💖作者:小树苗渴望变成参天大树🎈
🎉作者宣言:认真写好每一篇博客💤
🎊作者gitee:gitee✨
💞作者专栏:C语言,数据结构初阶,Linux,C++ 动态规划算法🎄
如 果 你 喜 欢 作 者 的 文 章 ,就 给 作 者 点 点 关 注 吧!

文章目录
- 前言
- 一、什么是list
- 二、具体使用
- 2.1构造函数
- 2.2迭代器的使用
- 2.3容量的函数
- 2.4修改函数
- 2.5其他的操作函数
- 三、总结
前言
今天,博主来给大家介绍STL中的另一个容器——list的具体使用,这个容器平时使用的也非常的多,接口也挺多的,但是有的部分和之前的意思的一样的,有不一样的接口再重点讲解一下,话不多说,我们一起来看正文。
一、什么是list
我们一起来看一下文档:
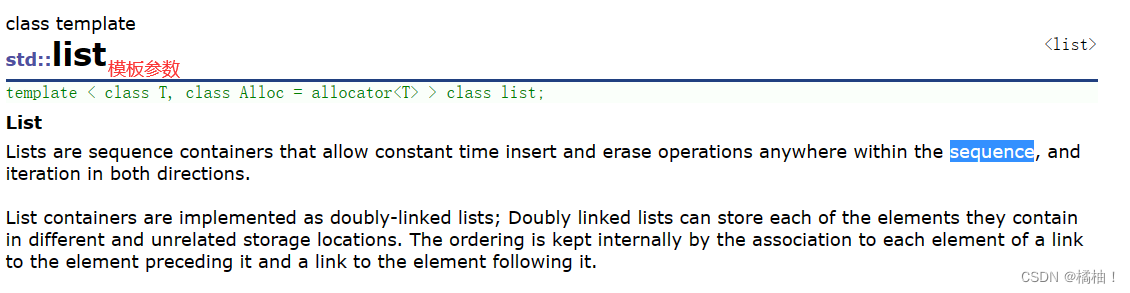
- list是可以在常数范围内在任意位置进行插入和删除的序列式容器,并且该容器可以前后双向迭代。
- list的底层是双向链表结构,双向链表中每个元素存储在互不相关的独立节点中,在节点中通过指针指向其前一个元素和后一个元素。
我们发现底层是双向链表,倒是再模拟实现的时候难度就有所提升。大致了解list是一个什么样的容器了吧,接下来就看他的具体使用:
二、具体使用
2.1构造函数
我们要使用list必须先将list的对象创建出来,所以目前看他的构造函数:

这个几乎和vector的构造函数一模一样,来看示例:
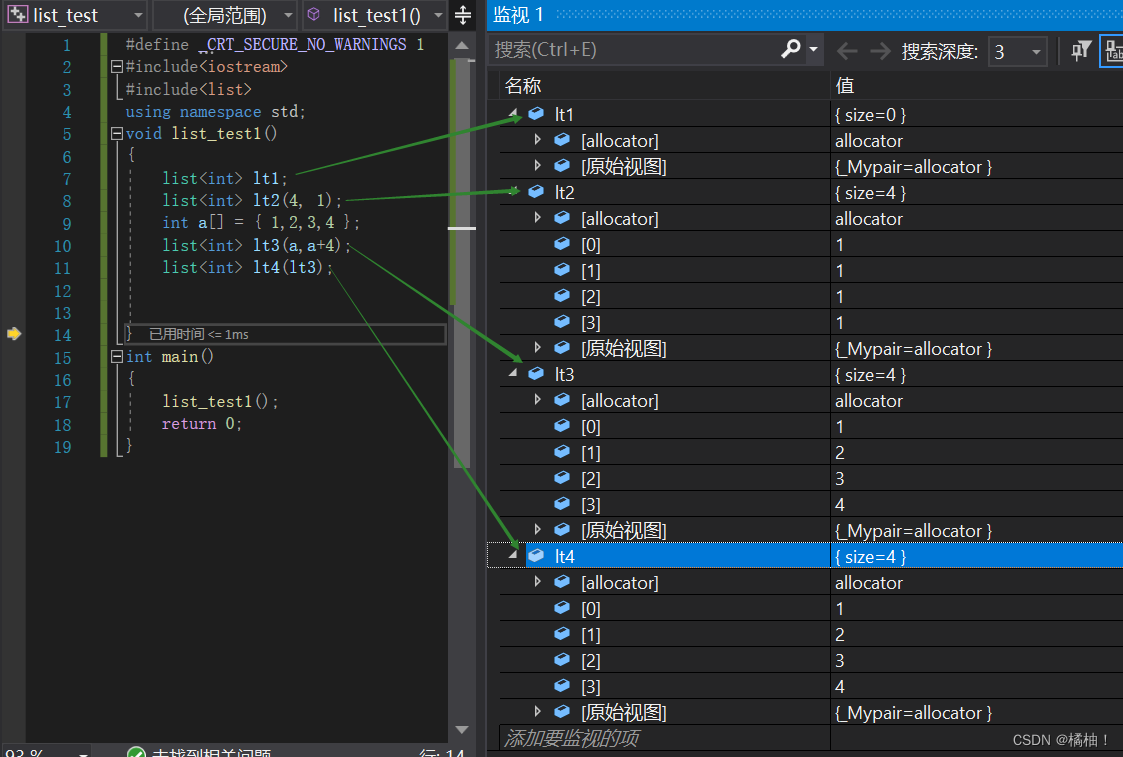
list<int> lt1;//默认构造
list<int> lt2(4, 1);//构造n个大小的空间,并初始化为想要的值
