01
背景
在微服务架构体系流行的当下,Spring Cloud全家桶已经是大多数团队的首选,我们也不例外,并且选择了Spring Cloud Gateway作为了业务网关,进行了一些通用能力的开发,如鉴权、路由等等。作为一个成熟的框架,我们已经使用了很长时间都没有出现问题,表现十分稳定。然而最近突然出现短时间内的5xx告警,起先没引起注意,认为是网络的问题,但是后来发现每隔一段时间(一两个星期),就会出现一次5xx的告警,而且会持续十几秒到半分钟之久。在经过排查之后,发现居然是logback日志产生了大量的FinalReference而导致了GC长时间停顿,那为什么logback的日志会产生大量FinalReference以及导致长达十多秒的gc停顿呢,本文对本次的排查过程以及涉及到技术知识进行详细的介绍。
02
问题排查
根据几次的观察,发现应该不是偶然现象,于是开始着手排查。首先看CPU和内存,发现CPU平稳,利用率在20%左右,可以排除因为流量原因导致CPU被打挂的可能了。但是,看到内存,有一个容器实例突然增高很多,于是开始怀疑是不是内存泄漏之类的问题,方向逐步往JVM方向排查。
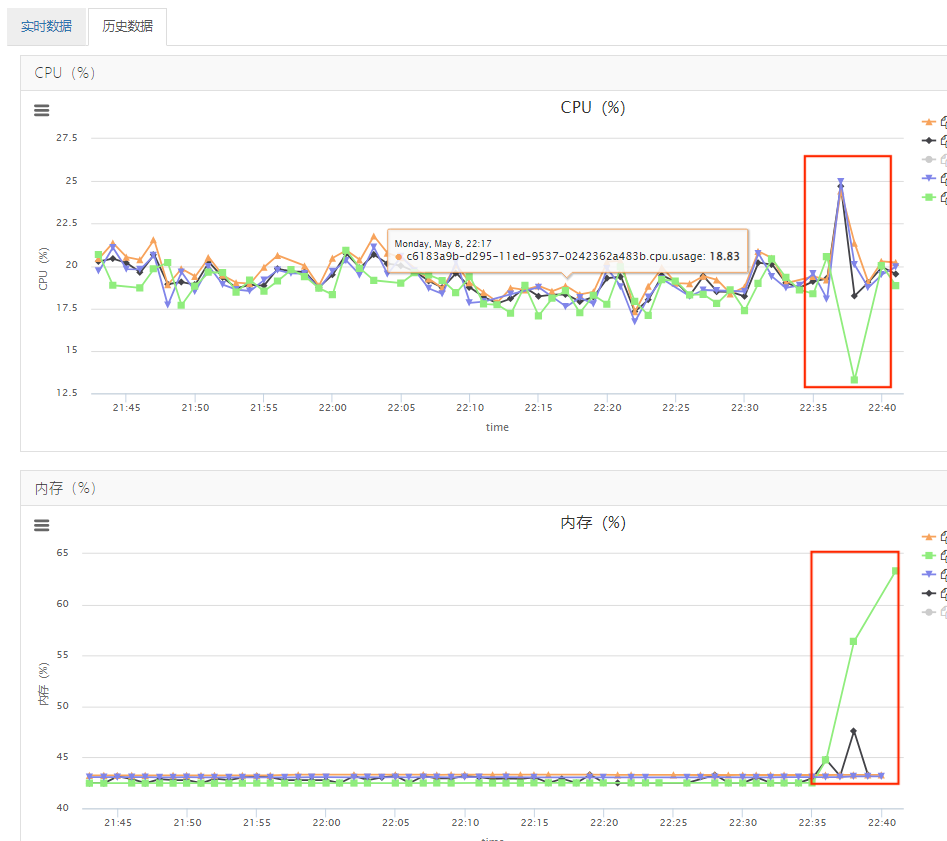
面对内存突然升高,朴素的想法是内存泄漏,因为SpringCloudGateway的底层用的是Netty,如果没有及时释放ByteBuf,则会造成内存泄露。由于,之前就遇到过类似的问题,在程序的某个路径下,因为修改了response但又未及时释放,导致了内存泄漏。所以,很自然地想到,是不是有类似的情况导致了没有及时释放内存。但是,在开启了-Dio.netty.leakDetection.level的日志后,发现并没有内存泄漏。
另外,如果是内存泄漏的话,程序通常是直接挂了然后重启,而不是半分钟之后又恢复了,且之后内存保持不动,又正常运行了。所以想到的另一种可能,是不是发生fullgc,导致长时间的停顿,使得服务不响应了。于是查看gc log,遗憾的是没有发现full gc的发生。但意外发现的是,在remark阶段耗时高达13秒。由于我们用的是G1GC,所以remark阶段会进行STW,导致程序被卡了13秒之久,进而产生了大量的5xx。基本可以定位问题是发生在了remark阶段的长时间停顿,那到底是什么造成了remark阶段耗时这么久呢?
