多线程系列整体栏目
| 内容 | 链接地址 |
|---|---|
| 【一】深入理解进程、线程和CPU之间的关系 | https://blog.csdn.net/zhenghuishengq/article/details/131714191 |
| 【二】java创建线程的方式到底有几种?(详解) | https://blog.csdn.net/zhenghuishengq/article/details/127968166 |
| 【三】深入理解java中线程的生命周期,任务调度 | https://blog.csdn.net/zhenghuishengq/article/details/131755387 |
深入理解java中线程的生命周期,任务调度
- 一,深入理解java中线程的生命周期,任务调度
- 1,线程的生命周期
- 1.1,线程的生命状态
- 1.2,yield状态
- 2,线程的调度
- 2.1,协同式线程调度
- 2.2,抢占式线程调度
- 3,java中线程调度的实现方式
- 3.1,内核线程实现
- 3.2,用户线程的实现
- 3.3,混合线程的实现
- 3.4,java线程调度是抢占式原因
- 4,守护线程
- 5,协程
- 5.1,协程的概念
- 5.2,纤程的使用
一,深入理解java中线程的生命周期,任务调度
前一篇谈了线程的创建方式,接下来这篇深入的了解java中的线程
1,线程的生命周期
1.1,线程的生命状态
线程生命周期整体结构如下图所示,总共可以归纳为六种状态,分别是:初始状态,运行状态,等待状态,超时等待状态,阻塞状态和终止状态
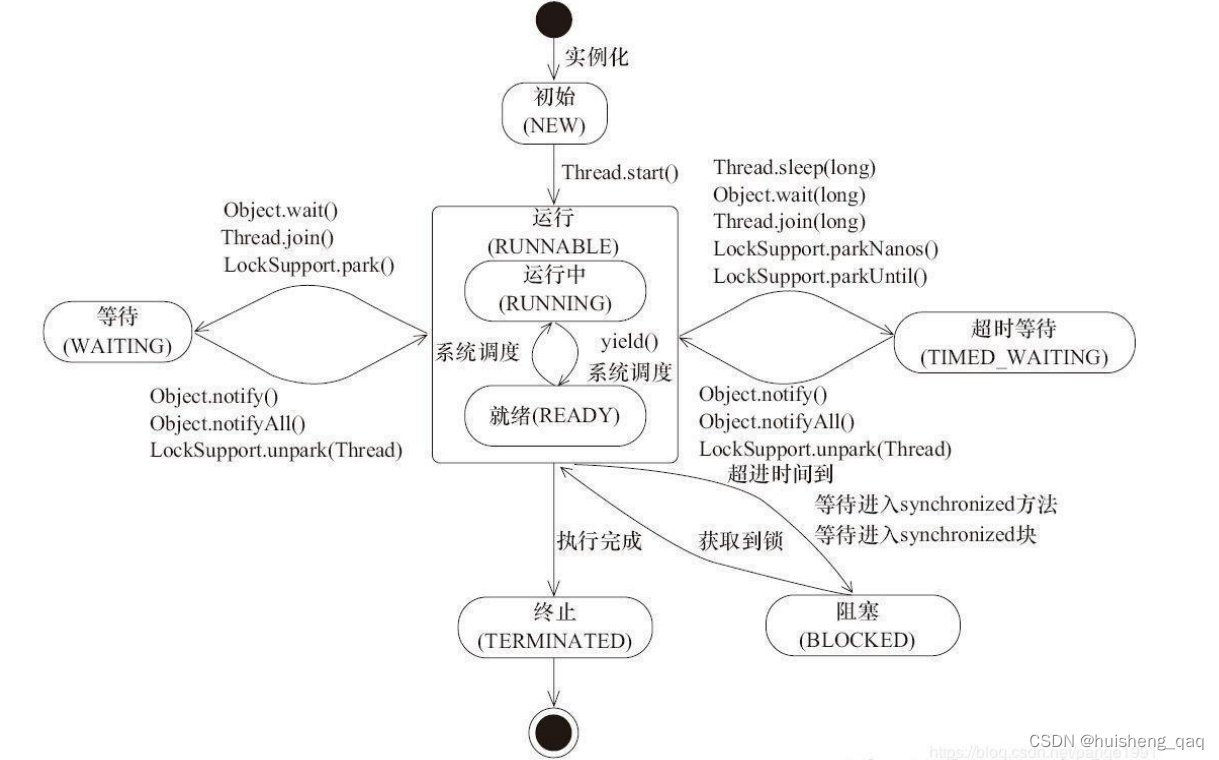
1,首先是初始状态,此时实例化了一个线程,就是在堆内存中创建一个Thread实例,此时还没有调用start方法
Thread thread = new Thread();
2,在调用start方法之后,该线程会进入运行状态,但是由于线程的执行需要通过cpu的调度,因此在cpu没有轮换到该线程执行的时候,会处于一个就绪状态,当cpu时间片轮询到该线程时,则是处于一个运行中的状态。
3,在运行中,可能会遇到等待状态,这些等待的线程没有时间限制,需要其他线程唤醒
Object.wait(); <==> Object.notify();
Thread.join();
LockSupport.park(); <==> LockSupport.unpark(Thread);
4,除了上面的这种等待状态,还有一种与之类似的超时等待 状态,这些等待的线程到达一定的时间自动被唤醒
Thread.sleep(long time);
Object.wait(long time); <==> Object.notify();
Thread.join(long time);
LockSupport.parkNanos(long time); <==> LockSupport.unpark(Thread);
LockSupport.parkUntil(long time);
超时等待和等待的区别在于:等待是由于某个条件不满足而一直等待,超时等待是即使条件不满足,但是到一定的时间之后,还是会从等待状态变为运行状态
5,同时也存在一种block阻塞状态,就是平常时开发中用到的一些隐私锁操作,比如Synchronized ,这样就可以保证只有一个线程可以继续执行,其他的只有等这个线程释放锁之后,才能抢锁,再继续往下执行。而像Lock这种显示锁,其内部的线程时处于等待状态,并且其底层是通过CLH同步等待队列完成的
public static Synchronized void test(); //其他线程处于阻塞状态
