ReplicationID : 主从节点实例的ID ,redis内部就是通过这个id去识别主从节点。
offset:数据同步偏移量,也就是从节点每次从主节点同步数据后记录的数值,用来标记已经同步到哪个地方了。一般offset是从小到大增长的,增长的大小就是获取数据的字节数。比如从A首次同步主B的数据,则一开始offset为-1,表示未同步数据。在一次同步完后,同数据未1000字节,则主节点和从节点都会记录当前偏移量,作用:实现部分数据同步,以后作为后续集群中选举过程中一个门槛。
Redis数据同步是一个异步的过程,所以不能保证数据强一致性。
在老版本中,主从复制在第一次或者断线重连后,只能进程全量数据同步SYNC,但是在新版本中,从节点断线重连后可以进行增量数据同步(这个指的是断线重连之后)。

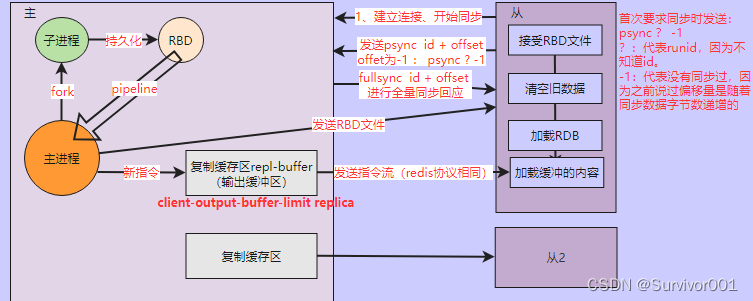
主从复制数据同步原理-全量复制
全量复制指主服务器将全量的RBD数据复制给从的过程。
什么情况下会进行全量复制?
1、从首次进行数据同步过程,在老版本中因为不支持部分复制,所以一旦从机启动就会进行全量同步。
2、在新版本中支持了部分同步,所以在从机断线从重启后会根据offset偏移量来判断是否全量同步。
全量复制原理以及怎么保证新增数据的一致性?
当从节点与主节点建立关系后,
1、从节点会发送psync要求数据复制同步,此时传输过去的offset为-1,代表全量复制。
2、主节点会接受同步请求,并同步给从ID和offset
3、主中主线程会fork一个子进程开始RDB操作,并通过管道技术,将RBD传输给主线程。
4、主线程将RBD文件传输给子进程。
5、在同步过程中,如果有新的数据产生,则主节点会将数据写入 复制缓冲区(输出缓冲区的一种),在完成RBD传输后,会将缓冲区中的数据同步给从,来保证数据一致性。
注意:复制缓冲区是针对客户端的缓冲区,也就是每有一个客户端连接就会有这样的一个缓冲区。用来接受客户端输出数据,如果超过缓冲区,就会断开客户端连接(后面详细说)通过 client-output-buffer-limit replica 256mb 64mb 60
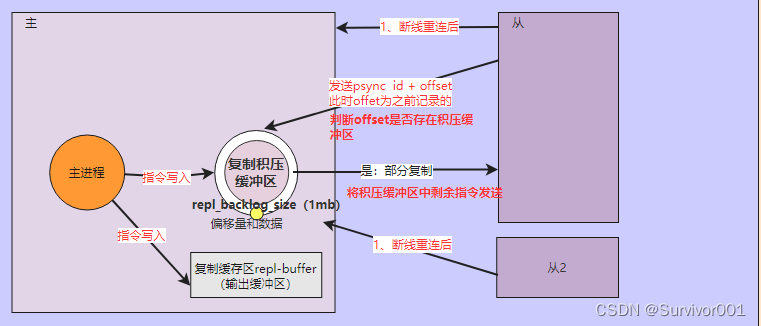
主从复制数据同步原理-增量复制(部分数据同步)
这里的增量复制指的是从节点发生断线重连后,进行的增量数据同步,在老版本因为不支持增量数据同步,所以从节点重连后,依然会进行全量数据的同步,如果RBD很大的情况下,需要更多的开销,比如fork开销更大。所以在后续版本中redis支持从节点断线重连后进行增量数据复制过程。
一般从节点断线场景:
1、比如主从同步超时:repl-timeout
2、输出缓冲区溢出 output-limit : 1、当存在非常大的key 。2、读取频率非常高时。
3、输入缓冲区溢出 : 1、当存在非常大的key 。2、写入频率非常高时。
增量复制原理
在开启主从复制后,在进行全量数据同步的过程中,同时也会将数据写入到复制积压缓冲区(主从都是会维护自身的一个offset的)
1、当从节点重连后,会发送psync并带上id和offset给主,此时offset就是上次断线前同步的偏移量。
2、主节点会通过这个偏移量判断是否在复制积压缓冲区中,
如果存在:则将缓冲区中剩余的内容同步给从,
如果没有:则表示当前偏移量已经很老了,则需要全量同步。
ps:复制积压缓冲区是一个环形缓冲区,大小为1mb,它是所有slave共享的缓冲区,所以如果一个从断线后,在此过程中发生了数据同步,则新的数据可能会覆盖环形缓冲区的数据,导致断线的slave偏移量在缓冲区没有,此时就需要全量复制。通过:repl-backlog-size配置缓冲区大小,默认是1m
原图下载:

![[Docker异常篇]解决Linux[文件异常]导致开机Docker服务无法启动](https://img-blog.csdnimg.cn/a764c87021b44f44a5c845ddee522d15.png)