0.摘要
近期的研究在使用全卷积网络(FCN)框架改善像素级标注的空间分辨率方面取得了显著进展,通过采用扩张/空洞卷积、利用多尺度特征和细化边界等方法。本文通过引入上下文编码模块来探索全局上下文信息对语义分割的影响,该模块捕捉场景的语义上下文,并选择性地突出显示类别相关的特征图。所提出的上下文编码模块在几乎不增加额外计算成本的情况下显著改善了语义分割结果,我们的方法在PASCAL-Context数据集上取得了新的最先进结果,mIoU达到了51.7%,在PASCAL VOC 2012上达到了85.9%的mIoU。我们的单一模型在ADE20K测试集上取得了0.5567的最终得分,超过了COCO-Place Challenge 2017的获胜模型。此外,我们还探索了上下文编码模块如何改善相对较浅网络在CIFAR-10数据集上的图像分类的特征表示。我们的14层网络在错误率方面达到了3.45%,与拥有10倍以上层数的最先进方法相当。完整系统的源代码公开可用。
 图1:准确地为场景进行逐像素标注对于语义分割算法来说是一个挑战。即使对于人类来说,这个任务也很具有挑战性。然而,根据场景上下文缩小可能类别列表可以使标注变得更容易。受此启发,我们引入了上下文编码模块,该模块选择性地突出显示类别相关的特征图,使网络对语义分割的处理更加容易。(来自ADE20K数据集的示例。)
图1:准确地为场景进行逐像素标注对于语义分割算法来说是一个挑战。即使对于人类来说,这个任务也很具有挑战性。然而,根据场景上下文缩小可能类别列表可以使标注变得更容易。受此启发,我们引入了上下文编码模块,该模块选择性地突出显示类别相关的特征图,使网络对语义分割的处理更加容易。(来自ADE20K数据集的示例。)
1.引言
语义分割为给定的图像分配每个像素的对象类别预测,从而提供了包括对象类别、位置和形状信息在内的全面场景描述。最先进的语义分割方法通常基于全卷积网络(FCN)框架。深度卷积神经网络(CNN)的应用受益于从不同图像集中学习到的丰富的对象类别和场景语义信息。通过堆叠具有非线性和下采样的卷积层,CNN能够捕捉具有全局感知野的信息表示。为了解决与下采样相关的空间分辨率损失问题,近期的研究使用扩张/空洞卷积策略从预训练网络中产生密集的预测。然而,这种策略也会使像素与全局场景上下文相隔离,导致像素被错误分类。例如,在图4的第三行中,基线方法将一些窗玻璃像素错误分类为门。
最近的方法通过使用基于多分辨率金字塔表示的方法,扩大感受野,取得了最先进的性能。例如,PSPNet采用了空间金字塔池化,将特征图汇集到不同的尺寸并在上采样之后进行级联[57],而Deeplab提出了一种采用大空洞卷积的空洞空间金字塔池化方法[5]。虽然这些方法确实提高了性能,但上下文表示并不明确,这引出了一个问题:捕捉上下文信息与扩大感受野的大小是否相同?考虑对一个包含150个类别的大型数据集(如ADE20K [59])中的图像进行标注,如图1所示。假设我们有一个工具允许标注员首先选择图像的语义上下文(例如卧室)。然后,该工具可以提供一个更小的相关类别子列表(例如床、椅子等),这将大大减少可能类别的搜索空间。同样地,如果我们能设计一种方法充分利用场景上下文与类别概率之间的强相关性,那么对于网络来说,语义分割变得更容易。
