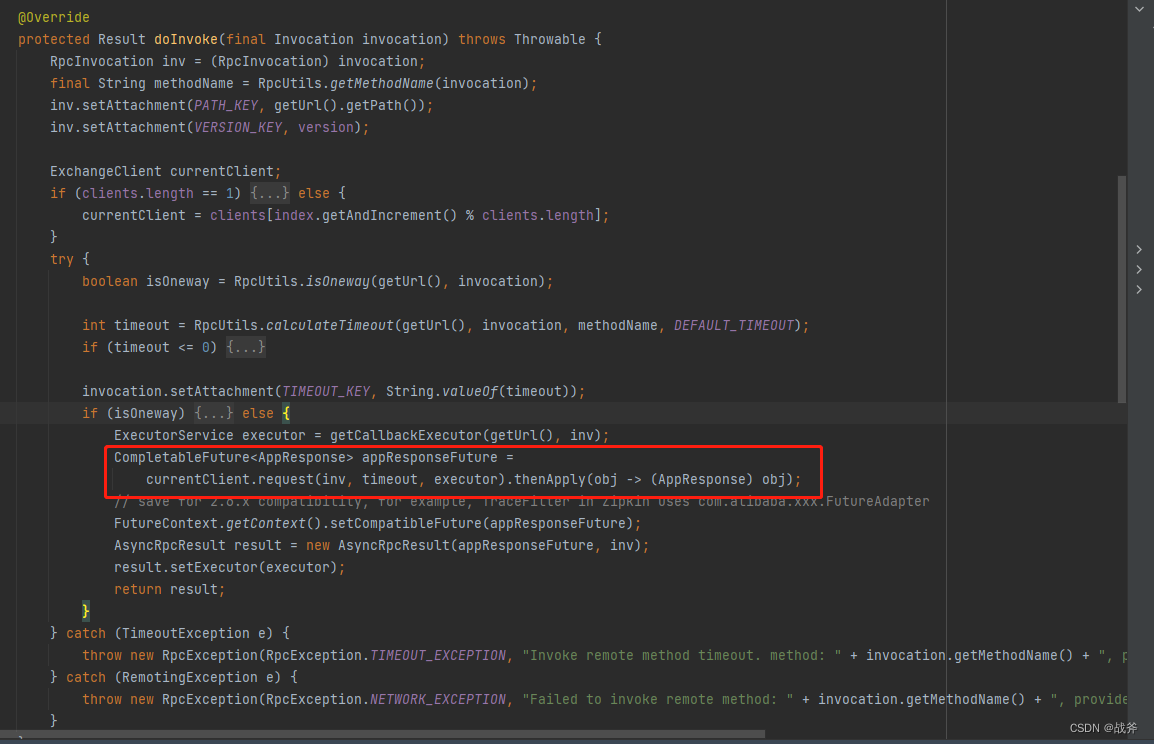
// ReferenceCountExchangeClient
@Override
public CompletableFuture<Object> request(Object request, int timeout, ExecutorService executor) throws RemotingException {
return client.request(request, timeout, executor);
}
我们着重看一下,此时request对象属于Rpcinvocation类,该对象承载的信息如下图所示。
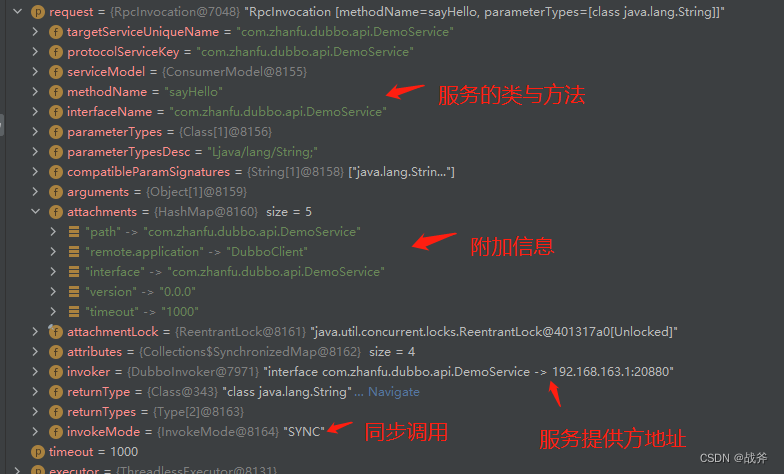
那么到现在为止,我们可以说在服务调用这方面已经结束,接下来主要的工作就是将该请求信息发送到指定服务器去执行了、
三、网络通信
1. Exchange
在进行通讯的时候,Dubbo定义了Exchange这样的部分,也就是说提供了一种统一的消息交换机,使得服务消费者和提供者可以进行可靠的通信。它封装了底层的网络细节,处理网络的传输、编解码、序列化和反序列化等操作。
通过Exchange,Dubbo可以支持多种通信协议(如Dubbo, HTTP ,RMI)和序列化协议(如Hession, JSON, Protobuf)等。其主要有两个接口和其实现类组成
-
ExchangeClient(接口):用于在消费者端发送请求和接收响应。它定义了发送请求、接收响应和关闭连接等方法。
-
ExchangeServer(接口):在提供者端用于接收请求并发送响应。它定义了启动服务器、接收请求、发送响应和关闭服务器等方法。
-
Exchanger(SPI接口):是Exchange的核心接口,用于创建客户端和服务器端的实例。
-
HeaderExchangeClient:是ExchangeClient接口的默认实现类,负责在消费者端处理请求和响应的编解码、序列化和反序列化等操作。
-
HeaderExchangeServer:是ExchangeServer接口的默认实现类,负责在提供者端处理请求和响应的编解码、序列化和反序列化等操作
2. Netty
当然,Dubbo并没有真正复写底层的通信代码,而是采用了另一个专业的网络框架——Netty,这个框架笔者看源码是也是深感佩服,对性能的强调,要求是非常高的。Dubbo 则是嫁接在其之上,利用 Netty 的客户端与服务端进行通信的,当然,作为发送请求的消费者,自然是客户端。而接收请求的服务提供方,则是服务端(概念上的)
当然,关于Netty的部分,我们不可能在这里进行讲解,我们只需要知道,Dubbo的通信底层是调用的高性能网络通信框架Netty即可,关于Netty框架的讲解,我们会在一个新的系列中进行。
四、服务执行
1. 消息接收
其实通过上面的网络章节就能看出来。真正的通信都是依赖于Netty实现的,因此在消息接收上,依赖的也是Netty的机制。如下图,Dubbo内置着Netty的服务端