LockSupport.park(); //其他线程处于等待状态
6,在线程执行完之后,就会进入一个 TERMINATED终止状态
1.2,yield状态
除了以上六种主要的状态之外,还存在一个 yield 状态,该状态主要作用是礼让出cpu的执行权,让当前线程的状态从运行中的状态变为一个就绪状态。
在concurrentHashMap的initTable 方法中,就用到了这个线程礼让,这是因为 ConcurrentHashMap 中可能被多个线程同时初始化 table,但是其 实这个时候只允许一个线程进行初始化操作,其他的线程就需要被阻塞或等待, 但是初始化操作其实很快,为了避免阻塞或者等待这些操作 引发的上下文切换等等开销,就让其他不执行初始化操作的线程干脆执行 yield() 方法,以让出 CPU 执行权,让执行初始化操作的线程可以更快的执行完成
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
2,线程的调度
线程调度是指系统为线程分配 CPU 使用权的过程,线程中的调度主要有两种,一种是协同式线程调度,一种是抢占式线程调度。
2.1,协同式线程调度
协同式线程调度指的是当前线程主要起协助作用,就是自身的控制是否停止当前cpu的调度。比如说当前线程在执行完任务之后,主动地的释放cpu的使用权,进而让系统去执行其他的线程。这样的好处是实现比较简单,并且不会出现并发的问题,但是坏处也比较明显,就是由于是串行执行,所有当一个线程出现问题的时候,后面的线程全部会跟着阻塞,导致整个程序阻塞
2.2,抢占式线程调度
而使用抢占式线程调度的多线程系统,每个线程执行的时间都会由系统进行决定,并且其时间线程不可控,比如说一个cpu对应10个线程,每个线程执行10s,那么cpu就会通过不断地切换执行线程,这样子就解决了上面的因一个线程而导致整个进程阻塞的问题。
java中使用的线程调度方式就是抢占式线程调度。 下文中会通过线程的调度方式说明为啥是抢占式而不是协同式
3,java中线程调度的实现方式
任何语言实现线程调度的方式总共有三种,分别是内核线程实现,用户线程实现,混合实现
3.1,内核线程实现
在操作系统内部已经实现了线程的实体以及所有的方法,内核态就是操作系统的核心,类似于人的大脑,负责整个操作系统的任务调度。
使用内核态实现线程的方式,就是通过内核控制操作系统线程调度器,让用户的创建的线程和操作系统的线程实现1:1的关系,就如java中就是使用的内核线程的方式实现的,在用户态new Thread在调用start之后,就会在操作系统中开启一个与之对应的线程,由在操作系统中实现了这些系统的调度等,因此不需要再语言层面进行控制,只需要将用户的应用代码交给操作系统即可。
这种方式的优点很明显,只需要进线程之间的映射,其他的任务调度这些交给操作系统即可;缺点也很明显,比如说一些线程的创建,线程的同步等,这些操作都是在用户态写的代码,因此需要通过系统调度来完成,那么就会产生上下文的切换,需要来回的从用户态切换到内核态,代价相对而言是比较高的。
如在java中这些线程的方法,其最终调用的还是native本地方法,就是直接操作本地的内核态,在通过内核态分发指令给操作系统,通过操作系统来完成以下的命令。
public static native void yield();
public static native void sleep(long millis) throws InterruptedException;
public static native Thread currentThread();
private native boolean isInterrupted(boolean ClearInterrupted);
....
