近期,关于 ChatGPT 的访问量有所下降的消息引发激烈讨论,不过这并不意味着开发者对于 AIGC 的热情有所减弱,例如素有【2023 最潮大语言模型 Web 开发框架】之称的大网红 LangChain 的热度就只增不减。
原因在于 LangChain 作为大模型能力“B2B2C”的一个重要的中间站,能够将大模型和其他项目丝滑连接在一起,达到 1 + 1 大于 3 的效果。
正如大家所知,AIGC 时代,提高大模型应用性能的一个关键手段就是将大语言模型(LLM)和外部数据相结合。具体而言就是在 LLM 中接入现成的数据集,并要求 AI 应用能够记住用户的对话,通过“反思”对话上下文生成“新记忆”。当用户在 AI 应用中进行检索时,应用系统会先在接入的现成数据集中提取相关信息,然后结合用户查询以及记忆的上下文,最终高效准确地返回检索结果,LangChain + Milvus 就是其中最好的应用。
为了帮开发者深入理解使用 LangChain 和 Milvus 进行语义搜索的原理及实例,Zilliz 联动 LangChain 进行了一次干货满满的直播讨论,LangChain 联合创始人兼首席执行官 Harrison Chase 对话 Zilliz 软件工程师 Filip Haltmayer ,共同探讨如何使用 LangChain 和向量数据库进行语义搜索以及在此过程中可能会遇到的一些典型案例。

01.
什么是检索?
检索是指从内存或其他存储设备中获取信息的过程。那么,如何利用检索技术、向量数据库(如:Milvus)、AI 代理(如:LangChain)搭建一个接入外部知识库的 LLM 应用?
Harrison 表示,尽管 LLM 功能强大,但在使用上还存在一些限制,比如 LLM 只能记住预先训练时的信息。这就意味着,LLM 并不能够做到实时更新数据信息。举个例子,ChatGPT 的数据仅涵盖 2021 年及以前的数据,因此 ChatGPT 无法回答 2021 年之后的信息。除此之外,LLM 还缺乏特定领域的专业信息(如:业务相关的特定数据)。在此情况下,检索技术能够作为一种补充形式,帮助我们打破 LLM 本身的使用限制。换言之,检索技术能够为 LLM 应用提供更多信息上下文,从而帮助 LLM 返回更准确的答案。
02.
语义搜索——检索技术的主流用例
检索技术的主流用例之一就是语义搜索。Harrison 解释了语义搜索如何在 CVP 架构(ChatGPT + Vector Database + Prompt)中发挥作用。
下图展示了语义搜索在 CVP 技术栈中的作用。如果用户提出了一个一般问题且 LLM 可以回答,那么 LLM 会直接返回问题的答案。但是,如果用户提出的问题是特定领域的专业问题,那么这个问题会被转化为向量并被发送到如 Milvus 之类的向量数据库。而向量数据库中已经预先存储了一些专业文档片段的 embedding 向量。当用户专业问题向量被发送到向量数据库后,会在数据库中进行相似性搜索,以找到 “top-k” 个最相关的结果。这些找到的结果会与用户查询的问题一同经过 AI 代理 (如:LangChain)的处理合并发送到 LLM。最终 LLM 返回令人满意的响应结果。
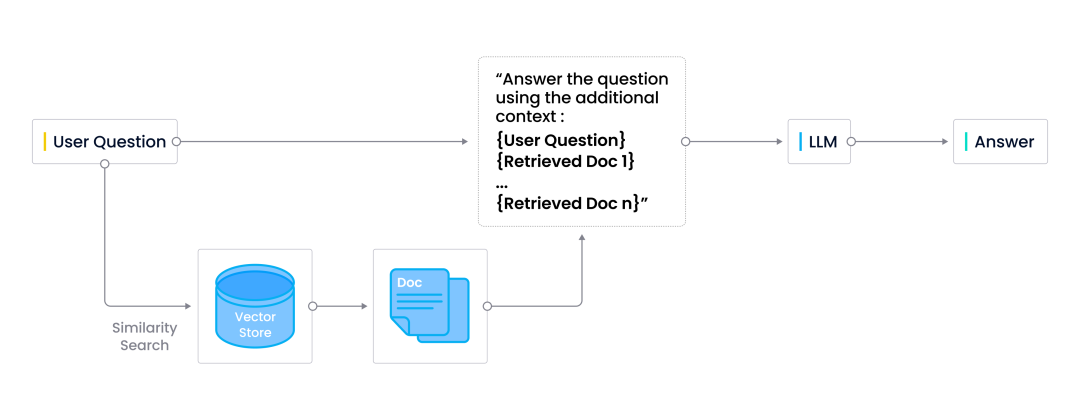
|CVP 技术栈中的语义搜索
03.
