文章目录
- Layer Normalization
- Classification Token
- Position embeedding
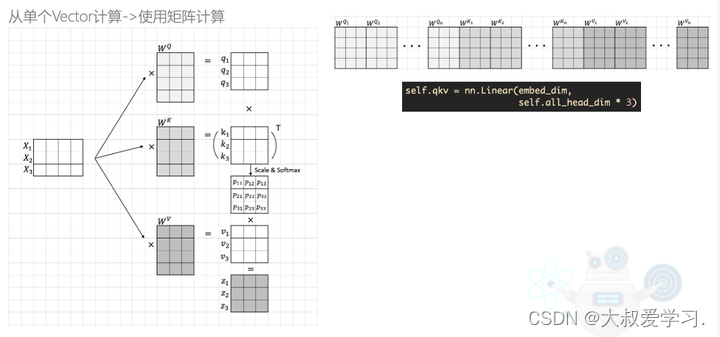
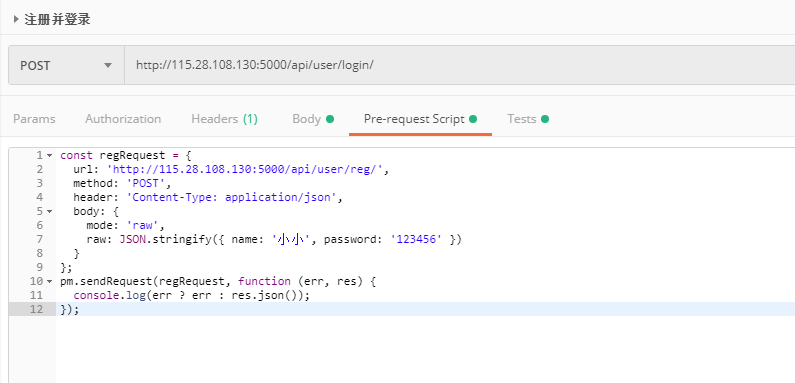
先把上一篇中的遗留问题解释清楚:上图中,代码中的all_head_dim就是有多少head。把他们拼接起来。
Encoder在Multi-Head Self-Attention之后,维度一直是BND`,一直没有变。
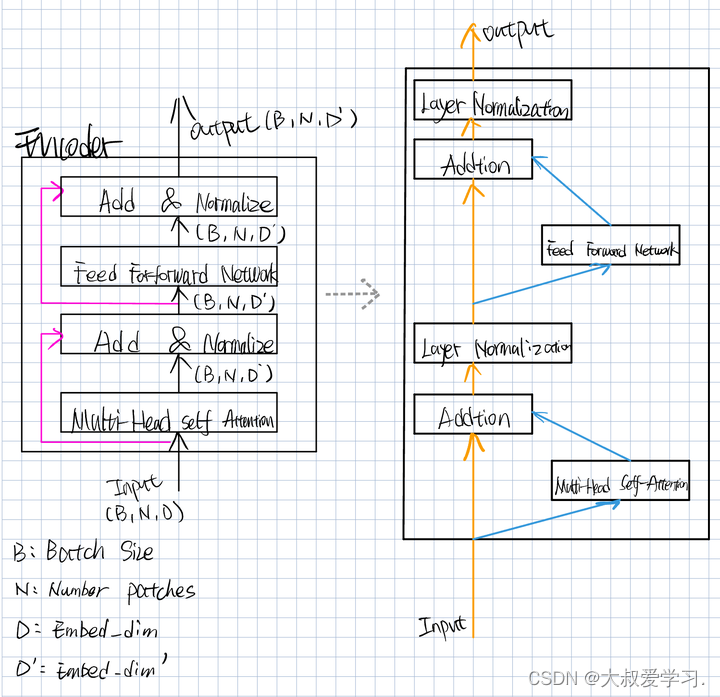
Layer Normalization
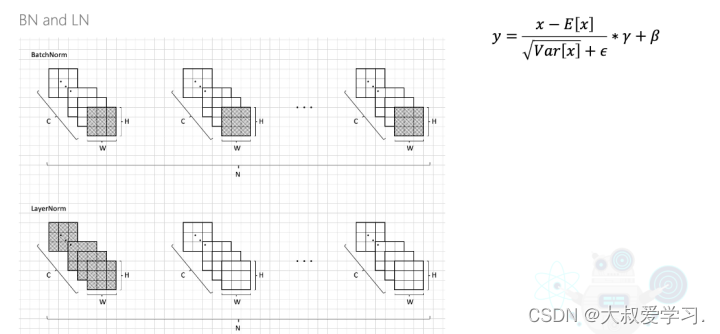
不论是BN(Batch Normalization)还是LN(Layer Normalization),都是对batch来做的。只是他们的归一化方式不同。