本文总结大模型相关基础知识,用于大模型学习入门 (持续更新中…)
文章目录
- NLP 基础知识
- 传统 NLP 知识
- NLU 与 NLG 各种任务的差异
- Transformer 相关知识
- Pre Norm与Post Norm的区别?
- Bert 预训练过程
- 手写 transformer 的 attention layer 并计算模型参数量
- 深度学习基础
- BN 和 LN 的区别
- 大模型基础知识
- 训练框架
- 开源大语言模型介绍
- Llama
- ChatGLM and ChatGLM2
- Bloom
- Tokenizer
- tokenizer 计算方式,不同 tokenizer 的优缺点
- BPE 介绍
- position embedding
- 为什么要引入 position embedding
- RoPE
- Alibi
- PEFT
- Pattern-Exploiting Training(PET)
- P-tuning and P-tuningv2
- LoRA
- 大语言模型推理
- 温度系数(Temperature)对大模型推理结果的影响
- Huggingface generate 函数中的 top_p sampling、top_k sampling、greedy_search、beam_search 参数解释
- 大语言模型应用
- LangChain 介绍
- 可精读的博客/演讲
- 大语言模型前沿研究
- 大模型涌现分析
- 大语言模型知识蒸馏
NLP 基础知识
传统 NLP 知识
NLU 与 NLG 各种任务的差异
- NLU (Natural Language Understanding):自然语言理解
- NLG (Natural Language Generation):自然语言生成
- NLU 从语言中提取事实,而NLG则将NLU提取的见解用于创造自然语言
Transformer 相关知识
Pre Norm与Post Norm的区别?
参考:为什么Pre Norm的效果不如Post Norm?
- 定义:
- Pre Norm(Norm and add): x t + 1 = x t + F t ( N o r m ( x t ) ) x_{t+1} = x_{t} + F_{t}(Norm(x_{t})) xt+1=xt+Ft(Norm(xt))
- Post Norm(Add and Norm): x t + 1 = N o r m ( x t + F t ( x t ) x_{t+1} = Norm(x_{t} + F_{t}(x_{t}) xt+1=Norm(xt+Ft(xt)
- 在同一训练设置下,同一设置之下,Pre Norm结构往往更容易训练,但最终效果通常不如Post Norm:
- Pre Norm更容易训练好理解,因为它的恒等路径更突出
- Pre Norm的深度有“水分”!也就是说,一个L层的Pre Norm模型,其实际等效层数不如L层的Post Norm模型,而层数少了导致效果变差了。Post Norm每Norm一次就削弱一次恒等分支的权重,所以Post Norm反而是更突出残差分支的,因此Post Norm中的层数更加“足秤”,一旦训练好之后效果更优。
- Post Norm的结构迁移性能更加好,也就是说在Pretraining中,Pre Norm和Post Norm都能做到大致相同的结果,但是Post Norm的Finetune效果明显更好
Bert 预训练过程