那抛去这一部分。那Dubbo本身做了怎样的准备呢?消息经由一个分发器Dispatcher(SPI接口)的自适应实现类实现分发后,然后由一个handler链来处理。
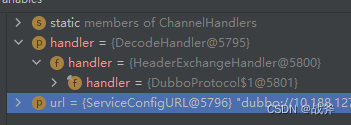
至此,我们就看到了exchange层次的另一个重要类 HeaderExchangeHandler,当消息发送来时,会触发其执行 received - handleRequest 方法
void handleRequest(final ExchangeChannel channel, Request req) throws RemotingException {
Response res = new Response(req.getId(), req.getVersion());
Object msg = req.getData();
try {
// 此处的handler 为 DubboProtocol.ExchangeHandler
CompletionStage<Object> future = handler.reply(channel, msg);
future.whenComplete((appResult, t) -> {
try {
if (t == null) {
res.setStatus(Response.OK);
res.setResult(appResult);
} else {
res.setStatus(Response.SERVICE_ERROR);
res.setErrorMessage(StringUtils.toString(t));
}
// 此处为返回响应
channel.send(res);
} catch (RemotingException e) {
logger.warn(TRANSPORT_FAILED_RESPONSE, "", "", "Send result to consumer failed, channel is " + channel + ", msg is " + e);
}
});
} catch (Throwable e) {
res.setStatus(Response.SERVICE_ERROR);
res.setErrorMessage(StringUtils.toString(e));
channel.send(res);
}
}
2. 获取服务并调用
DubboProtocol.ExchangeHandler.reply 中有一个重要方法
Invoker<?> invoker = getInvoker(channel, inv);
我们仔细来看看这个方法:DubboProtocol.getInvoker。
Invoker<?> getInvoker(Channel channel, Invocation inv) throws RemotingException {
// ...