我们在求mean和var时,是按照图中的灰色阴影来求的。BN的mean=(A, B, C)。假设batch是一摞书,总共做N本书,每一本书有C页,每一页有H行和W列的文字。BN做的就是把每本书的第一页抽出来,再取一个平均和方差,在做归一化。然后再把每本书的第2页抽出来,再做一遍均值,方差,归一化。一直到每本书做完。
LN还是假设我们有N本书,我们取第一本书的所有页,把他们都加起来做均值,方差,归一化。接着做第二本书的,一直做完N本书。
那么,为什么要在Transformer中用LN,而不用BN呢?又为何在CNN中用BN呢?BN主要关注的不同batch同channel的特征提取,LN关注的同batch不同channel的特征提取。CNN中,每一个channel学习的是一个固定的feature,每个channel学习某一个特征的固定表示,或颜色,或纹理,或位置,或其它表征信息。
实验中,Transformer也可以BN,但效果可能没有LN好,所以就沿用了LN。另外,第一,可能在Transformer中batch size不会特别大,第二,数据不定长,第三,同一个句子词之间有关系,但不同句子之间关系可能没有那么紧密。一个batch里可以存放不同的句子。
2种不同位置的Layer Normalization:PostNorm & PreNorm
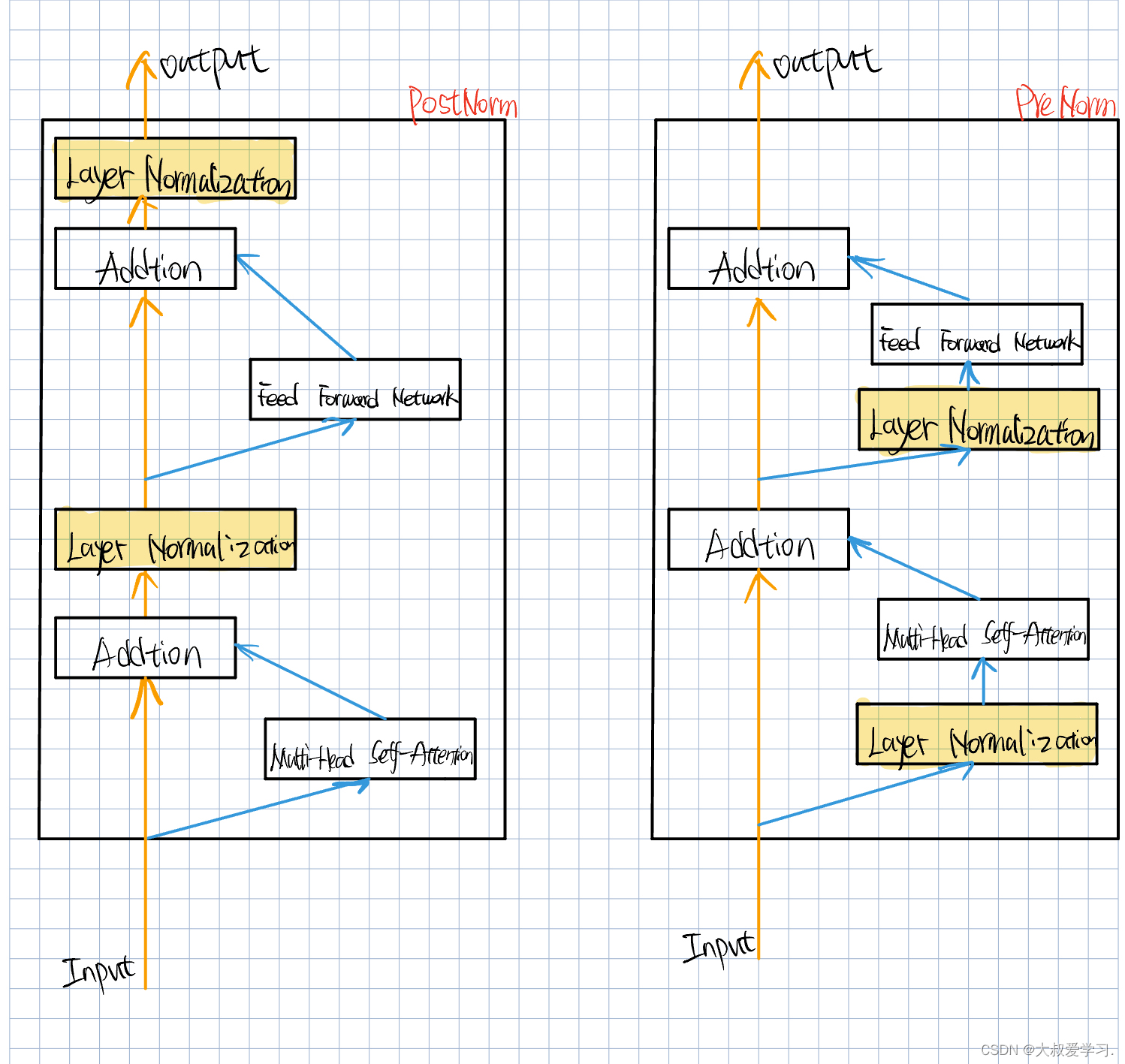
两种不同的位置。先MSA后LN,先LN后MSA。实现表明,Pre更容易收敛。PostNorm更容易爆掉。但是在Postnorm没有爆掉的里面,比PreNorm更好,参考下这2篇文章。
Xiong, Ruibin, et al. "On layer normalization in the transformer
architecture."International Conference on Machine Learning. PMLR,
2020.
Liu L, Liu X, Gao J, et al. Understanding the difficulty of training