int a[] = { 1,2,3,4 };
list<int> lt3(a,a+4);//通过其他迭代器进行构造
list<int> lt4(lt3);//拷贝构造
2.2迭代器的使用
再list我们的迭代器的好处就体现出来了,它不像string或者vector一样可以通过下标来访问,因为这两个都是连续的空间,而list是链表一样的结构,通过下标肯定是不行了,所以我们只能使用迭代器来访问list里面的元素:
我们的容易提供的迭代器接口都是一样的,就是为了方便一个会了,其他的都会了,降低了学习成本,但是我们再底层的实现都是千差万别的,我们先来看看使用吧:
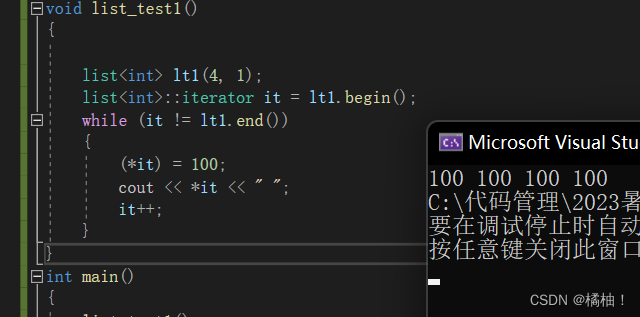
list<int> lt1(4, 1);
list<int>::iterator it = lt1.begin();
while (it != lt1.end())
{
(*it) = 100;
cout << *it << " ";
it++;
}
既然这样,我们来简单说明一下,我们发现我们的使用和之前的是一样的,不管是解引用还是++或者结束条件的判断都是一样的,再vector或者string那一块,我们还可以想懂,因为地址是连续的一块空间,迭代器就是地址,++就是加了此类型的空间大小,跳到下一个元素的,但是再list当中就不一样了,我们的链表地址是不连续的,那么++怎么找到的下一个位置,肯定不是加类型的大小,就找到下一下位置,我们之前学过链表,想要找到下一个位置,就需要通过next指针去找,说明我们的迭代器++肯定做了运算符重载,才达到此目的,解引用等其他操作肯定都重载了,既然有重载,我们不可能把一个单独的节点弄成指针的形式,而是要将节点封装成一个迭代器,再定义一个结构体,完成其他操作的重载,就可以达到我们后面想要的操作,等到模拟实现的时候再好好解释一样
