👑作者主页:@安 度 因
🏠学习社区:StackFrame
📖专栏链接:C++修炼之路
文章目录
- 一、读源码
- 二、成员变量
- 三、默认成员函数
- 1、构造
- 2、析构
- 3、拷贝构造
- 4、赋值重载
- 四、访问
- 1、[ ] 重载
- 2、迭代器
- 五、容量
- 1、capacity
- 2、size
- 3、reserve
- 4、resize
- 六、增删查改
- 1、insert
- 2、erase
- 3、push_back
- 4、pop_back
如果无聊的话,就来逛逛 我的博客栈 吧! 🌹
一、读源码
以下代码取自 stl30 的 stl_vector.h ,以下分析均在不更改并发布源码的前提条件下进行。
class vector {
public:
// ...
protected:
typedef simple_alloc<value_type, Alloc> data_allocator;
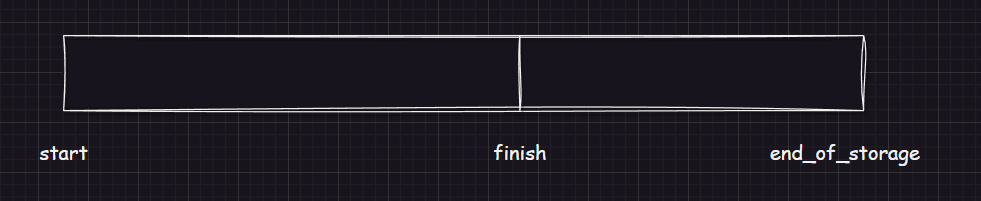
iterator start;
iterator finish;
iterator end_of_storage;
void insert_aux(iterator position, const T& x);
void deallocate() {
if (start) data_allocator::deallocate(start, end_of_storage - start);
}
vector 的成员替换为迭代器:start, finish, end_of_storage
构造:
vector() : start(0), finish(0), end_of_storage(0) {}
vector(size_type n, const T& value) { fill_initialize(n, value); }
vector(int n, const T& value) { fill_initialize(n, value); }
vector(long n, const T& value) { fill_initialize(n, value); }
explicit vector(size_type n) { fill_initialize(n, T()); }
了解成员函数功能:
void reserve(size_type n) {
if (capacity() < n) {
const size_type old_size = size();
iterator tmp = allocate_and_copy(n, start, finish);
destroy(start, finish);
deallocate();
start = tmp;
finish = tmp + old_size;
end_of_storage = start + n;
}
}
void push_back(const T& x) {
if (finish != end_of_storage) {
construct(finish, x);
++finish;
}
else
insert_aux(end(), x);
}
reserve:
start = tmp;
finish = tmp + old_size;
end_of_storage = start + n;
这部分其实就是扩容的步骤,start 为起始位置,finish 加上了原先的 old_size ,end_of_storage 加上扩容后的容量 n
push_back:
很明显 finish != end_of_storage 意思为空间如果够,则插入元素,并将 ++finsh ,将 size 位置偏移。
综上,得到成员的关系图:
vector 是根据 template <class T, class Alloc = alloc> 类模板实现的,其中 Alloc 其实就是 空间配置器:Alloctor,空间配置器只负责开辟空间,但不关注空间的初始化,所以需要 定位 new 表达式 来对空间进行初始化:
template <class T>
inline void destroy(T* pointer) {
pointer->~T();
}
template <class T1, class T2>
inline void construct(T1* p, const T2& value) {
new (p) T1(value);
}
stl 选用空间配置器,会让效率更高,但是由于不使用 new, delete 操作符,对空间上的值进行赋值可能会释放随机值导致崩溃,所以空间上值的处理和释放就需要用定位 new 了。
二、成员变量
看了源码,仿着源码开始造轮子。
template<class T>
class vector
{
private:
iterator _start;
iterator _finish;
iterator _endofstorage;
// iterator _start = nullptr; // 可以给缺省值,可以减少初始化列表初始化
// iterator _finish = nullptr;
// iterator _endofstorage = nullptr;
};
三、默认成员函数
1、构造
无参构造:
vector()
:_start(nullptr)
, _finish(nullptr)
, _endofstorage(nullptr)
{}
迭代器区间构造:
template<class InputIterator>
vector(InputIterator start, InputIterator last)
:_start(nullptr)
,_finish(nullptr)
,_endofstorage(nullptr)
{
while (start != last)
{
push_back(*start);
++start;
}
}
初始化列表初始化成员变量,不初始化编译器可能帮助初始化,但是最好不要依赖编译器。
类模板中,可以嵌套使用模板,通过模板可以使用其他类型的迭代器初始化。
n个值构造:
// 复用 resize
vector(size_t n, const T& val = T()) // 不初始化会有随机值
:_start(nullptr)
, _finish(nullptr)
, _endofstorage(nullptr)
{
resize(n, val);
}
// n 个 val 构造
vector(size_t n, const T& val = T())
:_start(nullptr)
, _finish(nullptr)
, _endofstorage(nullptr)
{
reserve(n); // n 个 val 初始化
for (size_t i = 0; i < n; i++)
{
push_back(val);
}
}
缺省参数 val 若不提供值,则 T() 为各个类型的默认构造:
为了兼容自定义类型初始化需要调用构造函数,模板对内置类型进行了升级,对内置类型增加了默认构造函数。
内置类型的默认构造函数不显示显现,当不给值时:int() ,编译器会隐式处理默认值,如 int 为 0,bool 为 false 等。
通过这种方式,对于任意类型,都能保证对对象的初始化。
当然由于多个构造函数的存在,当使用 n 个值构造函数时,会出现如下形式:
vector<int>(10, 1),由于迭代器区间的构造函数的参数为模板,当调用为两个 int 的参数时,就会匹配迭代器区间的构造函数,此刻InputIterator start, InputIterator last会被实例化为两个 int 。这种情况是根据 调用 n 个值构造函数的参数类型决定的 ,若
