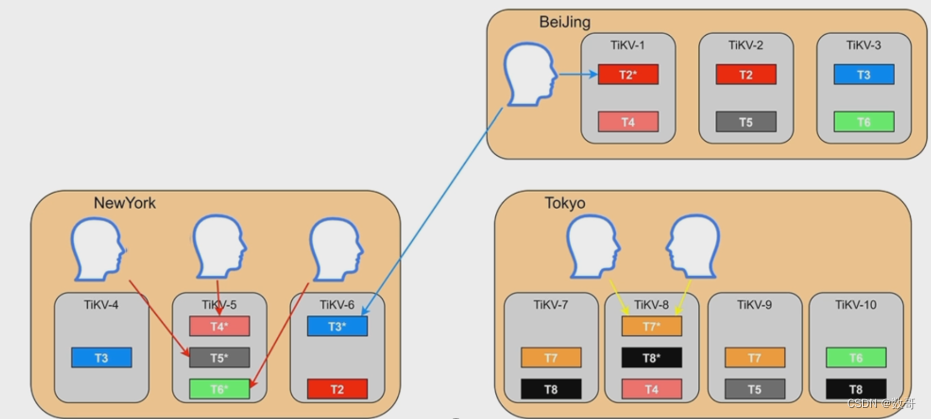
Placement Rules in SQL之前
- 跨地域部署的集群,无法本地访问
- 无法根据业务隔离资源
- 难以按照业务登记配置资源和副本数
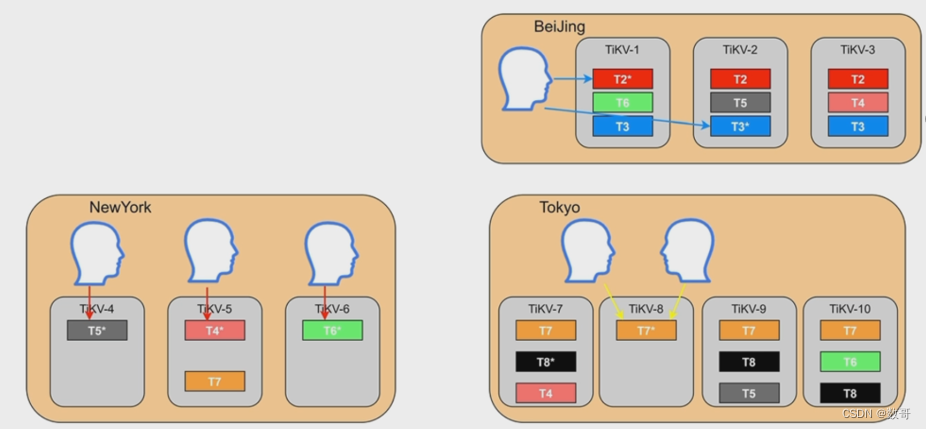
Placement Rules in SQL之后
- 跨地域部署的集群,支持本地访问
- 根据业务隔离资源
- 按照业务等级配置资源和副本数
配置 labels
设置 TiKV 的 labels 配置
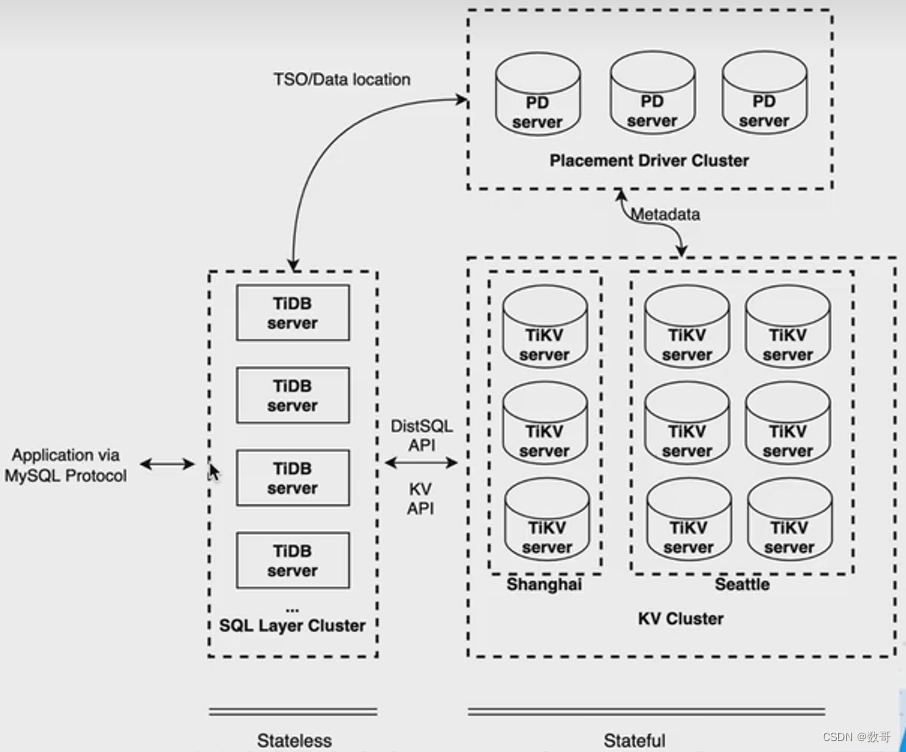
Region放置规则
- 用户可以将表指定部署到不同的地域、主机
- 支持应用跨地域部署
- 保证本地的数据副本可用于本地stale read读取
mysql> show placement labels;
+--------+----------------+
| Key | Values |
+--------+----------------+
| disk | ["hdd", "ssd"] |
| region | ["bj", "sz"] |
+--------+----------------+
2 rows in set (0.00 sec)
注意: 这个region的概念不是TiKV最小存储管理单元,而是自定义作为地域标签的意思。
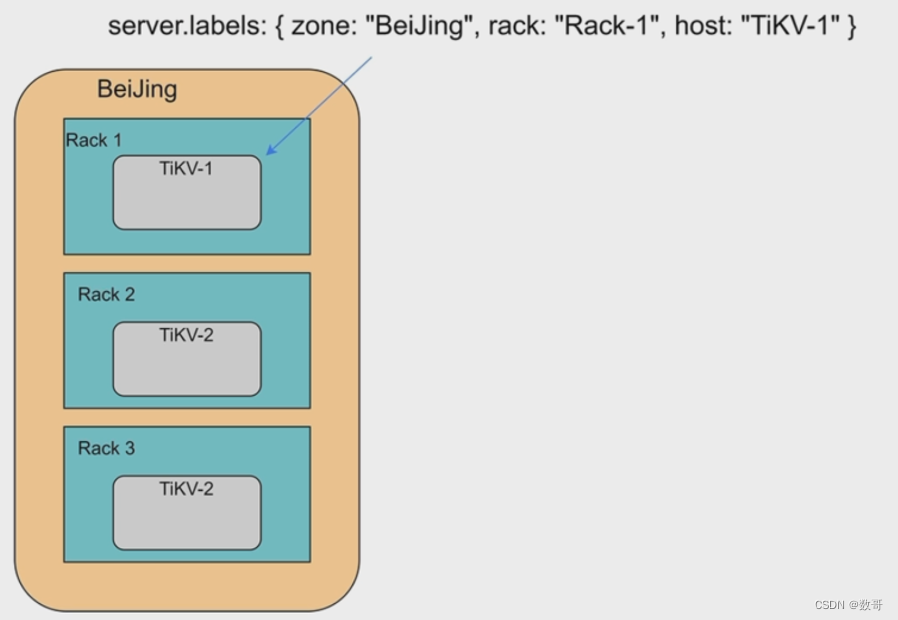
TiKV 支持在命令行参数或者配置文件中以键值对的形式绑定一些属性,我们把这些属性叫做标签(label)。TiKV 在启动后,会将自身的标签上报给 PD,因此我们可以使用标签来标识 TiKV 节点的地理位置。例如集群的拓扑结构分成三层:机房(zone) -> 机架(rack)-> 主机(host),就可以使用这 3 个标签来设置 TiKV 的位置。
使用命令行参数的方式:
tikv-server --labels zone=<zone>,rack=<rack>,host=<host>
使用配置文件的方式:
[server]
labels = "zone=<zone>,rack=<rack>,host=<host>"
设置 PD 的 location-labels 配置
根据前面的描述,标签可以是用来描述 TiKV 属性的任意键值对,但 PD 无从得知哪些标签是用来标识地理位置的,而且也无从得知这些标签的层次关系。因此,PD 也需要一些配置来使得 PD 理解 TiKV 节点拓扑。
PD 上的配置叫做 location-labels,在集群初始化之前,可以通过 PD 的配置文件进行配置。
[replication]
location-labels = ["zone", "rack", "host"]
如果需要在 PD 集群初始化完成后进行配置,则需要使用 pd-ctl 工具进行在线更改:
pd-ctl config set location-labels zone,rack,host
其中,location-labels 配置是一个字符串数组,每一项与 TiKV 的 labels 的 key 是对应的,且其中每个 key 的顺序代表了不同标签的层次关系。
注意
必须同时配置 PD 的 location-labels 和 TiKV 的 labels 参数,否则 PD 不会根据拓扑结构进行调度。
使用 TiUP 进行配置(推荐)
如果使用 TiUP 部署集群,可以在初始化配置文件中统一进行 location 相关配置。TiUP 会负责在部署时生成对应的 TiKV 和 PD 配置文件。