节点也不是单纯的内置类型,节点里面的成员变量是内置类型,节点是自定义类型,我们到时候使用迭代器的时候,就不能像内置类型一样,使用原始指针(int* double*)假设节点叫node,不能使用node这样的迭代器,迭代器的主要作用是访问节点里面的数据,node将节点整体的打包起来起来了取得地址,这是管理节点的方式,是list本身去管理的,不是迭代器的事,迭代器只管访问里面的数据,目前有的抽象,大家先看着理解。
既然迭代器可以使用,那我们的范围for也就可以使用了
list<int> lt1(4, 1);
list<int>::iterator it = lt1.begin();
for (auto& e : lt1)
{
e += 10;
cout << e << " ";
}
cout << endl;
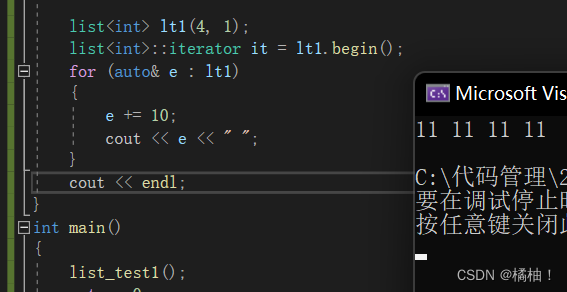
迭代器到时候再sort那块再讲一点细节,模拟实现是重点,我们来看下一个操作
2.3容量的函数

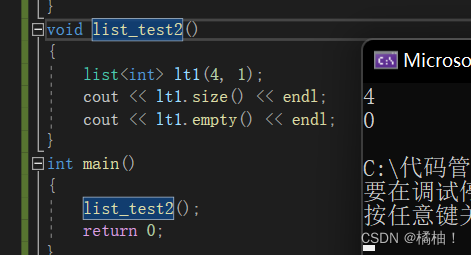
我们发现对于容量的操作据这么两个,相比较前面的vector和string,少了reserve,因为此结构是链表,不存在扩容的情况,而resize是放在修改那一块,不算改变容量,所以只有这上面两个接口:
list<int> lt1(4, 1);
cout << lt1.size() << endl;
cout << lt1.empty() << endl;
2.4修改函数

(1)头插头删和尾插尾删
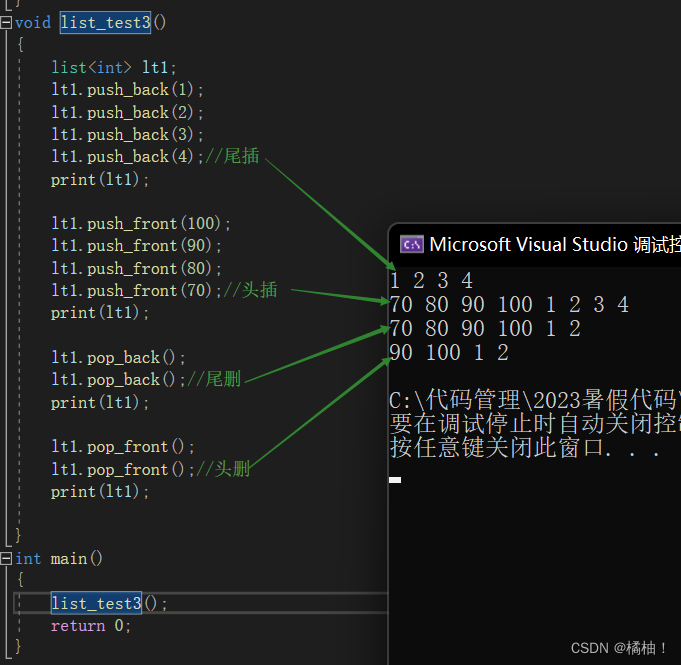
