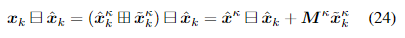论文链接:MonoDTR: Monocular 3D Object Detection with Depth-Aware Transformer
1. 解决了什么问题?
单目 3D 目标检测对于自动驾驶很重要,也很有挑战性。
现有的一些方法通过深度预测网络得到深度信息,然后辅助 3D 检测,这造成计算量激增,不适合实际部署。此外,如果深度先验不准确的话,也会影响算法的表现。如下图(a),Pseudo-LiDAR 方法通过单目深度估计将图像升成 3D 坐标,将预测的深度图转换为 3D 点云,模拟 LiDAR 信号,然后用 LiDAR 检测器来做 3D 目标检测。如下图(b),另一类基于融合的方法则使用多种融合策略,从图像和预测的深度图提取特征,然后将深度特征和图像特征融合,以检测目标。
从多传感器取得的深度信号,如 LiDAR 和立体匹配,可以取得极佳的表现,但是成本很高。为了降低传感器成本,人们提出了仅基于图像的单目 3D 检测算法,凭借 2D 和 3D 间的几何约束取得了不错的进展。

2. 提出了什么方法?
本文提出了一个端到端的单目 3D 检测算法,MonoDTR 是一个通晓深度信息的 transformer 网络,避免了大计算量和由深度估计带来的不准确的深度先验。主要由两部分构成:
- 深度特征增强(depth-aware feature enhancement, DFE)模块,通过辅助的监督信号隐式地学习深度特征,不会增加计算成本。
- 通晓深度信息的 Transformer 模块(depth-aware transformer, DTR),全局地整合上下文特征和深度特征。和传统的像素位置编码不同,MonoDTR 引入了一个全新的深度位置编码(depth positional encoding, DPE)往 transformers 中注入深度位置信息。
Transformer 的 decoder-encoder 架构能有效地获取长依赖关系,因此本文用它来建模上下文特征和深度特征之间的关系。为了更好地表示 3D 目标的特性,作者用深度特征代替 object queries 作为 decoder 的输入,能为 3D 推理提供更丰富的信息。

2.1 架构
如上图所示,MonoDTR 包括四个部分:主干网络、DFE 模块、DTR 模块、2D-3D 检测 head。
首先将 H i n p × W i n p H_{inp}\times W_{inp} Hinp×Winp分辨率的输入图像送入主干网络(DLA-102),得到特征图 F ∈ R C × H × W , H = H i n p 8 , W = W i n p 8 , C = 256 \mathbf{F}\in \mathbb{R}^{C\times H\times W}, H=\frac{H_{inp}}{8}, W=\frac{W_{inp}}{8},C=256 F∈RC×H×W,H=8Hinp,W=8Winp,C=256。DFE 模块通过辅助深度监督隐式地学习深度特征,并通过多个并行的卷积层提取上下文特征。然后,DTR 模块整合这两类特征,先用 DPE 模块往 transformer 中注入深度位置信息。最后,anchor-based 检测 head 预测 3D 边框。注意:只在训练阶段使用辅助的深度监督。
2.2 Depth-aware Feature Enhancement Module
目前的深度辅助算法使用现成的深度估计网络,但会带来不准确的深度先验,增加计算负担。为了缓解这个问题,本文提出了 DFE 模块做深度推理,如下图所示。在训练阶段,将精确的深度图作为辅助监督使用,使 DFE 模块隐式地学习深度特征。流程如下:
a. 生成初始的深度
X
\mathbf{X}
X,然后预测深度分布
D
\mathbf{D}
D。
b. 估计深度最初形态(depth prototype)
F
d
\mathbf{F}_d
Fd的特征表示。
c. 生成
F
d
\mathbf{F}_d
Fd的增强特征
F
′
\mathbf{F}'
F′,与初始深度特征
X
\mathbf{X}
X融合。

MonoDTR 通过轻量级模块生成深度特征,辅助 3D 检测,极大降低了计算成本。
Learning initial depth-aware feature