transformers[J]. arXivpreprint arXiv:2004.08249, 2020.
Classification Token
AveragePool是把所有的token做一个平均,再送入classifier里做分类。
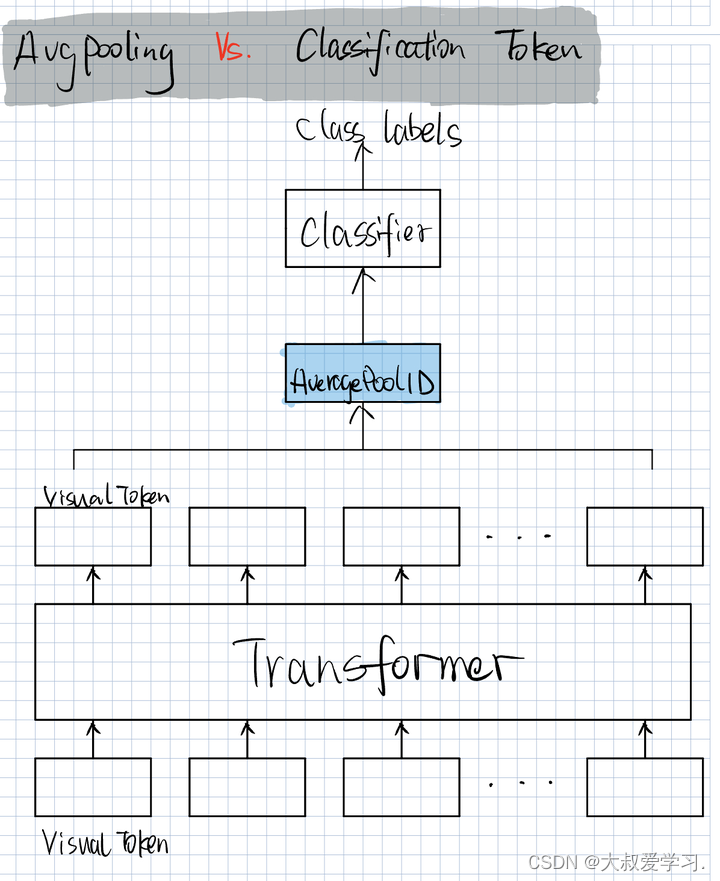
但是还有一种更NLP的方法,如下图:
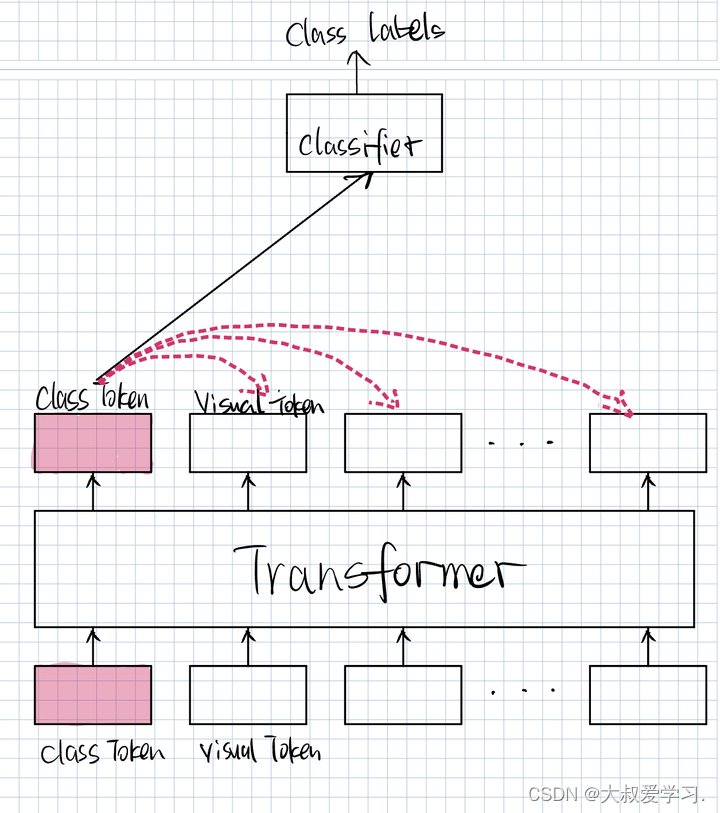
我们做CNN的时候,总是把feature做一个融合。或者做Transformer时,把patch进行融合。然后得到一个低维度的向量,去做分类。但在NLP里有一个Claas Token。我们单独添加一个token:Class Token(默认值给一个随机数),它的维度和我们的Visual Token(Patch Embedding)的维度是一样的。它的任务是学习分类,它去看每一个序列的信息,然后提取出图像分类相关的信息,用来作为自己的feature表征,送到Classifier。