我们看到头插头删,尾插尾删,在vector中,我们只有尾插尾删,因为头插头删对于vector来说消耗太大,需要把所有数据都挪动,而list不存在这样的情况,所以提供了头插头删,来看一下使用:
list<int> lt1;
lt1.push_back(1);
lt1.push_back(2);
lt1.push_back(3);
lt1.push_back(4);//尾插
print(lt1);
lt1.push_front(100);
lt1.push_front(90);
lt1.push_front(80);
lt1.push_front(70);//头插
print(lt1);
lt1.pop_back();
lt1.pop_back();//尾删
print(lt1);
lt1.pop_front();
lt1.pop_front();//头删
print(lt1);
(2)insert和erase

对于insert我们发现也有三个接口,但是要主要的时候,我们不能通过lt1.begin()+3这种方式来传迭代器,空间不连续,也侧面说明迭代器内部内有重载+这个运算符,只能通过循环先找到想要的位置,我们来看具体怎么操作的:
//90 100 1 2
//想在第2个位置插入一个10
auto it = lt1.begin();
//lt1.insert(it+1, 10);这种是不对的
for (int i = 0; i < 1; i++)
{
++it;
}
lt1.insert(it, 10);
print(lt1);
//想在第2个位置后插入一个数组
int a[] = { 5,6,7,8 };
lt1.insert(it, a, a + 4);