String serviceKey = serviceKey(
port,
path,
(String) inv.getObjectAttachmentWithoutConvert(VERSION_KEY),
(String) inv.getObjectAttachmentWithoutConvert(GROUP_KEY)
);
DubboExporter<?> exporter = (DubboExporter<?>) exporterMap.get(serviceKey);
if (exporter == null) {
throw new RemotingException(channel, "Not found exported service: " + serviceKey + " in " + exporterMap.keySet() + ", may be version or group mismatch " +
", channel: consumer: " + channel.getRemoteAddress() + " --> provider: " + channel.getLocalAddress() + ", message:" + getInvocationWithoutData(inv));
}
return exporter.getInvoker();
}
如果看过之前的 Dubbo最核心功能——服务暴露的配置、使用及原理 话,看到 exporterMap 就已经明白了,我们曾经说过,服务的暴露最终就存在这样的 exporterMap 里,键为接口信息,此处为com.zhanfu.dubbo.api.DemoService:20880; 值就是对该接口实现类的包装


那么没有悬念的,最终拿到了我们在服务暴露时生成的exporter,如果你没忘,当时我们举得是injvm的例子,这次我们是在进行真实的RPC调用,当然,他们invoker生成的形式是一样的,都是在 ServiceConfig.doExportUrl 里
// 前情回顾
private void doExportUrl(URL url, boolean withMetaData) {
Invoker<?> invoker = proxyFactory.getInvoker(ref, (Class) interfaceClass, url); if (withMetaData) { invoker = new DelegateProviderMetaDataInvoker(invoker, this); } Exporter<?> exporter = protocolSPI.export(invoker);
exporters.add(exporter); }
而此刻,我们获得了这个invoker,一般情况下,这个 invoker 也是被FilterChain层层包裹着的,比如我们在消费端就见过的 CallbackRegistrationInvoker ,以及profileServerFilter 、EchoFilter等等很多中间层

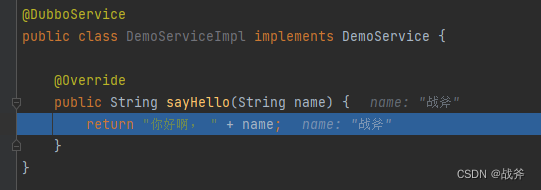
最终,到达了我们想要的那一层,也就是所谓的代理Invoker —— AbstractProxyInvoker,这个Invoker对象内包含了我们服务的实现类,如下图:

而该代理其实是由javassistProxyFactory负责创建的,所以这个代理的调用方法是早就被定义好的,就是执行目标方法的调用,而所谓目标自然就是我们的服务实现类
return new AbstractProxyInvoker<T>(proxy, type, url) {
@Override
protected Object doInvoke(T proxy, String methodName,
Class<?>[] parameterTypes,
Object[] arguments) throws Throwable {
return wrapper.invokeMethod(proxy, methodName, parameterTypes, arguments);
}
}
五、返回结果
1. 提供方返回
终于走到了整个流程的最后一个步骤,也就是服务执行完的结果返回。
对于服务提供者来说,要做的就是把刚刚的嵌套再走一遍,栈帧一层层退出并把结果返回。直到我们的Exchange层,我们再来看一遍 HeaderExchangeHandler 的核心代码
void handleRequest(final ExchangeChannel channel, Request req) throws RemotingException {
// ...
CompletionStage<Object> future = handler.reply(channel, msg);
// 在异步任务完成后会触发下列方法,最终返回数据
future.whenComplete((appResult, t) -> {
try {
if (t == null) {
res.setStatus(Response.OK);
res.setResult(appResult);
} else {
res.setStatus(Response.SERVICE_ERROR);
res.setErrorMessage(StringUtils.toString(t));
}
channel.send(res);
} catch (RemotingException e) {
logger.warn(TRANSPORT_FAILED_RESPONSE, "", "", "Send result to consumer failed, channel is " + channel + ", msg is " + e);
}
});
// ...
}
很直观的可以看见,处理完的结果会用同一个channel往回进行消息发送。发送的内容就包含了方法的返回值mResult。
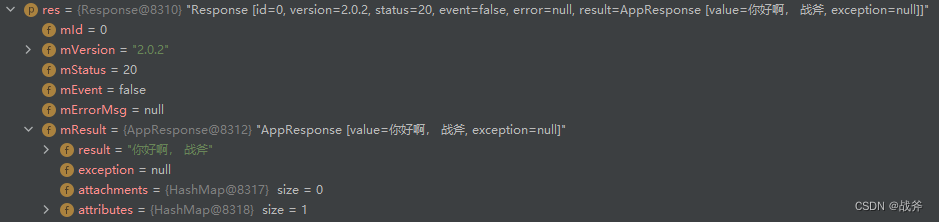
2. 消费方获取结果
当然,我们更关心的部分在于,对于服务消费者,收到这个消息该怎么返回至原方法,这一切通信是同步还是异步的?如果是异步,又该怎么找到这一笔返回结果对应着哪次请求呢?