- Bert的预训练主要包含两个任务,MLM和NSP,Masked Language Model任务可以理解为完形填空,随机mask每一个句子中15%的词,用其上下文来做预测;Next Sentence Prediction任务选择一些句子对A与B,其中50%的数据B是A的下一条句子,剩余50%的数据B是语料库中随机选择的,学习其中的相关性。BERT 预训练阶段实际上是将上述两个任务结合起来,同时进行,然后将所有的 Loss 相加
手写 transformer 的 attention layer 并计算模型参数量
深度学习基础
BN 和 LN 的区别
- BN 与 LN 定义:Batch Normalization 是对这批样本的同一维度特征做规范化处理, Layer Normalization 是对这单个样本的所有维度特征做规范化处理
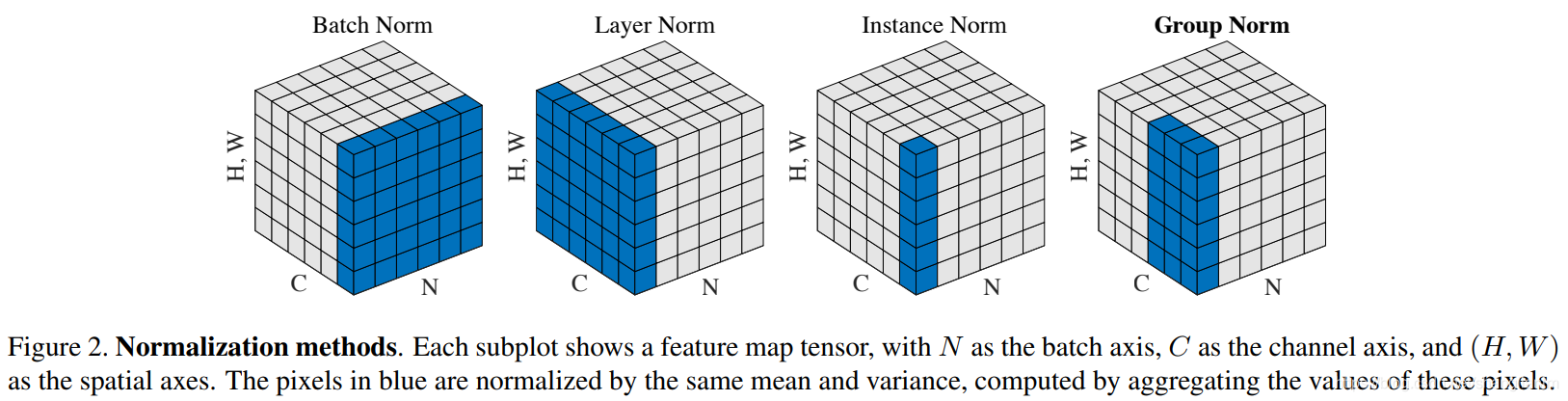
- 区别:
- LN中同层神经元输入拥有相同的均值和方差,不同的输入样本有不同的均值和方差;BN中则针对不同神经元输入计算均值和方差,同一个batch中的输入拥有相同的均值和方差
- 为什么 NLP 使用 LN 而不是 BN?
- LN 不依赖于 batch 的大小和输入 sequence 的长度,因此可以用于 batchsize 为 1 和 RNN 中 sequence 的 normalize 操作
- BN 不适用于 batch 中 sequence 长度不一样的情况,有的靠后面的特征的均值和方差不能估算;另外 BN 在 MLP 中的应用对每个特征在 batch 维度求均值方差,比如身高、体重等特征,但是在 NLP 中对应的是每一个单词,但是每个单词表达的特征是不一样的
- 如果特征依赖于不同样本间的统计参数(比如 CV 领域),那么 BN 更有效(它抹杀了不同特征之间的大小关系,但是保留了不同样本间的大小关系);NLP 领域 LN 更合适(抹杀了不同样本间的大小关系,但是保留了一个样本内不同特征之间的大小关系),因为对于 NLP 或序列任务来说,一条样本的不同特征其实就是时序上字符取值的变化,样本内的特征关系是非常紧密的
- 相同点:标准化技术目的是让每一层的分布稳定下来,让后面的层可以在前面层的基础上安心学习,加快模型收敛
- 区别:
大模型基础知识
训练框架
- megatron-lm、deepspeed 介绍
开源大语言模型介绍
Llama
- causal LM: 严格遵守只有后面的token才能看到前面的token的规则
- 使用 RoPE 位置编码
ChatGLM and ChatGLM2
- ChatGLM
- 使用 prefix LM:prefix部分的token互相能看到
- 使用 RoPE 位置编码
- ChatGLM2
- 回归 decoder-only 结构,使用 Causal LM
- 使用 RoPE 位置编码
Bloom
- BLOOM 使用 Alibi 位置编码
Tokenizer
tokenizer 计算方式,不同 tokenizer 的优缺点
BPE 介绍
position embedding
为什么要引入 position embedding
参考
-
对于任何一门语言,单词在句子中的位置以及排列顺序是非常重要的,它们不仅是一个句子的语法结构的组成部分,更是表达语义的重要概念。一个单词在句子的位置或排列顺序不同,可能整个句子的意思就发生了偏差。
I do not like the story of the movie, but I do like the cast.
I do like the story of the movie, but I do not like the cast.
