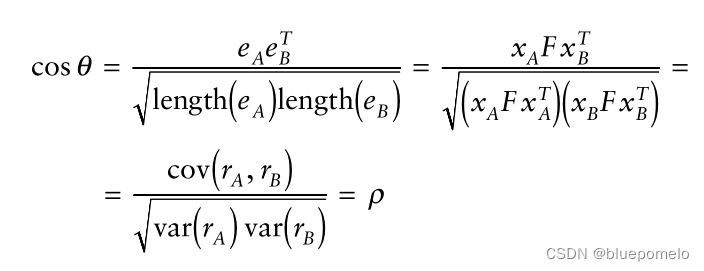案例介绍
本案例使用口罩识别推理程序作为例子进行演示,硬件平台是华为昇腾310设备(Ascend 310),该口罩识别使用目标检测中SSD模型,检测的结果有两个类别:戴口罩的脸、没带口罩的脸。成功执行推理程序后我们对其进行了推理调优,使推理过程速度加快。
代码、模型、数据的下载链接:
https://github.com/1051003502/msprofiler_mask_detection
包含的主要内容:推理程序源码、原始模型文件、后处理开源代码、待推理的图片。
本教程的视频讲解链接:https://www.bilibili.com/video/BV1Kd4y1x7M2
环境准备
Windows端
MindStudio 官网:https://www.hiascend.com/software/mindstudio
推理服务器
硬件平台:Ascend 310 arm64架构
操作系统:Ubuntu 18.04.6 LTS
软件包:
Ascend-cann-toolkit_5.1.RC2_linux-aarch64.run
下载:https://www.hiascend.com/software/cann/community
Ascend-mindxsdk-mxvision_3.0.RC2_linux-aarch64.run:
下载:https://www.hiascend.com/zh/software/mindx-sdk/mxVision/commercial
A300-3000-npu-driver_21.0.4.8_linux-aarch64.run:
下载:https://www.hiascend.com/hardware/firmware-drivers?tag=community
A300-3000-npu-firmware_1.80.22.5.220.run:
下载:https://www.hiascend.com/hardware/firmware-drivers?tag=community
请参考昇腾软件快速部署指南:
https://www.hiascend.com/document/detail/zh/quick-installation/22.0.RC2/quickinstg/300T_9000/300T_9000_00001.html
python环境配置
下载python3.9.12并安装
wget https://www.python.org/ftp/python/3.9.12/Python-3.9.12.tgz
tar -zxvf Python-3.9.12.tgz
cd Python-3.9.12
./configure --prefix={install_python_path} --enable-loadable-sqlite-extensions --enable-shared
make -j32
make install
cp {install_python_path}/lib/libpython3.9.so.1.0 /usr/lib
cp {install_python_path}/lib/libpython3.9.so.1.0 /usr/lib64
alias python3.9={install_python_path}/bin/python3.9
alias pip3.9={install_python_path}/bin/pip3.9
安装依赖的python包
pip3.9 install opencv-python
pip3.9 install google
pip3.9 install protobuf==3.19
Ascend APP项目创建
简介
MindStudio是华为开发的AI一站式开发环境,这里我们主要用到了代码编辑、代码上传下载、SSH远程连接功能。MindStudio在Windows上安装非常简单,大家请参照官网教程。
项目创建

可以点击菜单栏Open创建

或者直接将文件夹拖入桌面MindStudio图标。
SSH配置

左上角File->Settings

搜索ssh找到SSH Configurations ->点击加号输入推理服务器IP、端口、用户名、密码,可以点击Save password(保存后就不用重复输入密码了)。最后点击OK。

小提示:这里可以点击Test Connection按钮,测试SSH连接是否正常。

菜单栏点击Tools->Start SSH session

点击对应的服务器,就打开了一个SSH session。

可以在下面的界面中输入命令,操作服务器。
转换为昇腾项目
说明:项目必须是一个昇腾项目才能使用菜单栏Ascend中的功能

转换步骤

菜单栏Ascend->Convert To Ascend Project

然后依次选择Ascend App、Ascend ACL App,等待重新启动后完成创建

在设置界面设置服务器CANN路径,按照自己安装的CANN路径选择,最后需要选择到5.1.RC1(这个名字和安装的CANN版本相同,点击OK后,需要等待一段时间完成CANN同步。
部署配置

Tools->Deployment->Configuration
点击加号新增一个


选择刚才配置的SSH,这个配置好是通用的。

Deployment path根据服务器情况自由选择即可。

鼠标放在文件夹上点击右键,选择Deployment->Upload to...

