前言
关于bash:
bash:命令处理器,运行在文本窗口,能够执行用户输入的命令。
脚本:从linux文件中读取命令,被称为脚本。
1 命令:alias:起别名
2 快捷键操作:
ctrl+a:光标最左
ctrl+e:光标最右
ctrl+k:光标后面全删
ctrl+l:clear清屏
tap:命令补全
3. 特别的:
linux文件的文档每一行末尾都有 符,空白行也一样利用 c a t − E n p w d . t x t 发现所有内容末尾都有 符,空白行也一样 利用cat -En pwd.txt发现所有内容末尾都有 符,空白行也一样利用cat−Enpwd.txt发现所有内容末尾都有
关于正则表达式
基本正则表达式:BRE:regular expression
扩展正则表达式:ERE:extend regular expression
Linux三剑客的用途
grep:linux文本查找,一般不改变原文件
sed:linux文本替换,加-i可以改变原文件
awk:linux文本格式化后显示,一般不改变原文件,像Excel格式
以上三者,都是按行操作,一行行去操作
关于正则表达式和扩展正则表达式
普通正则表达式:


扩展正则表达式:
grep和sed使用需加: -E

+:匹配前一个1次或多次
a{n, m}:注意是花括号{},重复前面的a至少n次,最多m次。
[abc]:匹配abc中任意字符1次,带上+,就是匹配前面1次或多次。
grep
选项:

-v:取反,是比较常用的操作
grep [选项] [模式]
grep 单引号和双引号:一般用单引号,有变量用双引号
grep入门练习
·练手材料
cat /etc/password > pwd.txt
- 查找root行,忽略大小写
-i:忽略大小写
可以利用grep --help查看各种选项
grep root -i pwd.txt
- 统计有多少root有关的行,显示行号
-c:统计
可以利用grep --help查看各种选项
grep root pwd.txt -c -n
- 统计空行以外所有行和号
匹配空行用^$,起始和末尾中间是空
显示行号 -n // 也可以加到-v
取反 -v
grep '^$' pwd.txt -n -v
- 显示非注释行,注释行以#开头
grep '^#' -n -v pwd.txt
- 找所有m开头的,不论大小写
-n:显示行号
-i:忽略大小写
grep -i '^m' pwd.txt -n
- 输出以.结尾的行
当要匹配的是正则表达式特殊符号时,加转义反斜杠
-o 可加可不加,加上把行上其它内容去掉
grep -n '.$' pwd.txt
- 匹配有good和glod的行
():分组过滤,()内是一个整体,可以被\1引用,且是扩展正则,需要加-E
grep -E '(good|glod)' pwd.txt
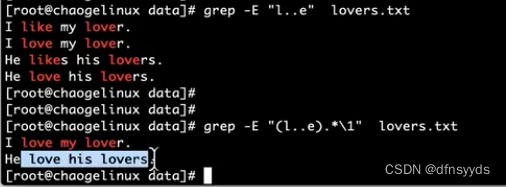
- 匹配‘lxxe’,且这个词需要出现至少两次,这两次的中间可以有任意内容
- 寻找带af或NZ或8~9的数字
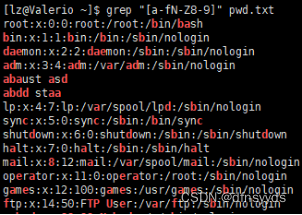
- 找到所有大写字母或者带数字的行
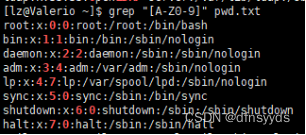
如果是[]带^,就是排除
grep练习题
回忆正则表达式和扩展正则表达式
^:表示锚定行首,此字符后面的任意内容必须出现在行首,才能匹配。
$:表示锚定行尾,此字符前面的任意内容必须出现在行尾,才能匹配。
^$:表示匹配空行,这里所描述的空行表示"回车",而"空格"或"tab"等都不能算作此处所描述的空行。
^abc$:表示abc独占一行时,会被匹配到。
<或者\b :匹配单词边界,表示锚定词首,其后面的字符必须作为单词首部出现。
>或者\b :匹配单词边界,表示锚定词尾,其前面的字符必须作为单词尾部出现。
\B:匹配非单词边界,与\b正好相反。
特别的扩展正则表达式:加-E
在基本正则表达式中,{n} 表示前面的字符连续出现n次,将会被匹配到。
在扩展正则表达式中,{n} 表示前面的字符连续出现n次,将会被匹配到。
在基本正则表达式中,( ) 表示分组,(ab) 表示将ab当做一个整体去处理。
在扩展正则表达式中,( ) 表示分组,(ab) 表示将ab当做一个整体去处理。
grep使用习惯
- grep做题用双引号
- >、<,其实像一对<>,显然<是起始,而>是结尾。分隔符不管是空格 还是 : ,grep自动能识别分隔符。
- 用扩展正则时,””,可以少写\,用()表示分组。()不用加\
- 扩展正则表达式中的>或<,还是得加\
-
找出root有关行