为了生成深度特征,作者利用了一个辅助的深度估计任务,将深度估计看作为序列分类问题。如上图(a),给定由主干网络输出的特征图 F ∈ R C × H × W \mathbf{F}\in \mathbb{R}^{C\times H\times W} F∈RC×H×W,通过两个卷积层来预测离散深度类别(bins) D ∈ R D × H × W \mathbf{D}\in \mathbb{R}^{D\times H\times W} D∈RD×H×W的概率, D D D是深度类别(bins)的个数。这个概率代表了像素点属于某一深度类别的置信度。为了将 ground-truth 深度值从连续空间离散化为离散的间隔,作者使用了 linear-increasing discretization(LID) 来得到深度 bins。至此,中间特征图 X ∈ R C × H × W \mathbf{X}\in \mathbb{R}^{C\times H\times W} X∈RC×H×W可以看作为初始的深度特征。
Depth prototype representation learning
为进一步增强深度表征,通过引入相应深度类别的中心表征,增广每个像素点的特征。聚合同一深度类别的每个像素的深度特征,得到每个深度类别的特征中心(depth prototype)。在实现时,首先对预测的深度图 D \mathbf{D} D使用分组卷积,融合相邻的深度类别,将类别数从 D D D减少为 D ′ = D / r D'=D/r D′=D/r,缩放系数为 r r r。它有助于共享相似的深度信息,降低计算量。然后聚合所有像素点 X ′ \mathbf{X}' X′的特征,并用它们属于深度类别 d d d的概率做加权,得到 F d \mathbf{F}_d Fd表征:
F d = ∑ i ∈ I P ~ d i X i ′ , d = { 1 , . . . , D ′ } \mathbf{F}_d=\sum_{i\in\mathcal{I}}\tilde{P}_{di} \mathbf{X}'_i, d=\left\{1,...,D'\right\} Fd=i∈I∑P~diXi′,d={1,...,D′}
其中 X i ′ \mathbf{X}'_i Xi′表示 X ′ \mathbf{X}' X′上第 i i i个像素的特征, I ∈ R H × W \mathcal{I}\in \mathbb{R}^{H\times W} I∈RH×W是特征图的像素集合, P ~ d i \tilde{P}_{di} P~di是第 d d d个 depth prototype 的归一化概率。这样, F d \mathbf{F}_d Fd能够表示每个深度概率的全局上下文信息,如上图(b) 所示。
Feature enhancement with depth prototype
基于 depth prototype 表征,我们就可重新构建新的深度特征了,让每个像素点都可以从全局角度理解出现的深度类别。新特征 F ′ \mathbf{F}' F′计算如下:
F ′ = ∑ d = 1 D ′ P ~ d i F d \mathbf{F}'=\sum_{d=1}^{D'}\tilde{P}_{di}\mathbf{F}_d F′=d=1∑D′P~diFd
随后,如上图© 所示,将初始深度特征 X \mathbf{X} X和新特征 F ′ \mathbf{F}' F′concat 在一起,并输入进一个 1 × 1 1\times 1 1×1卷积层。
2.3 Depth-aware Transformer
Tramsformer 适合建模长域关系,作者研究了 transformer 的架构,提出了 depth-aware transformer(DTR) 模块,从全局角度整合上下文特征和深度特征。
Transformer Encoder
目的是提升上下文特征。Transformer 的主要组成就是自注意力机制。给定输入:query
Q
∈
R
N
×
C
\mathbf{Q}\in \mathbb{R}^{N\times C}
Q∈RN×C、key
K
∈
R
N
×
C
\mathbf{K}\in \mathbb{R}^{N\times C}
K∈RN×C、value
V
∈
R
N
×
C
\mathbf{V}\in\mathbb{R}^{N\times C}
V∈RN×C,序列长度是
N
N
N,单 head 自注意力层可以表示为:
Attention
(
Q
,
K
,
V
)
=
softmax
(
Q
K
T
C
)
V
\text{Attention}(\mathbf{Q,K,V})=\text{softmax}(\frac{\mathbf{QK}^T}{\sqrt{C}})\mathbf{V}
