链表是一种常见的数据结构,广泛应用于计算机科学中。C语言提供了丰富的指针操作,使得链表的实现相对简便。本博客将介绍链表的基本概念,以及使用C语言实现链表的代码示例。
目录
一、链表的基本概念
二、链表的分类
三、通俗例子:学生管理系统
一、链表的基本概念
链表是由节点(Node)组成的数据结构,每个节点包含两个部分:数据域和指针域。数据域用于存储数据,指针域用于指向下一个节点。链表的起点为头节点(Head),尾节点的指针域为NULL。
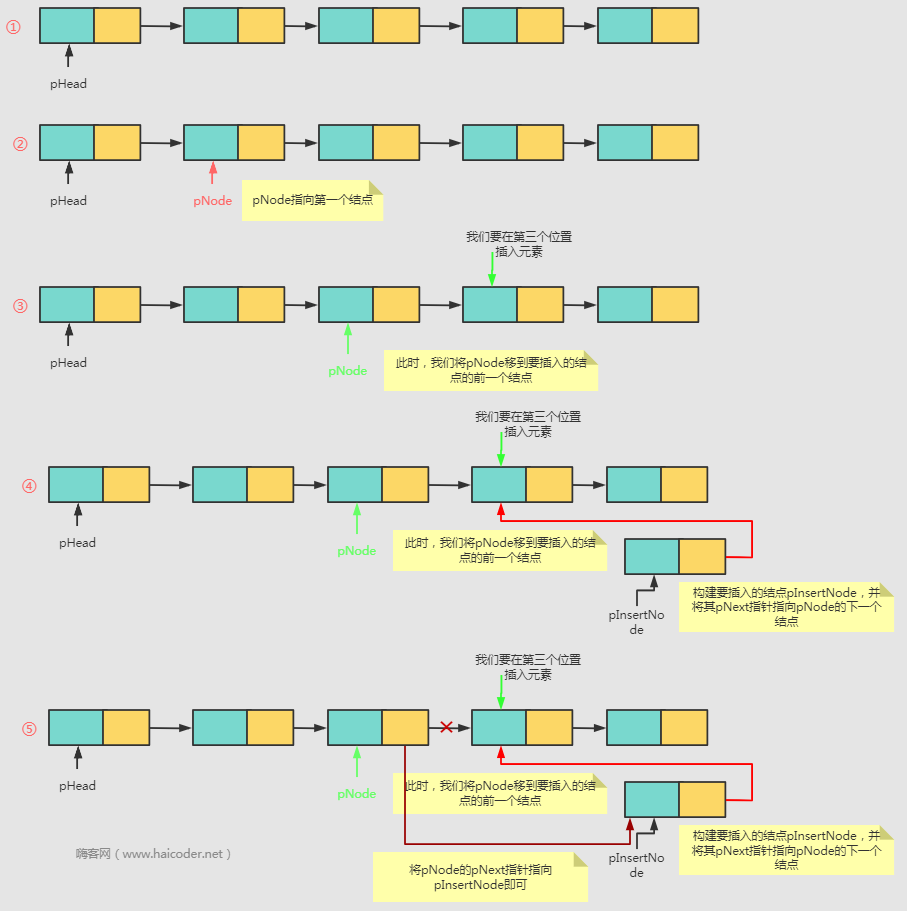
链表的特点包括:动态性(可以灵活地添加或删除节点)、内存利用率高、插入和删除操作效率高。然而,链表的查询效率较低,需要遍历整个链表才能找到目标节点。
二、链表的分类

1. 单链表(Singly Linked List):单链表是最基本的链表类型,每个节点包含一个数据域和一个指向下一个节点的指针。它只能从头节点开始顺序访问,无法回溯到前一个节点。
示例代码:
#include <stdio.h>
#include <stdlib.h>
typedef struct Node {
int data;
struct Node* next;
} Node;
void printList(Node* head) {
Node* current = head;
while (current != NULL) {
printf("%d ", current->data);
current = current->next;
}
}
// 在链表尾部插入新节点
void insert(Node** head, int data) {
Node* newNode = (Node*)malloc(sizeof(Node));
newNode->data = data;
newNode->next = NULL;
if (*head == NULL) {
*head = newNode;
} else {
Node* current = *head;
while (current->next != NULL) {
current = current->next;
}
current->next = newNode;
}
}
int main() {
Node* head = NULL;
insert(&head, 1);
insert(&head, 2);
insert(&head, 3);
printList(head);
return 0;
}2. 双向链表(Doubly Linked List):双向链表中的每个节点都有两个指针,一个指向前一个节点,一个指向后一个节点。相比于单链表,双向链表可以进行双向遍历和删除操作,但在插入和删除节点时需要维护更多的指针关系。
示例代码:
#include <stdio.h>
#include <stdlib.h>
typedef struct Node {
int data;
struct Node* prev;
struct Node* next;
} Node;
void printList(Node* head) {
Node* current = head;
while (current != NULL) {
printf("%d ", current->data);
current = current->next;
}
}
void insert(Node** head, int data) {
Node* newNode = (Node*)malloc(sizeof(Node));
newNode->data = data;
newNode->prev = NULL;
newNode->next = NULL;
if (*head == NULL) {
*head = newNode;
} else {
Node* current = *head;
while (current->next != NULL) {
current = current->next;
}
newNode->prev = current;
current->next = newNode;
}
}
int main() {
Node* head = NULL;
insert(&head, 1);
insert(&head, 2);
insert(&head, 3);
printList(head);
return 0;
}3. 循环链表(Circular Linked List):循环链表是一种特殊的链表,最后一个节点的指针指向第一个节点,形成一个闭环。循环链表可以无限循环地遍历,常用于构建循环队列等数据结构。