在java中每创建一个线程并且调用一个start方法,那么操作系统就得开启一个与之对于的线程,受硬件和操作系统之间的影响,线程的数量是有限的,因此在实际开发中,最好控制好线程的数量,如使用线程池来创建和管理线程。
3.2,用户线程的实现
由于通过内核方式实现这个线程的调度会产生大量的上下文切换,因此后面就有了用户线程的实现线程的调度,这样用户线程的建立、同步、销毁和调度完全在用户态中完成,不需要内核的帮助,非常快速且低消耗的方式来支持更大的线程数量。这种线程可以实现操作系统线程和用户线程1:N的关系
这中方式的优点很明显,就是不需要上下文的切换,并且也不需要内核的支援;但是缺点也很明显,在用户态中要实现所有的关于线程的创建、销毁、切换和调度等的问题,并且没有内核的支援,所有关于线程在操作系统的方法都要在用户态的语言库中要实现一遍,相对而言比较复杂。
在现在如日中天的go语言以及其他支持高并发的语言中,已经是通过用户态的方式实现了线程的调度了。
3.3,混合线程的实现
上面的两种实现是纯粹的通过用户态或者内核态来实现线程调度的,因此在这两种基础上引入了混合线程的实现,就是让用户线程和内核线程同时使用,比如说让N个用户态的线程对应M个操作系统的线程,这样就解决了即可以使用操作系统中对线程的调度的一些方法,实现用户线程和操作系统线程的映射,也可以通过用户线程之间的直接切换,从而减少上下文的切换,让用户态的线程和操作系统的线程对应的关系是K:1
这样的缺点也有,就是要实现用户线程的切换以及用户线程所对应的那一个操作系统的线程。
3.4,java线程调度是抢占式原因
由于java采用的系统调度方式是内核线程的方式,因此java的线程和操作系统的线程时1对1的关系,也就是说具体的执行在java语言层面并不能够控制,因为完全是交给了操作系统去执行,所以在java中并不能够过控制住线程的优先级,jvm虚拟机也干涉不了操作系统内部是如何进行系统调度的,所以java线程并不是协同调度,而是抢占式调度
4,守护线程
在执行一个main主线程的代码之后,然后将其存在的线程全部打印
/**
* @Author: zhenghuisheng
* @Date: 2023/7/11 13:50
* 单线程总统计
*/
public class ThreadCount {
public static void main(String[] args) {
// 获取线程管理bean
ThreadMXBean threadMXBean = ManagementFactory.getThreadMXBean();
// 获取线程和线程堆栈信息
ThreadInfo[] threadInfo = threadMXBean.dumpAllThreads(false, false);
for (int i = 0; i < threadInfo.length; i++) {
ThreadInfo ti = threadInfo[i];
//打印线程id
System.out.println("线程id为:" + ti.getThreadId() + "线程名称为:" + ti.getThreadName());
}
}
}
其结果如下,除了打印这个main主线程之外,还存在其他的五个协助的线程,这几个线程就被称为守护线程,主要是在后台做调度和支持型工作。如负责垃圾回收的线程,就被称为守护线程。
线程id为:6线程名称为:Monitor Ctrl-Break //监控中断信号的
线程id为:5线程名称为:Attach Listener //监听内存dump,类信息统计,获取系统属性等
线程id为:4线程名称为:Signal Dispatcher //分发处理发送给JVM信号的线程
线程id为:3线程名称为:Finalizer //调用finalize方法的线程
线程id为:2线程名称为:Reference Handler //清除Reference线程
线程id为:1线程名称为:main
在java语言中,除了上面的这些基本的守护线程之外,还可以通过这个设置daemon参数来讲普通线程修改成守护线程
