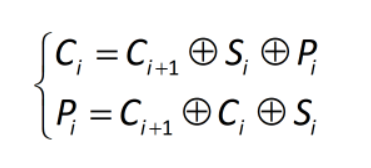BERT(Bidirectional Encoder Representations from Transformers,基于Transformers的双向编码器表示)系列算法在自然语言处理任务中是必不可少的经典模型,当初第一代GPT模型发布的时候,坐了冷板凳,罪魁祸首就是BERT。
有任何问题欢迎在下面留言
本篇文章配套的PPT资源已经上传
目录
1、如何训练BERT
1.1相关背景
1.2 方法1随机遮挡
1.3 方法2连接预测
2 ALBERT
2.1 什么是ALBERT
2.2 第一点大矩阵拆分
2.3 第二点跨层参数共享
2.4 实验中还告诉我们的故事
3 RoBERTa
3.1 如何训练RoBERTa
3.2RoBERTa-wwm
4 DistilBERT
1、如何训练BERT
在图像任务中,针对不同的任务需要设计不同的策略以及不同的网络设计,但是NLP任务真没有五花八门的操作,太多NLP的基础基本都是不需要的。基于2023的今天,大多数的NLP我觉得都比较啰嗦,后续也不可能用到,硕博学位论文那肯定还是会用到的。
1.1相关背景
语言模型,BERT只是其中的一种,后续本人会在CSDN上分析多个语言模型。
17年,Transformer提出来,给了NLP一个新的方法新的架构
18年,谷歌带头做出BERT,他说他有数据,他有算力,用Transformer训练一个大的语言模型出来即BERT模型