虽然remark阶段主要做的事情是最终标记(并发标记后最后再标记一次),但这个阶段也会附加一个reference的处理,叫ref-proc。通过添加-XX:+PrintReferenceGC and -XX:+PrintGCDetail后,可以看到remark阶段的详细日志,如下:
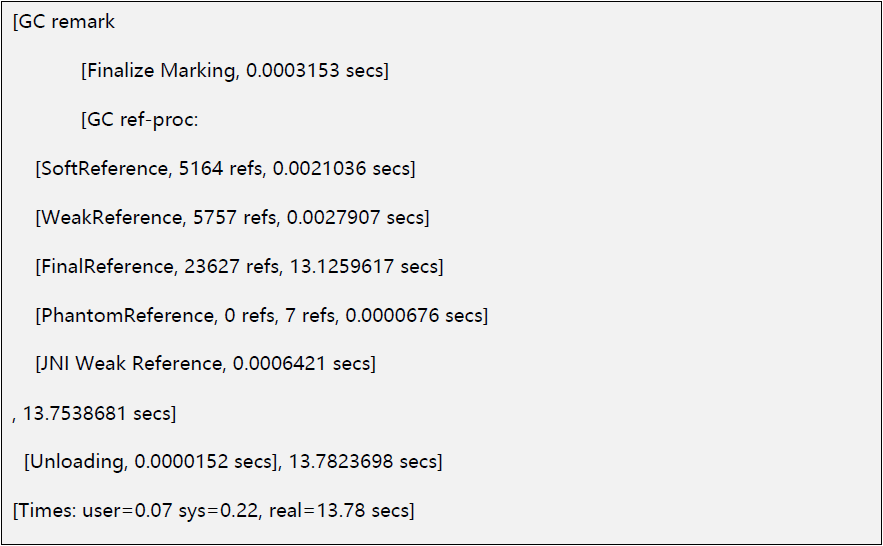
可以看到,最终标记Finalize Marking才花了0.0003153秒,真正耗时的是ref-proc,耗时主要发生在FinalReference,花了13.1秒多,看到数量也是惊人的2.3万多的reference。
03
调优
治标缓解
找到原因之后,剩下的就是如何调优了,由于耗时是发生在remark的ref-proc这个阶段,主要有两个方向:1. 如何加快处理速度,缩减耗时 2. 如何减少FinalReference的数量。
通过查阅资料,发现可以通过增加-XX:+ParallelRefProcEnabled参数来加速reference的处理,其原理是通过增加处理的线程来并行处理,默认是串行的,只有一个线程处理,而启动并行处理后,就会按cpu数量来创建线程数进行并行处理,即采用了ParallelGCThreads的线程数。
关于ParallelGCThreads的线程数,可以通过 -XX:ParallelGCThreads=n来指定,或者采用默认值。默认情况下,当 CPU 数量小于8, ParallelGCThreads 的值等于 CPU 数量,当 CPU 数量大于 8 时,则使用公式:ParallelGCThreads = 8 + ((N - 8) * 5/8) = 3 +((5*CPU)/ 8),即对于超过8的cpu数量,选用5/8的比例。其源码如下:

因此,可以通过启用-XX:+ParallelRefProcEnabled来加速ref-proc的处理速度。
但这种方式,只是治标并不治本,只是通过消耗更多的cpu资源来加快处理速度。特别是,我们的容器配置是2核4G的低配实例,即使开启了并行处理,也只是多了一个线程,减少耗时的程度有限,只能缓解问题,但并未根治。为此,只能向第二个方向发力,就是如何减少FinalReference的数量,或者说是什么原因产生了如此多的FinalReference。
我们知道,产生FinalReference的唯一方法就是一个class实现了finalize()方法,那到底是人为的误用实现了finalize()方法,还是引入了有问题的库导致的,为此我们需要dump一份jvm内存来一探究竟。
治本探索