Attention(Q,K,V)=softmax(CQKT)V
对上下文特征 X c ∈ R N × C , N = H × W \mathbf{X}_c\in \mathbb{R}^{N\times C}, N=H\times W Xc∈RN×C,N=H×W做 flatten 操作,输入 transformer encoder。通过 multi-head 自注意力和 FFN 可产生编码后的上下文特征。
Transformer Encoder
Decoder 也是构建于 transformer 架构之上。Decoder 的输入是深度特征,而非 learnable embedding (object query)。在单目 3D 检测任务中,由于透视投影,近距离或远距离的相机视角可能造成物体大小的剧烈变化。这使得简单的 learnable embedding 很难表示物体的特性,很难应付复杂尺度变化的场景。然而,深度特征包含了大量的距离信息。因而,作者提出采用深度特征作为 decoder 的输入。至此,decoder 能够发挥 cross-attention 模块的作用,高效地建模上下文特征和深度特征,提升算法表现。
Depth positional encoding
位置编码在 transformer 中加入了位置信息,扮演着重要角色。根据图像上像素点的位置,它通常用正弦函数或学习的方式来生成。作者发现,深度信息要比像素间的关系更有助于机器去了解 3D 世界。于是,先提出了 DPE 模块,将每个像素点的深度位置信息嵌入在 transformer 中。如下图所示,为每个深度区间,通过 learnable embedding 构建深度类别编码 E d = [ e 1 , . . . , e D ] ∈ R D × C \mathbf{E}_d=[e_1,...,e_D]\in \mathbb{R}^{D\times C} Ed=[e1,...,eD]∈RD×C。根据每个像素点预测的深度类别 D \mathbf{D} D的 argmax 值,可以从 E d \mathbf{E}_d Ed中查询到初始的深度位置编码 P ∈ R H × W × C \mathbf{P}\in\mathbb{R}^{H\times W\times C} P∈RH×W×C。为了进一步从邻近的像素点表示位置信息,对 P \mathbf{P} P使用了一个核大小为 3 × 3 3\times 3 3×3的卷积层 G \mathcal{G} G,得到最终的编码,记做 DPE。
Computation reduction
标准的自注意力层的复杂度是 O ( N 2 ) \mathcal{O}(N^2) O(N2)。为了缓和这个问题,人们提出了诸多方法来加速注意力的计算。原版 transformer 的相似度函数写作: sim ( q , k ) = exp ( q T k C ) \text{sim}(q,k)=\exp(\frac{q^Tk}{\sqrt{C}}) sim(q,k)=exp(CqTk)。在 Linear Transformer 中,它被替换为 sim ( q , k ) = ϕ ( q ) ϕ ( k ) \text{sim}(q,k)=\phi(q)\phi(k) sim(q,k)=ϕ(q)ϕ(k),其中 ϕ ( x ) = elu ( x ) + 1 \phi(x)=\text{elu}(x)+1 ϕ(x)=elu(x)+1, elu ( x ) = { e x − 1 , if x < 0 x , if x ≥ 0 \text{elu}(x)=\left\{ \begin{aligned} e^x-1,& & \text{if} & x<0 \\ x,& & \text{if} & x\geq0 \end{aligned} \right. elu(x)={ex−1,x,ififx<0x≥0。至此,结合 ϕ ( K ) T \phi(K)^T ϕ(K)T和 V V V可以将计算量降为 O ( N ) \mathcal{O}(N) O(N)。本文用 linear attention 替代了原版的自注意力,提高了推理速度。
