pstore简介
pstore最初是用于系统发生oops或panic时,自动保存内核log buffer中的日志。不过在当前内核版本中,其已经支持了更多的功能,如保存console日志、ftrace消息和用户空间日志。同时,它还支持将这些消息保存在不同的存储设备中,如内存、块设备或mtd设备。 为了提高灵活性和可扩展性,pstore将以上功能分别抽象为前端和后端,其中像dmesg、console等为pstore提供数据的模块称为前端,而内存设备、块设备等用于存储数据的模块称为后端,pstore core则分别为它们提供相关的注册接口。
通过模块化的设计,实现了前端和后端的解耦,因此若某些模块需要利用pstore保存信息,就可以方便地向pstore添加新的前端。而若需要将pstore数据保存到新的存储设备上,也可以通过向其添加后端设备的方式完成。
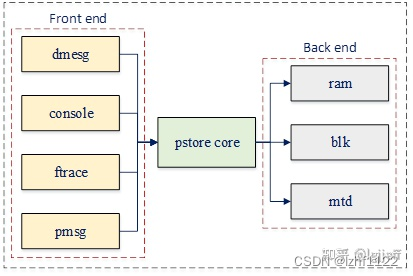
除此之外,pstore还设计了一套pstore文件系统,用于查询和操作上一次重启时已经保存的pstore数据。当该文件系统被挂载时,保存在backend中的数据将被读取到pstore fs中,并以文件的形式显示。
代码实现
pstore初始化流程
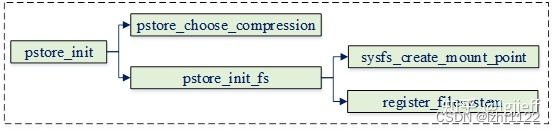
pstore初始化主要是为其指定压缩算法,以及初始化pstore文件系统,其流程如下:
若存储空间比较有限,可以将pstore的内容压缩后再保存到backend设备上,相应的压缩算法可以通过配置选项CONFIG_PSTORE_COMPRESS_DEFAULT或模块参数compress指定。当前支持的压缩算法如下:
static const struct pstore_zbackend zbackends[] = {
#if IS_ENABLED(CONFIG_PSTORE_DEFLATE_COMPRESS)
{
.zbufsize = zbufsize_deflate,
.name = "deflate",
},
#endif
#if IS_ENABLED(CONFIG_PSTORE_LZO_COMPRESS)
{
.zbufsize = zbufsize_lzo,
.name = "lzo",
},
#endif
#if IS_ENABLED(CONFIG_PSTORE_LZ4_COMPRESS)
{
.zbufsize = zbufsize_lz4,
.name = "lz4",
},
#endif
#if IS_ENABLED(CONFIG_PSTORE_LZ4HC_COMPRESS)
{
.zbufsize = zbufsize_lz4,
.name = "lz4hc",
},
#endif
#if IS_ENABLED(CONFIG_PSTORE_842_COMPRESS)
{
.zbufsize = zbufsize_842,
.name = "842",
},
#endif
#if IS_ENABLED(CONFIG_PSTORE_ZSTD_COMPRESS)
{
.zbufsize = zbufsize_zstd,
.name = "zstd",
},
#endif
{ }
}
pstore_init_fs用于初始化pstore文件系统,其代码如下:
int __init pstore_init_fs(void)
{
…
err = sysfs_create_mount_point(fs_kobj, "pstore"); (1)
…
err = register_filesystem(&pstore_fs_type); (2)
…
}
(1)在/sys/fs目录下为其创建挂载点pstore
(2)向内核注册pstore文件系统
在pstore文件系统挂载时会调用pstore_fs_type的mount回调,它会执行挂载相关的操作,其流程如下:
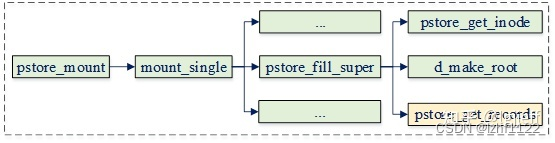
其中pstore文件系统需要实现自身的超级块填充函数pstore_fill_super,它主要为其设置inode和file相关的操作函数,并且将上一次重启时已保存在pstore backend设备中的pstore信息读取出来,并加入文件系统中。其主要实现如下:
void pstore_get_backend_records(struct pstore_info *psi,
struct dentry *root, int quiet)
{
…
if (psi->open && psi->open(psi)) (1)
goto out;
for (; stop_loop; stop_loop--) {
…
pstore_record_init(record, psi);
record->size = psi->read(record); (2)
…
decompress_record(record); (3)
rc = pstore_mkfile(root, record); (4)
…
}
if (psi->close)
psi->close(psi);
…
}
(1)打开pstore backend设备
(2)从backend设备中逐条读取pstore record信息
(3)若使用了压缩算法,则需要将数据解压缩
(4)根据recored的内容,为其在pstore文件系统中创建一个文件。此后,用户就可以通过文件查询相关消息了
pstore backend注册流程
pstore core通过pstore_info结构体来描述一个pstore后端,该结构体主要包含了后端设备相关的信息,以及相关的操作函数,其定义如下:
struct pstore_info {
struct module *owner;
const char *name; (1)
struct semaphore buf_lock;
char *buf; (2)
size_t bufsize;
struct mutex read_mutex;
int flags; (3)
int max_reason; (4)
void *data; (5)
int (*open)(struct pstore_info *psi); (6)
int (*close)(struct pstore_info *psi);
ssize_t (*read)(struct pstore_record *record);
int (*write)(struct pstore_record *record);
int (*write_user)(struct pstore_record *record,
const char __user *buf);
int (*erase)(struct pstore_record *record);
}
(1)后端设备的名字
(2)buf用于保存实际的消息
(3)flag用于表示消息的类型,其定义如下:
#define PSTORE_FLAGS_DMESG BIT(0)
#define PSTORE_FLAGS_CONSOLE BIT(1)
#define PSTORE_FLAGS_FTRACE BIT(2)
#define PSTORE_FLAGS_PMSG BIT(3)
(4)该参数只有前端为DMESG时才有效,用于控制哪些消息允许被dump到pstore中。只有dump reason小于等于该值的消息才会被dump,其reason取值如下:
enum kmsg_dump_reason {
KMSG_DUMP_UNDEF,
KMSG_DUMP_PANIC,
KMSG_DUMP_OOPS,
KMSG_DUMP_EMERG,
KMSG_DUMP_SHUTDOWN,
KMSG_DUMP_MAX
}
(5)后端设备的私有数据,可由回调函数传回
(6)后端设备相关的回调函数,如open和close用于打开和关闭设备,read、write用于读写pstore recored数据。write_user也用于向后端写入recored,但是其buffer为用户态地址,erase用于删除一个指定的recored
后端设备首先需要构造一个pstore_info结构体,然后调用pstore_register函数将其注册到pstore core中。以ram后端为例,其注册流程如下:
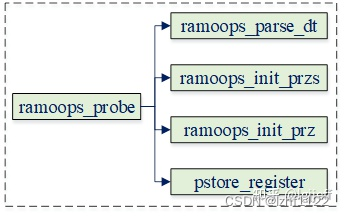
其中后端的配置信息可通过dts配置,如ramoops使用的内存地址、长度、recored长度等,ramoops_parse_dt用于解析dts中的相关信息。由于pstore可以包含多个前端,因此后端设备需要根据前端类型进行分区,ramoops_init_przs和ramoops_init_prz就是用于执行相关的分区操作。
pstore_register用于执行实际的注册工作,它的主要工作为校验输入参数是否合法,以及根据配置参数,注册相应的前端,其主要代码如下(去除了参数校验等部分):
int pstore_register(struct pstore_info *psi)
{
…
if (psi->flags & PSTORE_FLAGS_DMESG)
allocate_buf_for_compression(); (1)
pstore_get_records(0); (2)
if (psi->flags & PSTORE_FLAGS_DMESG) {
pstore_dumper.max_reason = psinfo->max_reason;
pstore_register_kmsg(); (3)
}
if (psi->flags & PSTORE_FLAGS_CONSOLE)
pstore_register_console();
if (psi->flags & PSTORE_FLAGS_FTRACE)
pstore_register_ftrace();
if (psi->flags & PSTORE_FLAGS_PMSG)
pstore_register_pmsg();
…
}
(1)若为pstore设置了压缩功能,则为其分配压缩时使用的内存
(2)从backend中读取上次重启时已保存的pstore recored,并为其建立相应的文件
(3)根据flags的值,注册相应的pstore前端
pstore frontend注册流程
pstore前端主要工作包含两部分,何时触发pstore写操作,以及需要向pstore写入什么内容,下面以dmesg前端为例,简要介绍一下其实现。
printk实现了一个kmsg_dump函数,用于方便其它模块dump内核的log buffer,当内核发生oops、panic或重启等事件时,都会调用该函数dump log信息。其代码实现如下