19年-20年,出现了很多对于BERT的改进(改进不是说把模型结构改变,把模型做的更大,是想办法把训练效率做的更高一些)
这么说吧,整个NLP领域都是基于Transformer去做的,只不过做的更大而已,这么多年过去了,还是用的17年这个结构,只不过做的更大。
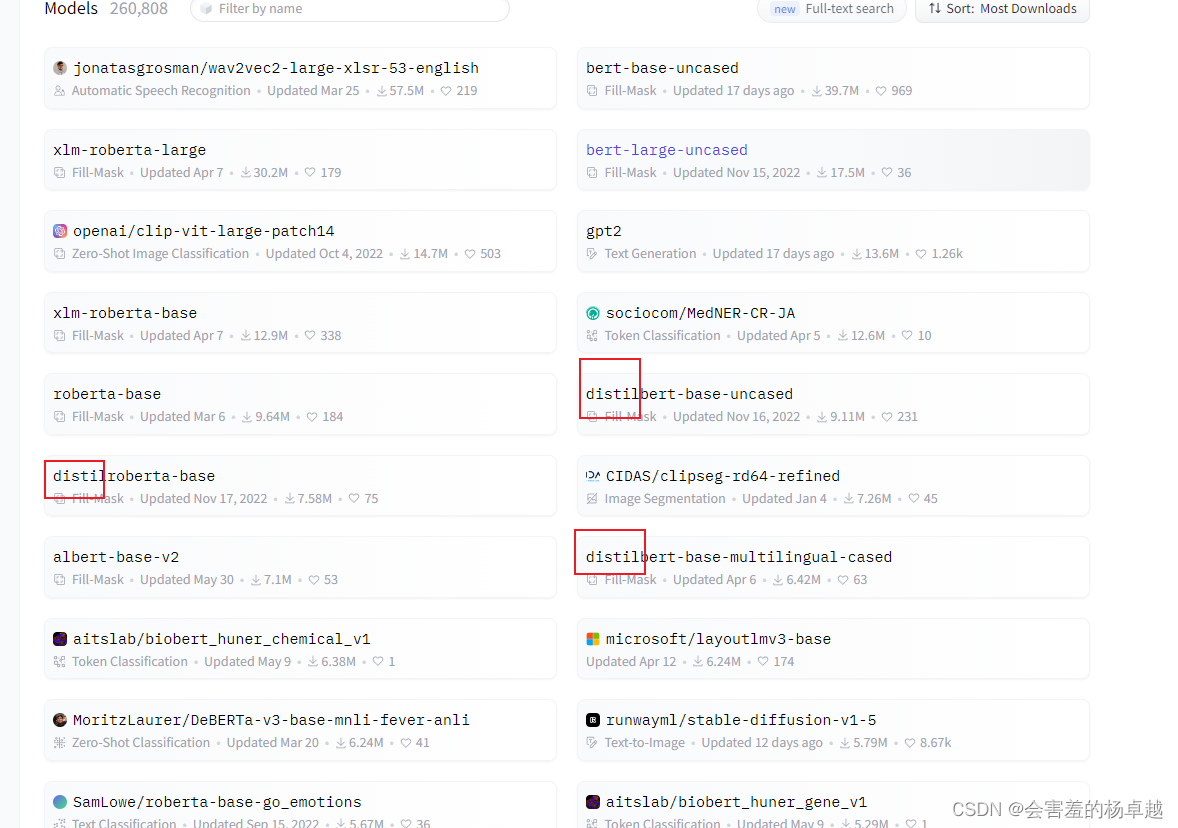
打开Hugging Face的模型页面,按销量排:
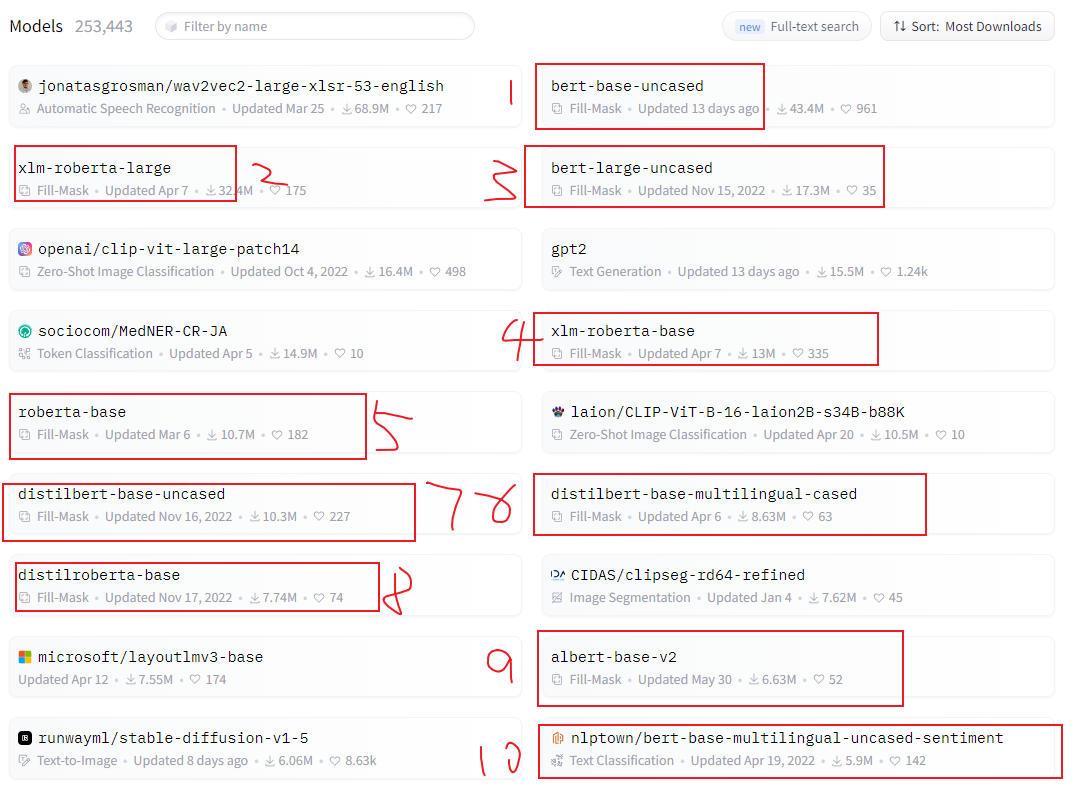
(截止2023年7月13日)排前18的模型有10个都是BERT相关的,其中标红的第一个bert-base-uncased是原装的bert。
关于这方面已经不推荐大家去看“很多论文”了,因为论文很多告诉你的都是一个训练过程。
1.2 方法1随机遮挡
- 方法1:句子中有15%的词汇被随机mask掉
- 交给模型去预测被mask的家伙到底是什么
- 词语的可能性太多了,中文一般是字
- 如果BERT训练的向量好,那分类自然OK
比如我现在有很多文本数据,但是其实并没有一个实际要做的目的。语言模型并不是一个固定的任务,不是做什么分类和回归,也不是做什么NER。就是让模型理解人类的文字,理解人说话的逻辑,这才叫语言模型,并不是一个具体的任务。
现在需要的是培养模型的语言能力,所以需要标签吗?不需要标签,在互联网中有海量的数据,随便去取一个句子,这句话有四个词,我随机mask掉一个词,这是随机选择的,然后让模型去猜这个被mask的词是哪个。