Class Token可以看到所有token的信息。SwinTransformer是用的Avg,没有用Class Token。
Position embeedding
我们前2篇说的,它少了一个位置编码。位置编码器为什么重要,先从NLP解释。比如下面两句话:
A:大叔曾经说自己很爱学习
B:大叔说自己曾经很爱学习
两个曾经的位置不同,含义也不一样。我当然不喜欢B这个表述,而更喜欢A。
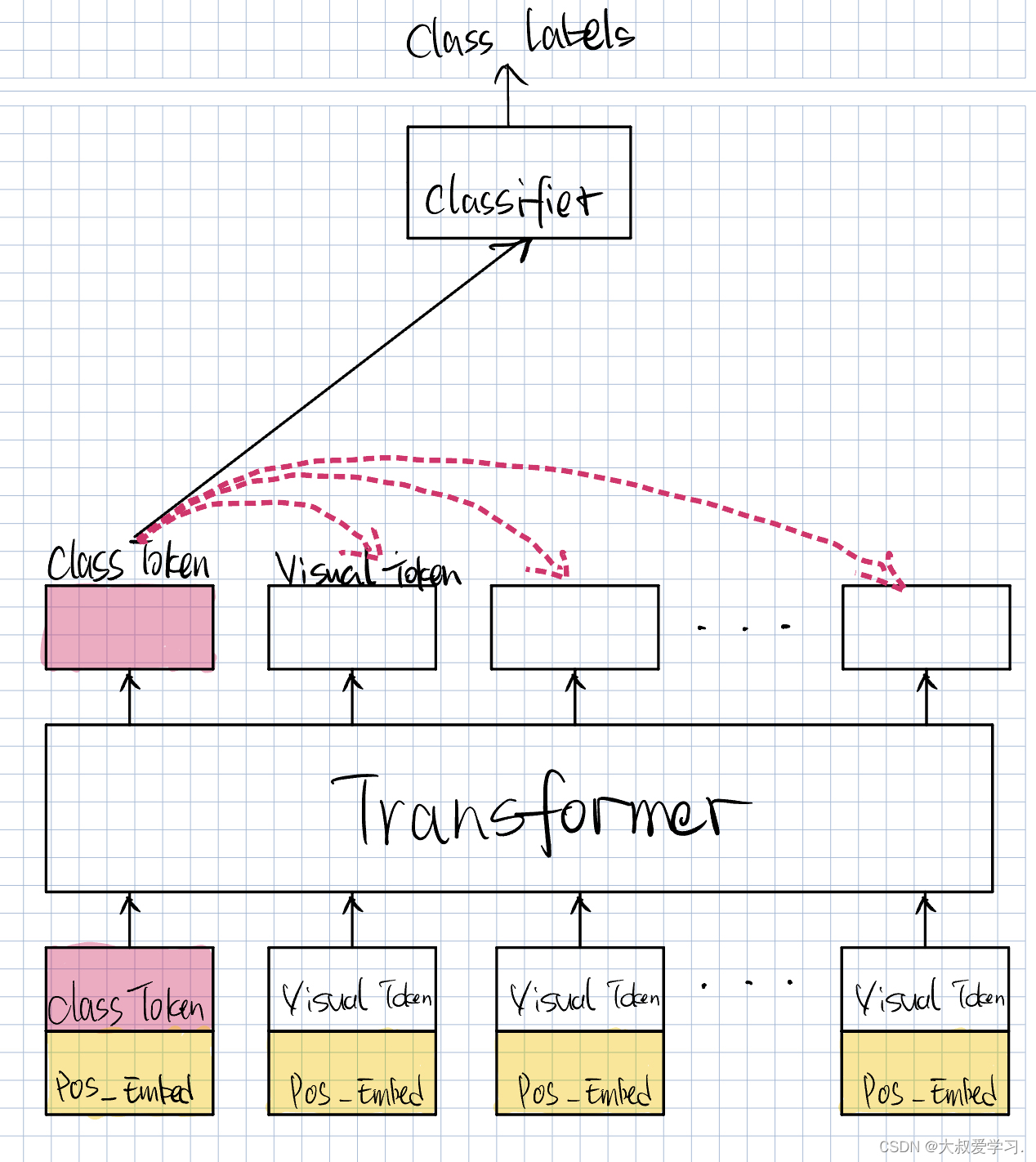
在图像领域,图像中物体的位置也是有关系的,所以在视觉Transformer也是重要的。
TransformerInput = VisualToken + PosEmbed
更推荐Position Embedding,可学习的。Visual Token和Position Embedding怎么结合,直接相加,或者concat也可以。Position Embedding的初始化,我们可以给它一个随机值。