文章目录
- 一 电商实时数仓介绍
- 1 普通实时计算与实时
- 2 实时电商数仓分层
- 二 实时数仓需求分析
- 1 离线计算与实时计算的比较
- 2 应数场景
- (1)日常统计报表或分析图中需要包含当日部分
- (2)实时数据大屏监控
- (3)数据预警或提示
- (4)实时推荐系统
- 三 统计架构分析
- 1 离线架构
- 2 实时架构
- 四 日志数据采集
- 1 模拟日志生成器的使用
- 2 本地测试
- (1)SSM和SpringBoot
- (2)创建SpringBoot
- a 创建空的父工程gmall2022-parent,用于管理后续所有的模块module
- b 新建SpringBoot模块,作为采集日志服务器
- c 配置项目名称及JDK版本
- d 选择版本以及通过勾选自动添加lombok、SpringWeb、Kafka相关依赖
- (3)Demo测试
- (4)模拟采集埋点数据,并进行处理
- a 在resources中添加logback.xml配置文件
- b 修改SpringBoot核心配置文件application.propeties
- c 在LoggerController中添加方法,将日志打印、落盘并发送到Kafka主题中
- d kafka常用命令
- e 修改hadoop101 上的rt_applog目录下的application.yml配置文件
- f 测试
一 电商实时数仓介绍
1 普通实时计算与实时
普通的实时计算优先考虑时效性,所以从数据源采集经过实时计算直接得到结果。如此做时效性更好,但是弊端是由于计算过程中的中间结果没有沉淀下来,所以当面对大量实时需求的时候,计算的复用性较差(如B想要使用A的结果),开发成本随着需求增加直线上升。

实时数仓基于一定的数据仓库理念,对数据处理流程进行规划、分层,目的是提高数据的复用性(如e可以直接使用b的结果)。

2 实时电商数仓分层
项目分为以下几层
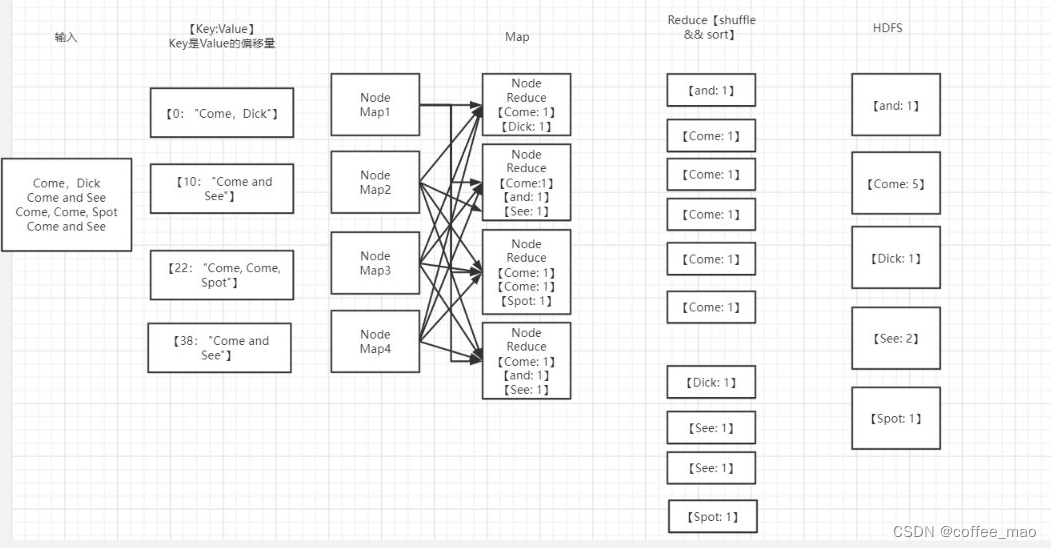
- ODS:原始数据,日志和业务数据。
- DWD:根据数据对象为单位进行分流,比如订单、页面访问等等。维度数据保存到HBase中,事实数据放到DWD主题中。
- DWM:对于部分数据对象进行进一步加工,比如独立访问、跳出行为,也可以和维度进行关联,形成宽表,依旧是明细数据。
- DWS:根据某个主题将多个事实数据轻度聚合,形成主题宽表。对于从DWD层获取不到的结果,从dwm层获取。所以实时数仓比离线数仓多出一层DWM。
- ADS: 把Clickhouse中的数据根据可视化需要进行筛选聚合。
二 实时数仓需求分析
1 离线计算与实时计算的比较
离线计算:就是在计算开始前已知所有输入数据,输入数据不会产生变化,一般计算量级较大,计算时间也较长。例如今天早上一点,把昨天累积的日志,计算出所需结果。最经典的就是Hadoop的MapReduce方式;
一般是根据前一(几)日(T + 1(n))的数据生成报表,虽然统计指标、报表繁多,但是对时效性不敏感。从技术操作的角度,这部分属于批处理的操作。即根据确定范围的数据一次性计算。
实时计算:输入数据是可以以序列化的方式一个个输入并进行处理的,也就是说在开始的时候并不需要知道所有的输入数据。与离线计算相比,运行时间短,计算量级相对较小。强调计算过程的时间要短,即所查当下给出结果。
主要侧重于对当日(T + 0)数据的实时监控,通常业务逻辑相对离线需求简单一下,统计指标也少一些,但是更注重数据的时效性,以及用户的交互性。从技术操作的角度,这部分属于流处理的操作。根据数据源源不断地到达进行实时的运算。
大数据的设计架构主要有两种:
- lambda:离线数据与实时数据一起运行,完成后将结果聚合起来。
- kappa:在实时计算得到结果后也可以做离线。【实时 + 离线】
Flink中的流批一体使用Flink-SQL实现,处理两种数据使用的SQL相同,不同点在于数据的日期。
2 应数场景
(1)日常统计报表或分析图中需要包含当日部分