上面两句话所使用的的单词完全一样,但是所表达的句意却截然相反。那么,引入词序信息有助于区别这两句话的意思。 -
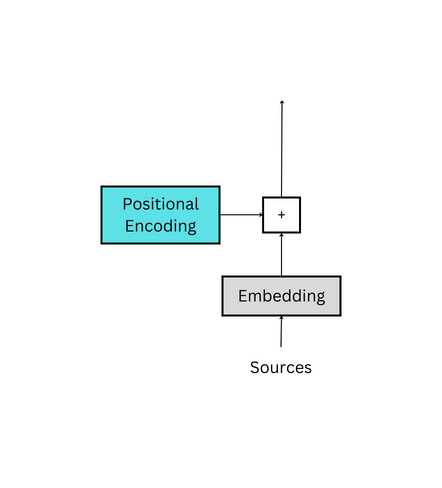
Transformer模型抛弃了RNN、CNN作为序列学习的基本模型。我们知道,循环神经网络本身就是一种顺序结构,天生就包含了词在序列中的位置信息。当抛弃循环神经网络结构,完全采用Attention取而代之,这些词序信息就会丢失,模型就没有办法知道每个词在句子中的相对和绝对的位置信息。因此,有必要把词序信号加到词向量上帮助模型学习这些信息,位置编码(Positional Encoding)就是用来解决这种问题的方法。
RoPE
参考1, 参考2,参考3
- RoPE
- 二维情况下用复数表示的RoPE
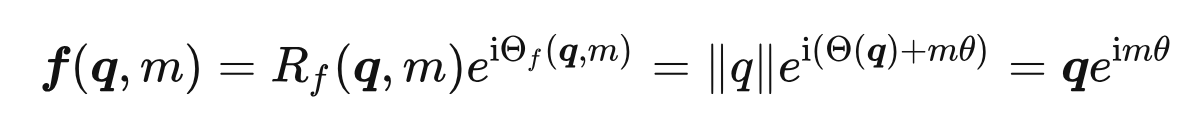
根据复数乘法的几何意义,该变换实际上对应着向量的旋转,所以我们称之为“旋转式位置编码” - RoPE通过绝对位置编码的方式实现相对位置编码,综合了绝对位置编码和相对位置编码的优点
- 绝对位置编码:最原始的正余弦位置编码(即sinusoidal位置编码)是一种绝对位置编码,但从其原理中的正余弦的和差化积公式来看,引入的其实也是相对位置编码。
- 优势: 实现简单,可预先计算好,不用参与训练,速度快
- 劣势: 没有外推性,即如果预训练最大长度为512的话,那么最多就只能处理长度为512的句子,再长就处理不了了。当然,也可以将超过512的位置向量随机初始化,然后继续微调
- 相对位置编码:经典相对位置编码RPR式
- 直接地体现了相对位置信号,效果更好。具有外推性,处理长文本能力更强
- 绝对位置编码:最原始的正余弦位置编码(即sinusoidal位置编码)是一种绝对位置编码,但从其原理中的正余弦的和差化积公式来看,引入的其实也是相对位置编码。
- 主要就是对attention中的q, k向量注入了绝对位置信息,然后用更新的q,k向量做attention中的内积就会引入相对位置信息了
- 二维情况下用复数表示的RoPE
Alibi
参考1, 参考2
- ALiBi (Attention with Linear Biases,22年ICLR),是一种 position embedding 方法,允许Transformer 语言模型在推理时处理比其训练时更长的序列。
- ALiBi在不使用实际位置嵌入的情况下实现这一目标。相反,ALiBi计算某个键和查询之间的注意力时,会根据键和查询的距离来对查询可以分配给键的注意力值进行惩罚。因此,当键和查询靠近时,惩罚非常低,而当它们相距较远时,惩罚非常高。这个方法的动机很简单,即靠近的单词比远离的单词更重要。
- ALiBi方法的速度与正弦函数嵌入或绝对嵌入方法相当(这是最快的定位方法之一)。在评估超出模型训练序列长度的序列时,ALiBi优于这些方法和Rotary嵌入(这称为外推)方法(ALiBi的方式,训练快了11%,并且会减少11%的内存消耗)。
- position embedding并没有加在work embedding上,而是加在了Q*K^T上面
PEFT
Pattern-Exploiting Training(PET)
参考
- 它通过人工构建的模版与 BERT 的 MLM 模型结合,能够起到非常好的零样本、小样本乃至半监督学习效果,而且该思路比较优雅漂亮,因为它将预训练任务和下游任务统一起来了
P-tuning and P-tuningv2
-
P-tuning(GPT Understands, Too)(参考)
- P-tuning 重新审视了关于模版的定义,放弃了“模版由自然语言构成”这一常规要求,从而将模版的构建转化为连续参数优化问题,虽然简单,但却有效
- P-tuning直接使用[unused*]的token来构建模版,不关心模版的自然语言性
- 借助 P-tuning,GPT 在 SuperGLUE 上的成绩首次超过了同等级别的 BERT 模型,这颠覆了一直以来“GPT 不擅长 NLU”的结论
-
P-tuningv2
LoRA
参考1,参考2
- 低秩自适应 (Low-Rank Adaptation, LoRA):冻结了预训练的模型权重,并将可训练的秩分解矩阵注入到 Transformer 架构的每一层,极大地减少了下游任务的可训练参数的数量,有效提升预训练模型在下游任务上的 finetune 效率
- 【背景】之前的 PEFT 方法是 adapter/prefix/promp/P-tuning,但是Adapter会引入很强的推理延迟(只能串行),prefix/prompt/P-tuning很难练,而且要占用context length,变相的降低模型能力