别急,我们回到上文出现过的DubboInvoker的这张图
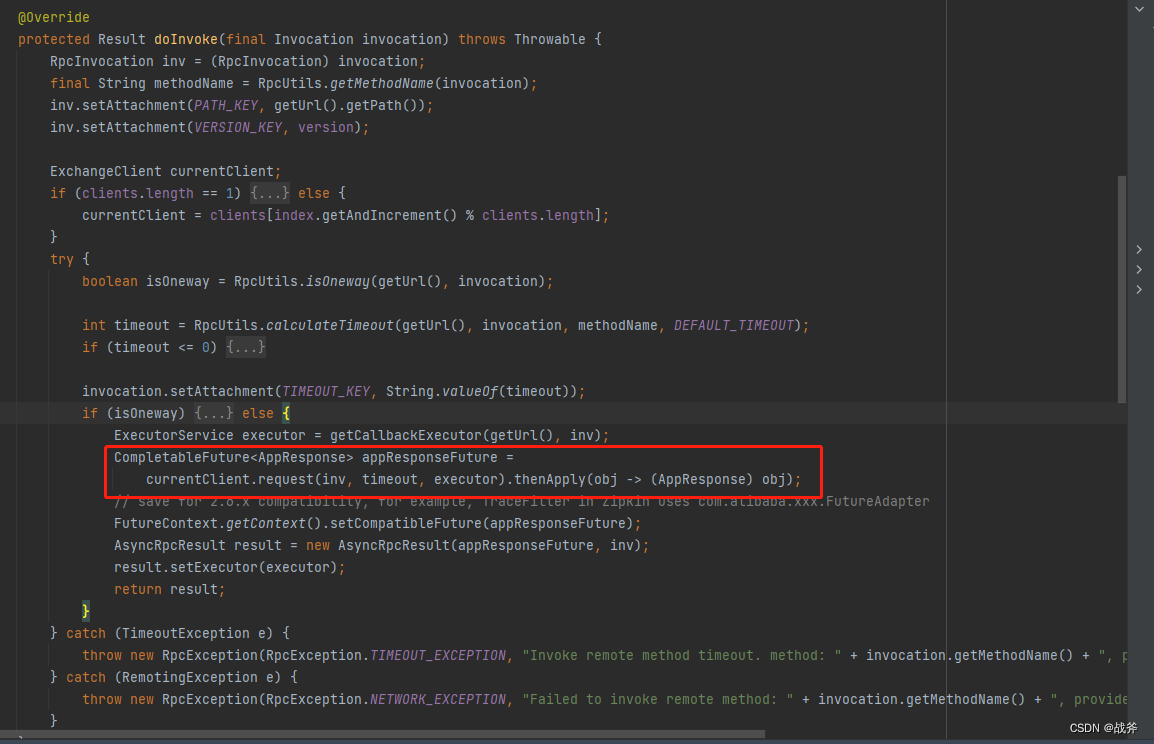
我们可以看到,请求发送后形成的是一个CompletableFuture 的子类 DefaultFuture,这个对象属于个即刻返回的对象,但并不代表该对象里有返回值。不了解这个的也可以去看 JUC基础(二)—— Future接口 及其实现,我们先看这个Future的创建,可以看到,我们在这个Future静态属性里对象里面保存了请求id与本Future的关系,这一点很关键。
private static final Map<Long, Channel> CHANNELS = new ConcurrentHashMap<>();
private static final Map<Long, DefaultFuture> FUTURES = new ConcurrentHashMap<>();
private DefaultFuture(Channel channel, Request request, int timeout) {
this.channel = channel;
this.request = request;
this.id = request.getId();
this.timeout = timeout > 0 ? timeout : channel.getUrl().getPositiveParameter(TIMEOUT_KEY, DEFAULT_TIMEOUT);
// put into waiting map.
