文章目录
- 【半监督医学图像分割 2022 IJCAI】UGPCL
- 摘要
- 1. 介绍
- 2. 相关工作
- 2.1 半监督医学图像分割
- 2.2 对比学习
- 2.3 不确定度估计
- 3. 方法
- 3.1 解码器间的一致性学习
- 3.2 不确定性引导的对比学习
- 3.3 等变对比损失
- 4. 实验
- 4.1 实验设置
- 4.2 定量实验
- 4.3 消融实验
- 5. 结论
【半监督医学图像分割 2022 IJCAI】UGPCL
论文题目:Uncertainty-Guided Pixel Contrastive Learning for Semi-Supervised Medical Image Segmentation
中文题目:基于不确定性指导的像素对比学习的半监督医学图像分割
论文链接:https://www.ijcai.org/proceedings/2022/0201
论文代码:https://github.com/taovv/UGPCL
论文团队:深圳大学
发表时间:
DOI:https://doi.org/10.24963/ijcai.2022/201
引用:
引用数:
摘要
近年来,对比学习在医学图像分割中显示出巨大的潜力。
然而,由于缺乏专家注释,将对比学习应用于半监督场景具有挑战性。
为了解决这一问题,我们提出了一种新的不确定性引导的像素对比学习方法用于半监督医学图像分割。 具体来说,我们为每个未标记图像构造一个不确定性映射,然后去除不确定性映射中的不确定性区域,以减少噪声采样的可能性。
不确定性映射是由一个精心设计的一致性学习机制确定的,该机制通过鼓励来自两个不同解码器的一致网络输出来为未标记数据生成综合预测。
此外,我们建议图像编码器学习的有效全局表示应该对不同的几何变换是等价的。 为此,我们构造了一个等变对比损失来增强编码器的全局表示学习能力。 在流行的医学图像基准上进行的大量实验表明,该方法比现有的方法具有更好的分割性能。
1. 介绍
医学图像分割在计算机辅助诊断系统中占有重要地位。 基于深度学习的监督学习方法依靠大量标注数据取得了巨大的性能。 然而,由于专业临床知识和时间消耗对数据采集和标注的要求,很难获得大规模的医学图像标注。 半数据学习可以同时利用标记数据和未标记数据,大大减少了对注释的依赖。 半监督学习旨在挖掘未标记数据的内在信息以提高模型的性能。 一些流行的半监督学习策略包括使用伪标签的自训练、自集成、熵最小化、一致性正则化。 上述方法在训练阶段通过构造可信标签或当输入数据遇到干扰时强制预测一致性来利用未标记数据。 但这些方法使得每个像素的分类独立,忽略了图像像素(或特征)之间的内在相关性。
为了加强像素之间的联系,最近的一些工作将对比学习应用到分割任务中。 对比学习方法在自然图像的自监督表示学习中取得了较好的效果。 对比学习的核心思想是相似样本的表征应该是相同的,不同类型样本的表征应该是不同的。 如何定义相似样本是对比学习中的关键。 图像级对比学习将相似样本定义为同一图像的不同变换,将来自不同图像的样本定义为不相似。 然而,在分割任务中,相似像素密集分布。 因此,不同样本的定义不适用于像素级对比学习。 针对这一问题,[Wang et al.,2021]使用分割标签为监督分割任务构造对比度样本。 对于未标记的数据,[Chen et al.,2021b]使用预测的伪标记来确定样本类别。 [Zhong等,2021]利用弱增强图像的空间一致性构造相似样本,通过一个简单的交叉图像和伪标签加权启发式构造不相似样本。 事实上,使用伪标签构建样本很可能与实际语义类别不一致,这可能会导致对比学习中的噪声采样。 另外,像素对比学习只建立局部像素的关联,忽略了全局表征信息的学习。
本文的目标是:
1)利用伪标签解决对比学习中的噪声采样问题;
2)增强编码器的全局表示学习能力。
为了实现这些目标,我们提出了一种基于不确定性的对比学习方法。
图 1显示了我们方法的核心思想。
对于未标注的数据,利用不确定度图来指导伪标注采样区域,减少错误样本数。 然后通过计算样本对比损失来优化网络,减小预测的不确定性区域。
为了获得更好的不确定性映射,我们设计了一种基于CNN解码器和Transformer解码器的一致性学习策略,利用两个解码器之间的结构差异,从不同的角度获得准确的预测。 此外,分割模型应该具有识别几何变换的能力。
在此基础上,我们定义了一个等变对比损失,通过在表示学习阶段加入变换类别预测来强制网络学习几何变换的识别信息。 概括而言,我们的贡献主要包括:
- 我们提出了一种新的不确定性引导的对比学习方法,该方法可以有效地减少从未标记数据的伪标记中采样的噪声。
- 设计了一种基于CNN和Transformer的异构译码器一致性学习策略,通过对未标记数据进行一致性训练,获得可靠的预测结果和不确定性映射。
- 定义了一个用于全局表示学习的等变对比损失,使模型具有区分图像不同几何变换的能力。
2. 相关工作
2.1 半监督医学图像分割
由于不需要大规模的标记数据,半数据学习在医学图像分割中引起了广泛的关注。 现有的半监督医学图像分割方法主要包括熵最小化、伪标签自训练、协同训练和一致性学习等。 熵最小化[Vu et al.,2019]认为高质量的预测结果应该具有低熵,因此它通过最小化预测概率分布的信息熵来进行模型学习。 伪标签自训练[Chen et al.,2021a]通过预测未标记数据的伪标签来执行类监督学习。 协同训练[Chiao et al.,2018]假设存在多个包含互补信息的决策视图,设计不同的分类器学习不同的视图以促进分割性能。 一致性学习[Verma et al.,2019;Laine and Aila,2016;Tarvainen and Valpola,2017;Ouali et al.2020]做出一个假设,即即使图像样本遇到一些扰动,比如输入扰动或模型扰动,来自样本的预测结果也不应该改变。 在这种直觉的激励下,这些方法通过鼓励对未标记扰动样本的一致预测来进行模型训练。 受协同训练和一致性学习的启发,我们提出利用CNN和Transformer的结构差异,从不同角度刻画数据的互补信息,并应用一致性约束对模型进行训练。
2.2 对比学习
在图像级表征学习中,对比学习可以充分利用未标记的数据来学习有效的视觉表征,其核心思想是通过在一定的相似性约束条件下缩小相似对(正)和分离不相似对(负)来加强所学视觉表征的区分度。 图像级对比学习的关键是如何构造对比样本。 [He et al.,2020]中提出了一种可行的解决方案,通过引入记忆库和动量对比度来增加对比样本的数量。
最近,有一些工作[Chaitanya et al.,2020;Wang et al.,2021;Zhong et al.,2021;Hu et al.,2021]被提出将对比学习从图像级扩展到像素级用于图像分割。 像素级对比学习的主要思想是借助分割标签构造像素样本对。 对于未标记的数据,利用伪标记或空间结构构造样本对。 然而,这些方法在构造样本对的过程中可能会遇到噪声采样的问题。 为了缓解这一问题,我们建议用预测不确定性来指导样本采样,减少噪声样本数。 此外,像素级对比学习缺乏全局表征的捕获能力,这促使我们在表征学习中施加先验知识的约束,以完成分割任务。
2.3 不确定度估计
在半监督学习中,不确定性可以用来评估模型预测的质量,以便更好地使用未标记的数据。
估计不确定度的度量方法主要包括:
1)利用预测概率分布的信息熵,
2)利用同一输入在不同扰动下的多个预听结果的偏差[Yu等,2019],
3)计算同一输入不同预测结果的方差[Zheng和Yang,2021]。
但这些方法耗时长且缺乏可靠性。 在我们的方法中,我们通过计算不同预测器获得的平均概率分布的熵来估计不确定性,以克服这些问题。
3. 方法
给定一个标号数据集 D L = { ( x i , y i ) , i = 1 , … , N } D_{L}=\{(x_{i},y_{i}),i=1,\ldots,N\} DL={(xi,yi),i=1,…,N}和一个未标号数据集 D U = { x j , j = 1 , … , M } D_{U}~=~\{x_{j},j~=~1,\ldots,M\} DU = {xj,j = 1,…,M},其中 M ≫ N M\gg N M≫N, D L D_{L} DL和 D U D_{U} DU中的图像首先经过几何变换,然后送入编码器网络提取多尺度特征。
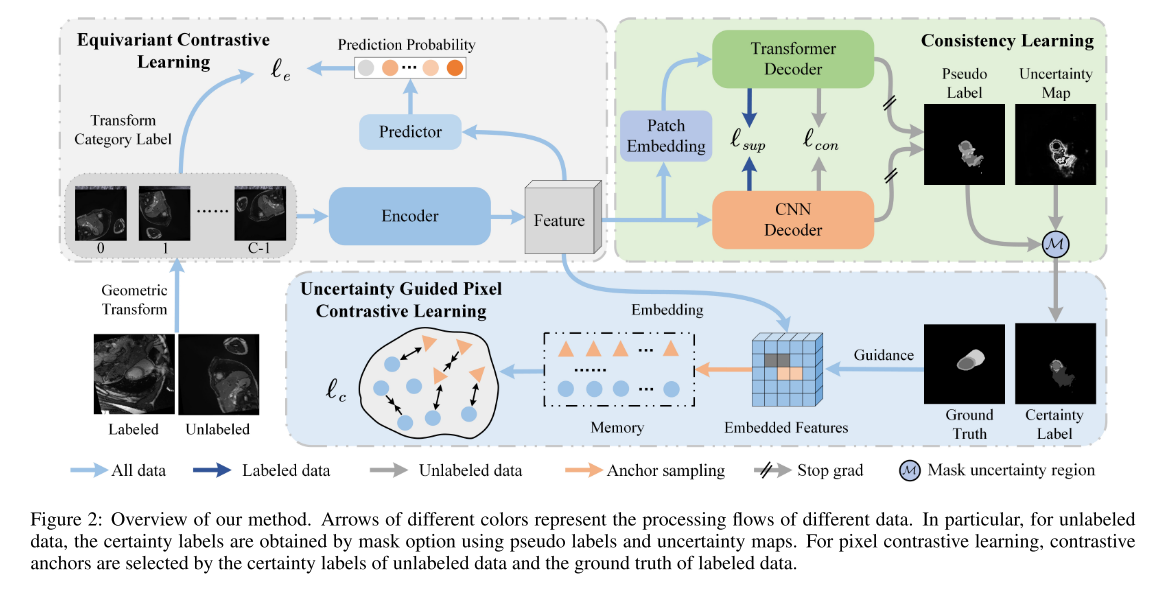
然后,这些特征将被发送到以下三个分支,包括一致性学习分支、不确定性指导的对比学习分支和等变对比学习分支。
对于一致性学习分支,我们提出了一个异构一致性网络来预测分割结果,该网络由监督损失和一致性损失驱动。 用 D L D_{L} DL的真实标签计算出 ℓ s u p \ell_{sup} ℓsup,用DU的预测一致性计算出 ℓ c o n \ell_{con} ℓcon。
对于不确定性引导的约束学习分支,我们建立并维护一个记忆队列,以保存足够的样本用于约束学习。
内存队列中样本的选择取决于 D L D_{L} DL的标签和 D U D_{U} DU的确定性标签。
对于选定的样本,我们施加一个像素级的对比损失,使同类别的像素彼此靠近,不同类别的像素彼此远离。
对于等变对比学习分支,我们对所有标记和未标记数据进行几何变换类别预测,并设计了一个等变对比损失来迫使编码器对几何变换具有鲁棒性。 为了便于理解,图2给出了我们提出的方法的总体架构和训练过程的说明。
总之,我们的方法的总目标是:
ℓ
=
ℓ
s
u
p
+
λ
t
ℓ
c
o
n
+
λ
1
ℓ
c
+
λ
2
ℓ
e
\ell=\ell_{sup}+\lambda_{t}\ell_{con}+\lambda_{1}\ell_{c}+\lambda_{2}\ell_{e}
ℓ=ℓsup+λtℓcon+λ1ℓc+λ2ℓe
在本文中,我们设置 λ 1 = λ 2 = 0.1 \lambda_{1}=\lambda_{2}=0.1 λ1=λ2=0.1, λ t \lambda_{t} λt是一个从0增加到0.01的温度参数。 下面详细介绍了上述三个分支。
3.1 解码器间的一致性学习
在一致性学习方面,我们设计了一个简单而有效的网络结构,以实现以下两个目标:1)使用未标记数据促进分割网络的学习;2)从网络输出中获得可靠的不确定性估计。