print(lt1);
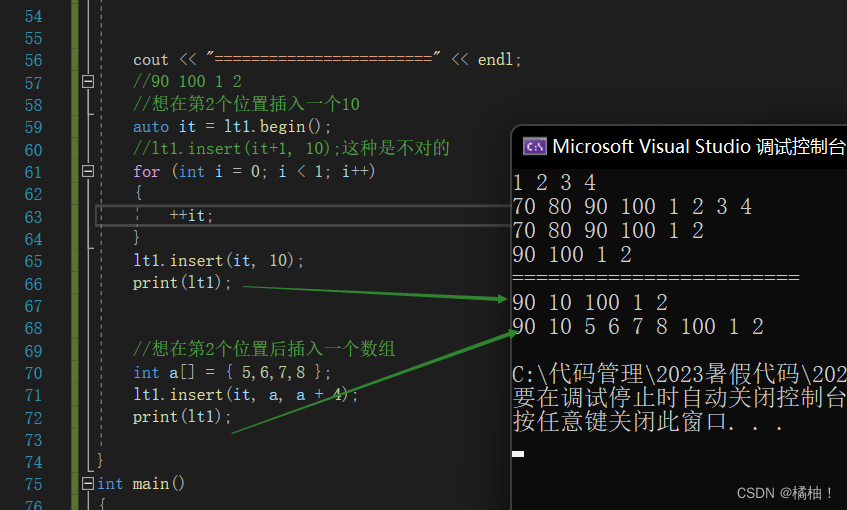
这是相比较前面两个不太的地方
参数列表都是和之前一样的,传的迭代器和上面的insert一样需要重新计算出来:
auto it = lt1.begin();
for (int i = 0; i < 1; i++)
{
++it;
}
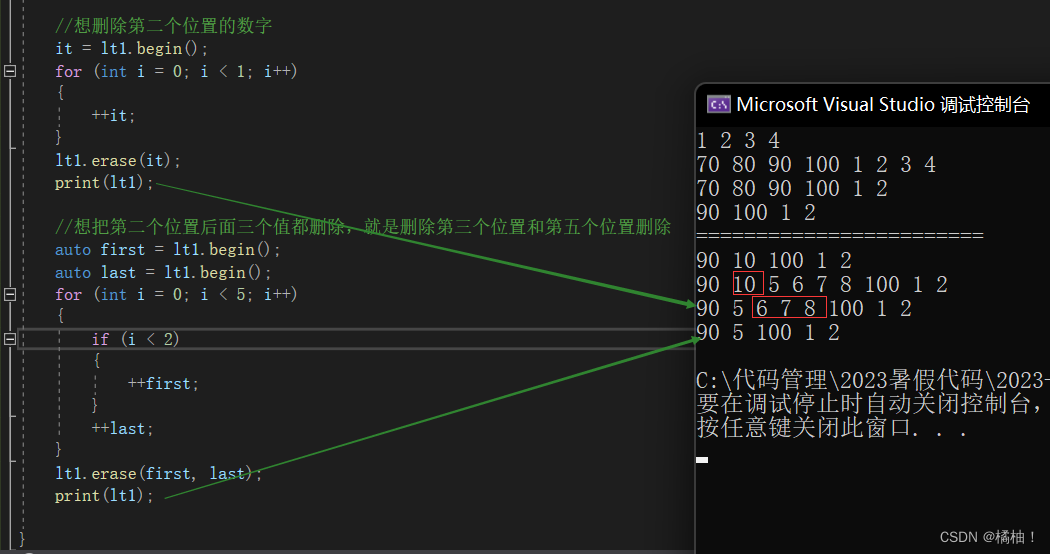
lt1.erase(it);
print(lt1);
//想把第二个位置后面三个值都删除,就是删除第三个位置和第五个位置删除
auto first = lt1.begin();
auto last = lt1.begin();
for (int i = 0; i < 5; i++)
{
if (i < 2)
{
++first;//先找到第三个位置
}
++last;//先找到第五个位置
}
lt1.erase(first, last);
print(lt1);
迭代器失效的问题:
在前面我们说过什么情况会导致迭代器失效,是迭代器指向了已经释放的空间,才会导致失效,迭代器失效即迭代器所指向的节点的无效,即该节点被删除了。因为list的底层结构为带头结点的双向循环链表,因此在list中进行插入时是不会导致list的迭代器失效的,只有在删除时才会失效,并且失效的只是指向被删除节点的迭代器,其他迭代器不会受到影响。
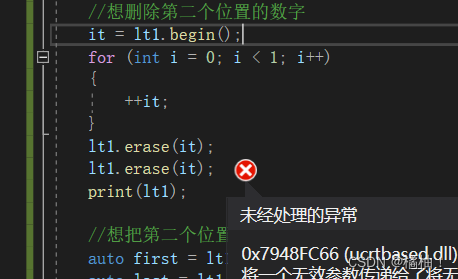
这中就会导致失效,第一次erase就已经导致it指向一个不存在的节点,此时按照之前按的方法重新赋值一下就行了。
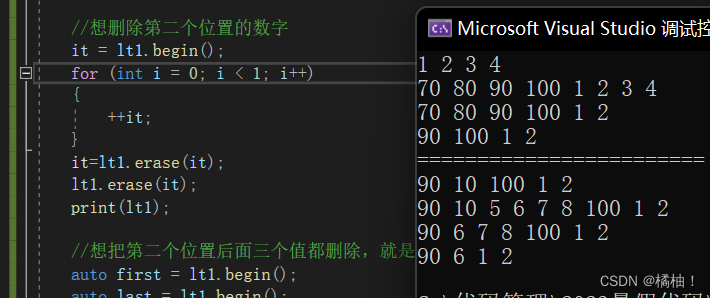