-
root开头的行
开头:用^
grep '^root' pwd.txt
-
root开头或sync开头
grep匹配建议都用"",如下括号前不必加反斜杠
要用到(),使用选项:-E
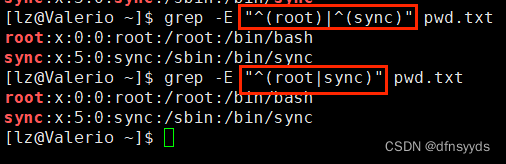
-
找出bin开头的行,要行号
行号 -n

-
找出非root开头的行
取反 -v:
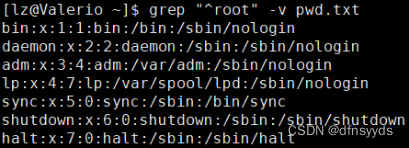
-
统计
先grep再加管道:| wc -l

-
最多匹配root3次
-m选项,直接加3

-
匹配多个文件,列出存在信息的文件名称
grep --help:
-l:匹配到的文件名,
-L:匹配不到的文件名

-
显示不以/bin/bash结尾的行
结尾用$,取反用 -v,下面忘了加 -v

-
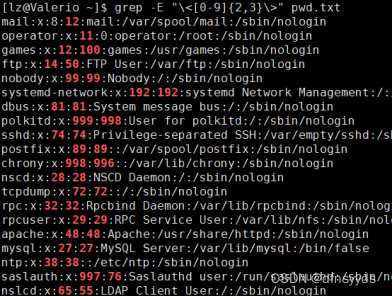
文件中2位数或3位数字的行
让数字重复2~3次。
[0-9]{2,3}
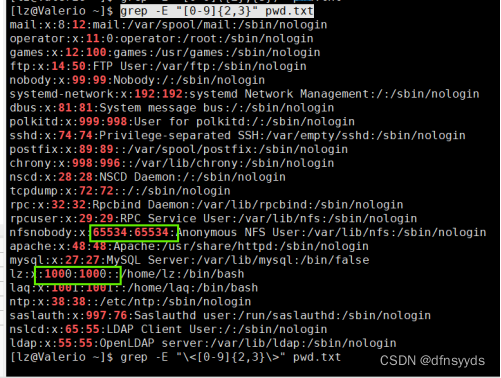
第一个绿色错误:因为655,符合数字出现3次,而34符合出现2次,所以看到65534和65534标红,而1000中100匹配到是因为匹配到了三次,而后面的单独0,匹配不到,因为最多3次。
所以需要增加一个结尾标志符:
这样,数字的后面必须是特殊符号
-
找出文件中所有大小写i开头的行
两种写法:
grep -i:忽略大小写

或者忽略大小写:

或者【】包裹或关系的字符

-
找出文件中至少一个空白字符开头,后面非空字符的行
文件中有纯空格的行和空行。
别匹配到纯空格行
空格:[[:space:]]
以空格开头即可
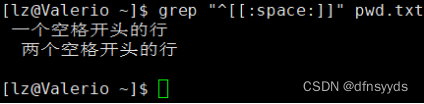
但是我不要纯空格行,怎么去?加上一个去掉纯空格行的命令,管道纯空格取反,其实下面应该写*,而不是以$结尾,但是这样也行的