下面的例子定义了 zone/host 两层拓扑结构。集群的 TiKV 分布在三个 zone,每个 zone 内有两台主机,其中 z1 每台主机部署两个 TiKV 实例,z2 和 z3 每台主机部署 1 个实例。以下例子中 tikv-n 代表第 n 个 TiKV 节点的 IP 地址。
server_configs:
pd:
replication.location-labels: ["zone", "host"]
tikv_servers:
# z1
- host: tikv-1
config:
server.labels:
zone: z1
host: h1
- host: tikv-2
config:
server.labels:
zone: z1
host: h1
- host: tikv-3
config:
server.labels:
zone: z1
host: h2
- host: tikv-4
config:
server.labels:
zone: z1
host: h2
# z2
- host: tikv-5
config:
server.labels:
zone: z2
host: h1
- host: tikv-6
config:
server.labels:
zone: z2
host: h2
基于拓扑 label 的 PD 调度策略
PD 在副本调度时,会按照 label 层级,保证同一份数据的不同副本尽可能分散。
下面以上一节的拓扑结构为例分析。
假设集群副本数设置为 3(max-replicas=3),因为总共有 3 个 zone,PD 会保证每个 Region 的 3 个副本分别放置在 z1/z2/z3,这样当任何一个数据中心发生故障时,TiDB 集群依然是可用的。
假如集群副本数设置为 5(max-replicas=5),因为总共只有 3 个 zone,在这一层级 PD 无法保证各个副本的隔离,此时 PD 调度器会退而求其次,保证在 host 这一层的隔离。也就是说,会出现一个 Region 的多个副本分布在同一个 zone 的情况
示例一: 初始化集群时配置
1、编辑配置文件
[root@tidb2 ~]# more scale_out_all.yaml
# # Global variables are applied to all deployments and used as the default value of
# # the deployments if a specific deployment value is missing.
global:
user: "root"
ssh_port: 22
deploy_dir: "/tidb-deploy"
data_dir: "/tidb-data"
server_configs:
pd:
replication.location-labels: ["zone","dc","rack","host"] # pd需要跟tikv当中的配置对应上
pd_servers:
- host: 192.168.16.13
tidb_servers:
- host: 192.168.16.13
tikv_servers:
- host: 192.168.16.13
ssh_port: 22
port: 20160
status_port: 20180
deploy_dir: "/tidb-deploy/tikv-20160"
data_dir: "/tidb-data/tikv-20160"
config:
server.labels:
zone: bj # zone dc rack host 这些只是标签,可自定义
dc: bja
rack: rack1
host: host1
- host: 192.168.16.13
ssh_port: 22