为此,可以通过jmap来对内存进行dump。一开始,我们只对存活对象进行dump,即命令如下:jmap -dump:live,format=b,file=heapdump.phrof pid(注意:在dump live的时候,会触发fullgc,所以在生产环境中慎用)

利用Java官方的VisualVM查看dump文件发现,其FinalReference的数量并不多,虽然有很多重复的JarFileWrapper,但类比其他服务的,看起来属于正常的情况。关于JarFileWrapper,其实是SpringBoot的一个bug,其官方已经在新版本修复,点击可跳转相关内容。虽然这是一个bug,但并不是引起本次问题的元凶。
考虑到FinalReference在remark阶段是有两万多的,而这次却只有两千多,数量上差距很多,因此想到一个可能,是不是有很多FinalReference在dump的时候就被gc回收了。为此,再对程序来了一次全量的dump。
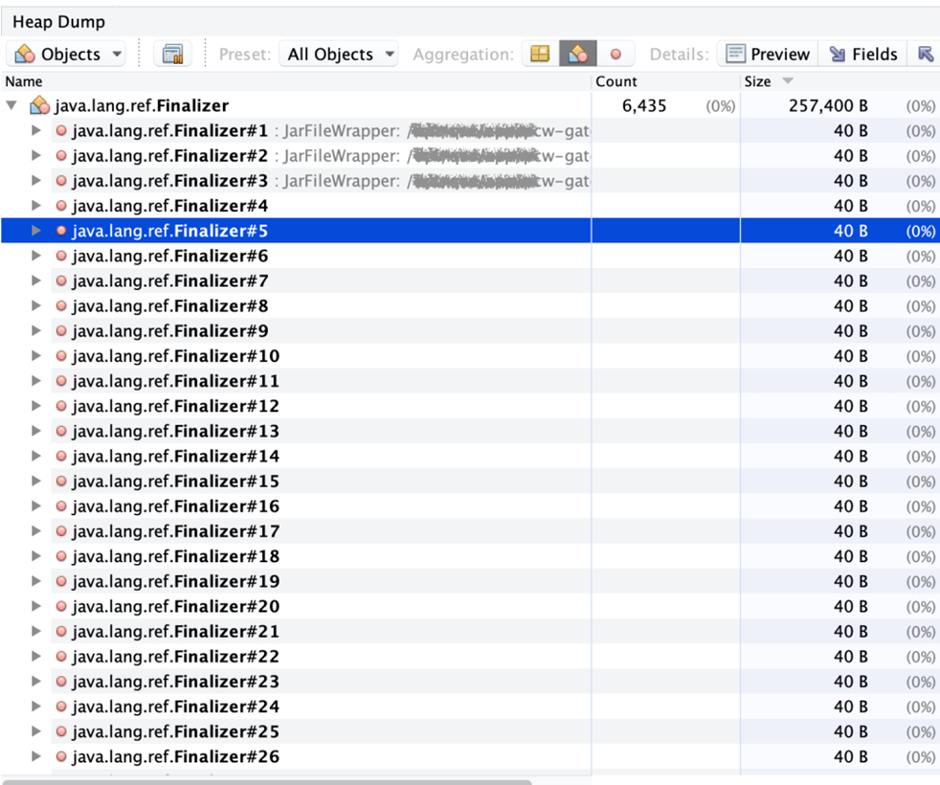
发现果然多了很多Finalizer,有六千多。但仔细对比发现,多出来的Finalizer,都是没有引用对象的(referent为null),即这些Reference的引用对象早就被垃圾回收了。这个时候就会有个疑问,难道是这些已经失去引用对象的Reference造成了gc时ref-proc耗时过长?要回答这个问题,就需要我们去深入了解jvm在gc时,到底是怎么处理Reference的。
04
Reference的处理过程
先来回顾下,Reference类的生命周期,如从new SoftReference(obj)开始,对于FinalReference,则只需要new实现了finalize()方法的class,jvm内部会实现类似new FinalReference(obj)的操作。对于一个Reference,会经历active -> pending -> enqueued -> inactive这些状态。
其大致的流程如下:
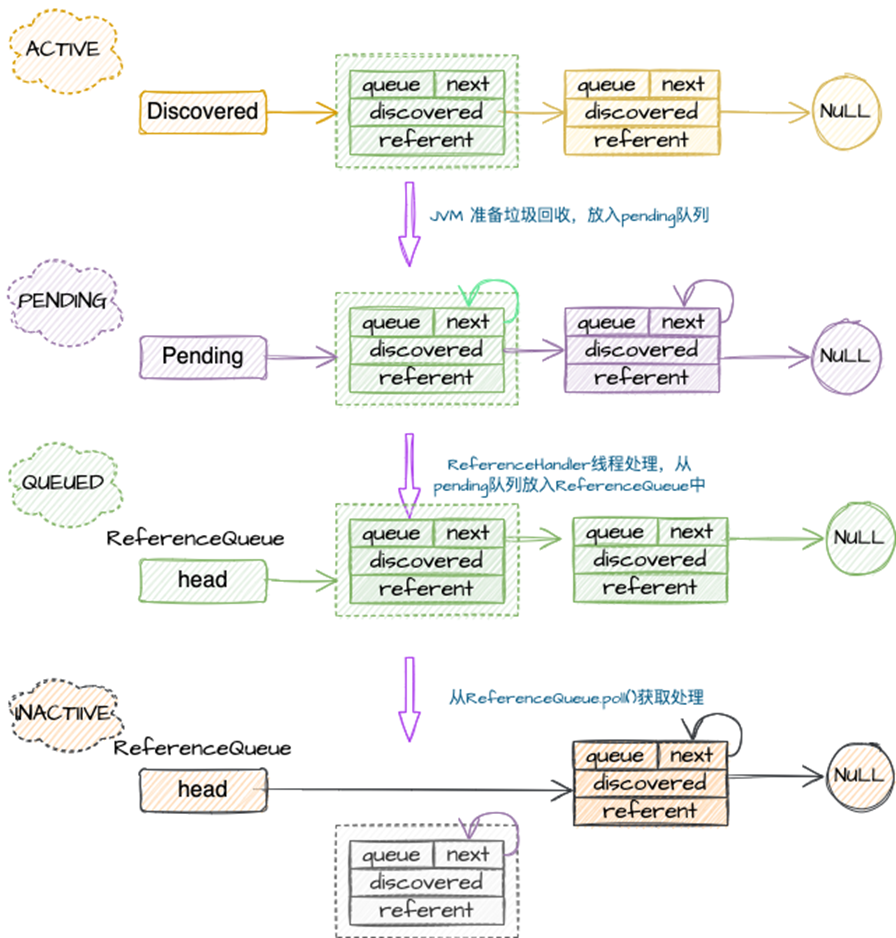
从图中可以看到,整个过程有三个队列:discovered队列、pending队列、ReferenceQueue队列,当对象进入pending队列后,后续流程则进入应用程序阶段,即可以通过ReferenceHandler来进行实现特殊功能,具体可以参考ReferenceHandler#tryHandlePendingx0;方法。而进入pending之前的阶段,也就是从对象生成new之后,到进入discovered队列以及到pending队列,这些都是由JVM来完成的,而GC的ref-proc正是工作在这个阶段。
Reference在JVM中的执行步骤大致如下(点击可跳转相关源码):