对于日常企业、网站的运营管理如果仅仅依靠离线计算,数据的时效性往往无法满足。通过实时计算获得当日、分钟级、秒级甚至亚秒的数据更加便于企业对业务进行快速反应与调整。
所以实时计算结果往往要与离线数据进行合并或者对比展示在BI或者统计平台中。
(2)实时数据大屏监控

数据大屏,相对于BI工具或者数据分析平台是更加直观的数据可视化方式。尤其是一些大促活动,已经成为必备的一种营销手段。
另外还有一些特殊行业,比如交通、电信的行业,那么大屏监控几乎是必备的监控手段。
(3)数据预警或提示
经过大数据实时计算得到的一些风控预警、营销信息提示,能够快速让风控或营销部分得到信息,以便采取各种应对。
比如,用户在电商、金融平台中正在进行一些非法或欺诈类操作,那么大数据实时计算可以快速的将情况筛选出来发送风控部门进行处理,甚至自动屏蔽。 或者检测到用户的行为对于某些商品具有较强的购买意愿,那么可以把这些“商机”推送给客服部门,让客服进行主动的跟进。
(4)实时推荐系统
实时推荐就是根据用户的自身属性结合当前的访问行为,经过实时的推荐算法计算,从而将用户可能喜欢的商品、新闻、视频等推送给用户。
这种系统一般是由一个用户画像批处理加一个用户行为分析的流处理组合而成。
三 统计架构分析
1 离线架构

MQ的作用:
- 系统解耦
- 异步通信
- 流量削峰
2 实时架构

四 日志数据采集
1 模拟日志生成器的使用
这里提供了一个模拟生成数据的jar包,可以生成日志,并将其发送给某一个指定的端口,需要大数据程序员了解如何从指定端口接收数据并对数据进行处理的流程。

上传文件application.yml、gmall2022-mock-log-2022-11-28.jar。
根据实际需要修改application.yml。
使用模拟日志生成器的jar 运行
java -jar gmall2022-mock-log-2022-11-28.jar
目前还没有地址接收日志,所以程序运行后的结果有如下错误

注意:ZooKeeper从3.5开始,AdminServer的端口也是8080,如果在本机启动了zk,那么可能看到405错误,意思是找到请求地址了,但是接收的方式不对。
2 本地测试
(1)SSM和SpringBoot
Spring:帮助程序员创建对象并且管理对象之间的关系。
- IOC:控制反转。
- AOP:面向切面编程。
SpringMVC:接收客户端的请求,并且进行响应。
mybatis:ORM(ObjectRelationMapption),将关系型数据库中的一张表和java中的类进行映射。
SpringBoot将SSM进行整合,约定大于配置。
(2)创建SpringBoot
a 创建空的父工程gmall2022-parent,用于管理后续所有的模块module
为了将各个模块放在一起,但是模块彼此间还是独立的,所以创建一个Empty
Project即可;如果要是由父module管理子module,需要将父module的pom.xml文件的设置为pom。
b 新建SpringBoot模块,作为采集日志服务器
在父project下增加一个Module,选择Spring Initializr。

注意:有时候SpringBoot官方脚手架不稳定,可以切换Custom,选择国内地址。
c 配置项目名称及JDK版本

d 选择版本以及通过勾选自动添加lombok、SpringWeb、Kafka相关依赖

(3)Demo测试
创建FirstController输出SpringBoot处理流程。
几个注解说明:
- Controller:将类对象的创建交给Spring容器,但是用Controller标记的类,如果方法的返回值是String,那么认为进行页面的跳转。
- RequestMapping:将请求交给方法去处理。
- ResponseBody:如果想要将字符串直接响应,不进行页面跳转,需要在方法上添加ResponseBody注解。
- RestController:RestController = Controller + ResponseBody。
- RequestParam:将浏览器上接收的参数和方法中定义的形式参数映射起来。
/**
* 回顾SpringMVC Controller
*/
//@Controller
@RestController
public class FirstController {
@RequestMapping("/first")
//@ResponseBody
public String first(@RequestParam("hahaa") String username,
@RequestParam("heihei") String password){
System.out.println(username + "---" + password);
return "success";
}
}
(4)模拟采集埋点数据,并进行处理
采集流程如下,在服务器执行jar包,启动本机执行程序,落盘到windows,最后由kafka消费数据。

