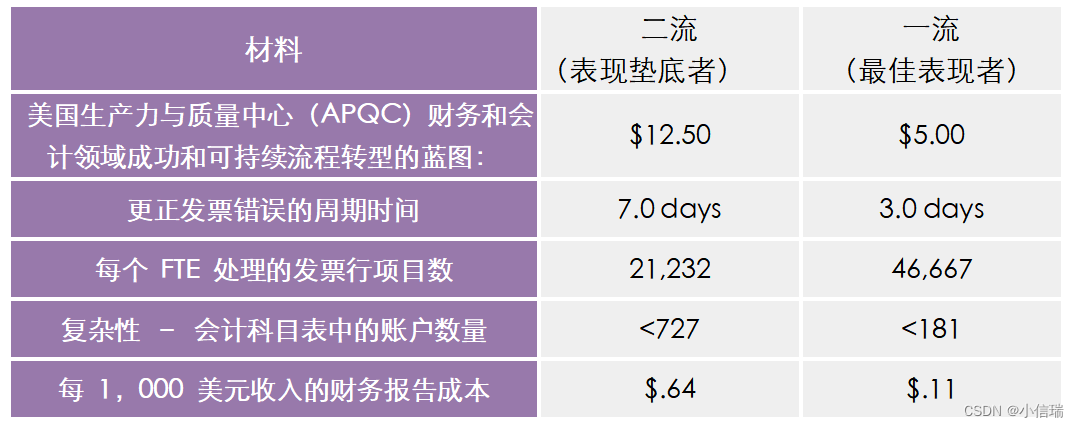
#01
背景

如今,短视频平台对各类搬运视频的检测力度和精确度越来越高了。无论是影视号的剪辑,还是从油管搬运,即使做了各类复杂的视频变换,都很容易被检测出来。作者都会收到提醒,严重的甚至被封号。

乔布斯演讲原始视频

搬运的视频,加了字幕遮盖
常见的视频变换手段包括时间和画面上的改变:
-
时间: 倒放,循环,混剪,加速,减速等
-
画面: 裁剪,翻转,缩放,分辨率,马赛克,色度,对比度,模糊,噪点,画面复制,文字或图案叠加,修改背景,二次盗拍,画中画,deepfake等
面对如此多种类的视频变换,平台是如何检测出来的?魔高一尺,道高一丈。针对各类层出不穷的作弊手段,现在平台的检测算法已经相对成熟。很难有搬运作弊视频逃脱检测。
本文将从技术角度分析揭开这背后的技术和算法,并手把手教你搭建一个同款的检测系统。
我们知道,现代 AI 神经网络模型可以对图像、视频等数据提取特征,也叫 embedding,每个图像或视频可以提取出一个独一无二的 embedding。对视频本身的重复检测也就是对提取出的 embedding 进行相似度分析。
首先我们了解两个概念,即不同粒度的视频的重复检测:视频粒度的检测和片段粒度的检测。
-
视频粒度检测是一种针对整个视频时长内拥有大量重复的情况的方法。 它通过比较两个完整视频的向量之间的相似性来找到重复的视频。 由于每个视频只会被一个向量表示,这种方法通常速度更快、效率得更高。 然而这种方法的局限性也很明显:无法适应部分片段重复的情况,尤其不利于检测长视频中小片段的重复。 例如,视频 A 和视频 B 的前 1/4 时长完全相同,后 3/4 时长完全不同,但它们的视频向量可能并不相似。 在这种情况下,视频粒度检测显然无法识别到侵权内容。
-
片段粒度检测能够找到重复片段的开始和结束时间,可以处理视频片段的复杂剪辑、插入片段、或视频长度不同等情况。 它的核心技术在于比较视频帧之间的相似性。显然,这种方法能够做到更加精确的查重效果,但要求更多的时间和资源。
在上一篇文章中,我们已经演示了如何构建一个简单的视频粒度视频去重系统。 在下面的例子中,我们将实现片段粒度的视频重复检测。这种细粒度的片段检测会更加精确,并带来更高的召回,比较符合实际业务需求。
我们会使用 Towhee 和 Milvus 搭建片段粒度的视频查重系统:Towhee 是一个能对非结构化数据一键提取 embedding 的工具;Milvus 是业内领先的向量数据库,可用于向量存储和检索。
本文中使用的方法可以将核心功能简化为几行代码,方便大家动手复现和学习。
#02
准备工作