下面也可以
-
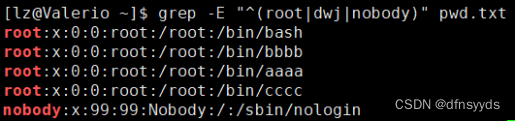
root,dwj,nobody用户的信息
()需要扩展表达式,-E
空格记得别乱加,这个用老方式,以各行开头,取或即可
“^(a|b|c)”
-
找出文件中的函数名,字符串后面跟着括号
函数必须字母开头:^加字母
后面是任意数字,但是最后需要是()。 如果文本有空格,适合sed查找。
如果文本有空格,适合sed查找。 -
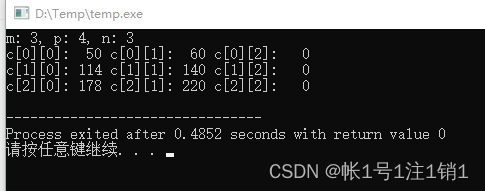
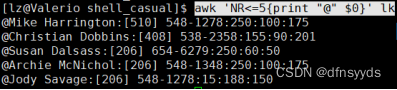
找出用户名和shell相同的用户?
分析:什么是和shell相同的用户?
解释器在最后一列,而用户是开头,所以以:分割,找开头和结尾相同的。
思路:匹配第一个:前面出现出现的词且末尾也要出现一次。
匹配到:结尾而不要:,[^:],意思是不要引号,然后它应该再重复一遍,所以圈起来,中间可以是任意,所以用.*,而要匹配到末尾,出现一次,所以要用\1,一定要加$。
使用:“(^[^:]*).*\1$”,
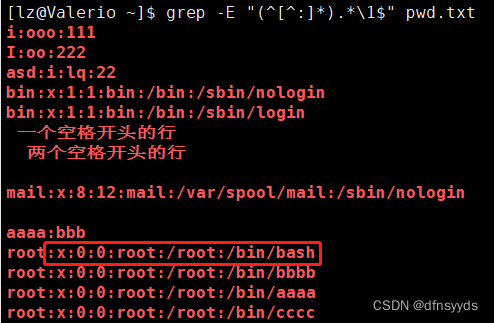
以上的错误在于后面使用.*,匹配到了全部。
加上>,确定词尾,意思是匹配到前面就停止。
技巧,用\1的部分,最好加上>。
sed
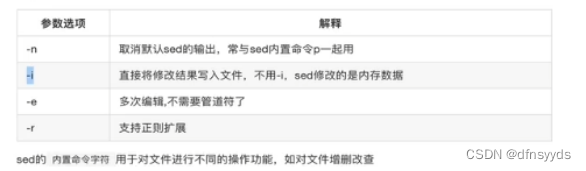
sed的选项:
-i:对原始文本做替换
-n:取消默认输出
-e:多次编辑
-r:支持正则扩展
sed的内置字符:

·与grep的相同点:
sed和grep均不考虑分隔符,因为只是做匹配和匹配替换
·与grep的区别:
- sed尽量使用单引号’’
- sed的扩展正则是-r,-e是多次编辑
sed练习题
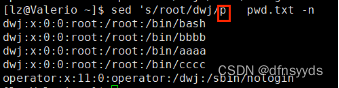
1 替换文件的root为dwj,只替换一次
sed的替换,用s杠杠杠///
要显示加上p
仅仅打印用-i
sed 's/root/dwj/p' pwd.txt
只是替换root,而不是开头的
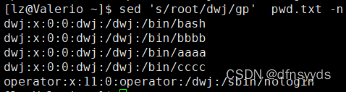
2 替换文件所有root为dwj,仅打印替换结果
所有的,用g
sed 's/root/dwj/gp' pwd.txt
3 替换前10行b开头的用户,改为c,仅仅打印替换的结果
前10行,加在s前面,1, 10
sed '1, 10s/^b/c/p' pwd.txt

4 替换前10行b开头改为c且m开头改为n
前10行,在’'中加1,10即可
连续做两次,-e即可
sed -e '1,10s/^b/c/' -e '1,10s/^m/n/p' pwd.txt

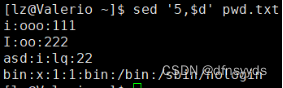
5 删除4行后面的行
后5到末尾的行:5,$
删除加:d
sed '5,$d' pwd.txt
6 删除从root开始到ftp之间的行
既然也是行,就用逗号隔开
删除加d即可
sed '/^root/,/^ftp/d' pwd.txt