再点击我们配置好的Deployment,就把文件同步到服务器端了

可以在Remote Terminal查看文件,看到确实上传至服务器了。
pb转离线模型
命令行方式

编辑切换为居中
添加图片注释,不超过 140 字(可选)
在facemaskdetection/models目录下运行:
atc --model=./face_mask_detection.pb --framework=3 --output=./facemask --output_type=FP32 --soc_version=Ascend310 --input_shape="data_1:1,260,260,3" --input_format=NHWC --insert_op_conf=./face_mask.aippconfig --fusion_switch_file=./fusion_switch.cfg
face_mask_detection.pb是TensorFlow训练后的模型文件。我们这一步将这个模型转为了能在昇腾AI处理器上高效执行的模型。运行之后在当前目录下生成了facemask.om,这个就是稍后我们用到的模型。
--model 指定要转换的pb文件,在models目录下面有下载好的face_mask_detection.pb 文件
--output 指定输出的om文件名字,会自动生成.om后缀。这个可以随意命名。
--output_type 建议指定为“FP32”
--soc_version指定昇腾芯片型号。
--input_shape 指定输入的尺寸
--input_format=NHWC 输入数据格式。
--insert_op_conf 指定配置aipp的配置文件,用于在AI Core上完成数据预处理,在models文件夹下有配置文件face_mask.aippconfig,参数具体含义可参考昇腾CANN文档
https://www.hiascend.com/document/detail/zh/canncommercial/51RC1/overview/index.html
--fusion_switch_file 模型融合配置文件
可视化方式
我们也可以选择使用MindStudio提供的Model Converter来进行模型转换,操作上会简单一些。

菜单栏Ascend->Model Converter

Model File 原始模型文件,选择face_mask_detection.pb
Model Name 转换后的模型名字
Target SoC version 按照服务器来选择
Output Path 转换后模型输出路径,选择的是本地路径
Input Format 输入数据的格式
data_1 输入数据的形状、类型,按照图上所示设置

数据预处理,与命令行一样,这里我们通过AIPP文件来设置。选择服务器models文件夹中自带的face_mask.aippconfig文件即可。
点击Next

这里我们可以设置算子融合、额外参数、环境变量等。
我们打开Additional Arguments,填入
--fusion_switch_file=/home/shandongdaxue/workspace/facemaskdetection/models/fusion_switch.cfg
下面的Command Preview是自动生成的命令,也就是将要执行的命令,基本与我们之前的一致。
--insert_op_conf路径与上一步设置的不一样,这是因为软件会自动提取AIPP文件里面的数据,生成这个文件,也就是说这个文件与我们的models/face_mask.aippconfig内容一样。
最后点击Finish,等待一段时间即可完成模型转换。
最后日志如果输出Model converted successfully. 代表转换成功了。

说明
当前昇腾AI处理器以及昇腾AI软件栈无法直接拿常用开源框架网络模型(如Caffe,TensorFlow等)来进行推理。如果想要进行推理则需要做一步模型转换的操作,也就是把开源框架的网络模型转换成Davinci架构专用的模型。而此处模型转换的步骤就是通过ATC工具完成的。
昇腾张量编译器(Ascend Tensor Compiler,简称ATC)是昇腾CANN架构体系下的模型转换工具。它可以将开源框架的网络模型(如Caffe、TensorFlow等)以及Ascend IR定义的单算子描述文件转换为昇腾AI处理器支持的离线模型。
模型转换过程中,ATC会进行算子调度优化、权重数据重排、内存使用优化等具体操作,对原始的深度学习模型进行进一步的调优,从而满足部署场景下的高性能需求,使其能够在昇腾AI处理器上高效执行。ATC工具功能架构如下图所示。

代码讲解
推理代码核心讲解
detect_image.py

streamManagerApi = StreamManagerApi() 该类用于对流程的基本管理,包括加载流程配置、创建流程、向流程上发送数据、获得执行结果。