细节请参考论文:Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention。Linear attention 将注意力得分计算式子的 softmax 中的 exp ( q T k ) \exp(q^Tk) exp(qTk)看作为一个 kernel 函数 k ( ⋅ ) k(\cdot) k(⋅),找到一个特征图 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅)使得 k ( x , y ) = ϕ ( x ) T ϕ ( y ) k(x,y)=\phi(x)^T \phi(y) k(x,y)=ϕ(x)Tϕ(y),如果找不到,就近似实现。
原来的注意力层输出的计算式子为: V i ′ = ∑ j exp ( Q i T K j ) V j ∑ j ′ exp ( Q i T K j ′ ) V'_i=\frac{\sum_j \exp(Q_i^T K_j) V_j}{\sum_{j'}\exp(Q_i^T K_{j'})} Vi′=∑j′exp(QiTKj′)∑jexp(QiTKj)Vj,假定 Q ∈ R n × k , K ∈ R k × n , V ∈ R n × k Q\in\mathbb{R}^{n\times k},K\in\mathbb{R}^{k\times n},V\in\mathbb{R}^{n\times k} Q∈Rn×k,K∈Rk×n,V∈Rn×k。
将注意力得分计算看成 kernel 函数,
V
i
′
=
∑
j
sim
(
Q
i
T
,
K
j
)
V
j
∑
j
′
sim
(
Q
i
T
,
K
j
′
)
V'_i=\frac{\sum_j \text{sim}(Q_i^T,K_j) V_j}{\sum_{j'}\text{sim}(Q_i^T,K_{j'})}
Vi′=∑j′sim(QiT,Kj′)∑jsim(QiT,Kj)Vj。
写成特征图,
V
i
′
=
∑
j
ϕ
(
Q
i
T
)
T
ϕ
(
K
j
)
V
j
∑
j
′
ϕ
(
Q
i
)
T
ϕ
(
K
j
′
)
→
V
i
′
=
ϕ
(
Q
i
)
T
∑
j
ϕ
(
K
j
)
V
j
T
ϕ
(
Q
i
)
T
∑
j
′
ϕ
(
K
j
′
)
V'_i=\frac{\sum_j \phi(Q_i^T)^T \phi(K_j) V_j}{\sum_{j'}\phi(Q_i)^T \phi(K_{j'})} \rightarrow V'_i=\frac{\phi(Q_i)^T \sum_j \phi(K_j) V_j^T}{\phi(Q_i)^T\sum_{j'} \phi(K_{j'})}
Vi′=∑j′ϕ(Qi)Tϕ(Kj′)∑jϕ(QiT)Tϕ(Kj)Vj→Vi′=ϕ(Qi)T∑j′ϕ(Kj′)ϕ(Qi)T∑jϕ(Kj)VjT。则分子的计算复杂度为
O
(
k
2
×
n
)
\mathcal{O}(k^2\times n)
O(k2×n)。
2.4 2D-3D Detection and Loss
Anchor definition
使用带预定义的 2D-3D anchors 的单阶段检测器来回归边框。每个预先定义的 anchor 包括 2D 框参数 [ x 2 d , y 2 d , w 2 d , h 2 d ] [x_{2d},y_{2d},w_{2d},h_{2d}] [x2d,y2d,w2d,h2d]和 3D 框参数 [ x p , y p , z , w 3 d , h 3 d , l 3 d , θ ] [x_p,y_p,z, w_{3d}, h_{3d}, l_{3d},\theta] [xp,yp,z,w3d,h3d,l3d,θ]。 [ x 2 d , y 2 d ] [x_{2d},y_{2d}] [x2d,y2d]和 [ x p , y p ] [x_p,y_p] [xp,yp]分别是 2D 框的中心,和 3D 框中心点投影到图像平面的点。 [ w 2 d , h 2 d ] [w_{2d},h_{2d}] [w2d,h2d]和 [ w 3 d , h 3 d , l 3 d ] [w_{3d},h_{3d},l_{3d}] [w3d,h3d,l3d]分别是 2D 框和 3D 框的尺度。 z z z是 3D 目标中心的深度, θ \theta θ是目标的观测角度。训练时,将所有的 ground-truth 投影到 2D 空间,计算它们和所有 2D anchors 的 IoU。将 IoU ≥ 0.5 \geq 0.5 ≥0.5的 anchor 分配给相应的 3D 框做优化。
Output transformation
遵循 YOLOv3 的方式,对于每个 anchor,预测
[
t
x
,
t
y
,
t
w
,
t
h
]
2