7 删除文件中空白字符开头的行,添加注释符
这个是需要替换,删除还添加,做个替换即可。
匹配开头是空格的空格,并且替换为@\1,此外,-r表示扩展正则表达式

8 删除文件中空白行和注释行
sed 's/(^$|#)//d' pwd.txt
数据:
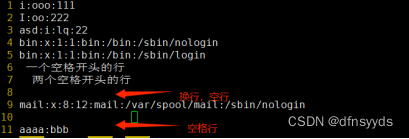
grep ‘^$’得到空行,不是空格行(因为一般没有空格行)
而要找空行就是第8行
操作注释行的删除
数据 lk:
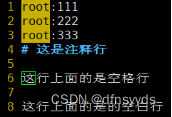
先删除空白行:
sed ‘/^$/d’ lk
发现空白行消失了,空格行还在
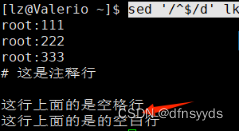
删除注释行
找某行,都是用杠杠//即可,不用三个杠杠杠
sed ‘/^#/d’ lk
发现#行删除了
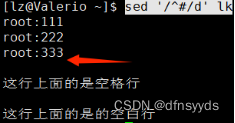
两种合并用-e:
sed -e ‘/^$/d’ -\e ‘/^#/d’ lk
空格行和注释行都被删除了。
9 文件前三行,添加@
其实是替换开头内容为原始多加一个@
所以用\1,(),需扩展表达式 -r
sed -r '1,3s/^(.)/@\1/p' pwd.txt
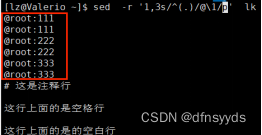
10 取出ip地址,两种方式
ifconfig eth0,显示物理网卡内容,加管道,sed 取第二行,2p即可
字符串替换前面的内容为空
多个管道,做替换即可,注意每次都需要-n,取消默认显示内容


11 找出系统版本
/etc/centos-release
把这一串中的第一个数字拿到即可

思路把release之前都替换掉,然后把第一个点后面的的内容都替换掉

也可以是:

awk
awk选项参数
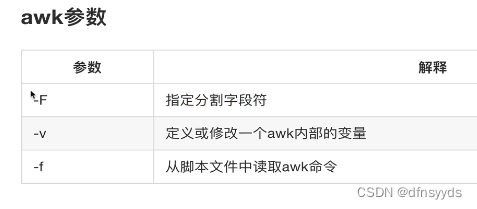
-F需要搭配双引号使用,指定读取的分隔符,允许使用两种分隔符。

与grep和sed的区别:
awk只用两个//,因为它只做查找并显示成Excel的格式
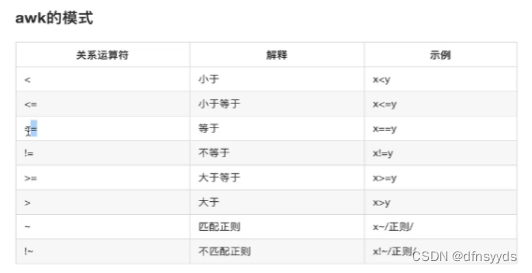
awk的模式
要对某个列做限定,需要用匹配正则,加飘~
内置变量:
以下都是针对awk的
RS:awk输入换行符修改
ORS:awk输出换行符修改
NR:行号,当前处理的文本行的行号
NF:列号
FNR:各文件分别计数的行号
FILENAME:当前文件名字
ARGC:命令行参数的个数
ARGV:数组,保存命令行给定的各个参数
数字搭配$会显示当前列。
小试身手:
1 $0显示每一行
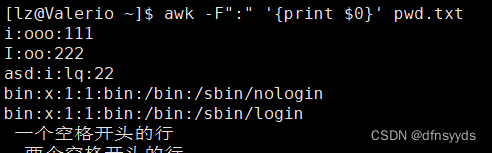
2 NF是行号

