![]()
![]()
![]()
![]()
![]()
目录
1、归并排序引申出的问题
2、磁盘与文件的关系---包含与被包含的关系
3、思路:
4、代码实现
1、归并排序引申出的问题
归并排序是最常用的外排序的方法(但归并排序既可进行内部排序也可进行外部排序),外排序就是在磁盘中的排序,不是在内存中。
若文件中有10亿个数据,需要排序,怎么办?假设内存中最多只能放1000w个数据。
怎么弄?用磁盘来弄,因为磁盘我们可认为是无限大的,因为磁盘有几百个G。
补充知识(会就不用看):
2、磁盘与文件的关系---包含与被包含的关系
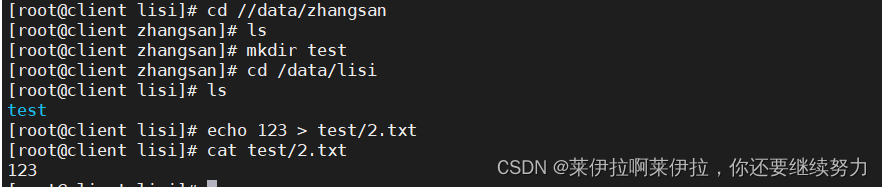
磁盘、文件夹和文件三者之间存在包含与被包含的关系。磁盘存储的数据中包括文件夹和文件,文件夹中也可包含文件夹和文件,理解为文件夹是一个小型的磁盘,而文件就是具体的存储数据。磁盘是为了便于管理电脑中所有数据而划分出来的分区,文件夹是为了便于管理磁盘中数据文件而建立的,文件则是存储数据信息而存在的,所以管理区域不同(磁盘中虽可以直接保存文件,但当文件过多时不利于用户查找,故最好用文件夹将其归类存放),但这三者具备共同的存储数据功能。
3、思路:
把10亿个数据读出来,因为文件中排序太慢(磁盘中和内存中的速度相差很多),故在内存中排,而内存中每次最多只能放1000w个数据,则分为100份,每份都在内存中排完再放入文件。归并是在文件中归并。(外排序尽量在内存中小段小段排好序,再用来归并,这样效率才高)
大文件平均分割为n份(具体多少份看实际情况),保证每份大小可以加载到内存,那就可把每个小文件加载到内存中,使用快排排成有序,再写回小文件。
总结:
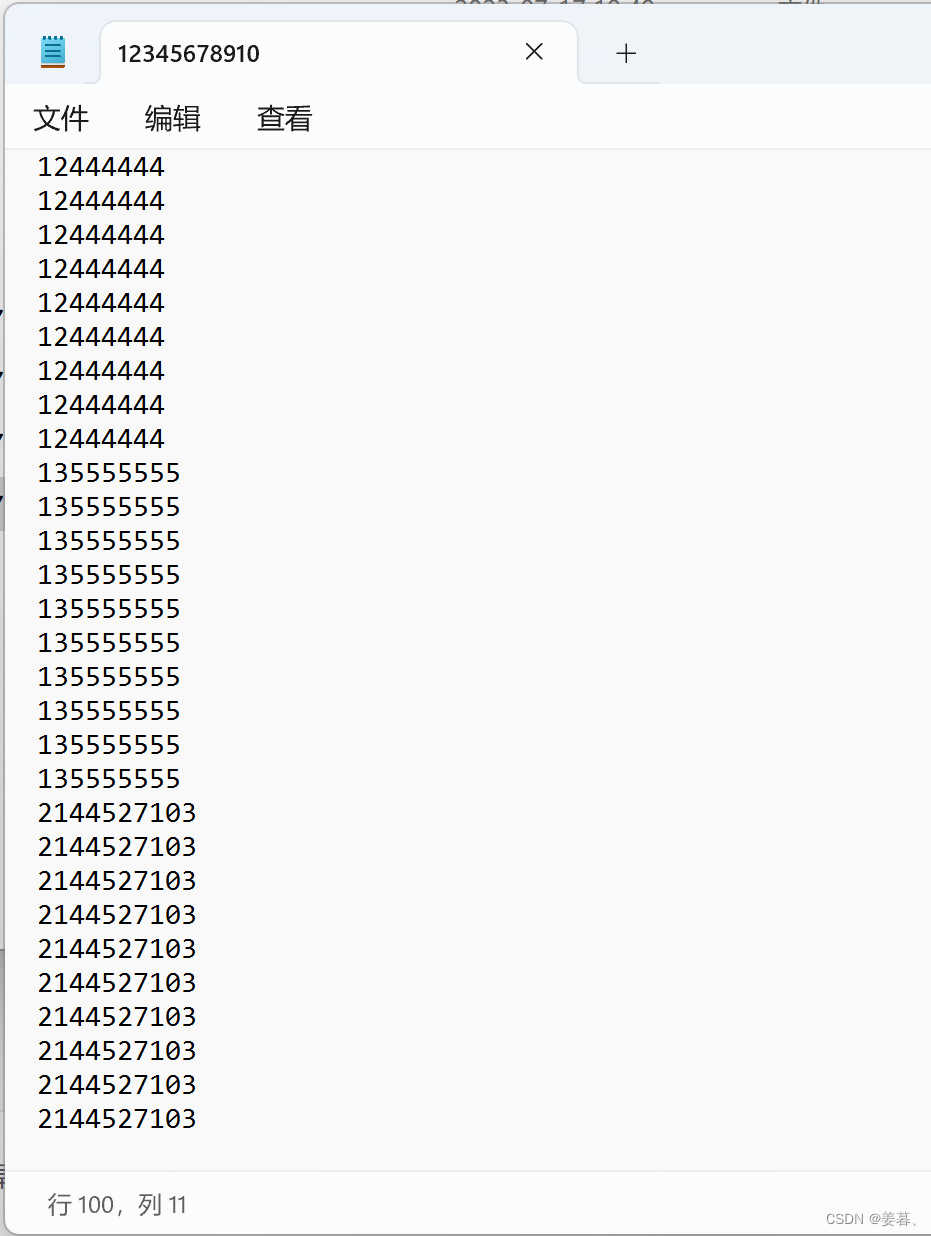
1亿个数据不便于测试和写,我们这里假设用100个数据,分为10份(10个文件,每个文件10个数据)来处理:
整体思路:
1、排序:
把100个数据分为10份,每份10个数据,对于每一份先排序(这里我利用快排)然后保存到数组中,排完再把数组中10个数据写入第一个文件中,然后循环,直到10个文件写完了
2、归并:
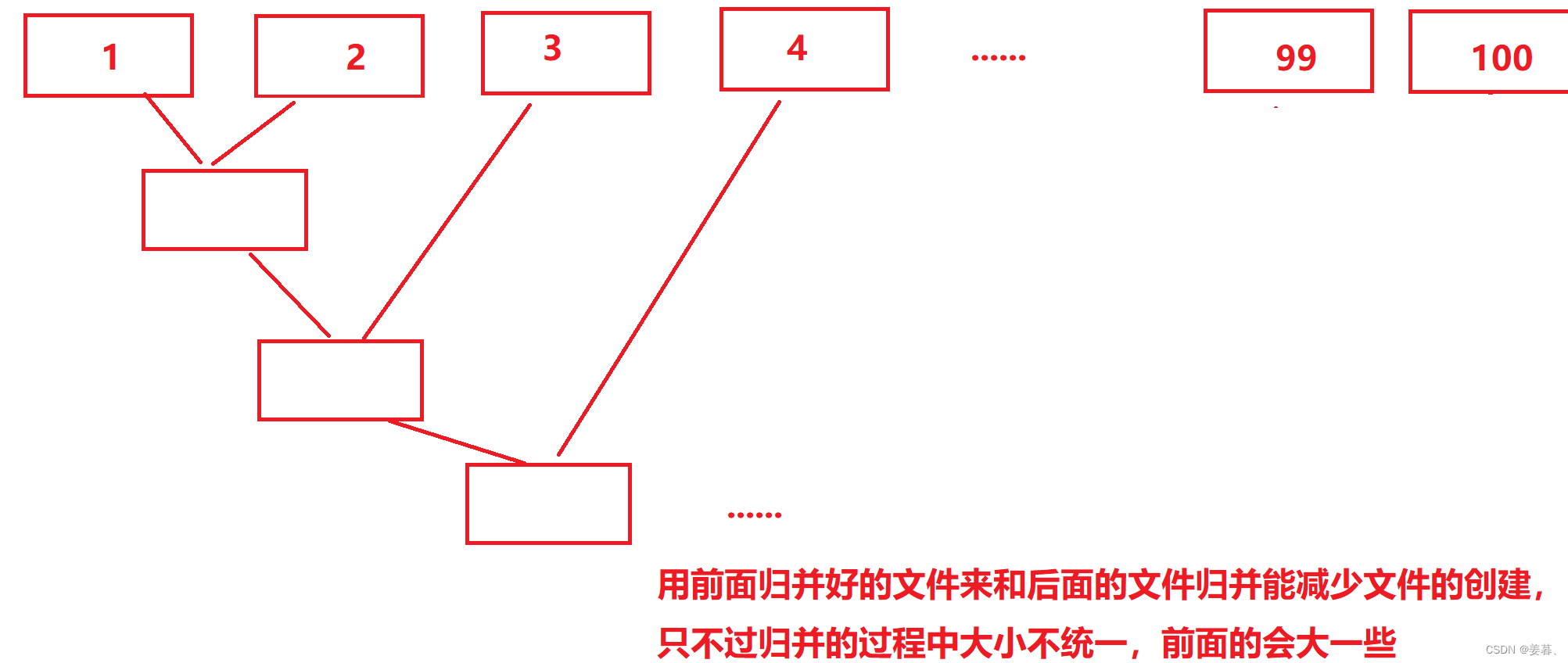
因为文件内部有序了,所以两个文件才可归并。不采用两个两个挨着归并,因为会建很多文件(如下如①),我们采用下图中的②,两个文件归并完后的文件再和后一个文件归并
①、
②、


4、代码实现
#include<stdio.h>
#include<stdlib.h>
//归并两个文件
void _MergeFile(const char* file1, const char* file2, const char* mfile)
{//把两个小文件归并为一个文件(mfile),因为已知这两个小文件是有序的,所以才可以归并
FILE* fout1 = fopen(file1, "r");
if (fout1 == NULL)
{