示例代码:
#include <stdio.h>
#include <stdlib.h>
typedef struct Node {
int data;
struct Node* next;
} Node;
void printList(Node* head) {
Node* current = head;
if (head == NULL) {
return;
}
do {
printf("%d ", current->data);
current = current->next;
} while (current != head);
}
void insert(Node** head, int data) {
Node* newNode = (Node*)malloc(sizeof(Node));
newNode->data = data;
newNode->next = NULL;
if (*head == NULL) {
*head = newNode;
newNode->next = newNode;
} else {
Node* last = *head;
while (last->next != *head) {
last = last->next;
}
newNode->next = *head;
last->next = newNode;
}
}
int main() {
Node* head = NULL;
insert(&head, 1);
insert(&head, 2);
insert(&head, 3);
printList(head);
return 0;
}4. 静态链表(Static Linked List):静态链表是使用数组实现的链表,而不是使用指针。通过数组的下标关系来模拟节点之间的链接关系。静态链表的缺点是大小固定,插入和删除节点不方便,但由于不需要指针的额外存储空间,具有一定的存储效率。
5. 带头结点链表(Head Linked List):带头结点的链表在链表开始部分添加了一个额外的头节点,用于简化链表的操作。头节点不存储具体的数据,仅用于指向第一个真正的节点,有助于统一处理链表的边界情况。
6. 带环链表(Cyclic Linked List):带环链表是一种特殊的链表,其中某个节点的指针指向链表中的一个前面的节点,形成环状结构。带环链表常用于解决一些与环有关的算法问题,如判断链表中是否存在环、找到环的起点等。
三、通俗例子:学生管理系统
假设我们要存储一组人的信息,每个人有姓名和年龄两个属性。如果使用数组来存储这些人的信息,可能会遇到一个问题:数组的大小是固定的,无法动态地添加或删除人员。这时候链表就派上用场了。
我们可以将链表看作是一个班级的人员名册。每个节点表示一个人,其中数据域存储着该人的姓名和年龄,指针域则指向下一个人。
现在,我们以一个简单的链表为例来说明。
假设我们有以下链表:
-> [Alice, 25] -> [Bob, 30] -> [Charlie, 35] -> [Diana, 40] -> NULL其中箭头表示指针,指向下一个节点。
在这个链表中,每个节点都包含两个部分:数据域和指针域。数据域存储人员的姓名和年龄,指针域则指向下一个人员节点。
我们可以从头节点(最前面的节点)开始,依次遍历整个链表,获取每个人员的信息。
通过链表,我们可以轻松地添加新的人员信息。比如,假设我们要插入一个叫"Eva"、年龄为28岁的人,只需在链表尾部添加一个新节点:
-> [Alice, 25] -> [Bob, 30] -> [Charlie, 35] -> [Diana, 40] -> [Eva, 28] -> NULL或者,我们也可以在链表中间插入一个新节点,比如将"Bob"后面插入一个叫"Frank"、年龄为32岁的人:
-> [Alice, 25] -> [Bob, 30] -> [Frank, 32] -> [Charlie, 35] -> [Diana, 40] -> NULL此外,我们还可以轻松地删除链表中的人员信息。比如,我们要删除年龄为35岁的"Charlie",只需要将指向"Charlie"的指针跳过,让它指向"Charlie"后面的节点:
-> [Alice, 25] -> [Bob, 30] -> [Frank, 32] -> [Diana, 40] -> NULL通过这个通俗的例子,我们可以更好地理解链表的概念。链表具有动态存储、灵活插入和删除的特性,可以解决一些固定大小的数据结构无法满足的需求。对于需要经常进行插入和删除操作的场景,链表是一个非常有用的数据结构。