GC标记时,对Reference对象进行判断,调用discover_reference方法,如果是active,则加入discoveredList队列;
遍历discoveredList队列,调用process_discovered_references方法,对每一个Reference进行处理,如果引用的referent仍然是存活的,则踢出队列中;剩下的,根据Reference类型执行对应的操作(例如对于SoftReference进行保活操作);
在process阶段之后,会进入enqueue阶段,即调用enqueue_discovered_references方法,将上一步过滤完之后的discoveredList队列中的Reference实例加入到pending队列中(pending队列是由Reference静态属性pending和实例属性discovered构成的一个链表)。同时更新Reference实例的next属性指向它自己,即将Reference实例标记成Pending状态。这个过程,即是所谓的enque阶段,注意这里enque的队列并不是ReferenceQueue,而是pending队列;
然后是由ReferenceHandler这个backgroud线程不断的从pending队列中将实例取出并放入ReferenceQueue中,并将实例属性discovered置为null,即处于enqueued状态;
最后,由应用程序从ReferenceQueue中获取实例,进行处理,此时会将实例的next属性置为null,即inactive状态,参见ReferenceQueue#reallyPollx0;的方法。
至此,我们可以根据Reference实例的discovered和next属性值来确定所属状态。
Active: discovered == null
Pending: discovered != null
Queued: next != null && next != this && discovered == null
Inactive: next == this && discovered == null
另外,可以看到,这五个步骤中,其中第一步发生在gc标记的时期,第四、第五步发生在用户程序阶段,只有第二、第三步才是gc阶段JVM做的事情,也就是ref-proc阶段的操作。
至此,我们看到那些referent已经为空的Finalizer,其实都是Inactive的状态了。也就是说,这些Finalizer是不会进入当前ref-proc阶段的,它们应该是上一次gc ref-proc之后被加入到pending队列后,最终处理完并成为Inactive的。