想一想英语考试,考试考的是什么?是你英文的一个学习能力,怎么考察呢?有一些完形填空的任务,有一些选择题,有一些阅读理解题,让你理解这些题在什么前提下?在你英语水平比较高的前提下,你就能做的比较好了
1.3 方法2连接预测
- 方法2:预测两个句子是否应该连在一起
- [seq]:两个句子之前的连接符
- [cls]:表示要做分类的向量
第二种方法没有mask,将两句完整句子用[SEP]连接起来,判断两个句子有没有相关性,做一个二分类

如果模型能够理解语言的含义,自然而然能够预测准,看第二张图:
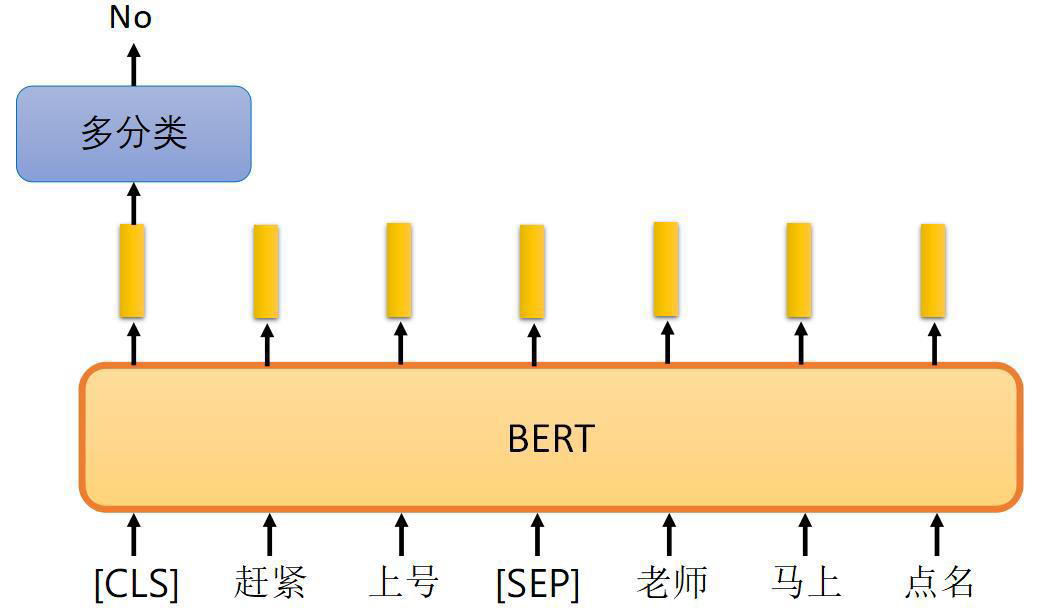
这两句话就没有连接性,老师上召唤师峡谷给你点名吗?
两种方法都是为了让模型理解我们文字的含义,想想你在英语考试中什么前提能让你在考试中做的好,就是语言能力。
有了语言模型,有一个能理解语言含义的模型之后,就能做一下下游任务,比如:
- 情感分类
- NER(Named Entity Recognition,命名实体识别)
- 关系抽取
- 语法检查纠错
仅仅列出一小部分,这些都是一个下游任务,怎么把这些下游任务做好,归根到底就是模型的语言能力非常强,能够很好的理解上下文的含义,拼的就是一个把语言模型做好的前提。
你让一个清华的状元和一个街溜子去做同一件事,清华状元的学习能力强可能就能做得好。
2 ALBERT
2.1 什么是ALBERT
A Lite BERT,轻量级的BERT
- 从BERT开始NLP就一直强调一件事,要想效果好,模型就一定得大
- 但是如果模型很大,权重参数就会非常多,训练是一个大问题(显存都装不下)
- 训练速度也是一个事,现在大厂模型都要以月为单位,速度巨慢
- 能不能简化下BERT,让他训练的更快更容易一些呢?(Transformer中Embedding占20%参数,Attetntion占80%)
之前训练CV任务的时候,都是以小时为单位的,可能训练三五个小时就出效果了,但是在自然语言处理任务中,三五个小时那可能还没训练完百分之一呢。
给大家举个例子,看这个模型BLOOM,176B(1760亿)个参数,开发人员和研究人员超过1000个,BLOOM能够以46种自然语言和13种编程语言生成文本。
他们每天都在推特发布训练进度:

每天只能训练1%,现在已经训练完成,那他是不是单CPU去训练的啊?要不然怎么会这么慢呢。到底是不是单卡,看看这台超级计算机的配置:
这是来自70多个国家和250多个机构的1000多名研究人员一年工作的成果,最终在法国巴黎南部的Jean Zay超级计算机上训练了117天(3月11日至7月6日)的BLOOM模型,这要归功于法国国家科学研究中心(CNRS)和法国科学研究中心(CNRS)估计价值300万欧元的计算拨款。
训练硬件:
GPU: 384 张 NVIDIA A100 80GB GPU (48 个节点) + 32 张备用 GPU
每个节点 8 张 GPU,4 条 NVLink 卡间互联,4 条 OmniPath 链路
CPU: AMD EPYC 7543 32 核处理器
CPU 内存: 每个节点 512GB
GPU 显存: 每个节点 640GB
Checkpoints:
每个 checkpoint 含精度为 fp32 的优化器状态和精度为 bf16+fp32 的权重,占用存储空间为 2.3TB。如只保存 bf16 的权重,则仅占用 329GB 的存储空间。
数据集:
1.5TB 经过大量去重和清洗的文本,包含 46 种语言,最终转换为 350B 个词元
模型的词汇表含 250,680 个词元
176B BLOOM 模型的训练于 2022 年 3 月至 7 月期间,耗时约 3.5 个月完成 (约 100 万计算时)。
NLP的模型量级怎么增长的,是指数级增长啊,真的恐怖如斯
ALBERT从轻量级作为一个切入点,ALBERT的研究人员发现Transformer中Embedding占20%参数,Attetntion占80%
先熟悉几个变量:
- E:词嵌入大小
- H:隐藏层大小
- V:语料库中词的个数
E就是第一层Embedding后得到向量的维度。比如“今天”这个词,经过词嵌入后映射成了一个768维的向量,这个E就等于768了。
H就是词经过词嵌入后,再经过self-Attention,还要经过一些全连接层,之后得到的向量维度,一般都会等于E。
V是语料库中词的个数,比如字典中一共有两万个词,在前面的mask任务中,求解mask就要从这个两万个词中选择,这个任务就是一个两万分类的任务了。
正常情况下,在embbeding层的参数量,需要把所有词都映射成向量,一共多少词呢?这里一定要理解,就是两万个词。每个词都映射成768维的向量,这中间需要构建的权重矩阵就是768*20000。这个矩阵很大,两万这个数字还只是一个保守的说法,在实际中可能要再翻个十倍。
那有没有办法给这个参数量降低一下呢?
2.2 第一点大矩阵拆分
- 通过一个中介,将一层转换为两层,但是参数量可以大幅降低
- 参数量:(V×H)降低到( V ×E + E ×H )
- 此时如果H>>E,就达到了咱们的目的(E越小可能会效果越差)
- 但是Embedding层只是第一步,Attention如何简化才是重头戏
我将768和10000二者之间引入一个中介,将这个768*20000的大矩阵拆分成两个小矩阵。所以ALBERT的做法就是,embbeding层做成两层。由768*20000变成768*100+100*20000,这个100是自己设计的,这样参数量就大大降低了。
不同E值会产生影响,E小一些影响结果,但是不大,这是一个E值的影响的表格:
| Model | E | Parameters | SQuAD1.1 | SQuAD2.0 | MNLI | SST-2 | RACE | Avg |
| ALBERT base not-hared | 64 | 87M | 89.9/82.9 | 80.1/77.8 | 82.9 | 91.5 | 66.7 | 81.3 |
| 128 | 89M | 89.9/82.8 | 80.377.3 | 83.7 | 91.5 | 67.9 | 81.7 | |
| 256 | 93M | 90.2/83.2 | 80.3/77.4 | 84.1 | 91.9 | 67.3 | 81.8 | |
| 768 | 108M | 90.4/83.2 | 80.4/77.6 | 84.5 | 92.8 | 68.2 | 82.3 | |
| ALBERT base all-hared | 64 | 10M | 88.7/81.4 | 77.5/74.8 | 80.8 | 89.4 | 63.5 | 79.0 |
| 128 | 12M | 89.3/82.3 | 80.0/77.1 | 81.6 | 90.3 | 64.0 | 80.1 | |
| 256 | 16M | 88.8/81.5 | 79.1/76.3 | 81.5 | 90.3 | 63.4 | 79.6 | |
| 768 | 31M | 88.6/81.5 | 79.2/76.6 | 82.0 | 90.6 | 63.3 | 79.8 |
首先可以看E越大特征越多,后面6列都是不同对比实验也有不同评分标准。从表格中可以看出,虽然这个策略有一定效果,但是并没有一个本质上的改进。这个结果有一定了解就行了,因为你几乎不可能去复现这个结果的。(别人的数据是无限的,计算资源也很强,论文你看看得了,这种实验就是一个可远观不可亵玩焉)
2.3 第二点跨层参数共享
共享的方法有很多,ALBERT选择了全部共享,FFN和ATTENTION的都共享。
之前我们的文章有讲过卷积神经网络,卷积层和全连接对比一下。全连接非常费参数,因为全连接没有任何共享的地方。卷积呢?为什么能省参数,同一个卷积核,在图像中的各个位置的权重完全一样,所以它参数少,好训练,因为CNN的效果比FC强。

