HBase是一个分布式、可扩展、面向列的数据存储(百万级别列)、可伸缩、高可靠性、实时读写的NoSQL 数据库。
HBase利用 Hadoop的 HDFS作为其文件存储系统, 利用MapReduce 来处理HBase中的海量数据, 利用Zookeeper作为分布式协同服务。
HBase 基本的操作命令:
# 进入HBase 客户端
[zsm@hadoop102 hbase-1.3.1]$ bin/hbase shell
# 查看所有的表
hbase(main):002:0> list
TABLE
stu
stu2
stu3
stu4 创建表:
create 'tableName', 'cf1', 'cf2'创建一个包含cf1、cf2 两个列族的表
插入数据:
put 'tableName', 'row1', 'cf1:column1', 'value1'在表的【row1】 行,【cf1】 列族下的 【column1】 列 中插入值 【value1】
更新数据:
put 'tableName', 'row1', 'cf1:column1', 'value2'将表的【row1】 行,【cf1】 列族下的 【column1】 列值修改为【value2】
查看数据:
# 查看指定行
get 'tableName', 'row1'
# 查看指定行的指定列族的指定列
get 'tableName', 'row1', 'cf1:column1'全表扫描数据:
# 全表扫描
scan 'tableName'
# 分段扫描 ,从row1行开始 【, 到row2行结束】
scan 'tableName', {STARTROW => 'row1' [, STOPROW => 'row2']}条件过滤:
# 单列值过滤器(SingleColumnValueFilter)
scan 'mytable', {FILTER => "SingleColumnValueFilter('cf1', 'column1', '=', 'value1')"}
# 组合过滤
scan 'mytable', {FILTER => "FilterList(AND, SingleColumnValueFilter('cf1', 'column1', '=', 'value1'), SingleColumnValueFilter('cf2', 'column2', '>=', '100'))"}
# 页码过滤
scan 'mytable', {FILTER => "PageFilter(10)"}
# 行键范围过滤器(RowFilter)
scan 'mytable', {FILTER => "RowFilter(>=, 'binary:row1')"}删除表、数据
# 删除表
disable 'tableName'
drop 'tableName'
# 清空表
truncate 'tableName'
# 删除某一行
delete 'tableName', 'row1'
# 删除某一列
delete 'tableName', 'row1', 'cf1:column1'HBase 数据模型
HBase 的数据模型同关系型数据库很类似,数据存储在一张表中,有行有列。但从HBase 的底层物理存储结构(K-V)来看,HBase 更像是一个multi-dimensional map(多维度 K-V)。它是一个面向列的数据存储, 可容纳百万级别列。
HBase物理存储结构:
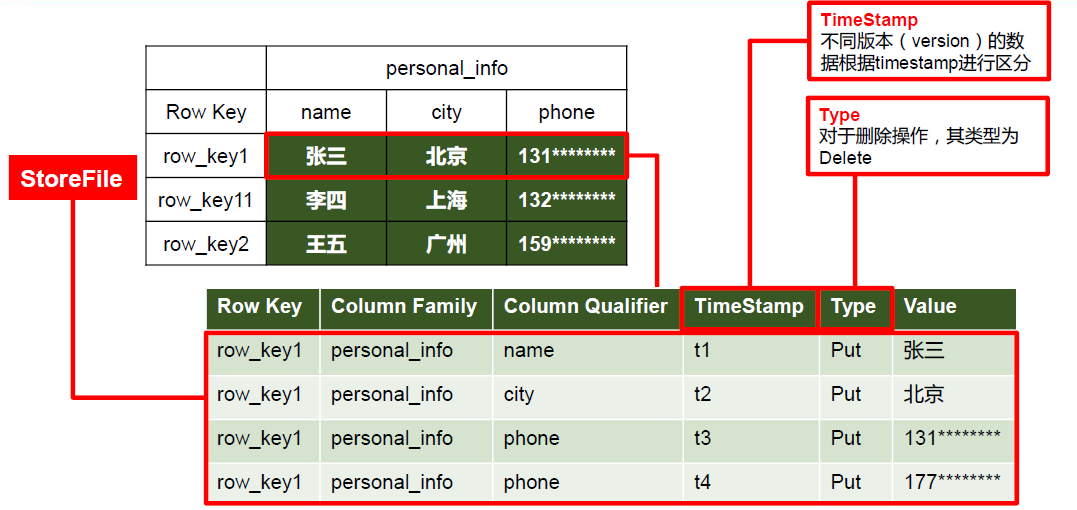
HBase的数据模型的主要组成部分:
-