printf("打开文件失败\n");
exit(-1);
}
FILE* fout2 = fopen(file2, "r");
if (fout2 == NULL)
{
printf("打开文件失败\n");
exit(-1);
}
FILE* fin = fopen(mfile, "w");
if (fin == NULL)
{
printf("打开文件失败\n");
exit(-1);
}
int num1, num2;
int ret1 = fscanf(fout1, "%d\n", &num1);//fscanf返回值是所读入的数据个数或EOF,即返回值为整形
int ret2 = fscanf(fout2, "%d\n", &num2);
while (ret1 != EOF && ret2 != EOF)
{//如果两个中有一个文件读完了,则循环终止
//谁小就先写入mfile文件中
if (num1 < num2)
{
fprintf(fin, "%d\n", num1);
ret1 = fscanf(fout1, "%d\n", &num1);//如果是小的需再读一次
}
else
{
fprintf(fin, "%d\n", num2);
ret2 = fscanf(fout2, "%d\n", &num2);
}
}
//看两个文件中哪个文件中还有数据,就写入fin文件中
// 但下面的代码不行,假设上面ret1读到EOF了,ret2可能就是一个数
// 然后你又fscanf读了一次放入num1(2)中,这就导致原来ret1和ret2
// 中保存的数据丢失了,所以还要用ret1和ret2继续实现
//while (fscanf(fout1, "%d\n", &num1) != EOF)
//{//fscanf返回值为0时,表示未成功匹配到任何数据项
返回值为-1时,表示在读取过程中出现了错误
返回值为正整数:表示成功匹配并读取的数据项数
// fprintf(fin, "%d\n", num1);
//}
//while (fscanf(fout2, "%d\n", &num2) != EOF)
//{
// fprintf(fin, "%d\n", num2);
//}
while (ret1 != EOF)
{
fprintf(fin, "%d\n", num1);
ret1 = fscanf(fout1, "%d\n", &num1);
}
while (ret2 != EOF)
{
fprintf(fin, "%d\n", num2);
ret2 = fscanf(fout2, "%d\n", &num2);
}
fclose(fout1);
fclose(fout2);
fclose(fin);
}
//假设要排序的文件中都是一行放一个数据
//内存中排好序并放入文件
void MergeSortFile(const char* file)
{
FILE* fout = fopen(file, "r");