FUTURES.put(id, this);
CHANNELS.put(id, channel);
}
紧接着,我们把这个 Future 放进了关键类 AsyncRpcResult 中,至此,还没有什么问题,然后DubboInvoker就把这个 AsyncRpcResult返回给上层 AbstractInvoker了,而这里才是真正获取结果的位置
public Result invoke(Invocation inv) throws RpcException {
RpcInvocation invocation = (RpcInvocation) inv;
// 准备调用
prepareInvocation(invocation);
// 调用并返回同步结果
AsyncRpcResult asyncResult = doInvokeAndReturn(invocation);
// 如果是同步的话等待远程结果返回
waitForResultIfSync(asyncResult, invocation);
return asyncResult;
}
我们关注 waitForResultIfSync方法,其中的核心代码就两个:如果是采用同步调用模式,或者本次调用时同步调用,就需要先获取远程值,即最终进入就是我们说的那个 AsyncRpcResult进行获取。如果都不是同步,则直接把半成品 asyncResult 返回。默认都是采用的同步调用,怎么设置成异步呢?
可以通过注解@DubboReference,@DubboService 的 async 属性可以进行设置,又或者如下的xml配置
<!-- 服务提供者配置 -->
<dubbo:service interface="com.zhanfu.dubbo.api" ref="demoService" async="true"/>
<!-- 服务消费者配置 -->
<dubbo:reference id="demoService" interface="com.zhanfu.dubbo.api" async="true"/>
因为默认采用的都是同步,在我们的Demo中,随后会进入阻塞获取阶段
private void waitForResultIfSync(AsyncRpcResult asyncResult, RpcInvocation invocation) {
if (InvokeMode.SYNC != invocation.getInvokeMode()) {
return;
}
try {
Object timeoutKey = invocation.getObjectAttachmentWithoutConvert(TIMEOUT_KEY);
long timeout = RpcUtils.convertToNumber(timeoutKey, Integer.MAX_VALUE);
asyncResult.get(timeout, TimeUnit.MILLISECONDS);
} catch (InterruptedException e)
// ...
}
}
不出所料,最后进行的其实还是利用了 Future.get 来进行阻塞获取。但这里,我们还需要留心上方的 waitAndDrain 方法,这个方法会去驱动线程池执行代办任务,所谓的代办其实就是如果有消息,得有个线程去处理消息。
public Result get(long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException {
if (executor != null && executor instanceof ThreadlessExecutor) {
ThreadlessExecutor threadlessExecutor = (ThreadlessExecutor) executor;
threadlessExecutor.waitAndDrain();
}
return responseFuture.get(timeout, unit);
}
但是远程的结果不可能突然就准备好了,这中间一定还有一个事件触发,最终准备好返回结果,然后 Future.get 才得以返回。
3. 事件触发
信道事件本身属于通信的范畴,我们此次并不细说,但是我们知道信道事件的发生,最终会触发一系列我们设置的处理器去执行,其中又包含了我们屡次提到的 HeaderExchangeHandler,不过当时我们看的还是 handleRequest,现在我们要看 handleResponse了
static void handleResponse(Channel channel, Response response) throws RemotingException {
if (response != null && !response.isHeartbeat()) {
DefaultFuture.received(channel, response);
}
}
而此时的Response就是返回值的包装了

最终的设置结果,通过 complete 方法把结果值塞进 CompletableFuture 的 result 属性,然后唤醒阻塞的线程
private void doReceived(Response res) {
if (res == null) {
throw new IllegalStateException("response cannot be null");
}
if (res.getStatus() == Response.OK) {
this.complete(res.getResult());
} else if (res.getStatus() == Response.CLIENT_TIMEOUT || res.getStatus() == Response.SERVER_TIMEOUT) {
this.completeExceptionally(new TimeoutException(res.getStatus() == Response.SERVER_TIMEOUT, channel, res.getErrorMessage()));
} else {
this.completeExceptionally(new RemotingException(channel, res.getErrorMessage()));
}
// ...
}
六、总结
至此,我们完整的看完了服务暴露、引用、调用的方法。不难体会到,Dubbo本身很好的完成了一个RPC框架的任务,除此以外,它利用SPI提供的众多扩展点形成了庞大的自定义体系,而且具有服务注册、发现、容错、路由、负载均衡、异步调用等诸多功能,这些都给予了Dubbo突破一般RPC框架的底气,而且其通讯底层采用了高性能框架Netty,网络通信效率亦是有所保障。当然,对于开发者来说,最舒心的还是它与Spring框架的适配非常融洽,使得我们可以靠注解完成大部分配置
不过,我们的学习才刚刚开始,了解了整体的流程以及基本原理后,我们还会对Dubbo 的配置、监控、功能细节、新特性进行讲解;当然,也会进行一些面试题的QA,感兴趣的可以直接订阅Dubbo 专栏获取最新的解读