不涉及到扩容,这一块的问题还是相对好解决的,罪域头插头删,尾插尾删都是复用insert和erase,这个就不给大家测试了。
(3)resize和clear
之前是放在容量那一块,这个改变有效字符个数也涉及不到扩容,所以就放在修改函数这一块了,我们来看看具体使用吧
list<int> lt1;
lt1.resize(5, 20);
print(lt1);
lt1.clear();
print(lt1);
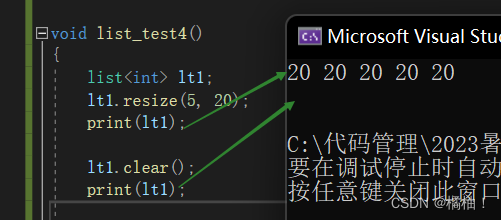
这个用法和前面的一样。
2.5其他的操作函数
接下来的函数有几个是之前没有学到的函数,重点介绍一下

(2)splice函数
这是拼接函数,准确来说是转移函数,将另一个链表的数据转移到另一个链表上,原来链表的数据就没有了
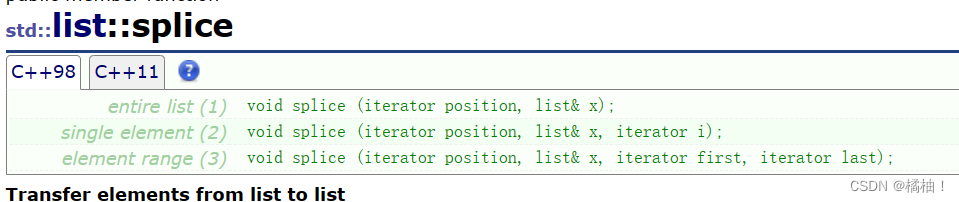
我们来看使用:
list<int> lt1;
lt1.push_back(1);
lt1.push_back(2);
lt1.push_back(3);
lt1.push_back(4);
list<int> lt2;
lt2.push_back(100);
lt2.push_back(200);
lt2.push_back(300);
lt2.push_back(400);
cout << "void splice(iterator position, list & x);//把lt2的数据转移到lt1的开头" << endl;
print(lt1);
print(lt2);
lt1.splice(lt1.begin(), lt2);
print(lt1);
print(lt2);