d
[t_x,t_y,t_w,t_h]_{2d}
[tx,ty,tw,th]2d和
[
t
x
,
t
y
,
t
w
,
t
h
,
t
l
,
t
z
,
t
θ
]
3
d
[t_x,t_y,t_w,t_h,t_l,t_z,t_\theta]_{3d}
[tx,ty,tw,th,tl,tz,tθ]3d,目的是将 2D 框和 3D 框的残差值参数化,并预测分类得分
c
l
s
cls
cls。输出边框可以根据 anchor 和网络的预测值恢复出来:
[
x
^
2
d
,
y
^
2
d
]
=
[
t
x
,
t
y
]
2
d
∗
[
w
2
d
,
h
2
d
]
+
[
x
2
d
,
y
2
d
]
[\hat{x}_{2d},\hat{y}_{2d}]=[t_x,t_y]_{2d} \ast [w_{2d},h_{2d}]+[x_{2d}, y_{2d}]
[x^2d,y^2d]=[tx,ty]2d∗[w2d,h2d]+[x2d,y2d]
[
x
^
p
,
y
^
p
]
=
[
t
x
,
t
y
]
3
d
∗
[
w
2
d
,
h
2
d
]
+
[
x
p
,
y
p
]
[\hat{x}_{p},\hat{y}_{p}]=[t_x,t_y]_{3d} \ast [w_{2d},h_{2d}]+[x_{p}, y_{p}]
[x^p,y^p]=[tx,ty]3d∗[w2d,h2d]+[xp,yp]
[
w
^
3
d
,
h
^
3
d
,
l
^
3
d
]
=
exp
(
[
t
w
,
t
h
,
t
l
]
3
d
)
∗
[
w
3
d
,
h
3
d
,
l
3
d
]
[\hat{w}_{3d},\hat{h}_{3d},\hat{l}_{3d}]=\exp([t_w,t_h,t_l]_{3d}) \ast [w_{3d},h_{3d},l_{3d}]
[w^3d,h^3d,l^3d]=exp([tw,th,tl]3d)∗[w3d,h3d,l3d]
[
w
^
2
d
,
h
^
2
d
]
=
exp
(
[
t
w
,
t
h
]
2
d
)
∗
[
w
2
d
,
h
2
d
]
[\hat{w}_{2d},\hat{h}_{2d}]=\exp([t_w,t_h]_{2d}) \ast [w_{2d}, h_{2d}]
[w^2d,h^2d]=exp([tw,th]2d)∗[w2d,h2d]
[
z
^
,
θ
^
]
=
[
t
z
,
t
θ
]
3
d
+
[
z
,
θ
]
[\hat{z},\hat{\theta}]=[t_z,t_\theta]_{3d}+[z,\theta]
[z^,θ^]=[tz,tθ]3d+[z,θ]
( ⋅ ) ^ \hat{(\cdot)} (⋅)^表示恢复的 3D 框参数。注意,这里给 2D 框中心 [ x 2 d , y 2 d ] [x_{2d},y_{2d}] [x2d,y2d]和 3D 投影中心 [ x p , y p ] [x_p,y_p] [xp,yp]使用相同的 anchor 中心点。
Loss function
总体损失
L
\mathcal{L}
L包括用于前背景分类和类别分类的分类损失
L
c
l
s
\mathcal{L}_{cls}
Lcls、边框回归损失
L
r
e
g
\mathcal{L}_{reg}
Lreg,以及带辅助深度监督的深度损失
L
d
e
p
\mathcal{L}_{dep}
Ldep:
L
=
L
c
l
s
+
L
r
e
g
+
L
d
e
p
\mathcal{L}=\mathcal{L}_{cls}+\mathcal{L}_{reg}+\mathcal{L}_{dep}
L=Lcls+Lreg+Ldep
在分类任务中使用 focal loss 平衡样本,在回归任务中使用 Smooth-L1 损失。对于深度类别预测,使用了 focal loss:
L
d
e
p
=
1
∣
P
∣
∑
p
∈
P
FL
(
D
(
p
)
,
D
^
(
p
)
)
\mathcal{L}_{dep}=\frac{1}{|\mathcal{P}|}\sum_{p\in\mathcal{P}}\text{FL}(\mathbf{D}(p), \hat{\mathbf{D}}(p))
Ldep=∣P∣1∑p∈PFL(D(p),D^(p))
P
\mathcal{P}
P是带有效深度标签的图像像素区域,
D
^
\mathbf{\hat{D}}
D^是由 LiDAR 生成的 ground-truth 深度 bins。