语义搜索的典型案例
语义搜索十分常用且能够有效解决多种 LLM 应用的问题。Harrison 列举了 5 个语义搜索的典型案例,并详细分析了每种情况:
重复信息
如果数据库中存有许多重复文档,检索信息会面临一些挑战。这些重复的内容其实不适用于 LLM,会产生很多不必要的上下文。
对于这个问题, Harrison 提出了以下 3 种解决方案:
通过语义搜索过滤掉类似的文档。例如在将提示发送到 ChatGPT 之前,LangChain 会检索 20-30 个相似文档,并通过向量检索技术过滤掉或者绕过重复文本,再将提示发送到 ChatGPT。
利用最大边际相关算法来优化多样性。此搜索侧重于从其他检索到的向量中获取相似和多样的结果。
在存储之前对文档进行去重。但是,这种方法挑战性最大,因为需要大量时间和精力来确定一个相似性分数,用于判定文档是否重复。即便设置了一个相似性分数,它也未必十分准确,因为单个事物的单个向量维度差异巨大,分数稍有偏差,结果就会大相径庭。
冲突信息
如果对于同一个问题,不同来源的数据给出不同的回答,则会导致信息冲突。如果将这些数据据全部都给到 LLM,可能会导致 LLM 混乱。
例如,用户想要通过 LLM 应用查询公司休假政策,而人力资源文件和一些临时会议记录给出了不同的答案。
对于这种情况,Harrison 提出了以下 2 种解决方案:
对来源进行优先级排序,并将优先级打分权重加入到检索中。
将所有源信息都传入生成步骤,交由 LLM 来判断哪个信息源更可靠。
时效性
信息需要不断更新,保证信息的时效性。例如,公司的休假政策可能会偶尔更新,那 LLM 应用需要能够确保给到用户更新后的正确信息。
对于这种情况,Harrison 提出了以下 3 种解决方案:
在检索中进行对最近的信息进行加权——完全过滤过时的信息。
给生成信息带上时间戳——要求 LLM 优先选择更近期的信息。
不断反思,即不断修订 LLM 对一个话题的理解。
元数据查询
某些情况下,用户提出的问题更侧重于元数据信息而非内容本身。
例如,用户可能会查询“1980年间关于外星人的电影”。其中,“关于外星人的电影”这一部分可以进行语义搜索,而”1980 年间“其实是需要通过精确匹配来筛选结果的。
对于这种情况,Harrison 建议在执行语义搜索检索之前先加入一个元数据过滤器。这样一来,当用户查询”1980年间关于外星人的电影“时,其实会分为两个步骤:
元数据过滤器:通过精确匹配,先筛选出年份为 1980 年的电影。
语义搜索:查询筛选结果中”关于外星人“的电影。
许多向量存储器都允许在查询前先通过元数据过滤器筛选数据。如果大家选择的向量存储器不支持在查询前进行元数据过滤,那么在语义搜索之后再过滤数据也是一个可行的方案。
多跳问题
用户可能会一次提出多个问题,这会给语义搜索带来挑战。对于这种情况,Harrison 建议使用如 LangChain 之类的 AI 代理工具。LangChain 可以将问题分解为几个步骤并使用语言模型作为推理引擎来检索所需信息。但是这种方法的一个弊端就是多次调用 LLM,导致使用成本较为高昂。
对此,Filip 建议集成 GPTCache 与 LangChain,使用 GPTCache 存储 LLM 生成的问题和答案。在用户下一次提出类似查询时,GPTCache 会先在缓存中搜索是否是已经问过的重复问题,之后如有必要再执行语义搜索并调用 LLM。这样一来,可以大大节省 LLM 的调用成本。
04.
