此篇博客主题:LLAMA模型数据、训练时长、功耗及碳排放量
LLaMA: Open and Efficient Foundation Language Models
paper https://arxiv.org/pdf/2302.13971v1.pdf
1 训练样本
Overall, our entire training dataset contains roughly 1.4T tokens after tokenization. For most of our training data, each token is used only once during training, with the exception of the Wikipedia
and Books domains, over which we perform approximately two epochs.
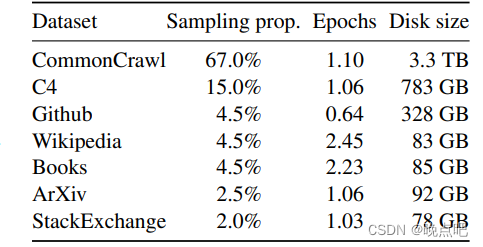
- 模型训练样本来源及占比如下图,经数据清理去重后剩下1.4Ttokens数据 (1.4T=1.4e12)
- 数据训练次数见Epochs ,大多数都只训练一轮,但book,wikipeida等数据会训练两轮左右(可能数据价值更高)
2 训练时间
When training a 65B-parameter model, our code processes around 380 tokens/sec/GPU on 2048 A100 GPU with 80GB of RAM. This means that training over our dataset containing 1.4T tokens takes approximately 21 days.
训练65B参数模型:
GPU数:2048
GPU型号:A100,80G
训练数据:1.4T
GPU数据处理速度:380 tokens/s/GPU
训练时间:21天 (计算公式如下)
t
=
1.4
∗
1
e
12
/
(
2048
∗
24
∗
3600
∗
380
)
=
21
d
a
y
t=1.4*1e12 /(2048*24*3600*380)=21 day
t=1.4∗1e12/(2048∗24∗3600∗380)=21day
3 碳排放量
- 每小时瓦数估计Watt-hour(WH)
W h = G P U − h ∗ ( G P U 瓦数 ) ∗ P U E Wh=GPU-h * (GPU 瓦数) * PUE Wh=GPU−h∗(GPU瓦数)∗PUE
PUE表示:电源使用效率
碳排放量公式为
t C O 2 e q = M W H ∗ 0.385 tCO_2eq=MWH*0.385 tCO2eq=MWH∗0.385
we estimate that we used 2048 A100-80GBfor a period of approximately 5 months to develop our models. This means that developing these models would have cost around 2,638 MWh under our assumptions, and a total emission of 1,015 tCO2eq.
我们使用2048个A100 80GPU,开发了约5个月。大约使用了2638Mwh, 碳排放量约为1015tCO2eq
4 思考
We hope that releasing these models will help to reduce future carbon emission since the training is already done, and some of the models are relatively small and can be run on a single GPU.
我们希望开源更多的大模型,再已有的模型基础上训练,减少重复开发,减少碳排放量。