在Transformer的堆叠中,一层self-Attention接着一层FC,上一层self-Attention和下一层self-Attention的权重参数能共享吗?当时19年读这篇论文的时候,我就在想,啊?这还能共享啊?self-Attention一层一层的堆叠,参数还共享,那还是Transformer吗,这个Transformer不是没有意义了么?但是经过实验证明,还真能共享。
来看一下结果:

先看这个E=768的,就是先不考虑E,all-shared全部共享参数有31M,结果是79.8,not-shared不共享,参数有108M,结果是82.3。确实把模型变小了很多,但是结果下降了,要是没有下降,那真是见鬼了。但是令人惊叹的是,有下降,但是下降的却很少。
然后看E=128,也就是说E也减少了,然后参数又进一步大大减小了,但是结果仍然是有下降,但是下降的不多。
在深度学习的很多结果,都是一个没有办法证明的事,只能是通过实验看到这样一个结论。
这就使得ALBERT在实际中被使用的更多,在我们的实际项目中,我们很少使用BERT这样一个模型,因为太庞大了。在训练与部署的过程中,需要考虑成本的,什么成本,时间成本。
你想想,用户给你一个反馈,点了鼠标,半天没有反应,人家气的肯定直接关了网页。
2.4 实验中还告诉我们的故事
层数是不是越多越好?

目前来看确实就是的。
隐层的特征是不是越多越好呢?

目前来看确实也是的,但是也不能一直大下去啊,一般来说隐层特征768就可以了。大到6144就开始下降了,实际上是因为数据跟不上了,虽然是NLP的数据是无限的,但是毕竟还是有限的。太大了也确实没意义。
看一下此时此刻,ALBERT在Hugging Face能排到第几名:

第16名,六百多万的下载量,也很不错了。
3 RoBERTa
RoBERTa,Robustly optimized BERT approach
我们的任务不应该仅仅是ALBERT,还有很多其他BERT的变形体。RoBERTa和ALBERT实际上是两条路,ALBERT实际上是对网络结构进行改变,RoBERTa是对训练过程进行优化。