问答彩蛋
问题 1: 如何使用外部知识生成 Prompt ?是否能够提供一些示例或者小技巧?LangChain 后续是否计划添加一些功能能够帮助优化 Prompt?
Harrison Chase:想要写出好的 Prompt,关键就在于要先明确自己想要什么。如果你无法清楚表达自己的意图,那么 LLM 是不知道该怎么做的,这就和人类之间的交流一样。而且我们确实后续会添加一些功能帮助用户优化 Prompt。
问题 2: 如何看待当前基于检索增强的文本生成赛道?现在我们也看到了许多解决方案,如 Langchain、LlamaIndex、Vectara 等。是否有用于细化检索步骤(包括路由器查询引擎等)的最佳解决方案?您之前提到检索技术可以区分文件的重要性,LangChain 是否已经实现此类功能?
Harrison Chase:整个赛道仍处于早期阶段,发展非常迅速。我们首先要区分检索步骤和生成步骤。对于检索而言,我认为 LangChain 模块化的架构支持自定义向量检索系统,更具灵活性。Vectara 是一套出色的端到端全托管的检索解决方案。LlamaIndex 提供了一些更有趣的数据结构,如树型结构,可供实验使用。对于生成步骤而言,所有用例都使用的是 LangChain。我们和这 3 种方案都有集成。
问题 3: 随着时间推移,LLM 可能会不断放宽其对提示中上下文字数限制,这对检索技术用例有何影响?
Harrison Chase:虽然 Anthropic 推出了支持 10 万上下文长度的 LLM 上下文转换器插件,但我们为什么仍然需要向量数据库?向量数据库提供了一种更高效的解决方案。设想一下,如果 LLM 负责所有计算的工作,而向量数据库负责所有存储的工作,那计算开销会飞速上涨。这也就是说,处理的上下文越多,成本越高。这时我们就可以使用向量数据库来节省开销。计算总是比存储更贵,而且甚至昂贵 100 多倍。而且使用上下文转换器,LLM 仍有可能会忘记早期对话中的内容。
问题 4: Cohere 发布了维基百科的向量数据集,另外还有一个项目发布了 arXiv 摘要的向量数据集。您此有什么看法吗?你是否有推荐的用于开源向量内容的最佳模型?
Harrison Chase:首先,这些初衷都是好的,可以帮忙熟悉语义搜索并降低生成向量数据所需的额外时间和成本。但是预先计算也会带来一些限制,例如你不可以修改 Embedding 方式或内容。此外,其实对于您的数据,并不存在最佳的推荐模型。我只能说,您使用的模型越流行的话,您的数据集被使用的概率就会越大。
问题 5: LangChain 中内存分包的工作原理是什么样的?为什么聊天消息的历史记录与内存分开?这样设计是否有什么特别理由?
Harrison Chase:我们正在重新设计内存模块,使其更加清晰。
点击【阅读原文】或访问下列网址观看直播回放:
https://zilliz.com/event/memory-for-llm-applications-webinar
🌟「寻找 AIGC 时代的 CVP 实践之星」 专题活动即将启动!
Zilliz 将联合国内头部大模型厂商一同甄选应用场景, 由双方提供向量数据库与大模型顶级技术专家为用户赋能,一同打磨应用,提升落地效果,赋能业务本身。
如果你的应用也适合 CVP 框架,且正为应用落地和实际效果发愁,可直接申请参与活动,获得最专业的帮助和指导!联系邮箱为 business@zilliz.com。
推荐阅读