- 【详解】具体来说,就是考虑到语言模型(LLM 尤其如此)的参数的低秩属性(low intrinsic dimension),或者说过参数化,在做 finetune 的时候不做 full-finetune,而是用一个降维矩阵A和一个升维矩阵B去做finetune。如果我们认为原来的模型的某个参数矩阵为
W
0
W_{0}
W0,那么可以认为原来经过全微调的参数矩阵为
W
0
+
Δ
(
W
)
W_{0} + \Delta(W)
W0+Δ(W) ,但考虑到前面的低秩属性,在 lora 中我们可以简单认为
Δ
(
W
)
=
B
A
\Delta(W)=BA
Δ(W)=BA (B 是降维矩阵,A是升维矩阵,其中 A 正常随机数初始化,B 全 0 初始化,从而保证训练初期的稳定性),其中 BA 的秩相当于是你认为的模型实际的秩。这样的话在做推理的时候,
h
=
W
0
x
+
B
A
x
h=W_{0}x + BAx
h=W0x+BAx ,根本不会引入推理延迟,因为你只需要把训好的 lora 参数
A
B
AB
AB 加进模型初始权重
W
0
W_{0}
W0 中就可以了。在 Transformer 中 self-attention 和 mlp 模块都有对应的 params 矩阵,对应加上 lora 即可。
- llama 为了节省参数量一般只加在 q、v 上 (参考),原论文实验是不会掉点
- bloom 一般加在 q、k、v 上
大语言模型推理
温度系数(Temperature)对大模型推理结果的影响
参考:What is Temperature in NLP / LLMs?
Huggingface generate 函数中的 top_p sampling、top_k sampling、greedy_search、beam_search 参数解释
参考:Huggingface 的 generate 方法介绍:top_p sampling、top_k sampling、greedy_search、beam_search
- Greedy search 每次都选择概率最大的词作为单词序列中的下一个词
- beam search(束搜索):通过在每个时间步骤保留最有可能的 num_beams 个假设,最终选择具有最高概率的假设,从而降低错过隐藏的高概率词序列的风险
- top-k sampling:在Top-K采样中,选择最有可能的 K 个下一个词,并将概率质量重新分配给这 K 个下一个词
- Top-p (nucleus) sampling:与仅从最可能的 K 个单词中进行采样不同,Top-p 采样从概率累积超过概率 p 的可能性最小的单词集中进行选择
大语言模型应用
LangChain 介绍
参考:大语言模型集成工具 LangChain
- LangChain 通过可组合性使用大型语言模型构建应用程序
- 【背景】大型语言模型 (LLM) 正在成为一种变革性技术,使开发人员能够构建他们以前无法构建的应用程序,但是单独使用这些 LLM 往往不足以创建一个真正强大的应用程序,当可以将它们与其他计算或知识来源相结合时,就有真的价值了。LangChain 旨在协助开发这些类型的应用程序
- LangChain 主要功能:
- 实现统一接口,支持不同大语言模型的统一化调用
- 支持引入 google 搜索、python 解释器等外部工具
- 支持便捷 prompt 模板设置(并提供一些教科书 prompt 模板供参考)
- 支持智能体 (Agent) 等高阶应用
可精读的博客/演讲
- State of GPT (OpenAI Karpathy 介绍 ChatGPT 原理及现状)
- Andrej Karpathy 介绍如何训练 ChatGPT 以及如何将 ChatGPT 用于定制化应用程序
- A Stage Review of Instruction Tuning
- 符尧讲解 SFT 现状及可以关注的问题
大语言模型前沿研究
大模型涌现分析
- 大模型涌现能力探讨:大型语言模型的涌现能力是幻象吗?
- 探索大语言模型表现出涌现能力的原因,初步结论是涌现能力主要是由研究人员选择一个非线性或不连续的评价指标导致的,另外探索了如何诱导涌现能力的出现,本文在视觉任务上通过对评价指标的修改复现了涌现现象。
大语言模型知识蒸馏
- Fine-tune-CoT: 旨在利用非常大的语言模型 (LMs) 的CoT推理能力来教导小模型如何解决复杂任务,蒸馏出来的小模型在某些数据集上精度甚至能超过 teacher 大模型


![学习babylon.js --- [3] 开启https](https://img-blog.csdnimg.cn/de5381c579a1456f981f34e9b42c8a60.png)