在通过对ref-proc阶段的深入了解后,可以发现,一定是存在着两万多个active状态的Finalizer,导致了remark时候ref-proc耗时过长。那到底是什么样的class产生了如此多的Fianlizer?要想知道具体的实例情况,只能通过dump去分析。由于是时隔一两个星期才会出现一次,所以想要抓到有分析价值的dump也很难。在历经长时间多次的dump之后,通过将跨度一两个星期的dump文件进行对比,终于发现了端倪。
05
拨云见日
在通过对比前后两星期的dump文件发现,随着程序的运行,越来越多的FileOutputStream出现,而这些都是用来打日志的,并且都是同名的日志文件出现了几千次。这么对比下来,基本可以确定原因了,但是FileOutStream是java基础库的类,按道理不应该会出现问题才对。

首先,看了下FileOutputStream的源码,的确是实现了finalize()方法,所以被Finalizer引用很正常。
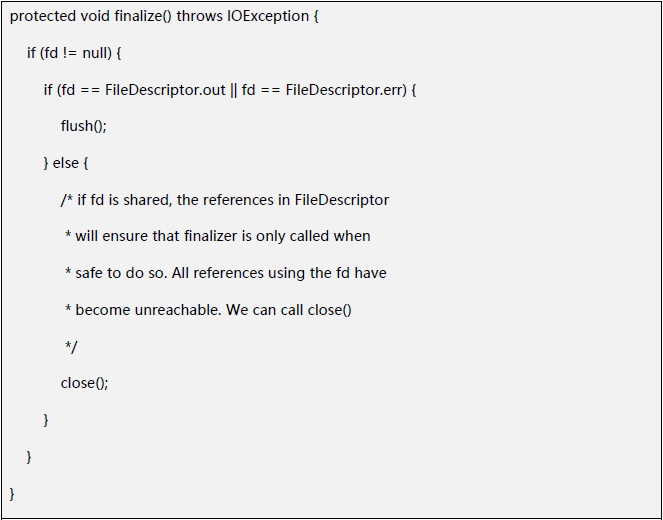
其finalize()作用就是防止文件没有被正常关闭就被回收了,这是finalize()方法的一个典型用法,看起来一切都挺正常的。
因此,为了确信的确是由FileOutputStream引起大量的FinalReference,通过写一个小程序来模拟:
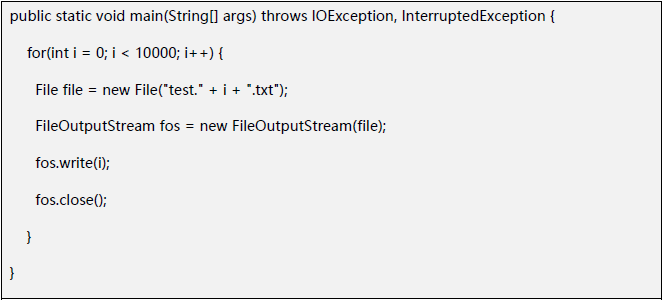 然后查看gc日志,发现是的确能产生这么多FinalReference的:
然后查看gc日志,发现是的确能产生这么多FinalReference的: 在确定是FileOutputStream产生大量FinalReference后,接下来就是确认是谁创造了这么多的FileOutputStream,通过dump文件里的引用关系,发现FileOutputStream的创建都来自于ResilientFileOutputStream,它是logback的一个类。
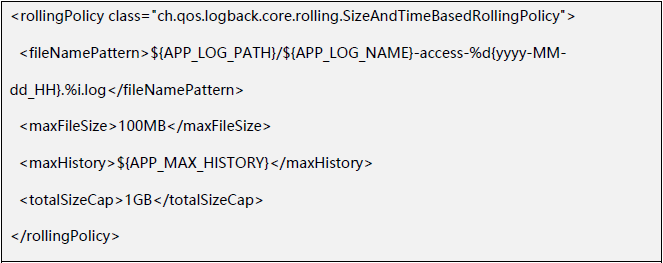
在确定是FileOutputStream产生大量FinalReference后,接下来就是确认是谁创造了这么多的FileOutputStream,通过dump文件里的引用关系,发现FileOutputStream的创建都来自于ResilientFileOutputStream,它是logback的一个类。 而ResilientFileOutputStream的创建也只来自于一个地方,就是每次创建新的日志文件的时候才会生成新的ResilientFileOutputStream。也就是有一个日志文件才会有一个FileOutputStream,那是不是我们有特别多的日志文件呢?查看容器实例,发现的确会打印出大量的日志文件,几乎一个小时就有十几个文件,在查看下logback的配置xml,发现目前的配置是每100M一个文件,所以会产生很多FileOutputStream是可以解释的。