if (fout == NULL)
{
printf("打开文件失败\n");
exit(-1);
}
//分割成一段一段数据,内存排序后写到小文件中
int n = 10;//切10份
int a[10];//每份都10个数据
int i = 0;
int num = 0;
char subfile[20];//文件名
int filei = 1;//假设从第一个文件开始
while (fscanf(fout, "%d\n", &num) != EOF)
{
if (i < n - 1)
{//如果写为i<n,确实读了n(10)个数据,但是最后读完了还要一次while循环
//fscanf又读了一次,放入num,可是此时直接开始排序了,排完i=0了,然后又while
//循环一次,放入num中,可之前那个num你还没用,就又读了一个,导致数据丢失
//故这里用i<n-1,先读n-1(9)个数据,然后走else把读到的num给a[i],然后排序完
//i再置为0再完成下一个文件的,这里就符合了
a[i++] = num;
}
else
{
a[i] = num;
//读满了10个数据
QuickSort(a, 0, n - 1);//快速排序,自己写的函数,只要能排成升序即可
sprintf(subfile, "%d", filei++);//输出文件名到subfile
FILE* fin = fopen(subfile, "w");
if (fin == NULL)
{
perror("fopen");
exit(-1);
}
for (int i = 0; i < n; i++)
{
fprintf(fin,"%d\n", a[i]);
}
fclose(fin);
i = 0;//i=0,以便写入下一个文件
}
}
//利用互相归并到文件,实现整体有序
char mfile[100] = "12";//归并出的文件
char file1[100] = "1";
char file2[100] = "2";
//要归并n个文件
for (int i = 2; i <= n; i++)
{
//读取file1和file2,进行归并出mfile
_MergeFile(file1, file2, mfile);
strcpy(file1, mfile);//将mfile文件名拷贝给file1,以便下一次的归并
sprintf(file2, "%d", i + 1);//同时file2文件名向后一位
sprintf(mfile, "%s%d", mfile, i + 1);//赋予新的文件名
}
fclose(fout);
}
int main()
{
int a[6] = { 4,2,5,7,8,2 };
MergeSortFile("sort.txt");
return 0;
}运行结果分析:
首先在当前程序文件目录下创建"sort.txt"文件,并写入100个数据,一行一个,最后会产生以下文件,12345678910文件中的数据才是100个数据排好的状态