cout << "void splice(iterator position, list & x, iterator i);//把lt1的第一个数据转移到lt2的开头,只转移一个" << endl;
lt2.splice(lt2.begin(), lt1, lt1.begin());
print(lt1);
print(lt2);
cout << "void splice(iterator position, list & x, iterator first, iterator last);//把lt1的一部分数据转移到lt2的开头" << endl;
lt2.splice(lt2.begin(), lt1, lt1.begin(), lt1.end());
print(lt1);
print(lt2);
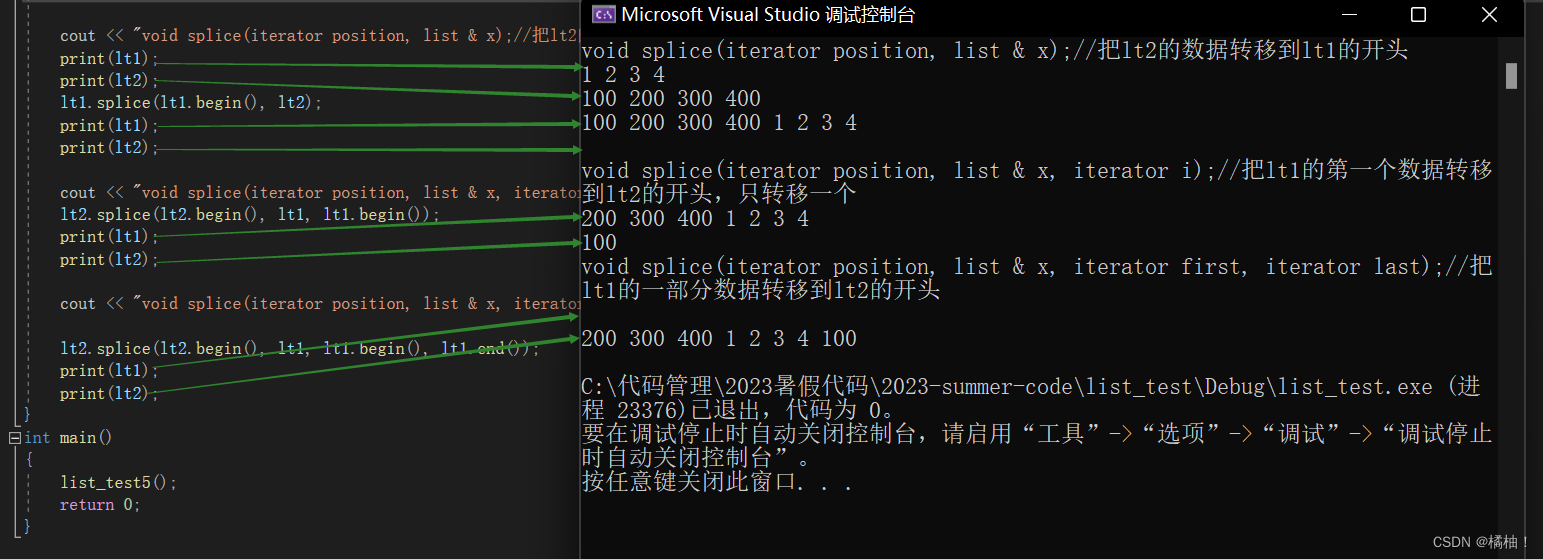
这个函数用到不多,大家了解就好了
(2)remove

这个函数就是先查找,在进行删除:
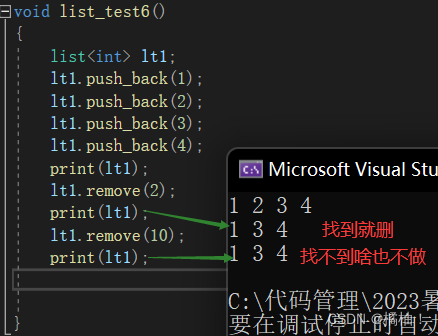
(3)remove_if
这个函数的参数是传一个函数参数,通过函数的功能进行筛选进行删除:
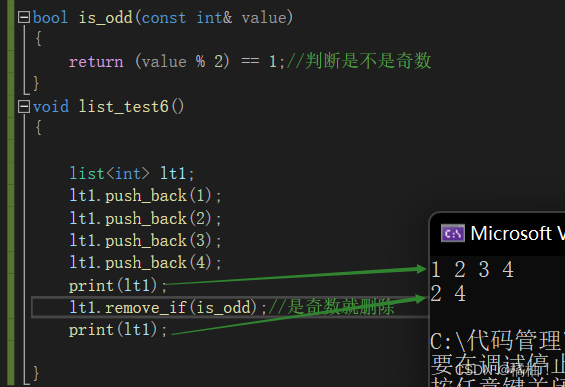
(4)sort
这个函数博主要重点介绍一下,在vector那个环节,sort函数是在算法里卖弄的,那个一位我们的容器要是排序使用算法里面的排序就好了,但是这里有单独设计了一个,这是为什么,是不是没有意义,我们用一下算法库里面的,在用一下本身的看看有什么区别:
本身的:
算法库里的:

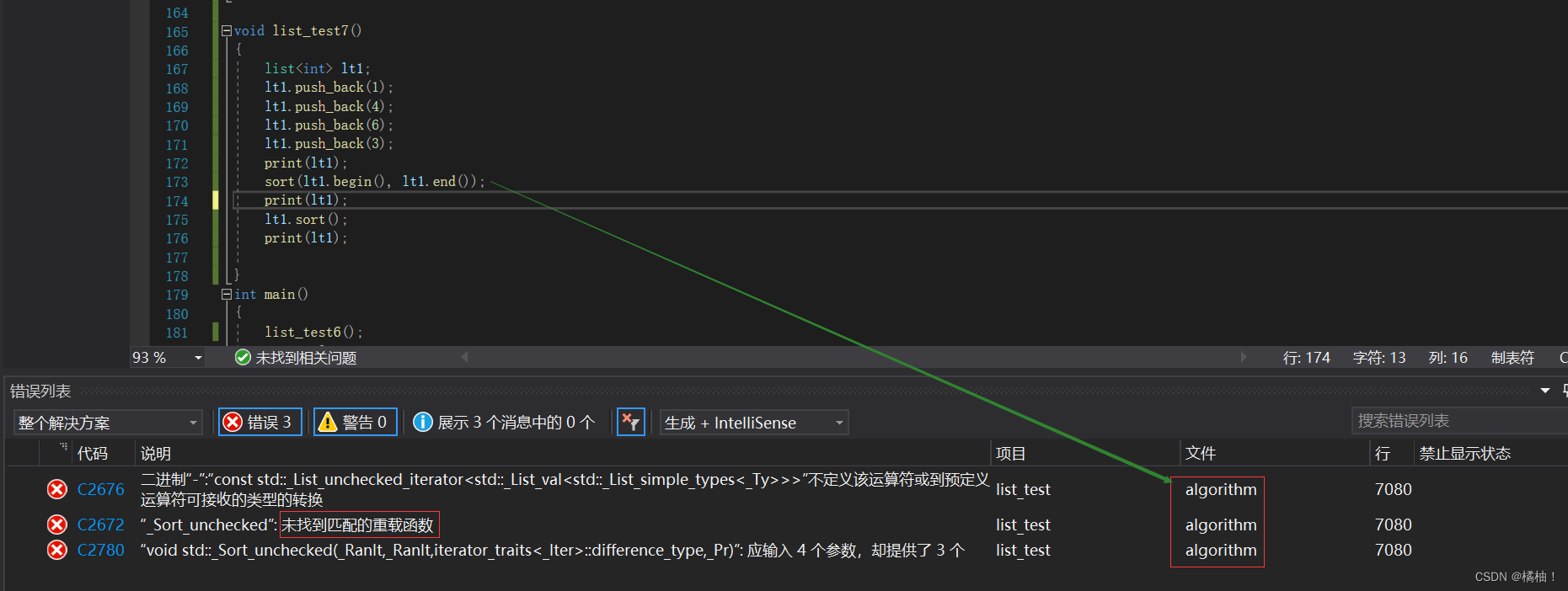