1、安装依赖
在 python3 环境下,安装这些依赖:
! python -m pip install -q pymilvus towhee pillow ipython numpy plyvel
2、准备数据
我们使用的视频均来自 VCSL 数据集。VCSL 包括了大量来自 Youtube 和 Bilibili 的真实视频,主要用于视频重复检测。
该数据集的重复视频包含了多种复杂的变换手段,包括画面裁剪、过滤、文字覆盖、添加背景、盗拍、画中画等,在超过 28 万条片段重复中有大范围的内容变换。这些贴近现实的巧妙转换给片段级的视频重复检测带来了巨大的挑战。
作为示例,我们仅使用来自 VCSL 的 5 组视频,每组包含了对同一视频的 3 种不同搬运拷贝。 文件夹 crashed_video 中还有一个损坏的视频,用于稳健性测试。
通过下面的命令下载示例数据:
! curl -L https://github.com/towhee-io/examples/releases/download/data/VCSL-demo.zip -O
! unzip -q -o VCSL-demo.zip
我们简单地观察其中一组视频:它们分别对电影《夏洛特烦恼》中的经典片段进行了三种不同方式的搬运拷贝,比如加字幕和变换分辨率。
madongmei
├── 0640bd5d43d1499c962e275be6b804ef-大爷,马冬梅家住这吗?-1e64y1y799.flv
├── 8ad81fc9fe0a47dbaab1b4cdc40bf07b-行了,大爷你一边凉快去吧,神曲《马冬梅》-1t54y117JK.flv
└── ad244c924f31461a9d809c77ae251ac1-夏洛特烦恼沈腾和大爷的经典对话,马什么梅,马冬什么,什么冬梅-1y7411n7y1.flv



3、创建集合
在正式搭建系统之前,我们需要准备一个 Milvus 集合。通过下面的方式可以快速安装并启动 Milvus 服务,更多细节和设置可参考 Milvus doc:
# Download docker yaml for Milvus standalone
! wget https://github.com/milvus-io/milvus/releases/download/v2.1.1/milvus-standalone-docker-compose.yml -O docker-compose.yml
# Run command below under the same directory as the docker yaml
! docker-compose up -d
创建一个名为video_deduplication的集合,使用L2 distance metric和 IVF_FLAT index:
from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection, utility
connections.connect(host='127.0.0.1', port='19530')
def create_milvus_collection(collection_name, dim):
if utility.has_collection(collection_name):
utility.drop_collection(collection_name)
fields = [
FieldSchema(name='id', dtype=DataType.INT64, descrition='id of the embedding', is_primary=True, auto_id=True),
FieldSchema(name='path', dtype=DataType.VARCHAR, descrition='path of the embedding',max_length=500),
FieldSchema(name='embedding', dtype=DataType.FLOAT_VECTOR, descrition='video embedding vectors', dim=dim)
]
schema = CollectionSchema(fields=fields, description='video dedup')
collection = Collection(name=collection_name, schema=schema)
index_params = {
'metric_type':'L2',
'index_type':"IVF_FLAT",
'params':{"nlist":1}
}
collection.create_index(field_name="embedding", index_params=index_params)
return collection
collection = create_milvus_collection('video_deduplication', 256)
#03
重复视频检测

接下来,我们将展示如何使用 Milvus 和 Towhee 构建我们的细粒度视频去重系统。该系统的核心思想是使用 Towhee 提供的 Image Embedding 算子提取视频帧向量,并将其存储在事先准备好的 Milvus 集合中,然后通过比较视频帧向量之间的相似度找到重复片段。
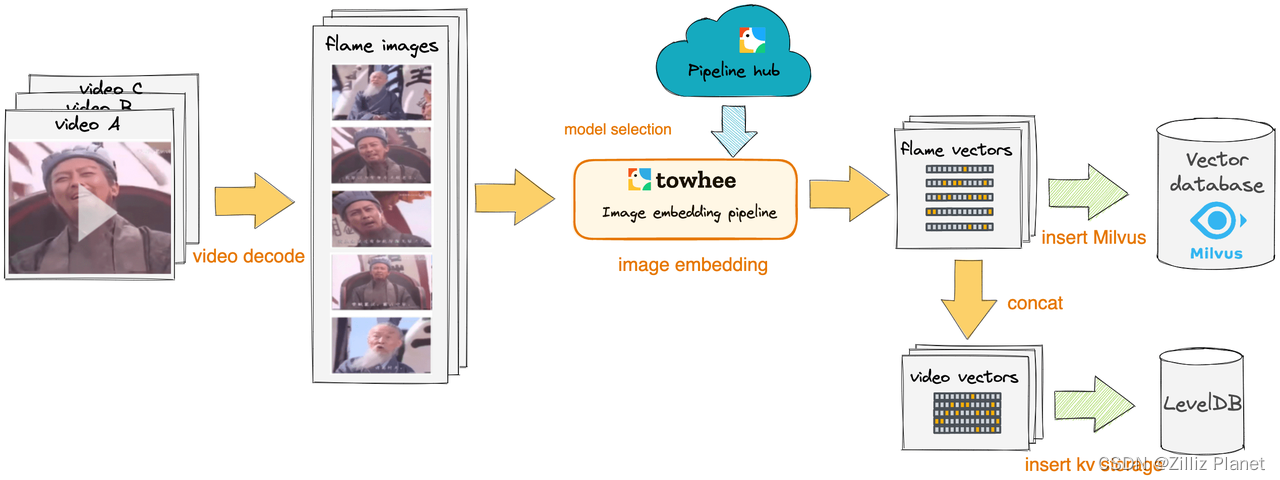
1、入库流程
对于每个视频,我们将其解码为图像帧,然后使用预训练好的神经网络将它们转换成向量。 这些向量会被插入到 Milvus 集合和 levelDB 中进行存储。
import towhee
import numpy as np
from towhee.types import Image
os.environ["CUDA_VISIBLE_DEVICES"] = '1'
@towhee.register
def get_image(x):
for i in x:
yield Image(i.__array__(), 'RGB')
@towhee.register
def merge_ndarray(x):
return np.concatenate(x).reshape(-1, x[0].shape[0])
all_file_pattern = os.path.join(vcsl_demo_root, '*', '*.*')
dc = (
towhee.glob['video_url'](all_file_pattern).stream()
.video_decode.ffmpeg['video_url', 'frames'](sample_type='time_step_sample', args={'time_step': 1})
.get_image['frames', 'images']()
.flatten('images')
.drop_empty()
.image_embedding.isc['images', 'embeddings']()
.select['video_url', 'embeddings']()
.ann_insert.milvus[('video_url', 'embeddings'), 'insert_result'](uri='tcp://localhost:19530/video_deduplication')
.group_by('video_url')
.merge_ndarray['embeddings', 'video_embedding']()
.insert_leveldb[('video_url', 'video_embedding'), ]('url_vec.db')
.select['video_url', 'video_embedding']()
.show(limit=20)
)