//创建一个线程
Thread thread = new Thread();
//设置成守护线程
thread.setDaemon(true);
当时守护线程主要还是用来支持用户线程的,也就说一个线程开启的时候,同时也会开启多个守护线程,但是线程执行完毕之后,那么守护线程也会停止,所以在java中,并不推荐在自定义方法中调用这个finalize()方法,其一是会产生stw,其二就是这个finalize是守护线程的一个方法,如果此时刚好用户线程执行完毕,那么这个守护线程也会退出,就不会执行这个gc的调用了。
可以通过守护线程实现的应用主要有:内存清理、接收外部信号等。守护线程的主要作用是守护整个内存资源的回收和调度。
5,协程
5.1,协程的概念
虽然说如今java主流的线程调度方式还是内核调度,但是随着分布式以及微服务的兴起,通过内核线程调度会显得稍微吃力。比如说用户的一个请求,需要经过几个服务的链路,这样就可能出现响应时间慢,并发量大的问题,而如果这还使用内核调度的方式,即用户线程有多少个操作系统就得开启多少个线程,那么就需要在操作系统中创建大量的线程,而操作系统的线程数是有限的,那么能支持的并发数肯定是有限的,响应时间也会相对较慢。
而在go语言中,天然的高并发也是他的优势,相对于java,他的高并发的响应速率以及执行的线程数远远是操作java的,go内部采用的是用户态的方式实现线程的调度,因此java在受到多重因素的压力下,在 jdk19中也引入了这种虚拟线程,被称为"纤程",从而解决内核态带来的上下文切换导致的资源损耗问题,线程数量有限的问题以及响应速度慢的问题等。
纤程在java中,是一个轻量级的线程。如自定义创建一个线程,那么其线程需要的空间为1m,假设2000个线程,那么就需要2G的内存;但是在协程中,一个线程所占用的内存大小只需要几百个字节,所以一个纤程所占用的空间远远小于线程的空间。因此纤程可以处理的线程量就是原来的几千倍
纤程的缺点在于需要再用户态实现所有的线程调度算法,从而不依赖与操作系统。因此适合使用纤程的场景主要是:大并发,高io。高io指的是io密集型,就是大量的网络交互和磁盘交互,纤程只解决了规模数量的局限性,并没有解决速率慢的问题,因此并不适合cpu密集型。
因在jdk19中,引入了一个 Quasar 的纤程库,通过字节码注入的方式,在字节码 层面对当前被调用函数中的所有局部变量进行保存和恢复。这种不依赖 Java 虚 拟机的现场保护虽然能够工作,但也会影响性能。
5.2,纤程的使用
首先需要安装jdk19的版本,随后在pom文件中引入以下的依赖
<dependency>
<groupId>co.paralleluniverse</groupId>
<artifactId>quasar-core</artifactId >
<version>0.7.9 </version>
</dependency >
创建纤程的方式如下,Fiber类就是纤程相关的类,和java中普通线程的Thread一样
Fiber fiber = new Fiber(
@Override
public void run() throws Exception{
...
}
);
fiber.start();
在运行时,需要添加对应的vm虚拟机参数,从而实现java的代理地址
-javaagent:D:\Maven\repository\co\paralleluniverse\quasar-core\0.7.9\quasarcore-0.7.9.jar
随着纤程的完善,通过 Executors.newVirtualThreadPerTaskExecutor() 提供了虚拟线程池功能,他是基于用户线程模式实现的,JDK 的调度程序 不直接将虚拟线程分配给处理器,而是将虚拟线程分配给实际线程,是一个 M: N 调度,具体的调度程序由已有的 ForkJoinPool 提供支持。
而在目前的版本中,还处于测试版本,并不推荐在开发中使用,所以目前为止了解即可,以后流行了再深入。