3 选定行号输出 NR==2,结果只有一行输出

4 可以在动作之前加模式,开始或结束输出,也在单引号中
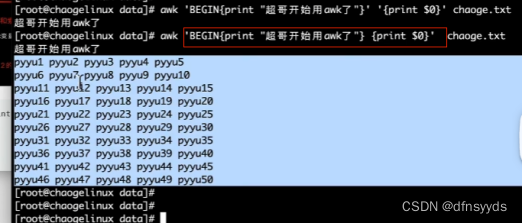
5 也可以输出参数
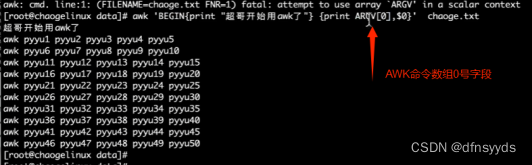
awk练习题
1 在当前系统中打印出所有普通用户的用户和家目录
需要加条件:第3列>=1000,大于等于1000才是普通用户ID,在{}前面加
awk -F":" ‘$3>=1000{print $1, $NF}’ pwd.txt
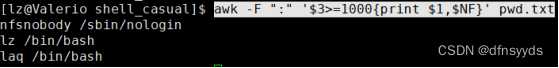
2 给txt文件的前5行添加#号
awk添加内容,只是显示上,所以直接读取前5行,多打印输出一个内容即可。
3 统计文本信息
名 姓 区号 电话 三个月捐款数量
Mike Harrington:[510] 548-1278:250💯175
Christian Dobbins:[408] 538-2358:155:90:201
Susan Dalsass:[206] 654-6279:250:60:50
Archie McNichol:[206] 548-1348:250💯175
Jody Savage:[206] 548-1278:15:188:150
Guy Quigley:[916] 343-6410:250💯175
Dan Savage:[406] 298-7744:450:300:275
Nancy McNeil:[206] 548-1278:250:80:75
John Goldenrod:[916] 348-4278:250💯17
Chet Main:[510] 548-5258:50:95:135
Tom Savage:[08] 926-3456:250:168:200
Elizabeth Stachelin:[916] 440-1763:175:75:300
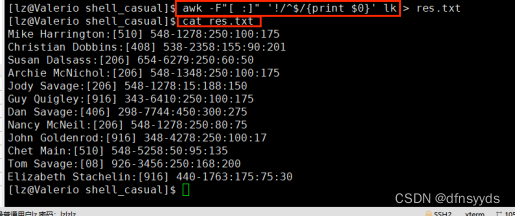
因为数据以:、空格切分,所以分隔符用[: ]两种选择
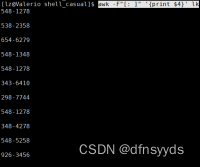
空格行,要删除,所以加匹配项,要取反。
awk正则匹配,用两个//就行了。此外,去除空行,用!取反即可。
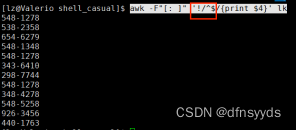
4 显示Tom电话
tom是名,在第一列,在开头,像上一题匹配空行一样,直接匹配即可

5 显示Nancy姓名、区号、电话

6 显示所有D开头的姓
要对某个列做匹配,需要用匹配正则,加飘~
姓在第二列,而要对第二列做正则匹配,就得在
//前面加列和~,后面才是正则表达式

注意列匹配放在/最前面,且带上飘~。
也是两个//
7 显示所有区号是916的人名
区号916,用[916],但是防止[916]被识别为正则表达式的或选择

8 显示Mike捐钱信息,每一项加美元符

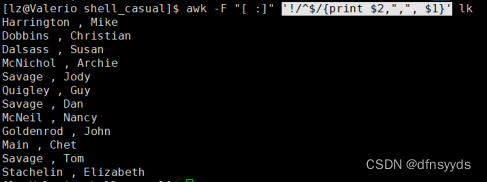
9 显示所有人的姓+逗号+名
记得最前面取反,去空行
然后姓、名无非是$2,$1反着写
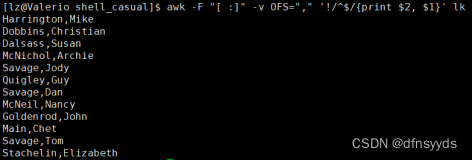
10 修改文件内置输出符
-v OFS=”,”
11 删除文件空白行
也就是个匹配空白,取反操作。



![学习babylon.js --- [4] 体验WebVR](https://img-blog.csdnimg.cn/87983d87a5a64db4980a90b371001d40.png)