而ResilientFileOutputStream的创建也只来自于一个地方,就是每次创建新的日志文件的时候才会生成新的ResilientFileOutputStream。也就是有一个日志文件才会有一个FileOutputStream,那是不是我们有特别多的日志文件呢?查看容器实例,发现的确会打印出大量的日志文件,几乎一个小时就有十几个文件,在查看下logback的配置xml,发现目前的配置是每100M一个文件,所以会产生很多FileOutputStream是可以解释的。
 那最后还有一个困扰的问题,假设一个小时有15个日志文件,一天24小时,也就360个文件,总共有三种日志类型,相当于一天近一千个日志文件。那为什么会有两万多个FinalReference呢?这里我们通过查看gc日志,发现两个星期里只做了一次老年代的mixed gc,也就是这些FinalReference一直没有被回收,存在了两个星期后,才触发了一次mixed gc,才导致了一次性回收这么多的FinalReference。
那最后还有一个困扰的问题,假设一个小时有15个日志文件,一天24小时,也就360个文件,总共有三种日志类型,相当于一天近一千个日志文件。那为什么会有两万多个FinalReference呢?这里我们通过查看gc日志,发现两个星期里只做了一次老年代的mixed gc,也就是这些FinalReference一直没有被回收,存在了两个星期后,才触发了一次mixed gc,才导致了一次性回收这么多的FinalReference。
经过这么看,一下子全解释通了,所有的程序都没有问题,只是由于老年代mixed gc长时间才做一次,导致了reference的大量堆积。这的确也是一个新的现象,因为一般都认为老年代gc做的越少,java的gc效果越好,但没想到过长时间不做老年代gc竟然会引发reference的问题。
关于为什么会这么长时间才做老年代gc,主要原因是因为Spring Cloud Gateway是作为业务网关的,所以没有太复杂的逻辑,创建的对象都是朝生夕死的,直接都在年轻代gc就被回收了。另外,Spring Cloud Gateway的基础是Netty,Netty是在堆外内存创建Request和Response,这样也减少了堆内垃圾的产生(作为网关,很多时候的对象就只是对request和response的操作)。另一方面,目前运行的程序中有一项参数-XX:InitiatingHeapOccupancyPercent=55比默认值是45稍微高了些,这也进一步降低了老年代的回收频次。