port: 20161
status_port: 20181
deploy_dir: "/tidb-deploy/tikv-20161"
data_dir: "/tidb-data/tikv-20161"
config:
server.labels:
zone: sz # zone dc rack host 这些只是标签,可自定义
dc: sza
rack: rack1
host: host1
2、部署集群
tiup cluster deploy tidb-test v6.1.0 ./scale_out_all.yaml --skip-create-user
3、查看信息
mysql> select store_id,address,store_state_name,label from information_schema.tikv_store_status;
+----------+---------------------+------------------+---------------------------------------------------------------------------------------------------------------------------------------+
| store_id | address | store_state_name | label |
+----------+---------------------+------------------+---------------------------------------------------------------------------------------------------------------------------------------+
| 1 | 192.168.16.13:20161 | Up | [{"key": "zone", "value": "sz"}, {"key": "rack", "value": "rack1"}, {"key": "host", "value": "host1"}, {"key": "dc", "value": "sza"}] |
| 4 | 192.168.16.13:20160 | Up | [{"key": "zone", "value": "bj"}, {"key": "rack", "value": "rack1"}, {"key": "host", "value": "host1"}, {"key": "dc", "value": "bja"}] |
+----------+---------------------+------------------+---------------------------------------------------------------------------------------------------------------------------------------+
2 rows in set (0.01 sec)
mysql> show placement labels;
+------+----------------+
| Key | Values |
+------+----------------+
| dc | ["bja", "sza"] |
| host | ["host1"] |
| rack | ["rack1"] |
| zone | ["bj", "sz"] |
+------+----------------+
4 rows in set (0.00 sec)
