mybatisplus 集成druid连接池源码分析:从spring的源码过渡到druid的相关jar包,里面是druid相关的类,下面我们开始分析:
1、取数据库连接的地方入口:public abstract class DataSourceUtils
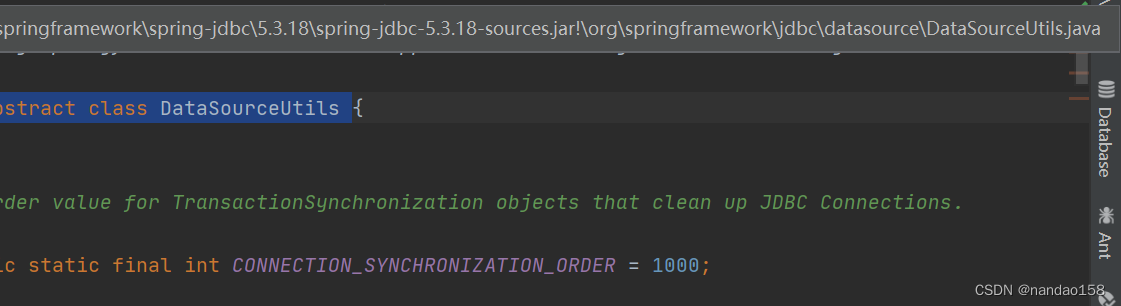
为spring-jdbc包里面的过渡工具类
private static Connection fetchConnection(DataSource dataSource) throws SQLException {
Connection con = dataSource.getConnection();//找实现类去,发现有很多的实现类
if (con == null) {
throw new IllegalStateException("DataSource returned null from getConnection(): " + dataSource);
}
return con;
}ctrl+t 看到:
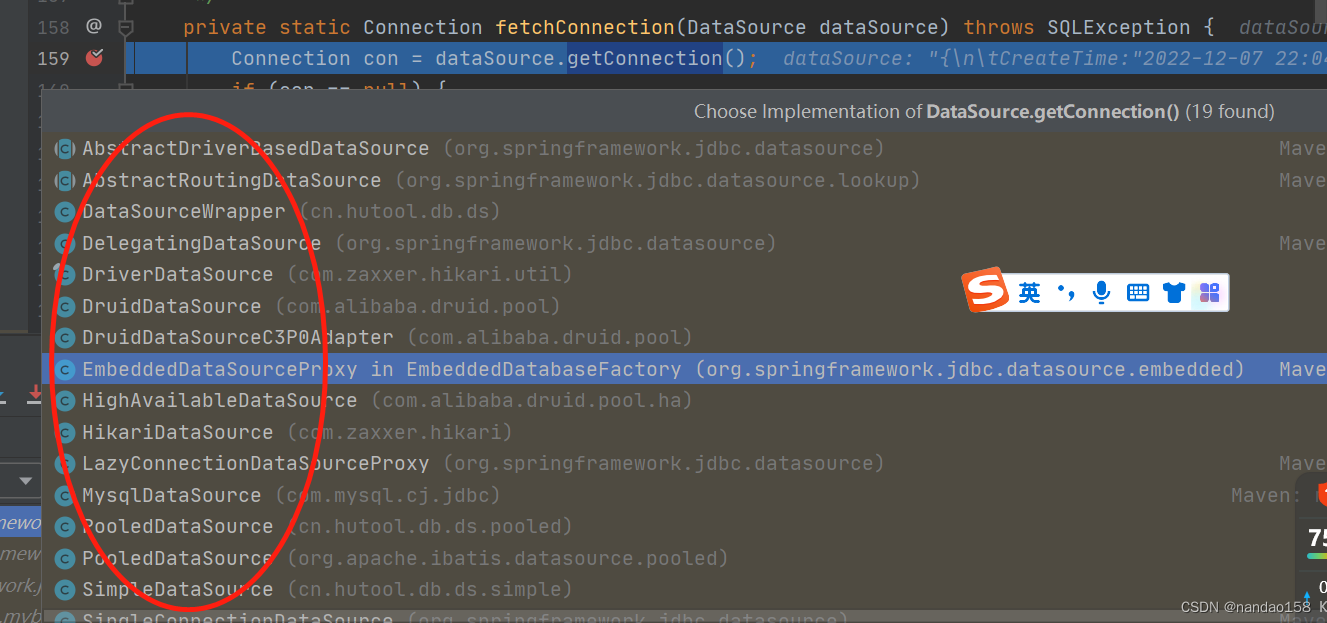
到底进入哪个实现类呢?这时候就要看你springboot 服务配置文件手动指定的哪个连接池类:
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource指定druid连接池,那么就会进入 DruidDataSource:
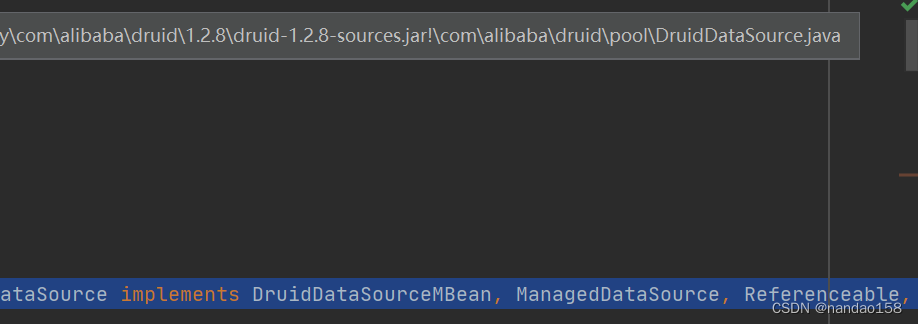
2、druid 连接池类:
public class DruidDataSource extends DruidAbstractDataSource implements DruidDataSourceMBean, ManagedDataSource, Referenceable, Closeable, Cloneable, ConnectionPoolDataSource, MBeanRegistration很丰满的一个类有多个基础和实现 :下面会详细讲解,多个 配置参数: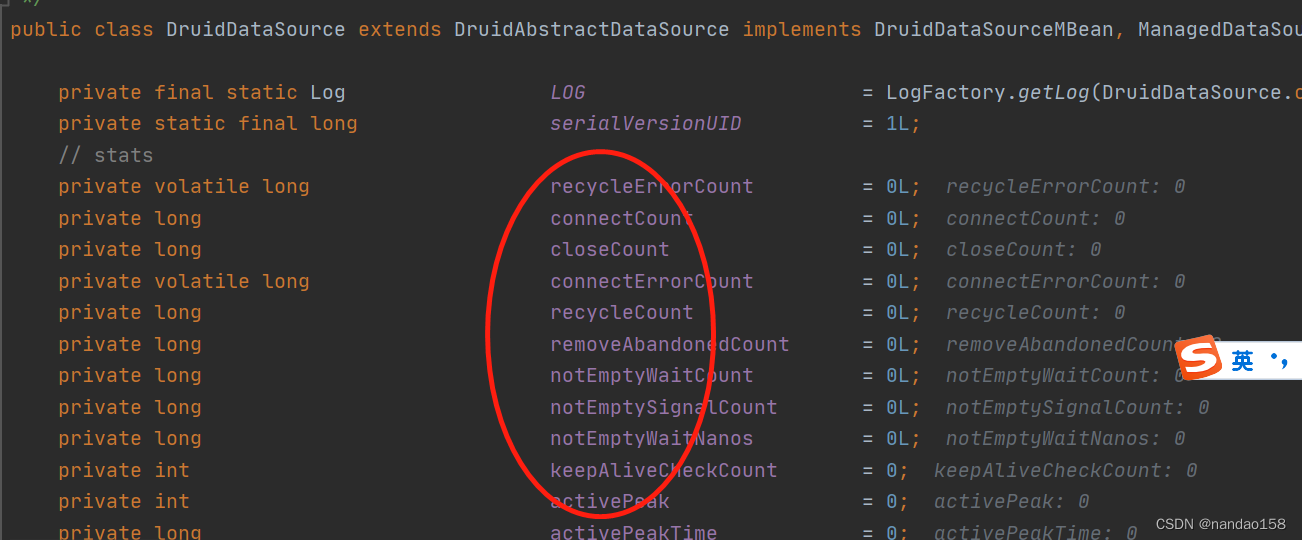
对应的配置文件里的配置:上面几个是数据库信息,多个是连接池信息
spring:
datasource:
name: user_db
url: jdbc:mysql://127.0.0.1:3306/user_db?useSSL=false
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: root
druid:
# 初始化大小
initial-size: 10
# 最小
min-idle: 10
#最大
max-active: 30
# 配置获取连接等待超时的时间
max-wait: 50000