这个排名也很高,第九名,接近一千万的下载量。
3.1 如何训练RoBERTa
- 基本就是说训练过程可以再优化优化
- 最核心的就是如何在语言模型中设计mask:
- 动态mask光听感觉肯定都比静态的要强,也就是这篇论文的核心
- 取消NSP任务(Next Sentence Prediction)后效果反而好
先想想BERT是怎么做的?
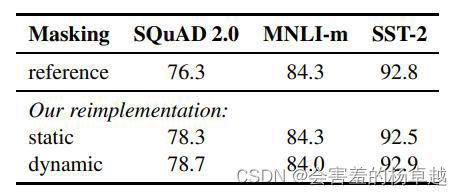
拿到一个数据集,有n条数据,BERT会将第1条一直到第n条数据,全部随机选中一个位置mask掉。但是哪个地方应该被mask掉,这个事情是一个确定的事情,后续无法改变的,这个是原始的BERT的方法。在深度学习中,一定会强调一个叫做epoch的东西,深度学习会将数据不断的进行迭代,迭代epochs次。在原始BERT中,对于n个句子中,在每一个epoch的迭代中,被mask的位置都是固定的。
比如:“珠穆朗玛峰是世界第一高峰”,第一次把“珠穆朗玛峰”给mask掉,让BERT猜谁是世界第一高峰,往后的第二次、第三次都是这么做。
但是我们能不能不做这么做呢?第一次我把“珠穆朗玛峰”给mask掉,第二次我把第一的一给mask掉可以吗?这样模型学到的东西是不是就更多了。
这这种做法,就是叫做动态的mask。
在回答深度学习训练方面的问题的时候,我经常回答把batch_size改成1试试。为什么呢,因为普遍大家的机器都没有几个说很舍得买3090,4090的,毕竟花一两万就买个显卡,确实还是没那么舍得。
所以batch_size肯定是越大越好,因为这样能够更快训练完一个数据集,更好的拟合到数据的概率分布。
所以提出RoBERTa的论文实际上就做了一个动态mask,然后做了一些实验。
看一看RoBERTa优化的那些地方:
- BatchSize基本也是大家公认的:
- 用了更多的数据集,训练了更久,提升了一点效果
- 分词方式做了一点改进,让英文拆的更细致(与中文无关)

看看人家的batch_size吧,我们自己玩不了这个东西。后面再看看gpt大模型,何止是以k为单位,简直是以w和m为单位。
3.2RoBERTa-wwm
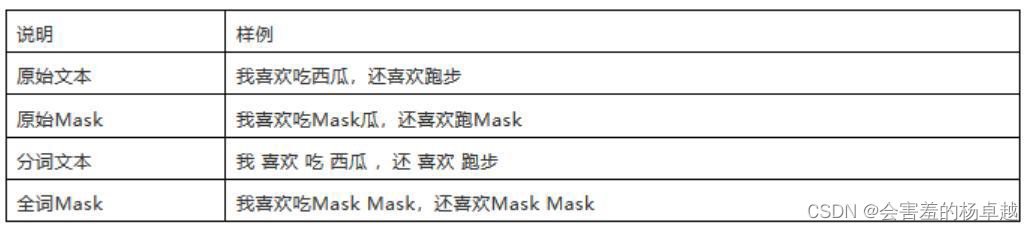
wwm就是 word whole mask,全词掩码,这里用中文版本的介绍一下( 就是哈工大和科大讯飞的中文分词模型)
比如这句话:我喜欢吃哈X滨正宗烤冷面,最早来说就是把中文的一个字给mask掉,但是这个时候模型学的是什么哈什么滨,跟正宗烤冷面是没有关系的,不仅跟烤冷面没关系,跟其他任务都没有关系,因为哈什么滨中国就一个哈尔滨。
所以说以前用字来mask带了一些问题,全词掩码,那就应该把这一整个词全遮挡住让BERT来猜:
我喜欢吃XXX正宗烤冷面
所以这个时候,模型思考的时候,正宗烤冷面在全国哪里最多呢?然后分析得出了哈尔滨。
这就是中文版的RoBERTa-wwm分词方式
4 DistilBERT

就叫它老四吧,老四觉得BERT模型太大了,在训练的时候不去改BERT的网络结构,但是训练完了之后,能不能给它拆了,让它变得更小呢?这件事情就叫做蒸馏。
什么叫做蒸馏?模型实现效果会有一些核心支撑点,但是模型会在核心支撑额外加一些东西,这些额外的东西在训练的时候需要,在部署和测试的时候可能并不需要。所以蒸馏就是在一个大模型的基础上进行拆分,把一些不重要没必要的东西拆除的过程,就是蒸馏。
为什么一定要做这个?NLP的参数是呈指数上升的趋势,是很恐怖的,CV就没有这么恐怖。因为NLP效果提升都不是在改网络结构,是把模型做的更大。因为都是基于Transformer去做的。所以学术上就一点,大力出奇迹。
但是工程上怎么办?还是得面向实际落地啊!所以还是需要想办法做的小一些。
DistilBERT的实验中去掉了40%的参数,但是效果依然能保持在97% :

distil蒸馏,在Hugging Face上很多模型都出现了蒸馏版本:
到今天为止的NLP任务中,主流的模型就是BERT和GPT两个方向。