示例一: 初始化后设置label
[root@tidb2 ~]# more scale_out_all2.yaml
# # Global variables are applied to all deployments and used as the default value of
# # the deployments if a specific deployment value is missing.
global:
user: "root"
ssh_port: 22
deploy_dir: "/tidb-deploy"
data_dir: "/tidb-data"
pd_servers:
- host: 192.168.16.13
tidb_servers:
- host: 192.168.16.13
tikv_servers:
- host: 192.168.16.13
1、pd添加locaton-labels信息
./pd-ctl -u http://192.168.16.13:2379 config set location-labels region,disk
Success!
2、创建具有不同label的tikv
[root@tidb2 ~]# more scale-out-tikv.yaml
tikv_servers:
- host: 192.168.16.13
ssh_port: 22
port: 20162
status_port: 20182
deploy_dir: "/tidb-deploy/tikv-20162"
data_dir: "/tidb-data/tikv-20162"
config:
server.labels:
region: bj
disk: hdd
- host: 192.168.16.13
ssh_port: 22
port: 20161
status_port: 20181
deploy_dir: "/tidb-deploy/tikv-20161"
data_dir: "/tidb-data/tikv-20161"
config:
server.labels:
region: sz
disk: ssd
[root@tidb2 ~]# tiup cluster scale-out tidb-test scale-out-tikv.yaml
- 添加具有lable的tikv server
集群中有⼀台被打上标签的tikv 创建集群的手,暂时只添加一个kv,并且打上标签
tiup playground v6.1.0 --tag classroom-geo --db 2 --pd 3 --kv 1 --tiflash 1 --kv.config ./label-geo-shanghai-ssd.toml --host 192.168.16.12
tiup playground scale-out --kv 1 --kv.config ./label-geo-seattle-hdd.toml
tiup playground scale-out --kv 1 --kv.config ./label-geo-seattle-ssd.toml
tiup playground scale-out --kv 1 --kv.config ./label-geo-shanghai-hdd.toml
tiup playground scale-out --kv 1 --kv.config ./label-geo-shanghai-ssd.toml
注意: 这个region 不是说tikv的存储单元,这个就是地区的意思,用于打标签,自定义的。
查看系统有哪些标签
mysql> show placement labels;
+--------+----------------+
| Key | Values |
+--------+----------------+
| disk | ["hdd", "ssd"] |
| region | ["bj", "sz"] |
+--------+----------------+
2 rows in set (0.04 sec)
mysql> select store_id,address,store_state_name,label from information_schema.tikv_store_status;
+----------+---------------------+------------------+---------------------------------------------------------------------+
| store_id | address | store_state_name | label |
+----------+---------------------+------------------+---------------------------------------------------------------------+
| 1 | 192.168.16.13:20160 | Up | null |
| 69 | 192.168.16.13:20161 | Up | [{"key": "region", "value": "sz"}, {"key": "disk", "value": "ssd"}] |
| 68 | 192.168.16.13:20162 | Up | [{"key": "region", "value": "bj"}, {"key": "disk", "value": "hdd"}] |
+----------+---------------------+------------------+---------------------------------------------------------------------+
3 rows in set (0.01 sec)
类似给Region打标签,例如我是西雅图的,优先访问Seattle, 上海的优先访问shanghai.但也有一个问题 Leader(shanghai)和flower(Seattle)同步的问题,那可能对实时性没这么强的表可以这样处理。
placement policy
创建placement policy
前提: 启动节点的时候,配置了lable。
创建放置规则
CREATE PLACEMENT POLICY IF NOT EXISTS east PRIMARY_REGION="sz" REGIONS="sz,bj" FOLLOWERS=2;
# PRIMARY_REGION : leader 角色
#FOLLOWERS :副本数量
#REGIONS : follower 角色region位置
mysql> CREATE PLACEMENT POLICY IF NOT EXISTS west PRIMARY_REGION="bj" REGIONS="bj,sz" FOLLOWERS=2;
Query OK, 0 rows affected (0.20 sec)
这个里面的region有是指打了sz bj标签的 TiDB当中的存储单元。
- placement_policies表
mysql> select * from information_schema.placement_policies \G;
*************************** 1. row ***************************
POLICY_ID: 1
CATALOG_NAME: def
POLICY_NAME: east
PRIMARY_REGION: sz
REGIONS: sz,bj
CONSTRAINTS:
LEADER_CONSTRAINTS:
FOLLOWER_CONSTRAINTS:
LEARNER_CONSTRAINTS:
SCHEDULE:
FOLLOWERS: 2
LEARNERS: 0
*************************** 2. row ***************************
POLICY_ID: 2
CATALOG_NAME: def
POLICY_NAME: west
PRIMARY_REGION: bj
REGIONS: bj,sz
CONSTRAINTS:
LEADER_CONSTRAINTS:
FOLLOWER_CONSTRAINTS:
LEARNER_CONSTRAINTS:
SCHEDULE:
FOLLOWERS: 2
LEARNERS: 0
2 rows in set (0.03 sec)
ERROR:
No query specified
创建表
设定数据对象的placement policy
# 建表的时候指定存放规则
DROP TABLE IF EXISTS test.t_east;
CREATE TABLE test.t_east(
id bigint primary key auto_random,
name varchar(30),
t_mark timestamp default now()
) PLACEMENT POLICY = east;
DROP TABLE IF EXISTS test.t_west;
CREATE TABLE test.t_west(
id bigint primary key auto_random,
name varchar(30),
t_mark timestamp default now()
) PLACEMENT POLICY = west;
插⼊数据
insert into test.t_east (name) values (0),(1),(2),(3),(4),(5),(6),(7),(8),(9);
insert into test.t_west (name) values (0),(1),(2),(3),(4),(5),(6),(7),(8),(9);
SELECT SLEEP(1);
insert into test.t_east (name) select name from test.t_east;
insert into test.t_west (name) select name from test.t_west;
SELECT SLEEP(1);
insert into test.t_east (name) select name from test.t_east;
insert into test.t_west (name) select name from test.t_west;
SELECT SLEEP(1);
insert into test.t_east (name) select name from test.t_east;
insert into test.t_west (name) select name from test.t_west;
SELECT SLEEP(1);
insert into test.t_east (name) select name from test.t_east;
insert into test.t_west (name) select name from test.t_west;
SELECT SLEEP(1);
insert into test.t_east (name) select name from test.t_east;
insert into test.t_west (name) select name from test.t_west;
SELECT SLEEP(1);
insert into test.t_east (name) select name from test.t_east;
insert into test.t_west (name) select name from test.t_west;
SELECT SLEEP(1);
insert into test.t_east (name) select name from test.t_east;
insert into test.t_west (name) select name from test.t_west;
SELECT SLEEP(1);
insert into test.t_east (name) select name from test.t_east;
insert into test.t_west (name) select name from test.t_west;
SELECT SLEEP(1);
insert into test.t_east (name) select name from test.t_east;
insert into test.t_west (name) select name from test.t_west;
SELECT SLEEP(1);
insert into test.t_east (name) select name from test.t_east;
insert into test.t_west (name) select name from test.t_west;
SELECT SLEEP(1);
insert into test.t_east (name) select name from test.t_east;
insert into test.t_west (name) select name from test.t_west;
SELECT SLEEP(1);
insert into test.t_east (name) select name from test.t_east;
insert into test.t_west (name) select name from test.t_west;
SELECT SLEEP(1);
insert into test.t_east (name) select name from test.t_east;
insert into test.t_west (name) select name from test.t_west;
analyze table test.t_east;
analyze table test.t_west;
查看放置规则
/* Show status */
select kvrs.region_id, kvss.store_id, kvrp.is_leader, kvss.label,
kvss.start_ts
from information_schema.tikv_region_status kvrs
join information_schema.tikv_region_peers kvrp
on kvrs.region_id = kvrp.region_id
join information_schema.tikv_store_status kvss
on kvrp.store_id = kvss.store_id
join information_schema.tables t
on t.table_name = kvrs.table_name
where t.table_schema='test'
and t.table_name='t_east';
+-----------+----------+-----------+---------------------------------------------------------------------+---------------------+