# 配置一个连接在池中最小生存的时间,单位是毫秒
min-evictable-idle-time-millis: 600000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
time-between-eviction-runs-millis: 50000
# 校验SQL,Oracle配置 spring.datasource.validationQuery=SELECT 1 FROM DUAL,如果不配validationQuery项,则下面三项配置无用
validation-query: SELECT 'x'
test-on-borrow: false
test-on-return: false
test-while-idle: true
# 打开PSCache,并且指定每个连接上PSCache的大小
pool-prepared-statements: true
max-pool-prepared-statement-per-connection-size: 30
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
filters: stat,wall,log4j
# 通过connectProperties属性来打开mergeSql功能;慢SQL记录
connect-properties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=6000
# 合并多个DruidDataSource的监控数据
use-global-data-source-stat: true
web-stat-filter:
enabled: true
exclusions: /druid/*,*.js,*.gif,*.jpg,*.png,*.css,*.ico
url-pattern: /*
stat-view-servlet:
allow: ''
enabled: true
login-password: druid
login-username: druid
reset-enable: false
url-pattern: /druid/*接口进入
//DataSource 的实现类接口
@Override
public DruidPooledConnection getConnection() throws SQLException {
//配置获取连接等待超时的时间,上面会统一的配置样例
//max-wait: 50000
return getConnection(maxWait);//参数最大等待时间,配置文件一般会配置,核心点,进入
}点击进入:
public DruidPooledConnection getConnection(long maxWaitMillis) throws SQLException {