视频帧向量提取结果展示
我们可以看到每个视频都被转成了为 n(默认 n 为时长秒数)条 256 维的向量。如果运行中出现报错“ERROR: header damaged”,那意味着样本数据集有损坏的视频。在 Towhee 搭建的流水线中,批量操作会自动跳过某个数据导致的错误,继续运行直至所有数据处理完毕。这是为了模拟在实践中,在处理庞大的视频数据时不会被少量的损坏视频影响进度。
2、检测流程
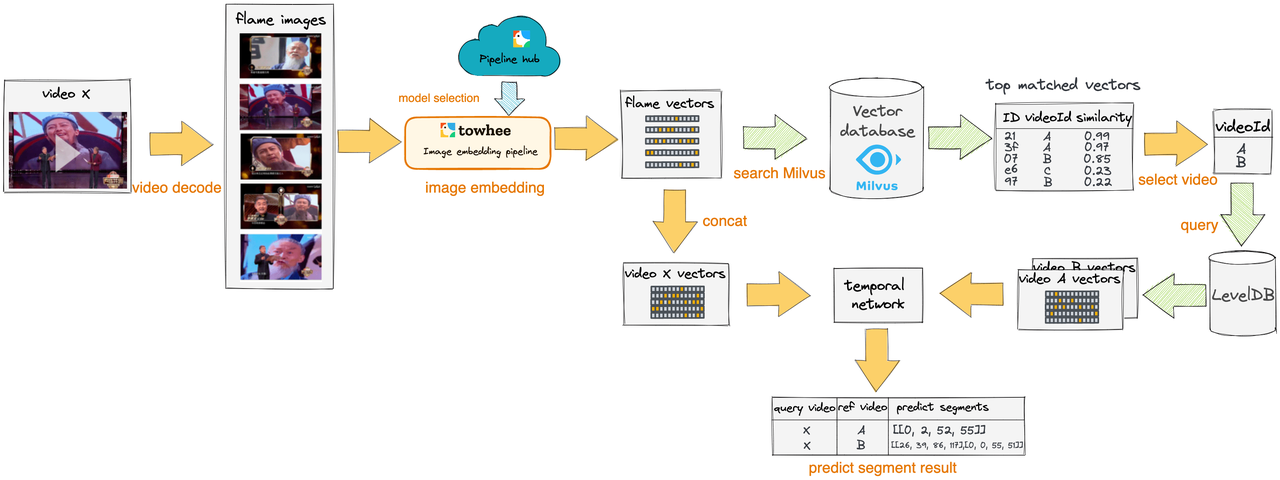
理论上,对于每一个查询视频,都需要匹配和检索数据库中的所有视频,然而这会导致巨大的开销。 在本例中,我们选择首先根据视频帧向量进行一遍粗筛,简单过滤掉完全不相关的视频。
-
粗筛:对于每个查询帧,我们通过 Milvus 向量检索找到一定数量的相似帧,并匹配到对应的视频。 然后对这些视频进行聚合、排序和过滤。这一步骤对应了上面检测流程图中,select video 选出 video A 和 video B 的过程。
然后,我们比较粗筛结果中的视频和查询视频的视频帧向量,使用 Temporal Network 对齐算法,定位重复的片段。
query_file_pattern = os.path.join(vcsl_demo_root, 'madongmei', '*.*')
@towhee.register
def split_res(x):
return [i.path for i in x], [i.score for i in x]
dc = (
towhee.glob['query_url'](query_file_pattern).stream()
.video_decode.ffmpeg['query_url', 'frames'](sample_type='time_step_sample', args={'time_step': 1})
.get_image['frames', 'images']()
.flatten('images')
.drop_empty()
.image_embedding.isc['images', 'embeddings']()
.select['query_url', 'embeddings']()
.ann_search.milvus['embeddings', 'results'](collection=collection, limit=64, output_fields=['path'], metric_type='IP')
.split_res['results', ('retrieved_urls','scores')]()
.group_by('query_url')
.video_copy_detection.select_video[('retrieved_urls','scores'), 'ref_url'](top_k=5, reduce_function='sum', reverse=True)