| region_id | store_id | is_leader | label | start_ts |
+-----------+----------+-----------+---------------------------------------------------------------------+---------------------+
| 38013 | 69 | 1 | [{"key": "region", "value": "sz"}, {"key": "disk", "value": "ssd"}] | 2023-07-05 05:58:23 |
| 38013 | 68 | 0 | [{"key": "region", "value": "bj"}, {"key": "disk", "value": "hdd"}] | 2023-07-05 05:58:22 |
| 38013 | 1 | 0 | null | 2023-07-05 05:58:22 |
+-----------+----------+-----------+---------------------------------------------------------------------+---------------------+
3 rows in set (0.05 sec)
select kvrs.region_id, kvss.store_id, kvrp.is_leader, kvss.label,
kvss.start_ts
from information_schema.tikv_region_status kvrs
join information_schema.tikv_region_peers kvrp
on kvrs.region_id = kvrp.region_id
join information_schema.tikv_store_status kvss
on kvrp.store_id = kvss.store_id
join information_schema.tables t
on t.table_name = kvrs.table_name
where t.table_schema='test'
and t.table_name='t_west';
+-----------+----------+-----------+---------------------------------------------------------------------+---------------------+
| region_id | store_id | is_leader | label | start_ts |
+-----------+----------+-----------+---------------------------------------------------------------------+---------------------+
| 38021 | 69 | 0 | [{"key": "region", "value": "sz"}, {"key": "disk", "value": "ssd"}] | 2023-07-05 05:58:23 |
| 38021 | 68 | 1 | [{"key": "region", "value": "bj"}, {"key": "disk", "value": "hdd"}] | 2023-07-05 05:58:22 |
| 38021 | 1 | 0 | null | 2023-07-05 05:58:22 |
+-----------+----------+-----------+---------------------------------------------------------------------+---------------------+
3 rows in set (0.02 sec)
放置规则约束
除了region以外,placement policy 可以利用其它label设置数据保存位置的限制
数据冷热分离是典型应用场景,例如:
create placement policy ssd constraints = "[+disk=ssd]"
create placement policy hdd constraints = "[+disk=hdd]";
/* Advanced Placement Rules */
DROP PLACEMENT POLICY IF EXISTS ssd;
CREATE PLACEMENT POLICY ssd
CONSTRAINTS="[+disk=ssd]";
DROP PLACEMENT POLICY IF EXISTS hdd;
CREATE PLACEMENT POLICY hdd
CONSTRAINTS="[+disk=hdd]";
/* Range Partition rpt1 */
DROP TABLE IF EXISTS test.rpt1;
CREATE TABLE test.rpt1 (name int) PARTITION BY RANGE (name) (
PARTITION p0 VALUES LESS THAN (5) PLACEMENT POLICY = ssd,
PARTITION p1 VALUES LESS THAN (10) PLACEMENT POLICY = hdd);
/* Data load */
insert into test.rpt1 (name) values (0),(1),(2),(3),(4),(5),(6),
(7),(8),(9);
insert into test.rpt1 (name) select name from test.rpt1;
insert into test.rpt1 (name) select name from test.rpt1;
insert into test.rpt1 (name) select name from test.rpt1;
insert into test.rpt1 (name) select name from test.rpt1;
insert into test.rpt1 (name) select name from test.rpt1;
insert into test.rpt1 (name) select name from test.rpt1;
insert into test.rpt1 (name) select name from test.rpt1;
insert into test.rpt1 (name) select name from test.rpt1;
insert into test.rpt1 (name) select name from test.rpt1;
insert into test.rpt1 (name) select name from test.rpt1;
insert into test.rpt1 (name) select name from test.rpt1;
insert into test.rpt1 (name) select name from test.rpt1;
analyze table test.rpt1;
mysql> SELECT store_id, address, store_state_name, label
-> FROM information_schema.tikv_store_status;
+----------+---------------------+------------------+---------------------------------------------------------------------+
| store_id | address | store_state_name | label |
+----------+---------------------+------------------+---------------------------------------------------------------------+
| 1 | 192.168.16.13:20160 | Up | null |
| 68 | 192.168.16.13:20162 | Up | [{"key": "region", "value": "bj"}, {"key": "disk", "value": "hdd"}] |
| 69 | 192.168.16.13:20161 | Up | [{"key": "region", "value": "sz"}, {"key": "disk", "value": "ssd"}] |
+----------+---------------------+------------------+---------------------------------------------------------------------+
3 rows in set (0.00 sec)
/* Show status */
/* Can you explain the result? */
select kvrs.region_id, kvss.store_id, kvrp.is_leader,
kvss.label, kvss.start_ts
from information_schema.tikv_region_status kvrs
join information_schema.tikv_region_peers kvrp
on kvrs.region_id = kvrp.region_id
join information_schema.tikv_store_status kvss
on kvrp.store_id = kvss.store_id
join information_schema.tables t
on t.table_name = kvrs.table_name
where t.table_schema='test'
and t.table_name='rpt1';
+-----------+----------+-----------+---------------------------------------------------------------------+---------------------+
| region_id | store_id | is_leader | label | start_ts |
+-----------+----------+-----------+---------------------------------------------------------------------+---------------------+
| 38029 | 69 | 1 | [{"key": "region", "value": "sz"}, {"key": "disk", "value": "ssd"}] | 2023-07-05 05:58:23 |
| 38029 | 68 | 0 | [{"key": "region", "value": "bj"}, {"key": "disk", "value": "hdd"}] | 2023-07-05 05:58:22 |
| 38029 | 1 | 0 | null | 2023-07-05 05:58:22 |
| 38033 | 69 | 0 | [{"key": "region", "value": "sz"}, {"key": "disk", "value": "ssd"}] | 2023-07-05 05:58:23 |
| 38033 | 68 | 1 | [{"key": "region", "value": "bj"}, {"key": "disk", "value": "hdd"}] | 2023-07-05 05:58:22 |
| 38033 | 1 | 0 | null | 2023-07-05 05:58:22 |
+-----------+----------+-----------+---------------------------------------------------------------------+---------------------+
6 rows in set (0.04 sec)
/* Check the polices */
mysql> SELECT * FROM information_schema.placement_policies\G;
*************************** 1. row ***************************
POLICY_ID: 6
CATALOG_NAME: def
POLICY_NAME: hdd
PRIMARY_REGION:
REGIONS:
CONSTRAINTS: [+disk=hdd]
LEADER_CONSTRAINTS:
FOLLOWER_CONSTRAINTS:
LEARNER_CONSTRAINTS:
SCHEDULE:
FOLLOWERS: 2
LEARNERS: 0
*************************** 2. row ***************************
POLICY_ID: 5
CATALOG_NAME: def
POLICY_NAME: ssd
PRIMARY_REGION:
REGIONS:
CONSTRAINTS: [+disk=ssd]
LEADER_CONSTRAINTS:
FOLLOWER_CONSTRAINTS:
LEARNER_CONSTRAINTS:
SCHEDULE:
FOLLOWERS: 2
LEARNERS: 0
*************************** 3. row ***************************
POLICY_ID: 3
CATALOG_NAME: def
POLICY_NAME: east
PRIMARY_REGION: sz
REGIONS: sz,bj
CONSTRAINTS:
LEADER_CONSTRAINTS:
FOLLOWER_CONSTRAINTS:
LEARNER_CONSTRAINTS:
SCHEDULE:
FOLLOWERS: 2
LEARNERS: 0
*************************** 4. row ***************************
POLICY_ID: 4
CATALOG_NAME: def
POLICY_NAME: west
PRIMARY_REGION: bj
REGIONS: bj,sz
CONSTRAINTS:
LEADER_CONSTRAINTS:
FOLLOWER_CONSTRAINTS:
LEARNER_CONSTRAINTS:
SCHEDULE:
FOLLOWERS: 2
LEARNERS: 0
4 rows in set (0.00 sec)
ERROR:
No query specified