我们发现是库里面的函数出现错误,没有匹配的重载函数,我们也看到我们传的参数应该没有问题啊,但是细心的朋友可能就看出来了,模板参数的名字有所不太一样,来看分析:
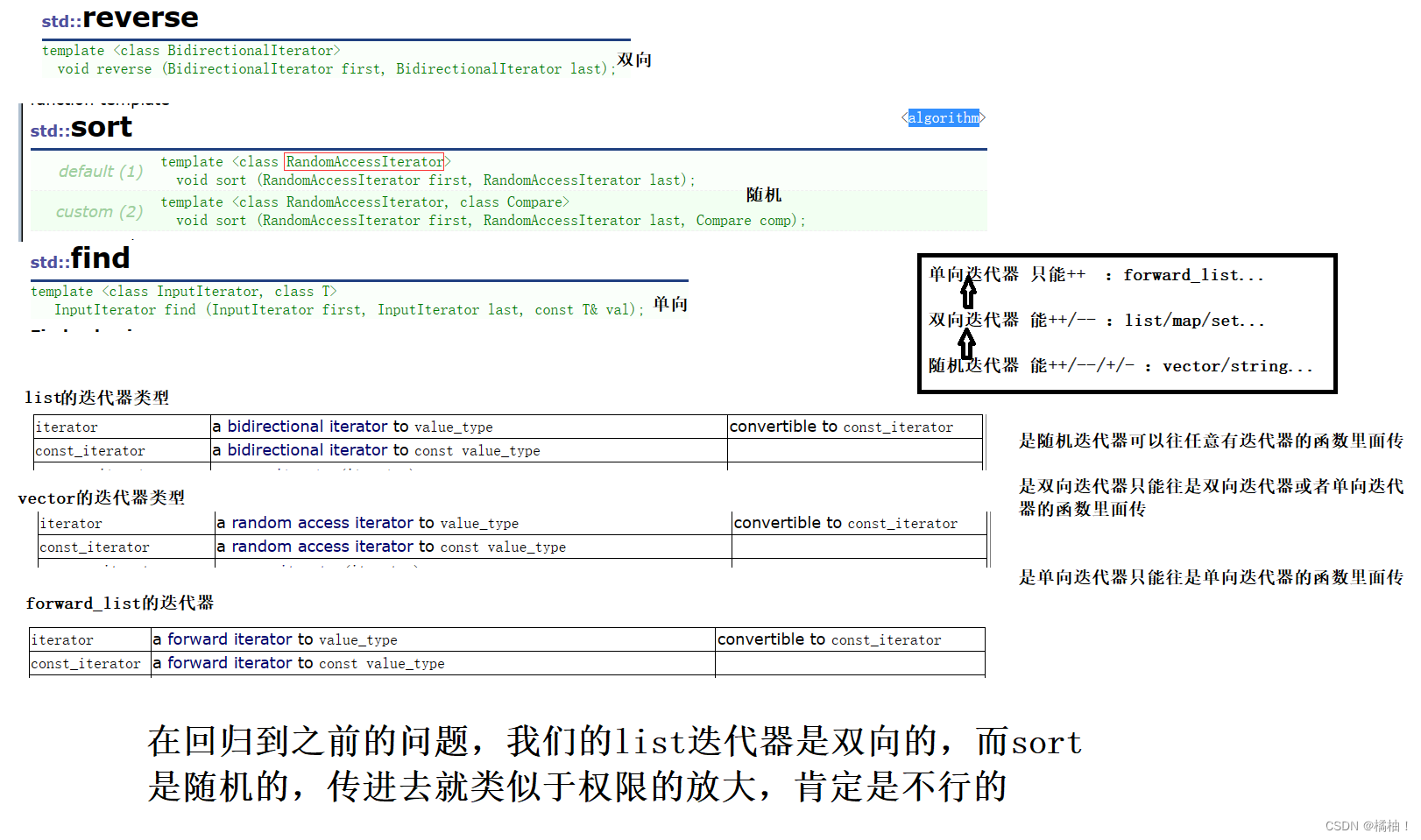
至此我们的list自带的sort是不就有意义了,但是要告诉你一点,意义不大,因为list里面的排序效率太慢了,我们通过vector的排序来比较,但是这样测的话要在realse版本下进行测试
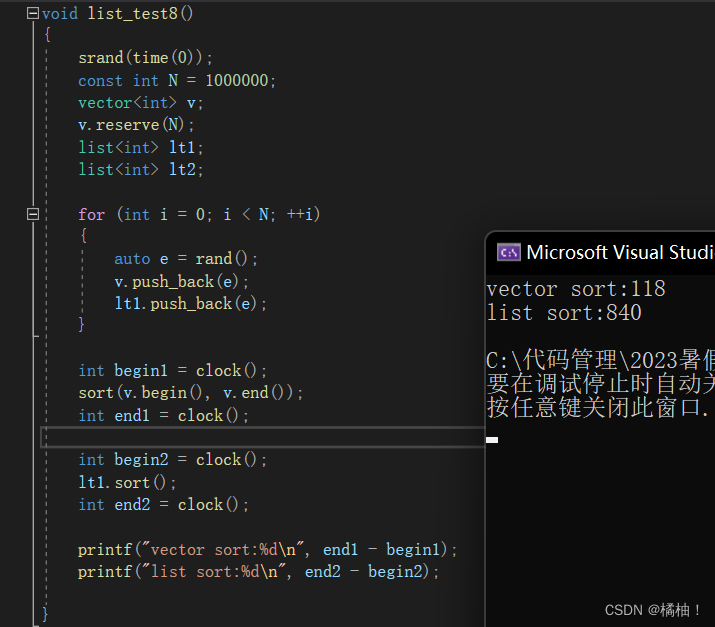
通过上面的例子可以还行啦,在相同数据的情况,vector使用算法库的排序,比list本身的怕思绪效率要高不好,尤其在数据量特别大的情况下更明显
那我们通过什么办法通过vector来帮助list排序呢??
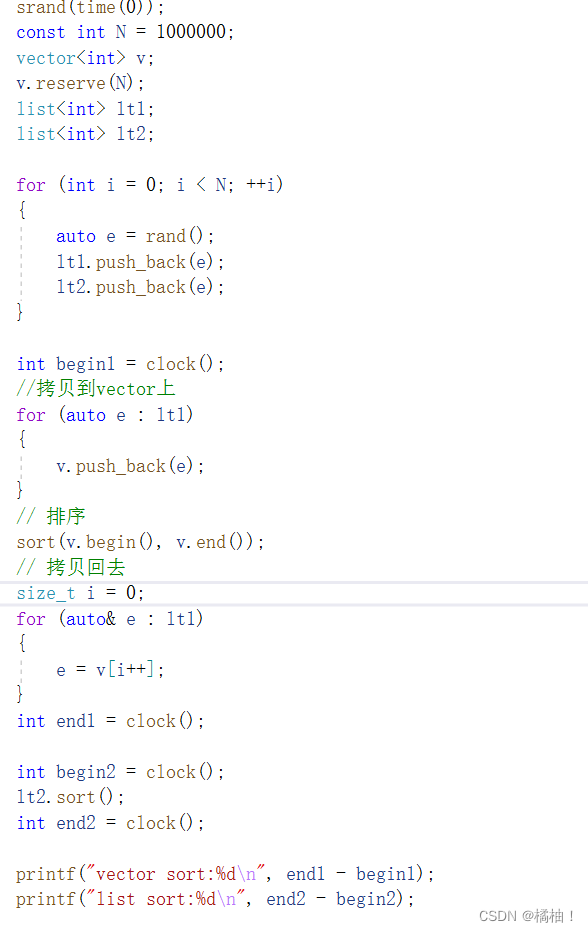
将数据拷贝到vector进行排序,然后再拷贝回来就可以了,效率比原来的sort要高
原因是算法库里面的排序使用的快排,而list本身的排序使用的是归并,所以数据量特别大的时候算法库里面的排序会特别快
注意:
我们一定要在realse版本下运行,上面也说过了,原因是,debug版本会添加许多调试信息,而快排是递归,调试信息会更多,而这里的归并用的是循环,所以调试信息少,如果再debug下测试,算符库里面的排序会慢很多。
(5)merge和reverse
这就是一个归并,两个合并成一个有序,前提两个链表都是有序的,reverse就是逆置,这两个函数用的不多,我就不用例子来解释了,大家自己去测试一下
三、总结
至此我们的vector的使用就讲解完毕了,接下来博主就要带大家进行模拟实现了,理解难度有所上升,大家要做好准备,把前面的知识点好好复习一下,我们下篇再见