经典的计算机视觉方法具有捕捉场景语义上下文的优势。对于给定输入图像,可以使用SIFT或滤波器响应密集提取手工设计的特征。然后,通常会学习视觉词汇(字典),并使用经典编码器(如词袋(BoW)、VLAD或Fisher Vector)描述全局特征统计信息。经典表示通过捕捉特征统计信息来编码全局上下文信息。虽然CNN方法极大地改进了手工设计的特征,但传统方法的整体编码过程便捷且强大。我们能否利用经典方法的上下文编码与深度学习的优势?最近的研究在CNN框架中广泛推广了传统编码器[1,56]。张等人引入了一个编码层,将整个字典学习和残差编码流程整合到单个CNN层中以捕捉无序表示。该方法在纹理分类方面取得了最先进的结果[56]。在这项工作中,我们扩展了编码层,以捕捉全局特征统计信息来理解语义上下文。
作为本文的第一个贡献,我们引入了一个上下文编码模块,其中包括语义编码损失(SE-loss),这是一个利用全局场景上下文信息的简单单元。上下文编码模块整合了一个编码层,以捕捉全局上下文,并选择性地突出显示与类别相关的特征图。为了理解,考虑到我们希望在室内场景中减弱车辆出现的概率。标准的训练过程只使用了每像素的分割损失,这并没有充分利用场景的全局上下文信息。我们引入了语义编码损失(SE-loss)来规范训练过程,让网络预测场景中物体类别的存在,以强制网络学习语义上下文。与每像素损失不同,SE-loss对大对象和小对象的贡献相等,并且我们发现在实践中小对象的性能通常会得到改善。所提出的上下文编码模块和语义编码损失在概念上非常直观,并且与现有的基于FCN的方法兼容。
本文的第二个贡献是设计和实现了一个新的语义分割框架Context Encoding Network (EncNet)。EncNet通过在预训练的Deep Residual Network (ResNet)[17]中加入一个Context Encoding Module来增强网络,如图2所示。我们使用预训练网络的扩张策略[4,52]。所提出的Context Encoding Network在PASCAL VOC 2012数据集上的mIoU达到了85.9%,在PASCAL in Context数据集上达到了51.7%。我们的EncNet-101单模型的得分为0.5567,超过了COCO-Place Challenge 2017 [59]的获奖作品。除了语义分割,我们还研究了Context Encoding Module在CIFAR-10数据集[28]上的视觉识别能力,通过使用所提出的Context Encoding Module显著改善了浅层网络的性能。我们的网络仅使用了3.5M个参数,错误率为3.96%。我们发布了完整的系统,包括最先进的方法,以及我们实现的同步多GPU批归一化[23]和内存高效的编码层[56]。
2.上下文编码模块
我们将CNN模块称为上下文编码模块,模块的组成部分如图2所示。
上下文编码:理解和利用上下文信息对于语义分割非常重要。对于在多样化图像集上预训练的网络[10],特征图编码了场景中的物体的丰富信息。我们使用编码层[56]来捕捉特征统计信息作为全局语义上下文。我们将编码层的输出称为编码语义。为了利用上下文,我们预测一组缩放因子,以选择性地突出显示与类相关的特征图。编码层学习了一个固有的字典,携带了数据集的语义上下文,并输出具有丰富上下文信息的残差编码器。为了完整起见,我们简要描述了编码层的先前工作。
编码层将形状为C×H×W的输入特征图视为一组具有C维输入特征的集合X={x1,...xN},其中N是由H×W给出的特征总数。编码层学习一个包含K个码字(视觉中心)的固有码本D={d1,...dK}和一组视觉中心的平滑因子S={s1,...sK}。编码层通过聚合带有软分配权重ek的残差输出残差编码器,其中ek=PNi=1eik,eik=exp(−skkrikk2)exp(−skkrikk2)PKj=1exp(−sjkrijk2)rik,(1),而残差由rik=xi−dk给出。我们对编码器进行聚合而不是连接。即e=PKk=1φ(ek),其中φ表示带有ReLU激活的批归一化,避免使K个独立编码器有序,并减少特征表示的维度。