vector<int>(10u, 1)就不会出错,因为类型已经对应了,第二个参数只能实例化为 int ;vector<string>(10, "11111")只能对两个参数实例化为int和string。
根据源码中的办法,可以针对 int 类型写函数重载:
vector(int n, const T& val = T())
:_start(nullptr)
, _finish(nullptr)
, _endofstorage(nullptr)
{
reserve(n); // n 个 val 初始化
for (size_t i = 0; i < n; i++)
{
push_back(val);
}
}
2、析构
~vector()
{
if (_start)
{
delete[] _start;
_start = _finish = _endofstorage = nullptr;
}
}
3、拷贝构造
自己负责空间的开辟和释放:
vector(const vector<T>& v)
{
_start = new T[v.size()]; // size 和 capacity 都可以
// memcpy(_start, v._start, sizeof(T) * v.size()); // 内置类型可以,自定义类型不可以
for (size_t i = 0; i < v.size(); i++)
{
_start[i] = v._start[i]; // 借助赋值重载进行深拷贝
}
_finish = _start + v.size();
_endofstorage = _start + v.size();
}
memcpy 在vector中存在自定义类型的拷贝时,会造成浅拷贝,例如 vector<vector<int> :
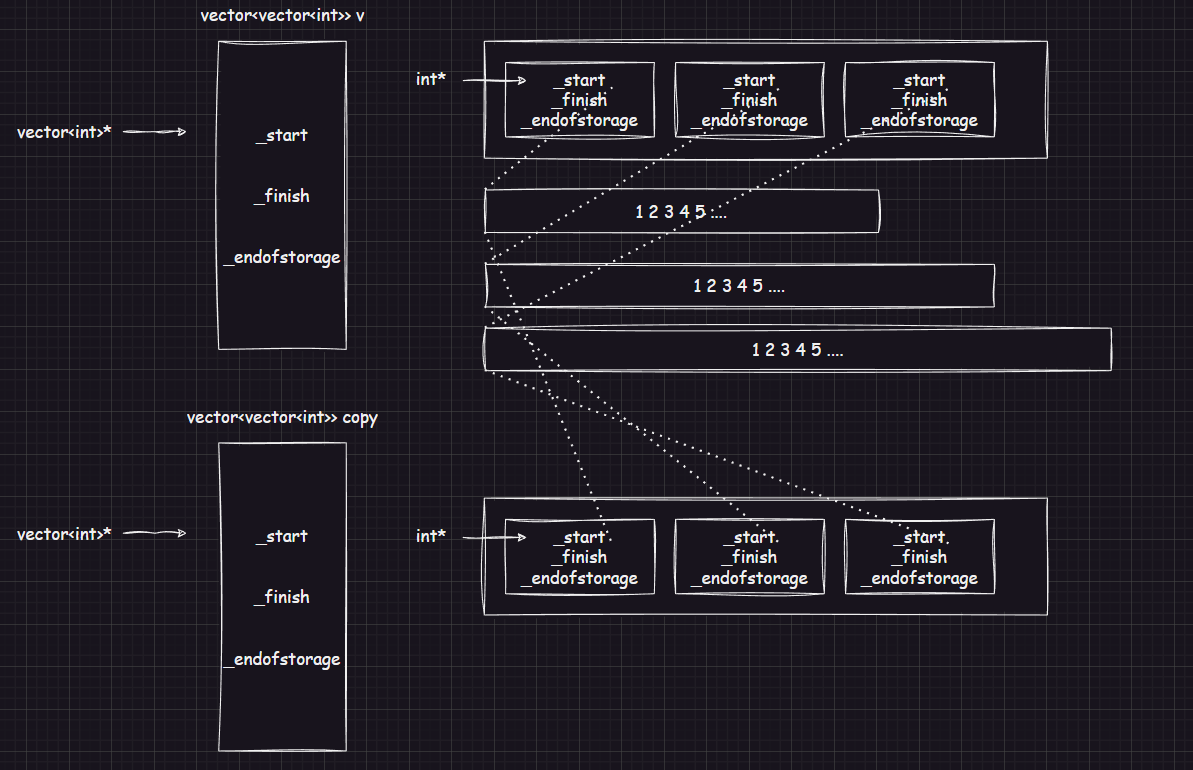
vector<vector<int>> copy 的 _start 指向的 vector<int> 类型的数组上的成员的 _start 和原先的对象指向的空间相同,当析构时,对空间析构后,空间上为随机值,再次析构就会报错。
所以,针对vector上自定义类型数据 的拷贝需要利用循环,调用赋值重载来进行深拷贝 ,这样对于自定义类型,就会调用类型本身的赋值重载,以达到深拷贝的目的。
push_back 进行拷贝构造 :
vector(const vector<T>& v)
:_start(nullptr)
,_finish(nullptr)
,_endofstorage(nullptr)
{
reserve(v.size()); // 先初始化,再开空间
for (const auto& e : v) // const auto& & 为了提高效率,加上 const 是因为参数给的是 const vector<T>& v,无法被修改
{
push_back(e);
}
}
此处使用 & 可以提高效率,也无需担心是否浅拷贝,因为 push_back 接口中,具有帮助拷贝类型完成深拷贝的接口。
借助构造完成拷贝构造:
void swap(vector<T>& v)
{
std::swap(_start, v._start);
std::swap(_finish, v._finish);
std::swap(_endofstorage, v._endofstorage);
}
vector(const vector<T>& v)
:_start(nullptr)
, _finish(nullptr)
, _endofstorage(nullptr)
{
vector<T> tmp(v.begin(), v.end()); // 迭代器区间构造
swap(tmp);
}
4、赋值重载
vector<T>& operator=(vector<T> tmp)
{
swap(tmp);
