python 常规的 stft 都是在 cpu 上进行计算,如果网络训练是在 GPU 上进行,那么就涉及到数据传输的问题,降低计算效率;而 torch 自带的 stft 可以直接在 GPU 上进行计算,因此可以节省计算时间。
import torch
import torchaudio
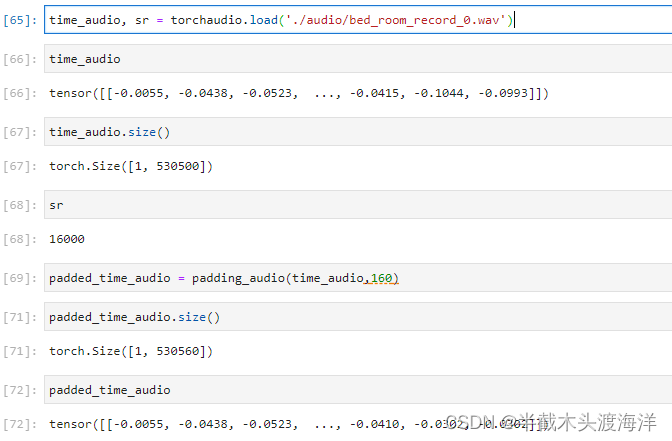
time_audio, sr = torchaudio.load('./audio/bed_room_record_0.wav')
frequency_audio = torch.stft(time_audio, n_fft = 512, hop_length = 160, return_complex=True, onesided=True)
time_recover = torch.istft(frequency_audio, n_fft = 512, hop_length = 160)运行结果如下:
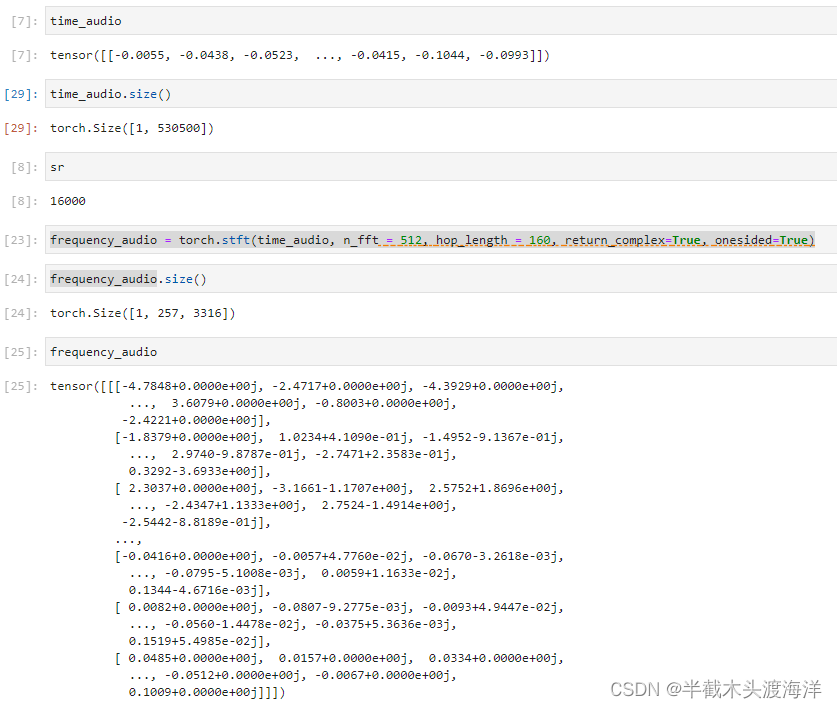
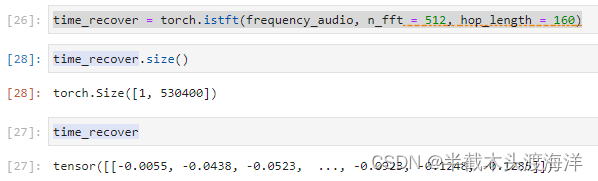
根据结果可以发现输入跟短时傅里叶逆变换的的结果大小并不一致,这是因为stft截断的原因,可以通过在输入信号之前添加padding的操作实现前后大小一致的目标。
import torch
import torchaudio
import numpy as np
def padding_audio(time_audio,hop_len):
length = time_audio.size(-1)
frame_num = int(np.ceil(length/hop_len))
padded_len = frame_num * hop_len
padding_len = padded_len - length
padded_audio = torch.cat([time_audio,time_audio[:,:padding_len]],-1)
return padded_audio
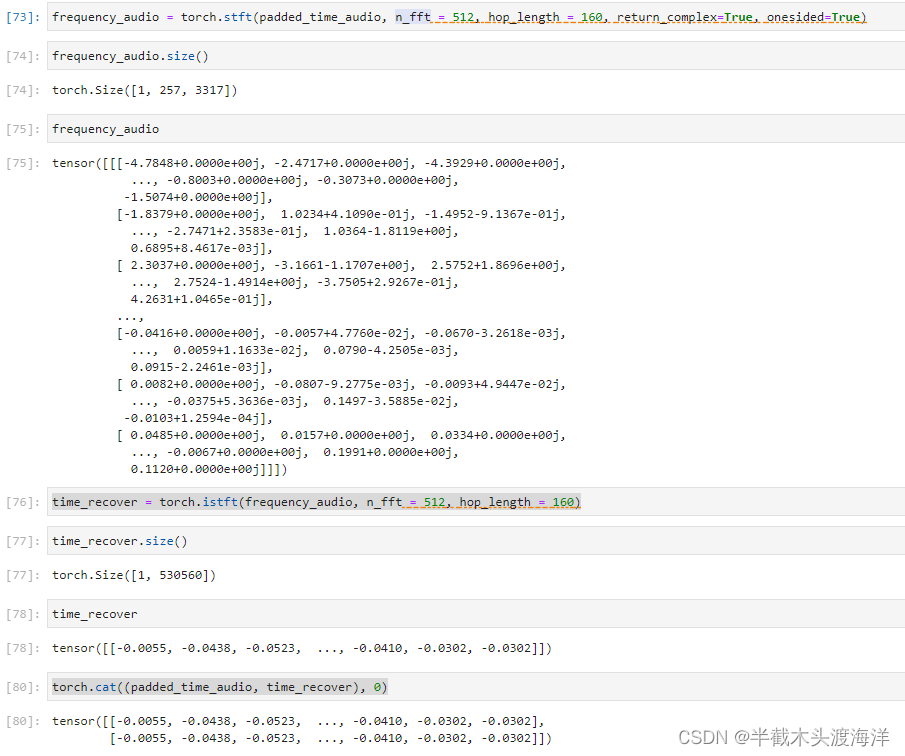
time_audio, sr = torchaudio.load('./audio/bed_room_record_0.wav')
padded_time_audio = padding_audio(time_audio,160)
frequency_audio = torch.stft(padded_time_audio, n_fft = 512, hop_length = 160, return_complex=True, onesided=True)
time_recover = torch.istft(frequency_audio, n_fft = 512, hop_length = 160)
torch.cat((padded_time_audio, time_recover), 0)输出结果如下: