目录
- 一.摘要
- 1.背景
- 解决方法
- 1.如何有效整合来自多模态医学图像的信息
- 2.如何处理常见模式缺失的情况
- 2.解决
- 1.ML
- 2.MA
- 3.结论
- 二.方法
- 2.1模态特定模型Modality-specific Model
- 2.2 Modality-Aware Module
- 2.3互学策略Mutual Learning Strategy
- 三.实验与结果
- 3.1数据集和评估指标
- 3.2运行细节
- 3.3多模态建模的有效性
- 3.4可解释融合Interpretable Fusion
- 3.5处理缺失的形式
一.摘要
1.背景
-
肝癌是最常见的癌症之一(Global cancer statistics 2018: Globocan estimates of incidence and mortality worldwide for 36 cancers in 185 countries2018)。CT图像是肝癌最初评估最常用的成像方式,从CT图像中测量肿瘤的体积、形状和位置等,可以帮助医生做出癌细胞的评估和手术计划。但是由于肿瘤的部分纹理可能在CT上不明显,影响了医生判断。
-
在多模态分割中应用神经网络存在两个主要问题,一是如何有效整合来自多模态医学图像的信息,二是如何处理常见模式缺失的情况。
解决方法
1.如何有效整合来自多模态医学图像的信息
大部分单模态(single-modal)方法扩展到多流(multi-stream)模型:每个流针对一个特定的模态,由不同的流提取的模态特定特征(modality-specific features)会在后续的模态中融合。
基于解码器-编码器结构,多模态特征(multi-modal feature)融合的策略可以分为4种:
- 1)早期融合( early-fusion)策略,在输入处集成多模态图像,并沿单一网络流(single stream of network)进行联合处理。
- 2)中间融合(middle-fusion)策略,不是在网络的输入端合并两个阶段both phases,而是在相应的编码器中独立处理不同的模态,这些模态共享相同的解码器进行特征融合和最终分割。
- 3)后期融合(late-fusion)方式使每个阶段经过编码器-解码器网络的独立流,并在每个流的末尾融合学习到的特征。
- 4)最后一种是引入编码器-解码器网络之间和内部的超连接,使不同模式之间的信息交换更加有效。
缺点:每个模态的特征被直接组合起来,忽略了不同模态的不同贡献。
2.如何处理常见模式缺失的情况
处理缺失模态的策略包括:通过生成模型合成缺失模态、学习模态不变特征空间。
缺点:合成缺失模态需要大量的计算,现有的模态不变方法通常在大多数模态缺失时失败
2.解决
本文中,我们致力于通过集成多模态CT来改进肝脏肿瘤的自动分割。
1.ML
我们提出了一种新的互学习(mutual learningML)策略,用于有效和鲁棒的多模态肿瘤分割。与现有的多模态方法(通过单一模型融合来自不同模态信息)不同,在ML中,一个特定模态的模型集合,协作学习并教彼此提取不同模态的高级表示之间的特征和共性。
优点:
所提出的ML不仅具有多模态学习的优势,而且可以通过将知识从已有的模式转移到缺失的模式来处理缺失的模式。提高了泛化能力,避免了多余的教师模型的使用。
训练模型:
在ML中,通过模态内(intra-modal)和联合损失(joint loss)来训练模型:前者鼓励每个模型学习辨别模态特定的特征(discriminative modality-specific features),而后者鼓励每个模型相互学习,保持高级特征之间的共性,以便更好地整合多模态信息
2.MA
此外,我们提出了模态感知MA模块,在该模块中,模态特定模型通过注意权重相互连接和校准,以实现自适应信息交换。对于每个模型,MA模块生成权重映射,逐像素的对特征进行评估,然后通过加权聚合对特征进行合并,实现有效的多模态分割。
3.结论
在一个具有654个CT volumes的大规模临床数据集评估所提出的方法,在每例肝肿瘤分割的Dice方面达到81.25%。在临床数据集和公共BRATS 2018数据集上,我们展示了MAML在只有一种模式可用的极端情况下处理缺失模式的有效性和鲁棒性。
二.方法
MAML采用了一组模态特定模型来协作和自适应地合并动脉和静脉相位图像,以实现精确的肝肿瘤分割。在这种情况下,它包括两个模态特定模型来学习每个模态中的特定特征和一个MA模块来自适应地探索两种模态之间的相关特征。
请注意,所提出的方法可以很容易地扩展到更多的模式。
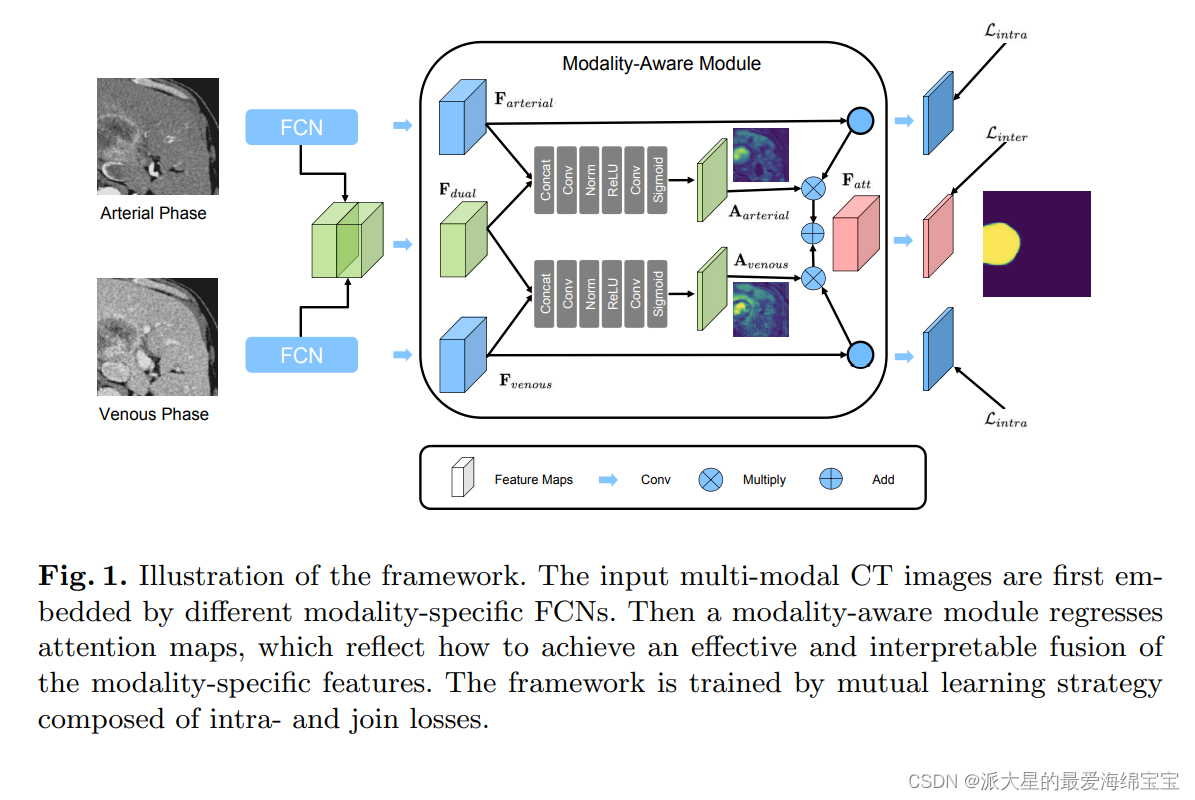
2.1模态特定模型Modality-specific Model
模态特定模型是用于单模态分割的常见FCN。
MAML采用了功能强大的nnUNet模型,用于实现原始CT图像的特征提取。
dual-phase CT volumes的输入分别经过每个模型,得到最后一层特定阶段的高级语义嵌入。高级语义嵌入共享输入图像的相同尺寸。不同模态特定模型的输出记为Fi∈RC×D×H×W,其中C = 32为通道数,D、H、W分别为深度、高度和宽度,i∈{AP, VP}。AP和VP分别是动脉期和静脉期的缩写。
2.2 Modality-Aware Module
如图1所示,我们提出了一个通过注意机制的MA模块,自适应地度量每个阶段的贡献。我们探索跨模态注意机制,有选择地突出嵌入在单一模态中的目标特征,以获得更具有辨别性的双模态特征,用于肝脏肿瘤分割。
模态特定模型的输出沿着通道连接在一起,通过随后的卷积层生成Fdual。Fdual虽然同时编码了肝肿瘤的动脉和静脉信息,但也不可避免地在肝肿瘤分割中引入了各种模态的冗余噪声。我们没有从Fdual中获得直接的分割,而是通过注意机制提出了MA来自适应地测量每个阶段的贡献,并直观地解释它。
MA模块利用Fdual和Fi作为输入,产生Fatt。具体来说,我们首先为每个Fi生成一个注意图Ai,它表示每个特定阶段Fdual中特征的重要性。给定每个阶段的Fi,我们将它们与Fdual连接,然后得到注意权重Ai:
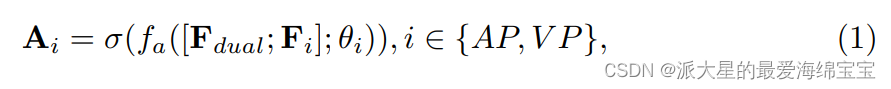
其中σ为Sigmoid函数,θ为fa学习到的参数,由两个级联的卷积层组成。第一个卷积层使用3 × 3 × 3核,第二个卷积层使用1 × 1 × 1核。每个卷积层后面都有一个实例归一化和一个leaky ReLU。这些卷积运算被用来建模相关性(判别双模态信息discriminative dual-modality information与每个模态的特征的相关性)。
然后,我们用逐元素(element-wise manner)的方式将注意地图Ai与Fi相乘。Fatt由每个Fi的加权和计算,定义为:
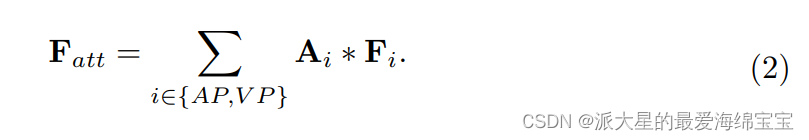
我们对每个相位应用MA模块,有选择地强调它们的特征。在这一过程中,利用注意机制生成一组注意地图,以表明对于更具辨别性的Fatt, Fi应该给予多少注意。此外,这些注意图提供了每个阶段对肝肿瘤分割的贡献的可视化解释,这在临床实践中是至关重要的。
2.3互学策略Mutual Learning Strategy
模态特定模型集的学习被公式化为关于地面真实掩模(ground-truth mask)的体素(voxel-wise)二元分类误差最小化问题。我们精心设计了用于多模态肝肿瘤分割的ML策略。具体地说,每一种模态特定模型都作为教师和学生相互作用。因此,静脉模型不仅可以从静脉期提取肿瘤分割的线索,还可以从动脉模型中学习,反之亦然。为此,我们引入了一个内相损耗(intra-phase loss)和一个关节损耗(joint)。前者鼓励每个流学习有区别的阶段特定的特征(discriminative phase-specific features),而后者鼓励每个流相互学习,以保持高级特征之间的共性,以便更好地合并多模态信息。
设X = {X静脉,X动脉}分别为输入静脉和动脉volumes,Y为ground-truth注释,W = {W静脉,W动脉}分别为静脉和动脉流中的权重。师生培养方案(teacher-student training scheme)的目标是使下列目标函数最小化:
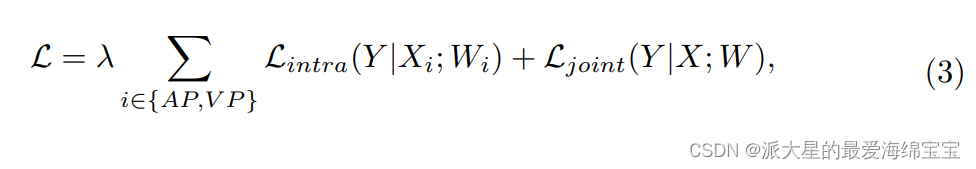
其中相位内损耗Lintra和关节损耗Ljoint均为标准分割损耗函数,λ为权重因子,经经验设置为0.5。我们采用交叉熵损失和Dice损失的组合作为分割损失,以减少肿瘤数据分布不平衡的影响。
ML的优点在于以下三个方面:
- (1)使模型既能处理多模态分割又能处理缺失模态,无需任何修改,在临床实践中是适用和高效的;
- (2)单个模态的每个模型都可以通过学习其他模型隐式利用双模态信息,即使在缺少其他模态的情况下也能获得更好的分割结果;
- (3)结合各模态的特点和共性,所有model-specific models的协同可以更好地进行多模态分割。