CreateMultipleStreamsFromFile 根据指定的配置文件创建多个Stream。

MxDataInput Stream 接收的数据结构定义。

SendData 向指定Stream上的输入元件发送数据(appsrc)。阻塞式,不支持多线程并发。

GetProtobuf 获得Stream上的输出元件(appsink)的protobuf数据后处理过程。
数据采集接口讲解
detect_image.py
当用户需要定位应用程序或上层框架程序的性能瓶颈时,可在Profiling采集进程内(acl.prof.start接口、acl.prof.stop接口之间)调用Profiling pyACL API扩展接口(统称为msproftx功能),开启记录应用程序执行期间特定事件发生的时间跨度,并将数据写入Profiling数据文件,再使用Profiling工具解析该文件,并导出展示性能分析数据。
Profiling pyACL API:将采集到的Profiling数据写入文件,再使用Profiling工具解析该文件,并展现性能分析数据。
在推理代码基础上新增部分代码,帮助我们分析推理过程。涉及的函数如下:
import acl 导入acl模块。
acl.prof.create_stamp() 创建msproftx事件标记。
后续调用函数 mark、set_stamp_trace_message、push、range_start接口时,需要以描述该事件的指针作为输入,表示记录该事件发生的时间跨度。同步接口。
acl.prof.set_stamp_trace_message(stamp, stampMsg, msgLen) 为msproftx事件标记携带字符串描述,在Profiling中解析并导出结果中msprof_tx summary数据展示。同步接口。

acl.prof.push 和 acl.prof.pop 接口配对使用,完成单线程采集
ret = acl.prof.push(stamp)
ret = acl.prof.pop()
msproftx用于记录事件发生的时间跨度的开始时间。同步接口。调用此接口后,Profiling自动在Stamp指针中记录开始的时间戳,将Event type设置为Push/Pop。
push、pop接口:成对使用,表示时间跨度的开始和结束。

ret = acl.prof.mark(stamp)
msproftx标记瞬时事件。同步接口。 调用此接口后,Profiling自动在Stamp指针中加上当前时间戳,将 Event type设置为Mark,表示开始一次msproftx采集。
详细可参考以下链接:
https://www.hiascend.com/document/detail/zh/canncommercial/51RC1/openform/devgopen/atlasprofiling_16_0024.html
运行
步骤一:main.pipeline文件修改

修改main.pipeline中模型路径modelPath,使用推理服务器中绝对路径,文件就是上一步生成的离线模型facemask.om
步骤二:detect_image.py文件修改

修改pipeline_path,使用绝对路径
步骤三:推理命令
按照上述步骤修改路径后,上传至推理服务器。

右键选择整个项目文件,也可以选择单个文件,Deployment->Upload to

再点击我们配置好的Deployment,就把文件同步到服务器端了
然后运行下面的命令

运行命令
/home/shandongdaxue/workspace/python3.9.12/bin/python3.9 detect_image.py image/demo1.jpg
在当前目录下就会生成my_result.jpg

调优
简介
目的:优化推理程序性能。
如何判断推理程序是否需要进行性能优化:
1、相同的模型在不用的硬件平台上跑出的性能数据不同,比如一个模型在GPU上跑推理耗时10ms,在NPU上跑耗时15ms,这个时候就可以考虑使用msprofiler进行性能调优了。
2、追求极致,释放软硬件的澎湃性能,比如一个模型在NPU上跑耗时20ms,但随着应用场景的发展,性能无法满足业务诉求,需要将模型耗时优化到15ms或者要达到更高的性能10ms等等。
Profiling数据采集命令

Profiling数据采集的目的是通过数据分析出执行推理或训练过程中软件硬件的性能瓶颈。命令如下(注意路径全部使用绝对路径):
/home/shandongdaxue/Ascend/ascend-toolkit/5.1.RC1/tools/profiler/bin/msprof --application="/home/shandongdaxue/workspace/python3.9.12/bin/python3.9 /home/shandongdaxue/workspace/facemaskdetection/detect_image.py /home/shandongdaxue/workspace/facemaskdetection/image/demo1.jpg" --msproftx=on --output=./profiling-data/
参数介绍
msprof 命令使用绝对路径,替换为自己服务器相应的CANN安装目录。
--application 配置为运行环境上AI任务文件,写入之前的推理命令
--msproftx 控制msproftx用户和上层框架程序输出性能数据的开关,可选on或off,默认值为off。之前我们调用了acl.prof相关Profiling AscendCL API扩展接口,所以这里选择on。
--output 收集到的Profiling数据的存放路径