return *this;
}
传参时调用拷贝构造,随后将 *this 和 tmp 交换
四、访问
1、[ ] 重载
T& operator[](size_t pos)
{
assert(pos < size());
return _start[pos];
}
const T& operator[](size_t pos) const
{
assert(pos < size());
return _start[pos];
}
2、迭代器
vector 的迭代器是原生指针:
typedef T* iterator;
typedef const T* const_iterator;
iterator begin()
{
return _start;
}
iterator end()
{
return _finish;
}
const_iterator begin() const
{
return _start;
}
const_iterator end() const
{
return _finish;
}
五、容量
1、capacity
size_t capacity() const
{
return _endofstorage - _start;
}
2、size
size_t size() const
{
return _finish - _start;
}
3、reserve
void reserve(size_t n)
{
if (n > capacity())
{
size_t sz = size(); // 先拷贝,否则计算 _finish 时,最后结果仍为上一次结果
T* tmp = new T[n];
if (_start)
{
// memcpy(tmp, _start, sz * sizeof(T)); // 当 vector<vector<int>> 时,深拷贝
for (size_t i = 0; i < sz; i++)
{
tmp[i] = _start[i]; // 借助赋值重载进行深拷贝
}
delete[] _start;
}
_start = tmp;
_finish = _start + sz; // 由于 _start 改变,所以 _finish 也需要改变
_endofstorage = _start + n;
}
}
reserve 有两个问题:
(1)finish 指向空间错误
当 reserve 后,原先空间被释放,若 _finish = _start + size() ,size() = _finish - _start ,将其带入计算,此刻 _finish 并没有改变指向。
尤其是第一次扩容,如果按照上面的写法,_finish 在扩容后仍然是 nullptr。
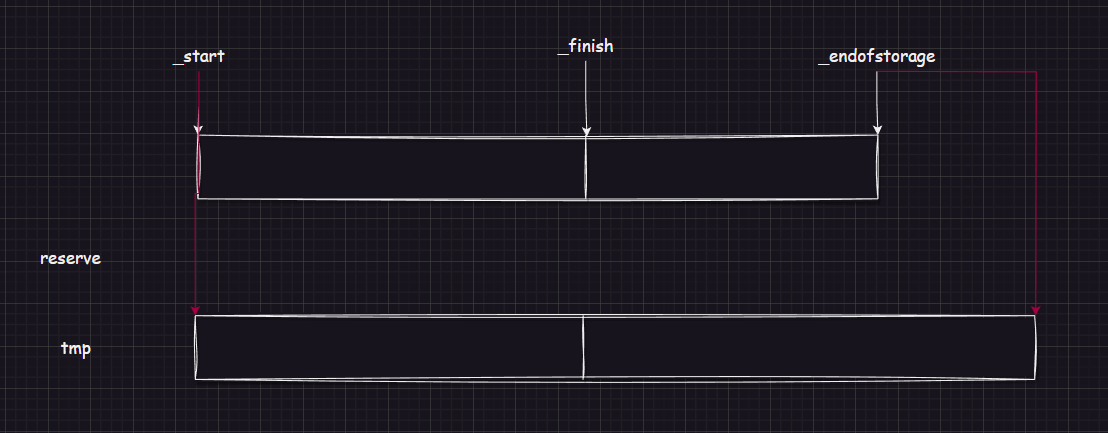
所以,需要提前拷贝 size() ,并在扩容后计算 _finish = _start + sz 。
(2)memcpy 拷贝自定义类型浅拷贝
道理和拷贝构造的原理相同,在扩容后,需要拷贝数据到新的空间,当对于 vector<vector<int> 类型拷贝时,需要使用深拷贝。所以也需要使用循环,利用赋值重载进行深拷贝。
4、resize
三种情况:
n < size,删除数据n >= size && n <= capacity,填充数据n > capacity,扩容,填充数据
void resize(size_t n, const T& val = T())
{
if (n > capacity())
{
reserve(n);
}
// 如果 n 大于原本的 size()
if (n > size())
{
// _start +n 为最后 _finish 应在位置
while (_finish < _start + n)
{
*_finish = val;
++_finish;
}
}
else