三.实验与结果
3.1数据集和评估指标
中国人民解放军总医院的CT增强volumes:
- 654个动脉和静脉相的CT增强容积,所有CT卷用SIEMENS扫描仪获得。
- CT体面内尺寸为512 × 512,间距为0.56 mm ~ 0.91 mm,切片数为67 ~ 198,间距为1.5 mm。
- 三位有丰富经验的肝胆外科临床医生参与了验证。我们利用配准方法[elastix : A toolbox for intensity-based medical image registration]来获取不同相位图像之间的空间关系。
- 对于数据预处理,我们将原始强度值在初始HU值的0.5%-99.5%范围内截断,并将每个CT原始病例归一化,使平均值和单位方差为零。
BraTS 2018数据集:
-
包含285名患者的MR扫描,包括T1、T2、T1对比增强(T1ce)和Flair四种模式。
-
该数据集的目标是分割脑肿瘤的三个子区域:整个肿瘤(WT)、肿瘤核心(TC)和增强肿瘤(ET)。
-
用于定量评价分割的指标包括Dice Similarity Coefficient(Dice)和平均对称表面距离(ASSD)。
3.2运行细节
- PyTorch环境,Nvidia Tesla V100 GPU
- Adam优化器训练
- 初始学习率为0.0003
- 每个volume送入网络前被切成128 × 128 × 128的小块(GPU内存的限制)
- 网络被训练了600个epochs,约150个小时
- 采用动态随机镜像,对所有训练数据进行旋转、变形deformation和伽马校正,以缓解过拟合问题
- 由于我们只打算评估网络设计的有效性,因此没有应用进一步的后处理策略。
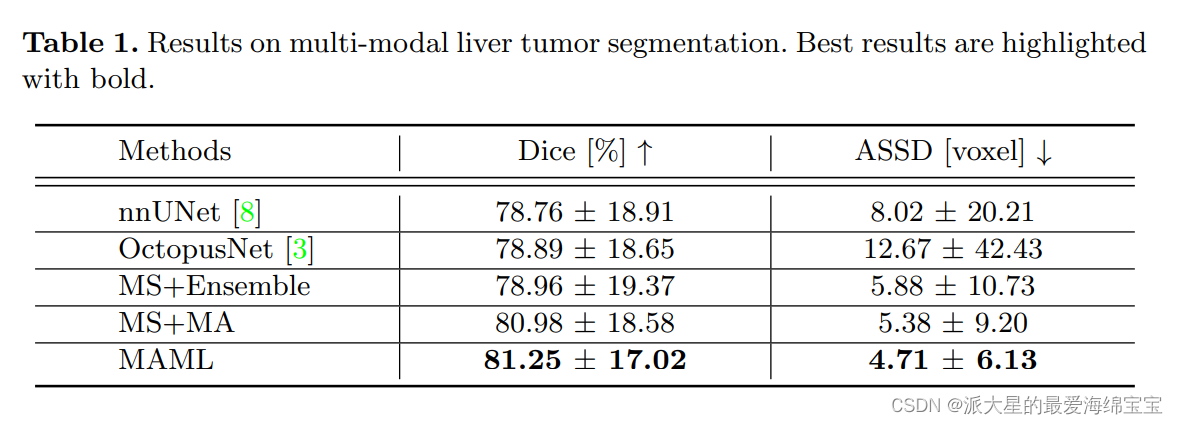
3.3多模态建模的有效性
我们分别在临床数据集上对MA和ML进行了消融研究,其中五分之一的图像用于测试,其余的用于训练:
- 基线是模态特定模型的输出的直接平均值,称为“MS+Ensemble”。
- 应用MA对模态特定模型进行自适应聚合,记为“MS+MA”。
- 将MA和ML结合起来,记为“MAML”