特征图注意力 为了利用编码层捕捉到的编码语义信息,我们预测特征图的缩放因子作为反馈回路,以强调或减弱与类别相关的特征图。我们在编码层之上使用一个全连接层和一个sigmoid作为激活函数,输出预测的特征图缩放因子γ=δ(We),其中W表示层的权重,δ是sigmoid函数。然后,模块的输出由Y =X ⊗γ给出,其中 ⊗ 表示逐通道乘法,X表示输入特征图,γ表示缩放因子。这种反馈策略受到了风格转移[22,55]和最近的SE-Net[20]中调整特征图尺度或统计量的先前工作的启发。作为对该方法实用性的直观示例,考虑强调天空场景中飞机的概率,但减弱车辆的概率。
语义编码损失 在标准的语义分割训练过程中,网络是从孤立的像素(对于给定的输入图像和真实标签,使用像素级交叉熵损失)中学习的。网络可能在没有全局信息的情况下难以理解上下文。为了规范化上下文编码模块的训练,我们引入了语义编码损失(SE损失),它以非常小的额外计算成本迫使网络理解全局语义信息。我们在编码层之上构建了一个附加的全连接层,并使用sigmoid激活函数进行个别预测,以判断场景中是否存在对象类别,并使用二元交叉熵损失进行学习。与像素级损失不同,SE损失同等考虑大和小的对象。实际上,我们发现小物体的分割结果通常会得到改善。总之,图2所示的上下文编码模块捕获语义上下文,预测一组缩放因子,以选择性地突出显示与类别相关的特征图,用于语义分割。
 图2:所提出的EncNet的概述。给定一张输入图像,我们首先使用预训练的CNN提取密集的卷积特征图。我们在顶部构建了一个上下文编码模块,包括一个编码层,用于捕捉编码的语义信息并预测依赖于这些编码语义的缩放因子。这些学习到的因子有选择地突出显示与类别相关的特征图(用颜色可视化)。在另一个分支中,我们使用语义编码损失(SE损失)来规范训练,让上下文编码模块预测场景中是否存在某些类别。最后,上下文编码模块的表示被输入到最后一个卷积层中进行每个像素的预测。
图2:所提出的EncNet的概述。给定一张输入图像,我们首先使用预训练的CNN提取密集的卷积特征图。我们在顶部构建了一个上下文编码模块,包括一个编码层,用于捕捉编码的语义信息并预测依赖于这些编码语义的缩放因子。这些学习到的因子有选择地突出显示与类别相关的特征图(用颜色可视化)。在另一个分支中,我们使用语义编码损失(SE损失)来规范训练,让上下文编码模块预测场景中是否存在某些类别。最后,上下文编码模块的表示被输入到最后一个卷积层中进行每个像素的预测。
(符号说明:FC表示全连接层,Conv表示卷积层,Encode表示编码层[56],N表示通道间乘法)
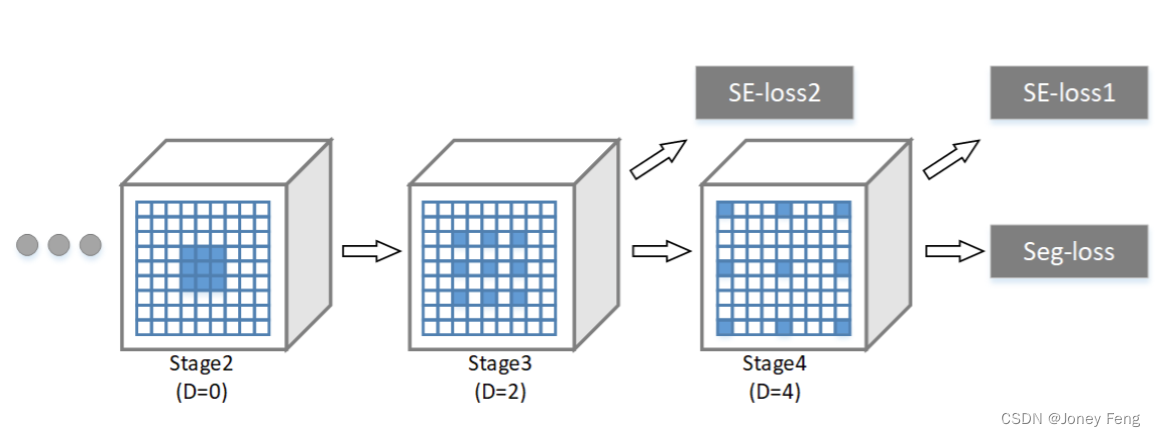 图3:扩张策略和损失。每个立方体代表不同的网络阶段。我们将扩张策略应用于第3和第4阶段。语义编码损失(SE损失)被添加到基础网络的第3和第4阶段。
图3:扩张策略和损失。每个立方体代表不同的网络阶段。我们将扩张策略应用于第3和第4阶段。语义编码损失(SE损失)被添加到基础网络的第3和第4阶段。
(D表示扩张率,Seg-loss表示每像素分割损失。)
2.1.上下文编码网络(EncNet)