{
_finish = _start + n; // 否则删除数据
}
}
六、增删查改
1、insert
iterator insert(iterator pos, const T& x)
{
assert(pos >= _start && pos <= _finish);
if (_finish == _endofstorage)
{
size_t len = pos - _start; // 记录原先 pos 的长短
size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;
reserve(newcapacity);
// 解决pos迭代器失效问题
pos = _start + len; // 让开始位置加上 len
}
iterator end = _finish - 1; // 不用移动 \0
while (end >= pos)
{
*(end + 1) = *end;
--end;
}
*pos = x; // 调用 string 的赋值重载,完成深拷贝
++_finish;
return pos;
}
当容量满后,需要扩容,当扩容后就会引起 内部迭代器失效 :
由于扩容,pos 指向的位置是释放的空间,所以,当往后修改 pos 位置时,就会访问到已经被析构的空间,造成程序错误。
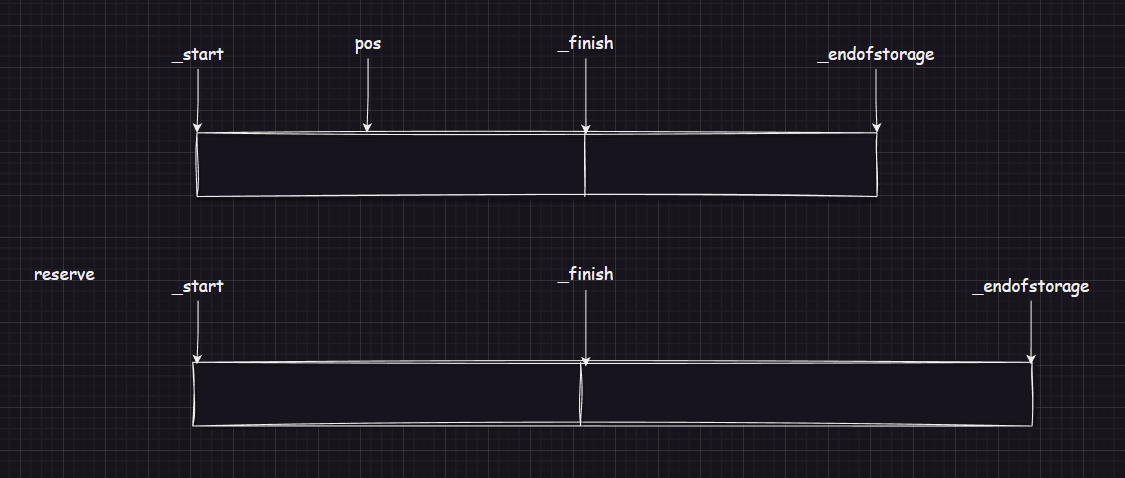
所以需要记录 pos 的位置:size_t len = pos - start,在扩容后,将 pos = _start + len 。此刻 pos 位置才是正确的。
同理,外部迭代器也会失效,当进行插入元素后,原先的迭代器位置可能失效了(扩容指向新空间),这时对这个迭代器操作可能会出错。

扩容后,it 仍然指向被释放的空间,所以在 insert 后需要用返回值接收:
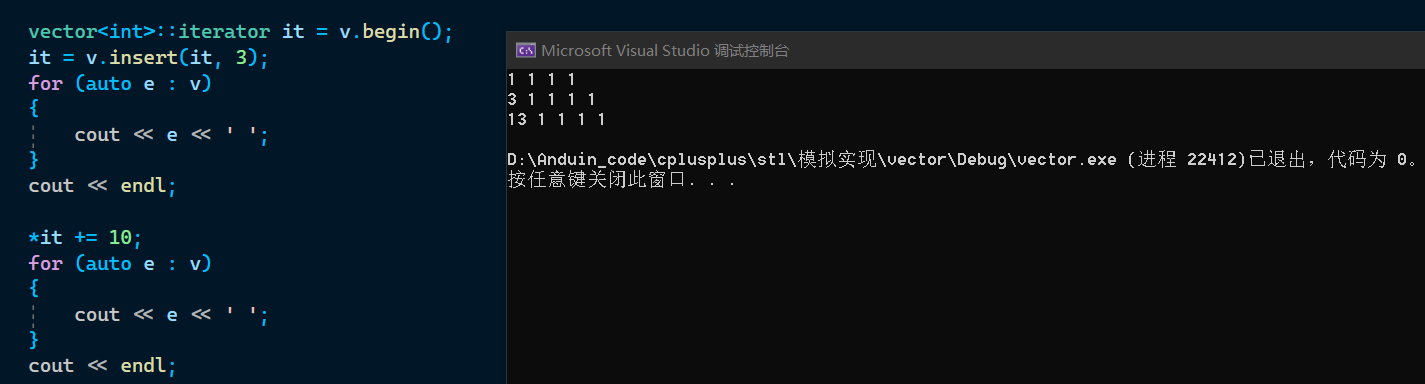
所以,stl 规定,insert 后要返回 pos 位置的迭代器,并且在外面接收,尽量避免外部迭代器失效。
2、erase
iterator erase(iterator pos)
{
assert(pos >= _start && pos < _finish); // pos != _finish
iterator begin = pos + 1;
while (begin < _finish)
{
*(begin - 1) = *begin;
++begin;
}
--_finish;
return pos;
}
当前 erase 的实现不会引起内部迭代器失效,但是可能会引起外部迭代器失效,以防万一,所以返回删除的下一个位置,即 pos 。
针对 vs 和 linux 下迭代器失效做一下总结:
在 vs 下,只要迭代器失效,均会报错(强制检查),需要接收返回值;在 linux 下,原理和这里实现差不多,有的会报错,有的数据错误,有的正确。为了保证程序在平台间的可移植性,建议在使用迭代器后,统一接收返回值,避免出现错误。
若在 insert 或 erase 后,不接收返回值,不要访问迭代器,我们认为它失效,访问结果是未定义。
3、push_back
void push_back(const T& x)
{
//if (_finish == _endofstorage)
//{
// size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;
// reserve(newcapacity);
//}
不是定位 new ,所以可以直接赋值
//*_finish = x;
//++_finish;
insert(end(), x);
}
4、pop_back
void pop_back()
{
assert(_finish > _start);
--_finish;
}