将MAML与最近的先进的多模态分割方法nnUNet和OctopusNet进行比较。前者接受两个相位的串接作为输入,而后者分别对每个相位进行编码,并通过一个解码器生成分割。
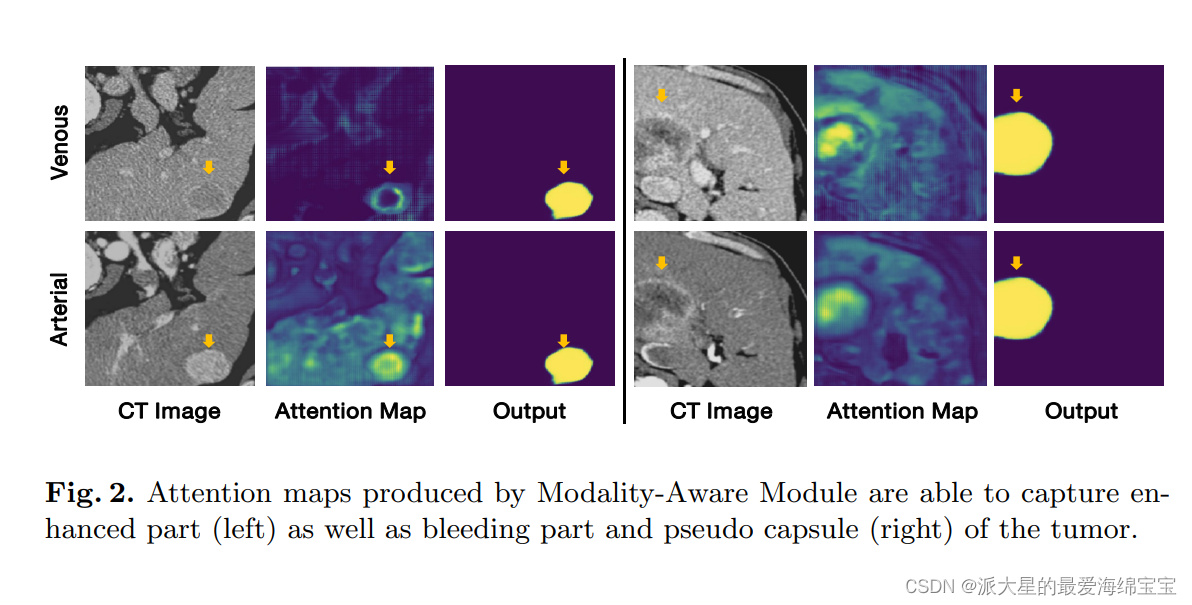
3.4可解释融合Interpretable Fusion
MA可提供解释的融合:
- 从图2(左)可以看出,静脉注意图集中在肿瘤的边缘,而动脉注意图集中在身体上。此外,一定数量的肿瘤表面和邻近肝脏通常勾画有假包膜。在图2(右)中,静脉注意图集中在假囊和肿瘤内出血部分。
这证明了MA可以捕获医学成像的知识,用于一个可解释的多模态肝肿瘤分割。
3.5处理缺失的形式
ML策略的一个优点是能够处理多模态分割中的缺失模态。我们考虑一个只有一种模式可用的极端场景。在临床数据集上,可以在推理过程中获得动脉期或静脉期的CT图像。
- 我们将nnUNet (MAML中模态特定模型的对应物)设置为基线,并仅对动脉或静脉期进行训练。
从表2中可以观察到,MAML明显优于基线。
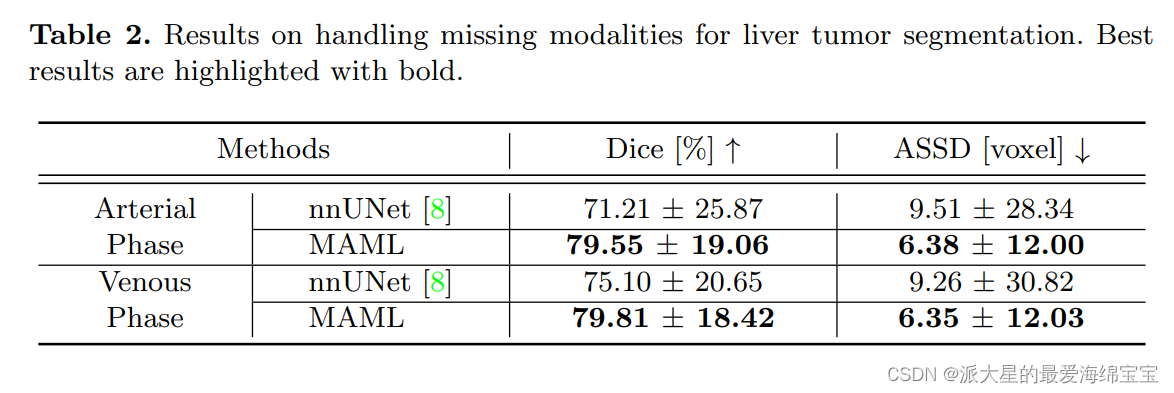
此外,MAML的动脉和静脉相间的性能差距明显小于nnUNet,显示出ML在模态间传递知识的出色能力。
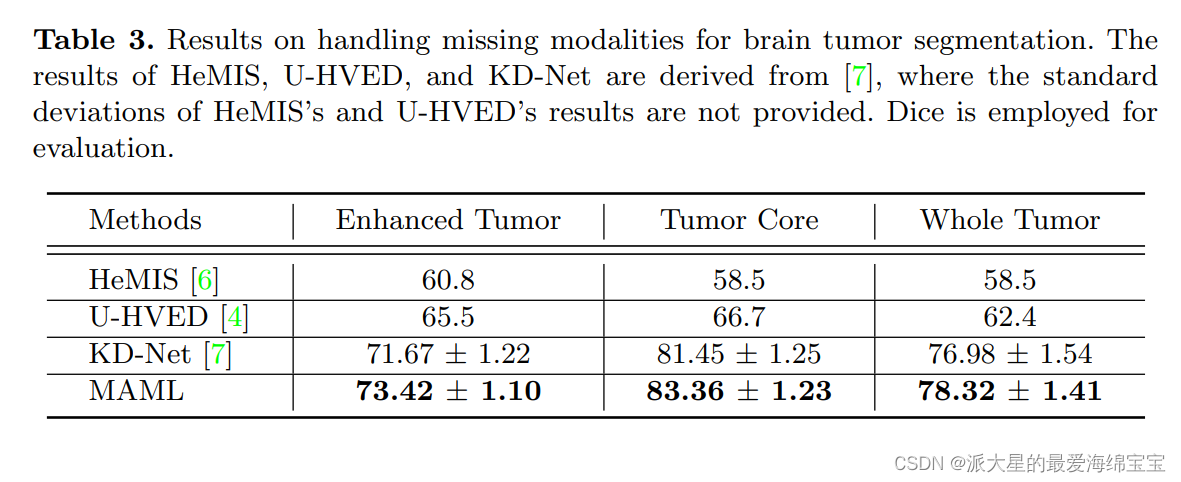
我们还比较了MAML与专门处理缺失模式的方法。在[7:Knowledge distillation from multi-modal to mono-modal segmentation networks]之后,仅使用T1ce模态作为输入,对BRATS 2018公共数据集进行了3次交叉验证。KD-Net[7]、U-HVED[4]和HeMIS[6]的结果在Dice方面直接取自[7:Knowledge distillation from multi-modal to mono-modal segmentation networks]。
从表3中,我们观察到我们的方法优于其他三种高级方法,证明了MAML处理缺失模式的有效性。
拟议框架在当前实施中的局限性在于,它既允许采用全套模式,也允许只采用一种模式作为输入。我们希望在未来的工作中对任意数量的缺失模式进行改进。