void kmsg_dump(enum kmsg_dump_reason reason)
{
…
list_for_each_entry_rcu(dumper, &dump_list, list) { (1)
enum kmsg_dump_reason max_reason = dumper->max_reason;
if (max_reason == KMSG_DUMP_UNDEF) {
max_reason = always_kmsg_dump ? KMSG_DUMP_MAX :
KMSG_DUMP_OOPS;
}
if (reason > max_reason) (2)
continue;
dumper->dump(dumper, reason); (3)
}
rcu_read_unlock();
}
(1)遍历dump_list链表中的所有的dumper,并对它们分别执行如下log dump操作
(2)根据dumper的max_reason值,确定是否需要向其dump log
(3)若需要dump,则调用该dumper的dump回调,执行实际的dump操作
因此pstore前端只需将自身注册到dump_list链表中即可,该操作由以下函数实现:
int kmsg_dump_register(struct kmsg_dumper *dumper)
{
…
if (!dumper->registered) {
dumper->registered = 1;
list_add_tail_rcu(&dumper->list, &dump_list);
err = 0;
}
…
}
其中dmesg前端的主要工作就是为其实现一个dump函数,该函数将从log buffer中读取lou信息,然后将其封装为recored之后写入对应的后端设备,其主要定义如下:
static struct kmsg_dumper pstore_dumper = {
.dump = pstore_dump,
}
static void pstore_dump(struct kmsg_dumper *dumper,
enum kmsg_dump_reason reason)
{
…
while (total < kmsg_bytes) {
…
pstore_record_init(&record, psinfo); (1)
…
header_size = snprintf(dst, dst_size, "%s#%d Part%u\n", why,
oopscount, part); (2)
dst_size -= header_size;
if (!kmsg_dump_get_buffer(&iter, true, dst + header_size,
dst_size, &dump_size)) (3)
break;
if (big_oops_buf) {
zipped_len = pstore_compress(dst, psinfo->buf,
header_size + dump_size,
psinfo->bufsize); (4)
…
} else {
record.size = header_size + dump_size;
}
ret = psinfo->write(&record); (5)
…
}
…
}
(1)初始化一个record结构体
(2)先向其写入pstore头信息,如dmesg reason、oops发生次数等
(3)从log buffer中读取一行log信息
(4)若需要压缩信息,则执行压缩操作
(5)调用后端的写函数,将record写入相应的后端设备
pstore配置和使用
pstore使用主要包含以下四个步骤:
(1)通过配置内核参数,使能pstore功能。由于dmesg前端是默认使能的,因此若以ramoops为后端,且使能所有前端为例,则其相应的配置参数如下:
CONFIG_PSTORE=y
CONFIG_PSTORE_RAM=y
CONFIG_PSTORE_PMSG=y
CONFIG_PSTORE_FTRACE=y
CONFIG_PSTORE_CONSOLE=y
(2)配置devicetree,为后端设备设置相关参数。以ramoops为例,pstore使用的内存需要被添加到reserved内存中,以下为其中的一个示例:
reserved-memory {
#address-cells = <2>;
#size-cells = <2>;
ranges;
ramoops@21f00000 {
compatible = "ramoops";
reg = <0x0 0x21f00000 0x0 0x00100000>;
record-size = <0x00020000>;
console-size = <0x00020000>;
ftrace-size = <0x00020000>;
};
};
(3)挂载pstore文件系统,由于其挂载点为/sys/fs/pstore,因此相应的挂载操作如下:
mount -t pstore pstore /sys/fs/pstore
(4)挂载完成后,若后端中已经保存了先前的pstore消息,则可在/sys/fs/pstore目录下查看到对应的文件。用户可对该文件执行读取,删除等操作
参考: 内核崩溃日志抓取pstore