Jenkins借助钉钉插件,实现当构建失败时,自动触发钉钉预警。虽然插件允许自定义消息主体,支持使用 Jenkins环境变量,但是局限性依旧很大。当接收到钉钉通知后,若想进一步查看报错具体原因,仍完全依赖邮件通知,很影响效率。
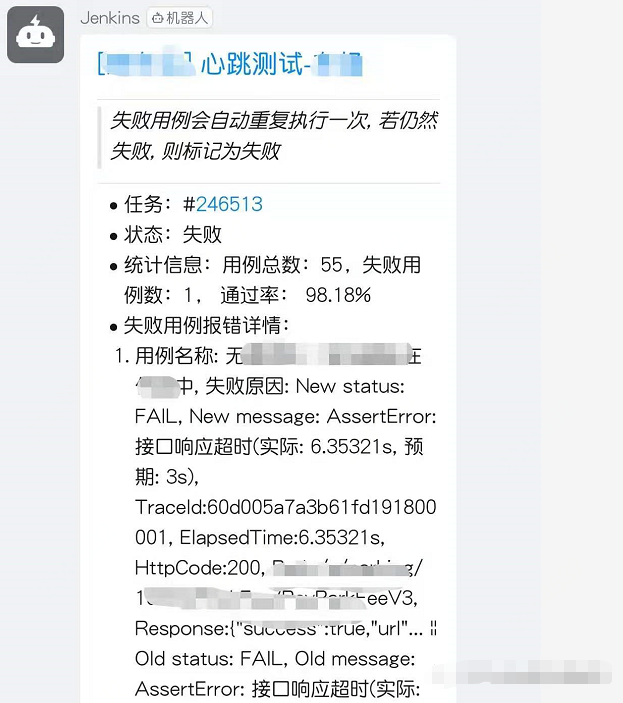
如何在钉钉通知消息中,获取到本次构建的具体内容,如失败占比、失败用例报错详情等,本文记录了解决思路。最终实现结果如图:
解决思路
Jenkins+RobotFramework项目
思路如下:
1、使用Startup Trigger插件和Groovy plugin插件,在服务重启时自动修改Jenkins CSP配置,解决Robot Framework项目测试报告在Jenkins服务器上无法预览的问题,如下:
System.setProperty("hudson.model.DirectoryBrowserSupport.CSP", "")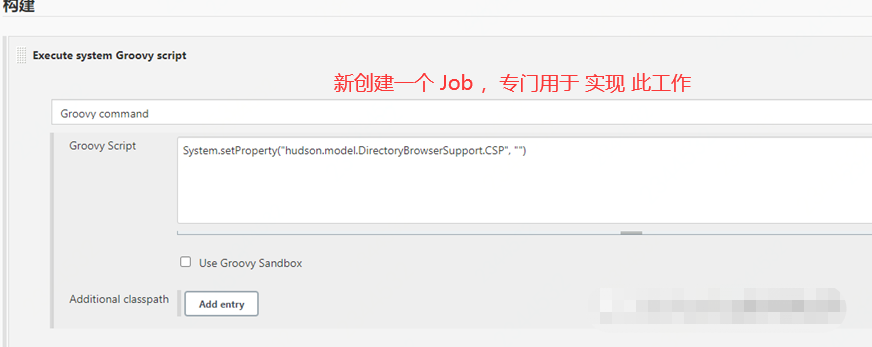
2、Jenkins项目构建完成后,在构建后操作中,利用Post Build Task插件提供的命令行功能,传入相关参数执行封装的脚本,如下:
if "%构建失败时触发钉钉通知%"=="true" (
echo ************推送钉钉消息通知************
cd %WORKSPACE%/test
C:/python38/python.exe dingtalk.py --id=%BUILD_NUMBER% --name=%JOB_NAME% --server=xxxxxx
echo *******************************************
exit 0
)说明几点:
-
“构建失败时触发钉钉通知” 是我自定义的布尔类型的项目构建参数,用于更方便的控制是否触发钉钉消息通知;
-
dingtalk.py是封装的脚本,其内容在下面会详细说明;
-
Post Build Task插件的位置必须位于Robot Framework插件之后, 否则会引发以下异常:
robot.errors.DataError: Reading XML source '<in-memory file>' failed: Incompatible XML element 'html'3、编写第二步中调用的钉钉消息通知脚本,其核心思路可分为两点:
-
获取并分析本次构建结果文件(如: output.xml)、提取数据,如: 失败占比、失败用例报错详情等
-
组装Markdown格式的消息主体,然后调用DingTalk Webhook接口,推送消息通知。
核心代码如下:
def fetch_robot_output_xml(xml_name=None, save=False, cache=True) -> str:
""" 从服务器上获取 Robot Framework 项目构建完成后生成的xml文件
@param xml_name: xml文件名称, 部分项目会合并测试报告, 默认`merge.xml`
@param save: 是否将文件保存到本地, 默认 False
@param cache: 默认为True, 会首先遍历本地已保存的构建文件, 若文件名称不存在才会向服务器发起请求;
@Returns : xml文件内容
"""
xml_name = xml_name if xml_name else "merge.xml"
url = url_prefix + f"{name}/{id}" + f"/robot/report/{xml_name}"
output_xml = None
if cache:
for xml in robot_outputs.glob('*.xml'):
if name in xml.stem and id in xml.stem:
output_xml = xml.read_text(encoding='utf-8')
break
if not output_xml:
print(f"发起请求获取测试报告, 目标URL: {url}")
# curl -X GET {URL} --user {USER}:{TOKEN}
resp = requests.get(url, auth=HTTPBasicAuth(jenkins_user.encode('utf-8'), jenkins_token.encode('utf-8')))
resp.encoding = 'utf-8'
output_xml = resp.text
if save and not cache:
save_output_xml(output_xml, f"{server}_{name}_{id}_output.xml")
print("Done.")
return output_xml
def parse_robot_result(xml) -> dict:
"""解析用例运行结果
pip install robotframework==3.2.1
获取统计信息, 优先使用此方法, 因为xml文件中可能会不包含有效的测试报告信息, 如请求获取文件服务器返回404的情况
"""
print('解析用例运行结果...')
try:
suite = ExecutionResult(xml).suite
except DataError as e:
raise e('解析xml文件失败, 请检查构建文件内容是否完整, 确认服务器上的构建文件是否已被删除')
all_tests = suite.statistics.critical
total, passed, failed = all_tests.total, all_tests.passed, all_tests.failed
pass_rate = round((passed / total) * 100, 2)
is_success = True if failed == 0 else False
stat = {'server': server, 'job': name, 'build_id': id, 'total': total, 'passed': passed, 'failed': failed, 'pass_rate': str(pass_rate) + "%", 'is_success': is_success}
print('Done')
return stat
def pick_fail_cases(xml: str) -> list:
print('获取所有失败用例及其报错信息...')
root = ET.fromstring(xml)
fail_cases = []
for case in root.iter('test'):
status = case.find('status')
if status.get('status') == "FAIL":
fail_cases.append({"case": case.get('name'), "message": truncate_text(status.text)})
print('Done.')
return fail_cases
def package_dingtalk_text(stat: dict) -> dict:
print("组装钉钉通知信息主体...")
# 项目页面地址
job_url = url_prefix + stat['job'] + '/'
# 本次构建ID以及详情页面地址
build_id = stat['build_id']
build_url = job_url + build_id + '/'
# 统计信息
summary_text = f"用例总数:{stat['total']},失败用例数:{stat['failed']}, 通过率: {stat['pass_rate']}\n"
# 用例报错详情
case_error_details = ""
num = 1 # 序号
if len(stat['fail_cases']) > 0:
for case in stat['fail_cases']:
case_error_details = case_error_details + f"{num}. 用例名称: {case['case']}, 失败原因: {case['message']}\n"
num += 1
print("Done.")
return {
"server_show_name": server_show_name,
"job_show_name": job_show_name,
"job_url": job_url,
"build_id": build_id,
"build_url": build_url,
"summary_text": summary_text,
"case_error_details": case_error_details
}
def ding_talk(message=None):
"""
目前只支持markdown语法的子集, 参考官方文档: https://developers.dingtalk.com/document/app/custom-robot-access
"""
print("推送钉钉消息通知...")