a 在resources中添加logback.xml配置文件
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property name="LOG_HOME" value="e:/logs" />
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<appender name="rollingFile" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_HOME}/app.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_HOME}/app.%d{yyyy-MM-dd}.log</fileNamePattern>
</rollingPolicy>
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<!-- 将某一个包下日志单独打印日志 -->
<logger name="com.hzy.gmall.controller.LoggerController"
level="INFO" additivity="false">
<appender-ref ref="rollingFile" />
<appender-ref ref="console" />
</logger>
<root level="error" additivity="false">
<appender-ref ref="console" />
</root>
</configuration>
logback配置文件说明
-
appender:追加器,描述如何写入到文件中(写在哪,格式,文件的切分)。
- ConsoleAppender–追加到控制台。
- RollingFileAppender–滚动追加到文件。
-
logger:控制器,描述如何选择追加器。
注意:要是单独为某个类指定的时候,不要忘记修改类的全限定名。
-
日志级别从低到高:TRACE、[DEBUG、INFO、WARN、ERROR]、FATAL。
配置完成后,程序运行读取的是target文件下的classes,而不是resources下的logback.xml。
想要使用,需要在类上添加Slf4j注解。
b 修改SpringBoot核心配置文件application.propeties
#============== kafka ===================
# 指定kafka 代理地址,可以多个
spring.kafka.bootstrap-servers=hadoop101:9092,hadoop102:9092,hadoop103:9092
# 指定消息key和消息体的编解码方式
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
c 在LoggerController中添加方法,将日志打印、落盘并发送到Kafka主题中
@RestController
@Slf4j
public class LoggerController {
// 不使用Slf4j注解需要自己定义接收日志的对象
// private static final org.slf4j.Logger log = org.slf4j.LoggerFactory.getLogger(LoggerController.class);
@Autowired
private KafkaTemplate kafkaTemplate;
@RequestMapping("/applog")
public String log(@RequestParam("param") String logStr){
// 1 打印输出到控制台
// System.out.println(logStr);
// 2 落盘,使用logback完成
log.info(logStr);
// 3 发送到kafka主题
kafkaTemplate.send("ods_base_log",logStr);
return "success";
}
}
在kafka中的写法:
Properties props = new Properties();
props.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop101:9092");
props.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"");
props.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"");
KafkaProducer kafkaProducer = new KafkaProducer(props);
kafkaProducer.send(
/**
* 生产者的分区策略:
* 1 通过分区号指定固定分区
* 2 指定key,根据key获取哈希值,对分区数做模运算,决定将数据发送到那一个分区内
* 3 粘性分区,不停的向一个分区发送数据,满足以下条件之一,会改变分区
* 1)大于batchsize(默认16K)
* 2)大于一定时间
*/
new ProducerRecord("ods_base_log",logStr)
);
但是,SpringBoot是一个全家桶,对一些常见的组件,提供了一些类。
d kafka常用命令
在服务器上将kafka的默认分区数改为4。
vim /opt/module/kafka_2.11-2.4.1/config/server.properties
num.partitions=4
# 启动zookeeper
zk.sh start
# 启动kafka
kfk.sh start
# 查看所有主题
bin/kafka-topics.sh --bootstrap-server hadoop101:9092 --list
# 创建主题
bin/kafka-topics.sh --bootstrap-server hadoop101:9092 --create --topic first --partitions 4 --replication-factor 2
# 查看主题详情信息
bin/kafka-topics.sh --bootstrap-server hadoop101:9092 --describe --topic first
# 删除主题
bin/kafka-topics.sh --bootstrap-server hadoop101:9092 --delete --topic first
# 101生产消息
bin/kafka-console-producer.sh --broker-list hadoop101:9092 --topic frist
# 101消费消息
bin/kafka-console-consumer.sh --bootstrap-server hadoop101:9092 --topic first
e 修改hadoop101 上的rt_applog目录下的application.yml配置文件
修改地址和日期,地址为本机地址。
f 测试
启动kafka消费者进行测试。
bin/kafka-console-consumer.sh --bootstrap-server hadoop101:9092 --topic ods_base_log
运行Windows上的Idea程序LoggerApplication。
运行rt_applog下的jar包。


![[附源码]Python计算机毕业设计SSM基于人脸识别和测温的宿舍管理系统(程序+LW)](https://img-blog.csdnimg.cn/0cee7d35168d482e813b5e847af669ae.png)




![[oeasy]python0027_整合程序_延迟输出时间_整合两个py程序](https://img-blog.csdnimg.cn/img_convert/18454516a5d87a12b4e7156b7207a07c.png)