init();//初始化参数,里面有很多信息,可以认真看看
//filters 对应上面的配置
if (filters.size() > 0) {
FilterChainImpl filterChain = new FilterChainImpl(this);
return filterChain.dataSource_connect(this, maxWaitMillis);
} else {
return getConnectionDirect(maxWaitMillis);//核心进入
}
}来到一个很复杂的方法里面:
public DruidPooledConnection getConnectionDirect(long maxWaitMillis) throws SQLException {
int notFullTimeoutRetryCnt = 0;
for (;;) {
// handle notFullTimeoutRetry
DruidPooledConnection poolableConnection;
try {
poolableConnection = getConnectionInternal(maxWaitMillis);//核心点,进入
} catch (GetConnectionTimeoutException ex) {
if (notFullTimeoutRetryCnt <= this.notFullTimeoutRetryCount && !isFull()) {
notFullTimeoutRetryCnt++;
if (LOG.isWarnEnabled()) {
LOG.warn("get connection timeout retry : " + notFullTimeoutRetryCnt);
}
continue;
}
throw ex;
}
....省略部分源码
}进入复杂业务,暂时屏蔽,后面详细优化:此处主要是获取数据库连接信息
同时此处也可以自定义添加业务,中间可以通过类型,或者用户获取连接信息,比如在spring工具类和DruidDataSource 类直接添加一个过渡类,并且通过配置spring.datasource.type指定,专门处理用户和数据源的对应关系,缓存起来使用,每次用户来取连接时先去缓存取,缓存没有再通过接口取,缓存起来数据库对象信息,返回给用户,这样从最底层解决动态多数据源问题,并且业务代码没有任何耦合性,不会漏掉某个接口,唯一的担心是性能上需要注意,保证高性能。
后面我们分享多数据源时,会详细分享。





![[附源码]Python计算机毕业设计SSM基于人脸识别和测温的宿舍管理系统(程序+LW)](https://img-blog.csdnimg.cn/0cee7d35168d482e813b5e847af669ae.png)