表(Table):HBase中的数据存储在表中,每个表有一个唯一的名称。表由行和列组成,以键值对的形式存储数据。
-
行(Row):在HBase中,每一行由一个唯一的行键标识。行键是一个可变长的字节数组,以字典序排序。行键是HBase中数据访问和查询的主要方式。
-
列族(Column Family):表中的列按照列族进行组织,列族定义了一组具有相似属性的列。每个列族都有一个唯一的名字。不同列族的列在物理存储上是分开存储的,这样可以为不同列族的数据设置不同的存储和压缩策略。
-
列限定符(Column Qualifier):列限定符用于标识列族中的每个列,它是在列族内唯一的。例如,如果列族是"user",那么列限定符可以是"age"、"name"等。
-
单元格(Cell):一个单元格由行键、列族、列限定符和时间戳组成。一个表中的数据由多个单元格组成。
-
版本号(Version):HBase支持存储多个版本的数据。每个单元格可以存储多个版本的值,每个版本都有一个对应的时间戳。通过版本号可以实现数据的历史查询和版本控制。
-
命名空间(Namespace):命名空间是对表的逻辑分组,相当于一个命名空间的容器。它提供了一种逻辑隔离和管理表的方式。
HBase架构原理:
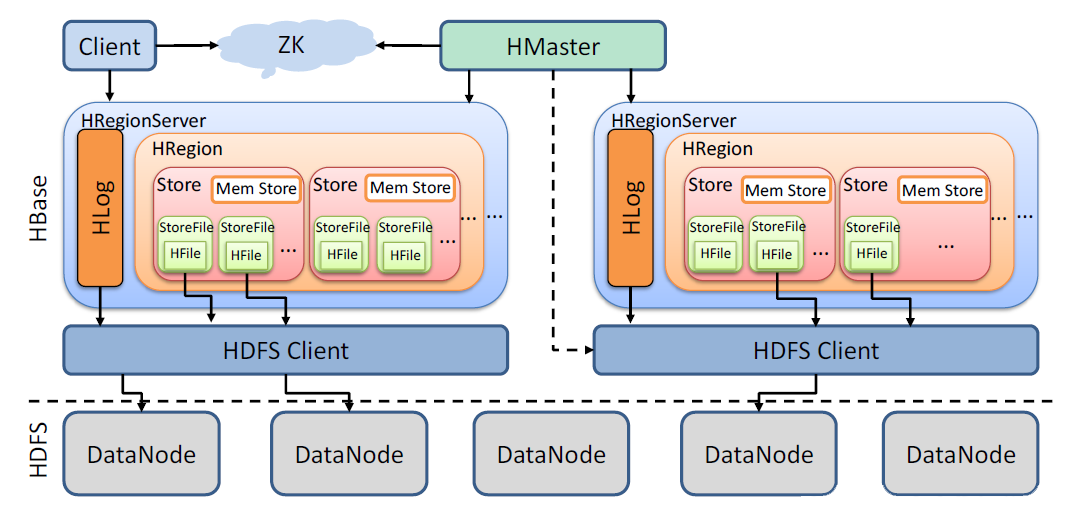
- client: 包含访问HBase的接口并维护cache来加快对HBase的访问
- zookeeper:
- 保证任何时候,集群中只有一个活跃的master
- 存储所有的region的寻址入口
- 实时监控Region server 的上线和下线信息,并实时通知Master
- 存储HBase的schema和table的元数据
- Master
- 为RegionServer 分配region
- 负责Region server 的负载均衡
- 发现失效的Region server 并重新分配其上的region
- 管理用户对table的增删改操作
- RegionServer
- 存储HBase的实际数据
- 刷新缓存到HDFS
- 维护region, 处理对这些region的IO请求
- 切分在运行过程中变化过大的region
- Region: HBase分布式存储和负载均衡的最小单元,包含一个或多个store,每个store保存一个columns family。
- Store: 包括位于内存中的memstore和位于磁盘的storefile。客户端检索数据,先在memstore找,找不到再找storefile 。
- MemStore:放在内存里的,保存修改的数据即keyValues。当MemStore的大小达到一个阀值(默认64MB)时,MemStore会被Flush到文件。
- StoreFile:MemStore内存中的数据写到文件后就是StoreFile,StoreFile底层是以HFile的格式保存。
- 当storefile文件的数量增长到一定阈值后,系统会进行合并(minor、major compaction),在合并过程中会进行版本合并和删除工作(majar),形成更大的storefile
- 当一个region所有的storefile的大小和超过一定阈值后,会把当前的region分割为两个,并有hmaster分配到相应的regionserver服务器,实现负载均衡
- HFile:HBase中KeyValue数据的存储格式,是Hadoop的二进制格式文件。
- HLog:WAL log --- WAL意为write ahead log, 用来做灾难恢复使用,HLog记录数据的所有变更,一旦region server 宕机,就可以从log中进行恢复。