通过所提出的上下文编码模块,我们使用预训练的ResNet [17]构建了一个上下文编码网络(EncNet)。我们按照之前的工作,在第3和第4阶段的预训练网络上使用了扩张网络策略[6,53,57],如图3所示。我们在最终预测之前的卷积层上构建了我们提出的上下文编码模块,如图2所示。为了进一步提高上下文编码模块的性能并规范化训练,我们建立了一个单独的分支来最小化SE损失,该分支以编码的语义信息为输入并预测对象类别的存在。由于上下文编码模块和SE损失非常轻量级,我们在第3阶段之上建立了另一个上下文编码模块,以最小化SE损失作为额外的正则化,类似于PSPNet [57]的辅助损失,但比较廉价。SE损失的地面真值直接从地面真实分割掩码中生成,无需任何额外的注释。我们的上下文编码模块可微分,并且在现有的FCN流程中插入,无需任何额外的训练监督或框架修改。在计算方面,所提出的EncNet对原始扩张FCN网络仅引入了边际的额外计算。
2.2.与其他方法的关系
在计算机视觉任务中,包括语义分割在内,卷积神经网络(CNN)已成为事实上的标准。早期的方法通过对区域提议进行分类来生成分割掩码[14,15]。全卷积神经网络(FCN)开创了端到端分割的时代[36]。
然而,由于使用了原本设计用于图像分类的预训练网络,从下采样的特征图中恢复细节信息是困难的。为了解决这个问题,
一种方法是学习上采样滤波器,即分数步卷积或解码器[3,40]。
另一种方法是在网络中采用Atrous/扩张卷积策略[4,52],该策略保留了较大的感受野并生成了密集的预测。
先前的工作采用密集条件随机场(CRF)来对FCN的输出进行细化分割边界[5,7],CRF RNN实现了与FCN的端到端CRF学习[58]。最近的基于FCN的工作通过使用更大率的扩张卷积或全局/金字塔池化来增加感受野,极大地提升了性能[6,34,57]。然而,这些策略不得不牺牲模型的效率,例如PSPNet [57]在金字塔池化和上采样之后对平面特征图应用卷积,DeepLab [5]采用了大率扩张卷积,在极端情况下会退化为1×1卷积。我们提出了上下文编码模块,以有效利用全局上下文进行语义分割,仅需要边际的额外计算成本。此外,所提出的上下文编码模块作为一个简单的CNN单元与所有现有的基于FCN的方法兼容。
通道级特征图注意力的策略受到一些开创性工作的启发。空间变换网络(Spatial Transformer Network)[24]学习了一个在输入条件下的网络内部变换,为特征图提供了空间注意力,无需额外的监督。批量归一化(Batch Normalization)[23]将数据的均值和方差规范化为网络的一部分,成功地允许更大的学习率,并使网络对初始化方法的敏感性降低。最近的风格迁移工作通过操作特征图的均值和方差[11,22]或二阶统计量,实现了网络内部的风格切换[55]。一个非常近期的工作SE-Net通过探索跨通道信息学习了通道级的注意力,在图像分类方面取得了最先进的性能[20]。受到这些方法的启发,我们使用编码的语义信息来预测特征图通道的缩放因子,这提供了一种机制,可以根据场景上下文强调或减弱单个特征图的显著性。
3.实验结果
在本节中,我们首先提供了EncNet和基线方法的实现细节,然后我们在Pascal-Context数据集[39]上进行了完整的消融研究,最后我们报告了在PASCAL VOC 2012 [12]和ADE20K [59]数据集上的性能。除了语义分割,我们还探讨了上下文编码模块如何提升在CIFAR-10数据集上浅层网络的图像分类性能(第3.5节)。
3.1.实现细节

图4:理解场景的上下文信息对于语义分割非常重要。例如,基线的FCN在不知道上下文的情况下将沙子分类为土地,如第一个例子所示。在第二和第四行中,很难区分建筑物、房屋和摩天大楼,没有语义信息。在第三个例子中,由于分类孤立的像素而没有全局感知/视角,FCN将窗玻璃识别为门。(来自ADE20K数据集的视觉示例。)
3.2.在PASCAL-Context数据集上的结果