等待一段时间后,终端输出Process profiling data complete. Data is saved in XXX。并且在目录下面生成了profiling-data目录,证明运行成功。
msprof命令可以采集推理程序的Profiling性能数据,使用该方式采集并解析Profiling数据需确保应用工程或算子工程所在运行环境已安装Ascend-cann-toolkit开发套件包。
命令行格式如下: ./msprof --application=<app> --output=<dir>
执行完上述命令后,会在--output目录下生成PROFXXX目录,PROFXXX目录保存Device侧或Host侧的原始Profiling数据以及timeline汇总数据。
更多细节请参考CANN文档:
https://support.huawei.com/enterprise/zh/doc/EDOC1100234052/2cda32a0
数据解析
根据以下命令可得出智能调优建议:
/home/shandongdaxue/workspace/python3.9.12/bin/python3.9 /home/shandongdaxue/Ascend/ascend-toolkit/5.1.RC1/tools/profiler/profiler_tool/analysis/msprof/msprof.py export summary -dir ./profiling-data/PROF_000001_20221114202456824_ILOFOEMKALLAEGCB/ --format csv
说明
在执行完导出summary数据命令“python3 msprof.py export summary -dir xxx”后,会在屏幕打印相关性能调优建议
-dir 指定数据采集的文件
--format 格式
运行结果见下图:


运行结果摘要:please check and reduce the transData
《性能调优建议》文档链接:
https://www.hiascend.com/document/detail/zh/canncommercial/51RC1/openform/devgopen/atlasprofiling_16_0045.html
查询文档可知,基于整网性能数据transData算子数量优化建议的原则:(1)存在transData算子,且数量超过设定的阈值(2)需检查是否有使用transData算子的必要性。
经过检查后,这里的transData算子是必要的,无法优化。
timeline/msprof_0_1_1.json 数据说明
将服务器端./profiling-data下载到Windows端,按照下面的路径找到msprof_0_1_1.json文件,这个json文件记录着我们的推理程序执行过程中各个组件的运行时间。
profiling-data/PROF_000001_20221114202456824_ILOFOEMKALLAEGCB/timeline/msprof_0_1_1.json
数据可视化:使用谷歌浏览器打开内置网页chrome://tracing/
将json文件拖进去或者是点击load加载文件,就可以看到如下图所示的页面

有些部分耗时短,可视化后的图块小,需要界面缩放平移:
WS按键放大缩小,AD按键左右平移;
或者点击右侧的箭头,鼠标拖拉也可以控制。
数据介绍
各个组件的耗时数据说明:

默认会显示所有组件耗时情况,一行就是一个组件的耗时情况,也可以选择只显示部分组件

MsprofTx: msprof tool extension,MindStudio系统调优工具扩展。
我们调用pyACL接口(例如acl.prof.push(stamp))会在MsprofTx显示采集的数据。
AscendCL: AscendCL接口耗时情况,这个是系统自动采集的数据。
Task Scheduler: 推理代码耗时情况,主要涉及到模型内部算子调用。
分析性能数据
步骤一


从timeline图中可以看到,CreateMultipleStreamsFromFile这段耗时比较长,这段耗时有5,645.052 ms,很不正常,这块是通过msproftx进行打点输出的,见detect_image.py的如下代码

通过排查代码看到,在增加性能调试代码的时候增加了sleep(5)的代码,可以删除此sleep代码,性能可以提升5s,然后我们重新导出数据看下结果


时间变为了642.772ms,与我们之前分析的一致
步骤二

编辑切换为居中
添加图片注释,不超过 140 字(可选)
通过msproftx定位出的性能问题优化后是否还有可以优化的空间,需要继续进行分析,通过分析acl接口调用耗时,可以看到aclmdlLoadFromFileWithMem和aclmdlExecute接口耗时比较长,aclmdlLoadFromFileWithMem这个接口是从文件加载离线模型,涉及文件IO操作,耗时理论上会相对较长,所以重点分析aclmdlExecute接口耗时情况

aclmdlExecute接口耗时7.209ms,这个接口主要耗时是算子在aicore上运行,可以分析om模型和算子耗时表(device_0\summary\op_statistic_0_1_1.csv)进行深入调优,见下图:

通过分析算子统计表,可以看到算子耗时最长的是Conv2D和BNInferenceD。除此之外,我们也可以通过om模型进行查看。
om模型可视化

在左边找到.om结尾的模型文件,然后双击一下,等待一会,就可视化出了模型图。

可以看出来模型中有很多的Conv2D、BNInferenceD、Relu算子,所以我们可以考虑融合为一个算子,提高推理速度。
修改图融合配置文件,打开算子融合规则,重新生成离线模型,命令如下
atc --model=./face_mask_detection.pb --framework=3 --output=./facemask_fusion_11-5 --output_type=FP32 --soc_version=Ascend310 --input_shape="data_1:1,260,260,3" --input_format=NHWC --insert_op_conf=./face_mask.aippconfig --fusion_switch_file=./fusion_switch_new.cfg
如果使用可视化方法生成模型,只需要按照下图修改fusion_switch_file,其他步骤不变。

融合后的模型图见下图:

融合后的算子耗时表见下图:



融合前的推理执行时间7.209ms,融合后推理执行时间2.305ms,时间减少了4.904ms,效率提升了68%
算子融合原理
算子融合是整网性能提升的一种关键手段,包括图融合和UB融合。
图融合是FE根据融合规则进行改图的过程。图融合用融合后算子替换图中融合前算子,提升计算效率。图融合的场景如下:
在某一些算子的数学计算量可以进行优化的情况下,可以进行图融合,融合后可以节省计算时间。例如:conv+biasAdd,可以融合成一个算子,直接在l0c中完成累加,从而省去add的计算过程。
在融合后的计算过程可以通过硬件指令加速的情况下,可以进行图融合,融合后能够加速。例如:conv+biasAdd的累加过程,就是通过l0c中的累加功能进行加速的,可以通过图融合完成。
UB即昇腾AI处理器上的Unified Buffer,UB融合是对图上算子进行硬件UB相关的融合。例如两个算子单独运行时,算子1的计算结果在UB上,需要搬移到DDR。算子2再执行时,需要将算子1的输出由DDR再搬移到UB,进行算子2的计算逻辑,计算完之后,又从UB搬移回DDR。
从这个过程会发现1的结果从UB->DDR->UB->DDR。这个经过DDR进行数据搬移的过程是浪费的,因此将1和2算子合并成一个算子,融合后算子1的数据直接保留在UB,算子2从UB直接获取数据进行算子2的计算,节省了一次输出DDR和一次输入DDR,省去了数据搬移的时间,提高运算效率,有效降低带宽。
总结
我们使用一个口罩识别模型,演示了如何在华为昇腾310设备上推理,演示了如何使用msprof命令采集性能数据,并且通过分析性能数据减少了推理过程花费的时间。
如果大家在使用中遇到问题,可以登录昇腾论坛寻求专家帮助: https://bbs.huaweicloud.com/forum/forum-945-1.html 也可以在这里分享使用感受,一起交流、一起进步。
FAQ
1 [ERROR]Apppath(/home/name/workspace/facemaskdetection/python3.9) is soft link, not support! 解决:msprof命令中全部需要使用绝对路径。
2 无root权限时加动态库搜索路径:
(1)临时增加动态库搜索路径: 命令行输入 export LD_LIBRARY_PATH={install_python_path}/lib/:$LD_LIBRARY_PATH
(2)永久设置(对当前用户有效):
修改~/.bashrc
末尾新增
export LD_LIBRARY_PATH={install_python_path}/lib/:$LD_LIBRARY_PATH
3 [ERROR] App path(/home/shandongdaxue/python3) is soft link, not support!
使用msprof命令时,python3必须使用绝对路径。
/home/shandongdaxue/Ascend/ascend-toolkit/5.1.RC1/tools/profiler/bin/msprof --application="python3 /home/shandongdaxue/workspace/facemaskdetection/detect_image.py /home/shandongdaxue/workspace/facemaskdetection/image/demo1.jpg" --msproftx=on --output=./profiling-data/
说明:此命令错误
/home/shandongdaxue/Ascend/ascend-toolkit/5.1.RC1/tools/profiler/bin/msprof --application="/home/shandongdaxue/workspace/python3.9.12/bin/python3.9 /home/shandongdaxue/workspace/facemaskdetection/detect_image.py /home/shandongdaxue/workspace/facemaskdetection/image/demo1.jpg" --msproftx=on --output=./profiling-data/
说明:替换为绝对路径后命令可正常运行
4 E10001: Value [-1] for [data_1] is invalid. Reason: maybe you should set input_shape to specify its shape.

解决方法:

在Data Pre-Processing中要打开Input Node设置。