注:InitiatingHeapOccupancyPercent是触发老年代mixed gc的阈值,其含义是当老年代的内存占比超过整个堆的数量时,则触发mixed gc。
在解释完上面所有的情景之后,优化的措施也就浮出水面,我们通过增大单个日志的体积来降低产生日志的分片数,进而降低FinalReference的数量,同时打开-XX:+ParallelRefProcEnabled,加快回收速度。另外由于老年代gc出发频率实在太低,我们也降低了XX:InitiatingHeapOccupancyPercent的值,让其触发老年代gc的频次快一些,这样积累的reference数量就会少很多。
06
总结
本文对Spring Cloud Gateway应用过程中遇到的remark阶段由于大量FinalReference导致的长时间停顿进行了详细的分析。其主要优化的难点主要在于对java reference不够熟悉,特别是jvm底层对reference的操作,即ref-proc阶段具体的过程,导致分析的时候会产生很多障碍。另外,也是从本次问题中,了解到了两个非直观的经验:
少用finalize,即使是正确的用法(如FileOutputStream),也可能会导致FinalReference过多,引发ref-proc阶段的长时间停顿
老年代gc不是触发频次越少越好,也需要控制在适当范围内,过长时间不触发,会导致“重型回收对象”大量堆积,导致单次gc时间过长。
参考资料
[1]https://zhuanlan.zhihu.com/p/540796318
[2]https://zhuanlan.zhihu.com/p/165285835
[3]https://juejin.cn/post/6942026483489734693
[4]https://zhuanlan.zhihu.com/p/371985669
[5]https://www.cnblogs.com/mazhimazhi/p/13503800.html
[6]https://blog.csdn.net/qq_31865983/article/details/104070299[7]https://hg.openjdk.org/jdk8u/jdk8u/hotspot/file/b44df6c5942c/src/share/vm/memory/referenceProcessor.cpp#l892
[8]https://github.com/spring-projects/spring-boot/issues/28042

也许你还想看
爱奇艺海外版HTTPS效率提升的探索和实践
爱奇艺海外运营系统的设计和实践
爱奇艺数据湖实战