.from_leveldb['ref_url', 'retrieved_embedding']('url_vec.db', True)
.merge_ndarray['embeddings', 'video_embedding']()
.flatten('retrieved_embedding', 'ref_url')
.video_copy_detection.temporal_network[('video_embedding', 'retrieved_embedding'), ('predict_segments', 'segment_scores')]()
.select['query_url', 'ref_url', 'predict_segments', 'segment_scores']()
.show(limit=50)
)
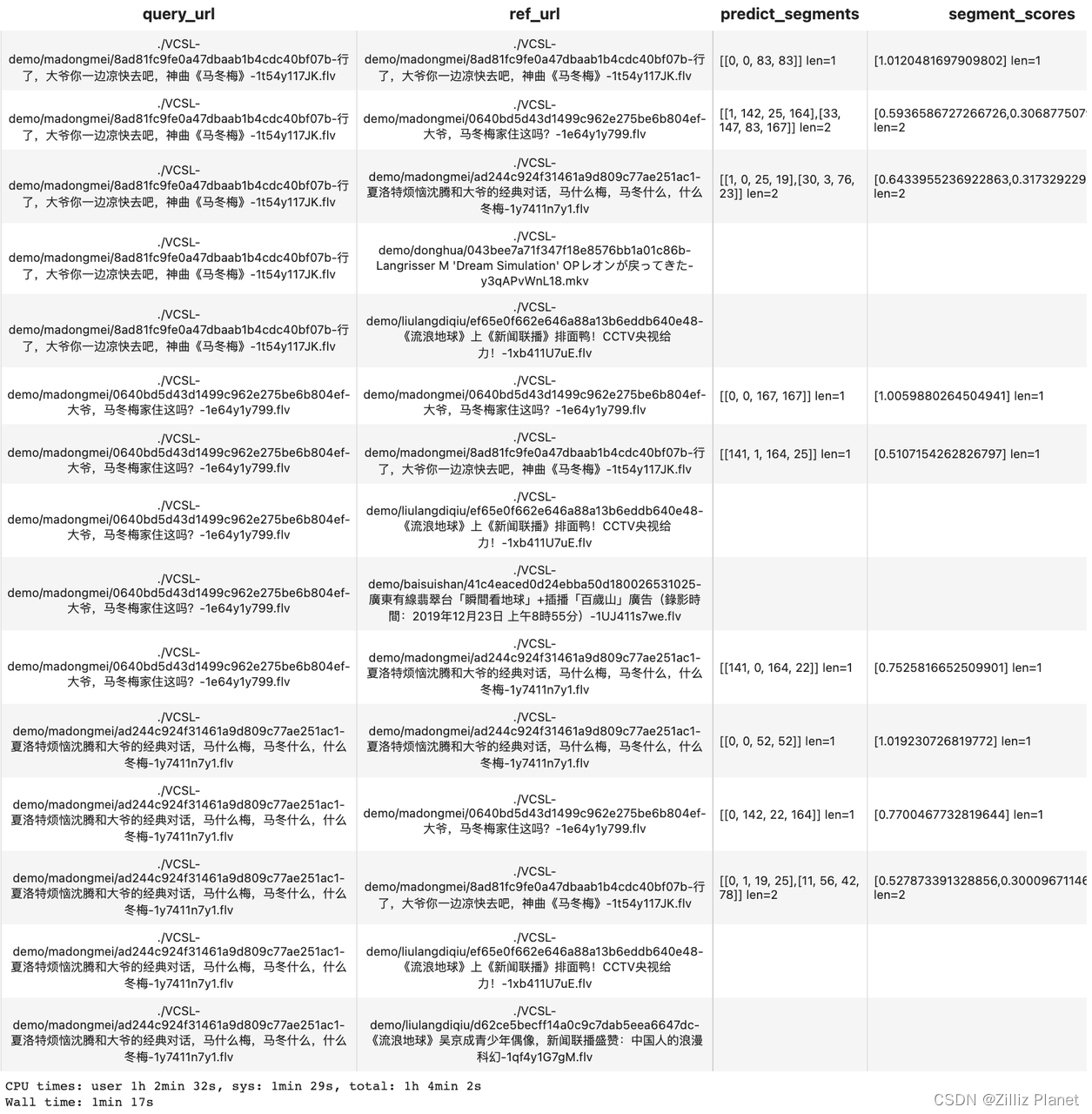
视频查重流程返回结果
我们这里使用同样的数据集进行查询,共 5 组视频,每组包含的 3 个视频是彼此的搬运副本(重复视频)。针对这个数据集查询,我们期望的正确查询结果应该是找到查询对象本身与它同组的两个副本视频。
另外,我们解读一下 Temporal Network 算子输出的结果:predict_segments 列展示了重复片段的具体时间[query_start_second, ref_start_second, query_end_second, ref_end_second] ,segment_scores列则表示了每个重复片段对应的相似度分数。我们可以观察到每个查询视频确实只检测到其自身事件的 3 个结果,这与我们预期的结果(ground truth)是一致的。
以第7行的结果为例,predict_segments = [141, 1, 164, 25],表示在 query video 的第 141 到 164 秒与 ref video 的第 1 到 25 秒重复。

#04
总结

对于常见的视频搬运查重,这一套方案就足已解决,当然具体的场景或许还需要调整一些参数。如果面对比较特殊的场景(比如声音抄袭)或者对速度性能要求更高的话,我们仍需要采用其他方法优化工程方案。
想要获取更多向量化的模型和方法,请参考 Towhee。
如需处理更大规模向量数据,可以选择配置 Milvus。
Jupyter Notebook 教程:https://github.com/towhee-io/examples/blob/main/video/video_deduplication/segment_level/video_deduplication_at_segment_level.ipynb