目录
一、HBase基本概述
1、Hbase是什么
2、什么时候用Hbase?
二、HBase基本架构
1、Client
2、Zookeeper
3、HMaster
4、 RegionServer
三、HBase逻辑结构
一、HBase基本概述
1、Hbase是什么
HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
2、什么时候用Hbase?
Hbase不适合解决所有的问题:
- 首先数据库量要足够多,如果有十亿及百亿行数据,那么Hbase是一个很好的选项,如果只有几百万行甚至不到的数据量,RDBMS是一个很好的选择。因为数据量小的话,真正能工作的机器量少,剩余的机器都处于空闲的状态
- 其次,如果你不需要辅助索引,静态类型的列,事务等特性,一个已经用RDBMS的系统想要切换到Hbase,则需要重新设计系统。
- 最后,保证硬件资源足够,每个HDFS集群在少于5个节点的时候,都不能表现的很好。因为HDFS默认的复制数量是3,再加上一个NameNode。
Hbase在单机环境也能运行,但是请在开发环境的时候使用。
二、HBase基本架构
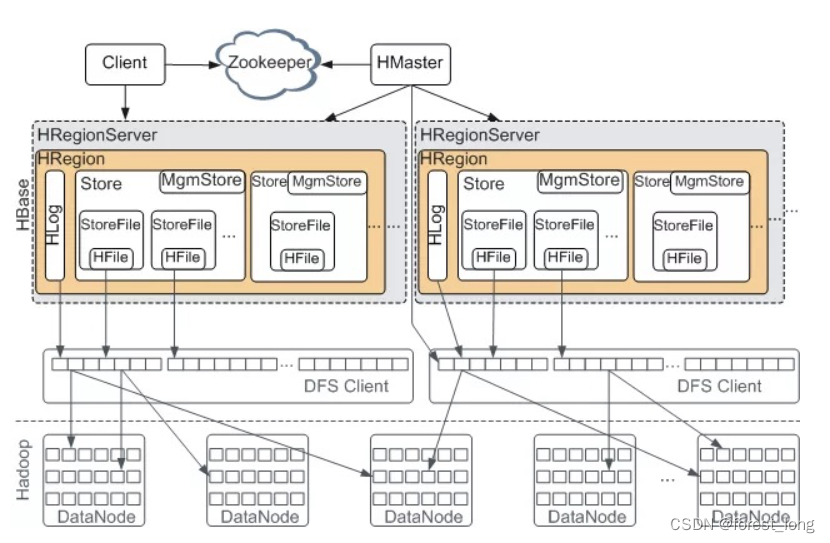
1、Client
包含访问HBase的接口,维护着一些Cache来加快对HBase的访问,比如缓存regione的位置信息等;
2、Zookeeper
保证任何时候,集群中只有一个master;存贮所有Region的寻址入口Root Region的位置;实时监控Region Server的状态,将Region server的上线和下线信息实时通知给Master;存储Hbase的schema,包括有哪些table,每个table有哪些column family;
3、HMaster
主要负责Region的分配与重分配;RegionServer的负载均衡;处理Schema更新(新建表、修改表结构等)的请求等;不参与HBase的读写数据过程;
4、 RegionServer
一个RegionServer对应一个节点,Regionserver是调度者,维护多个Region,处理对这些Region的IO,负责切分在运行过程中变得过大的Region,一个Region只能属于一个Regionserver,Regionserver可以自动调整Region所在的服务器;底层数据是持久化在HDFS上的;
三、HBase逻辑结构
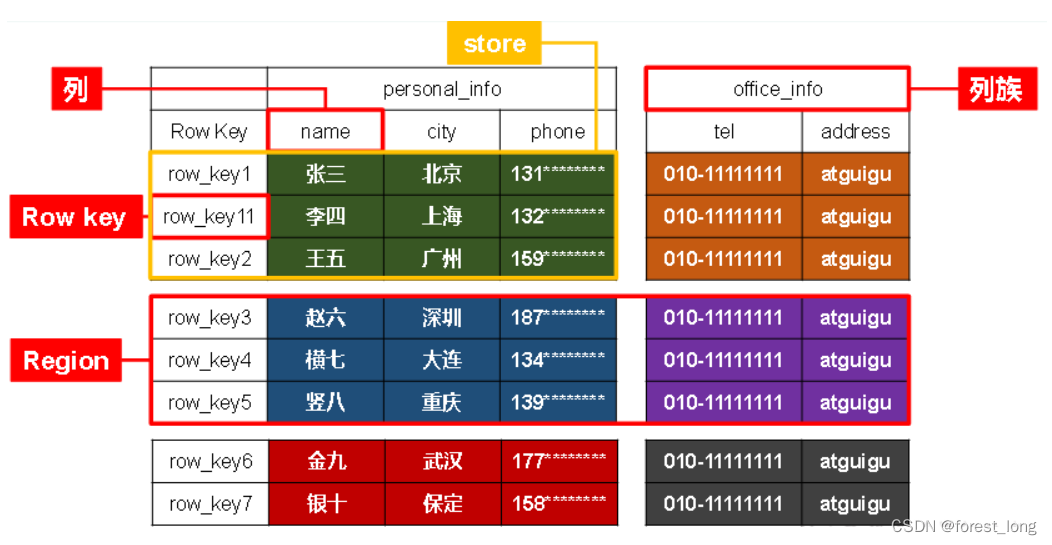
逻辑结构:HBase切两刀
一刀:根据RowKey横着切,得到一个个Region
二刀:根据列族竖着切,得到一个个Store
明确:
region存在同一个机器-->hdfs上对应一个文件夹
store存在同一个文件-->对应一个文件夹(嵌套在Region下的文件夹)-->数据就存到store这个文件夹里边