webhook = "https://oapi.dingtalk.com/robot/send?access_token=1048af6c9a25ea5e924ae328c6782b68c48a40bcea773df96eadce783f2941ca"
headers = {"Content-Type": "application/json", "Charset": "UTF-8"}
payload = {
"msgtype": "markdown",
"markdown": {
"title":
"心跳测试",
"text":
f"# [[{message['server_show_name']}] 心跳测试-{message['job_show_name']}]({message['job_url']})\n***\n>*失败用例会自动重复执行一次, 若仍然失败, 则标记为失败*\n***\n- 任务:#[{message['build_id']}]({message['build_url']})\n- 状态:失败\n- 统计信息:{message['summary_text']}\n - 失败用例报错详情: \n\n{message['case_error_details']}\n"
},
"at": {
"isAtAll": True
}
}
resp = requests.post(webhook, json=payload, headers=headers)
print(resp.text)
print("Done.")
return respJenkins+Jmeter项目
前两步是共同的,也是通过解析result.jtl文件提取需要的数据,直接贴代码:
def fetch(xml_name=None, save_file=False) -> str:
xml_name = xml_name if xml_name else "result.jtl"
url = url_prefix + f"{name}/{id}" + f"/artifact/{name}result/{xml_name}"
print(url)
resp = requests.get(url, auth=HTTPBasicAuth(jenkins_user.encode('utf-8'), jenkins_token.encode('utf-8')))
status_code = resp.status_code
if status_code == 200:
resp.encoding = 'utf-8'
xml = resp.text
if save_file:
save(xml, f"{server}_{name}_{id}_{xml_name}")
return xml
elif status_code == 404:
print(f"{status_code}, 指定的测试报告不存在, 可能已被删除, 请去服务器上检查")
raise Exception("{status_code}, 指定的测试报告不存在, 可能已被删除, 请去服务器上检查")
elif status_code == 500:
print(f"获取测试报告失败, 详情: {status_code} >> {resp.text}")
raise Exception(f"获取测试报告失败, 详情: {status_code} >> {resp.text}")
else:
return None
def parse(xml):
"""分析xml测试报告, 提取数据"""
result = {}
try:
root = ET.fromstring(xml)
except ParseError:
raise ParseError("解析XML文件失败, 请检查服务器上文件是否存在")
# 获取统计信息
samples = root.findall('httpSample')
failures = [sample for sample in samples if sample.get('s') == "false"]
failures_cnt = len(failures)
success = [sample for sample in samples if sample.get('s') == "true"]
success_cnt = len(success)
is_success = True if failures_cnt == 0 else False
success_rate = "100%" if is_success else str(round((success_cnt / len(samples)) * 100, 2)) + "%"
result['summary'] = {"samples": len(samples), "is_success": is_success, "failures_cnt": failures_cnt, "success_rate": success_rate}
# 数据清洗, 获取失败用例的报错信息
fail_details = []
if failures_cnt > 0:
pat = re.compile(".*R-TraceId:(.*?)\n.*", re.DOTALL)
for sample in failures:
msg = []
for res in sample.findall('assertionResult'):
for child in res:
if child.tag in ("failure", "error") and child.text == "true":
try:
msg.append(res.find('failureMessage').text) # ?这个节点可能会不存在
except AttributeError:
msg.append("")
response_header = sample.find('responseHeader').text
try:
traceid = pat.match(response_header).group(1).strip()
except AttributeError:
traceid = None
response_data = sample.find('responseData').text.replace('\r\n', '')
fail_details.append({
'sample': sample.get('lb'),
"traceid": traceid,
'data': truncate_text(response_data),
'msg': truncate_text(",".join(msg))
})
result['fail_samples'] = fail_details
result.update({
"server": server,
'job': name,
'build_id': id,
})
return result






![[附源码]Python计算机毕业设计SSM基于人脸识别和测温的宿舍管理系统(程序+LW)](https://img-blog.csdnimg.cn/0cee7d35168d482e813b5e847af669ae.png)