研究表明,采用协同训练策略可以获得更好的分割性能,其核心思想是从不同的角度做出不同的分类预测,然后将预测的差异作为不确定度估计的度量标准。 受[Luo et al.,2021]的启发,我们采用了一种简单而有效的方案,利用了Transformer解码器和CNN解码器之间的先天差异,而不是使用需要添加一些干扰来进行协同训练的相同架构。 具体来说,我们构造了一个异构预测器来约束两个解码器产生一致的预测。 然后利用均值预测的熵估计不确定性图。
Patch Embedding and Position Encoding
我们从SWIN-UNET和UNET中选择了两种不同的译码器 f θ t ( ⋅ ) f_{\theta}^{t}(\cdot) fθt(⋅)和 f θ c ( ⋅ ) f_{\theta}^{c}(\cdot) fθc(⋅)。 通过编码器,我们可以获得一组特征 { f i , i = 0 , … , 3 } \{f_{i},i=0,\ldots,3\} {fi,i=0,…,3} 在输入 f θ t ( ⋅ ) f_{\theta}^{t}(\cdot) fθt(⋅)之前,我们需要将特征 f i ∈ R H i × W i × C i f_{i}\in\mathbb{R}^{H_{i}\times W_{i}\times C_{i}} fi∈RHi×Wi×Ci重新塑造成一系列平坦的片 x p i ∈ R P i 2 × C i x_{p}^{i}\in\mathbb{R}^{P_{i}^{2}\times C_{i}} xpi∈RPi2×Ci,并使用可学习的线性投影 E E E将其嵌入到一个维数空间中。为了保留空间信息,我们在嵌入的片上增加了绝对位置编码:
P E ( x i ) = [ x p i 1 E ; x p i 2 E ; ⋯ ; x p i P i 2 E ] + E p o s PE(x_i)=[x_p^{i1}E;x_p^{i2}E;\cdots;x_p^{iP_i^2}E]+E_{pos} PE(xi)=[xpi1E;xpi2E;⋯;xpiPi2E]+Epos
其中 E ∈ R ( P i 2 × C i ) × D E\in\mathbb{R}^{(P_{i}^{2}\times C_{i})\times D} E∈R(Pi2×Ci)×D为贴片嵌入投影, E p o s ∈ R N × D E_{pos}\in R^{N\times D} Epos∈RN×D为绝对位置编码。
一致性学习
给定一幅输入图像,我们可以从两个解码器得到两个预测概率分布 p t p_{t} pt和 p c p_{c} pc。 对于标记数据,我们使用真实标签计算监督分割损失:
ℓ s u p = L s e g ( p c , y ) + α L s e g ( p t , y ) L s e g = 1 2 ( L C E + L D i c e ) \begin{align} \ell_{sup}=\mathcal{L}_{seg}(p_c,y)+\alpha\mathcal{L}_{seg}(p_t,y) \\ \mathcal L_{seg}=\dfrac{1}{2}(\mathcal L_{CE}+\mathcal L_{Dice}) \end{align} ℓsup=Lseg(pc,y)+αLseg(pt,y)Lseg=21(LCE+LDice)
其中 L C E , L D i c e \mathcal{L}_{CE},\mathcal{L}_{Dice} LCE,LDice是交叉熵损失和Dice损失,y是标记数据的基本真值。 我们使用 f θ c ( ⋅ ) f_{\theta}^{c}(\cdot) fθc(⋅)作为主要预测器,因此α设为0.4。 在推理阶段,从CNN分支预测是最终结果。 对于未标记的数据,一致性损失计算如下:
ℓ c o n = L d i s ( p c , p t ) \ell_{con}=\mathcal L_{dis}(p_c,p_t) ℓcon=Ldis(pc,pt)
其中 L d i s \mathcal L_{dis} Ldis是两个输出概率分布之间的距离度量。 在这项工作中,我们选择使用均方误差(MSE)作为距离度量。
3.2 不确定性引导的对比学习
为了进行像素级分类,图像分割任务通常涉及到交叉熵损失。 然而,这种损失使得每个像素的分类独立,从而忽略了像素之间的关系。
为了解决这一问题,我们设计了一种像素级对比学习机制,将相同类别(语义标签)的像素作为正样本,不同类别的像素作为负样本。
在一个嵌入空间中,通过缩小正样本之间的距离和扩大负样本之间的距离来建立像素之间的关系。 为了有效地利用未标记数据进行像素级对比学习,我们估计了未标记像素的不确定性,并选择确定性较高的像素作为对比学习的锚点。
掩模不确定区域。
我们选择预测熵作为度量来逼近不确定性。 具体来说,我们首先计算预测结果的平均概率分布 p ^ = ( p c + p t ) / 2 \hat{p}=(p_{c}+p_{t})/2 p^=(pc+pt)/2,然后针对信道维度上每个像素的概率分布计算熵。 可以概括为:
u = − ∑ c p ^ c log ( p ^ c + ϵ ) u=-\sum_c\hat p_c\log(\hat p_c+\epsilon) u=−c∑p^clog(p^c+ϵ)其中是一个非常小的常数,以避免奇点。 我们认为,大熵的预测在类别上是不确定的。 在计算伪标号时,将那些不确定度预测作为非采样区域去除,然后得到确定的伪标号:
y p = A r g m a x ( p ^ ) ∣ u < H y_p=Argmax(\hat p)_{|u<H} yp=Argmax(p^)∣u<H
其中 H H H是一个阈值来掩盖不确定标签, y p y_p yp是最终确定伪标签。
锚点采样。
我们使用标记图像的标签和未标记图像的确定性伪标签作为使用对比样本的基础。
由于原始图像分辨率太大,在原始图像尺寸下进行对比学习的成本很高,像素的原型向量包含的语义信息较少。因此,我们在低分辨率的特征空间中使用对比学习。首先,将从编码器中提取的特征嵌入到D维空间中,其中每个D维特征向量表示像素。 然后将标签下采样到相同分辨率,为每个原型向量指定类别,不对不确定区域中的向量进行采样。 我们对每个类别采用固定样本数的随机抽样策略。
如果同一类别的样本数量很少,我们将从其他类别样本锚。 对比负样本的数量在很大程度上影响着对比学习的性能,但是大量的负样本会产生大量的开销。
一个较好的解决方案是使用固定大小的外部存储器来存储采样样本,并随着训练更新存储内容。 在我们的方法中,我们设置了一个内存队列来存储收集的样本。 在每次迭代中,随机选取的样本作为锚点计算对比损失,然后更新到内存队列中。
像素对比损失。
原型向量及其像素类别保存在样本队列中。 我们使用流行的InfoNCE损失函数来计算对比损失。 在每次迭代中,我们随机抽取 M M M个锚点,并计算每个锚点的对比损失。 然后平均所有锚的损失作为总的对比损失。 具体计算如下:
ℓ c i = − 1 ∣ P i ∣ ∑ v i + ∈ P i l o g e c o s ( v i , v i + ) / τ e c o s ( v i , v i + ) / τ + ∑ v i − ∈ N i e c o s ( v i , v i − ) / τ ℓ c = 1 M ∑ i = 1 M ℓ c i \begin{align} \ell_c^i &= -\dfrac{1}{|P_i|}\sum_{v_i^+\in P_i}log\dfrac{e^{cos(v_i,v_i^+)/\tau}}{e^{cos(v_i,v_i^+)/\tau}+\sum_{v_i^-\in N_i}e^{cos(v_i,v_i^-)/\tau}} \\ \ell_c &=\dfrac{1}{M}\sum_{i=1}^M\ell_c^i \end{align} ℓciℓc=−∣Pi∣1vi+∈Pi∑logecos(vi,vi+)/τ+∑vi−∈Niecos(vi,vi−)/τecos(vi,vi+)/τ=M1i=1∑Mℓci其中 P i P_{i} Pi和 N i N_{i} Ni表示像素i的正负样本的原型向量集合。 v i v_{i} vi是像素 i i i的原型向量, v i + v_{i}^{+} vi+是正原型向量, v i − v_{i}^{-} vi−是负向量,τ是温度超参数。
3.3 等变对比损失
为了进行对比学习,以往的一些工作通过对同一图像进行不同的变换来构造正样本。 然而,有些变换并不符合分割任务的先验知识[Dangovski et al.,2021],例如几何变换。 在本文中,我们建议分割任务所需要的有效特征表示应该是对不同几何变换的等变(或区分)的。
在此基础上,我们考虑在分割模型的表示学习中加入等变对比损失来学习全局信息。 具体来说,我们将分割模型定义为编解码器形式:
f
(
x
i
)
=
f
γ
(
f
θ
(
x
i
)
)
f(x_{i})=f_{\gamma}(f_{\theta}(x_{i}))
f(xi)=fγ(fθ(xi))。 对于一幅图像
x
i
x_{i}
xi,当它经过某种几何变换G(·)时,相应的分割结果也会发生变化,即:
f
(
G
(
x
i
)
)
=
G
(
f
(
x
i
)
)
f(G(x_i))=G(f(x_i))
f(G(xi))=G(f(xi))
那么,我们可以推断:
f
θ
(
G
(
x
i
)
)
≠
f
θ
(
x
i
)
f_{\theta}(G(x_{i}))\neq f_{\theta}(x_{i})
fθ(G(xi))=fθ(xi)
因此,我们可以在fθ(·)中显式地加强这种几何变换信息的学习。 我们增加了一个分类预测器P(·)来预测几何变换的判别结果。 我们的等变对比损失函数如下:
ℓ
e
=
1
C
∑
i
=
0
C
−
1
L
C
E
(
p
ϕ
(
f
θ
(
G
i
(
x
)
)
)
,
i
)
\ell_e=\frac{1}{C}\sum_{i=0}^{C-1}\mathcal{L}_{CE}(p_\phi(f_\theta(G^i(x))),i)
ℓe=C1i=0∑C−1LCE(pϕ(fθ(Gi(x))),i)
其中几何变换
G
i
(
⋅
)
G^{i}(\cdot)
Gi(⋅)表示本文中的四倍旋转,所以C=4。
4. 实验
4.1 实验设置
ACDC数据集[Bernard et al.,2018]包含来自100名患者的200幅注释短轴心脏磁共振电影图像。 我们将数据集按7:3的比例划分,得到训练集和验证集。 根据不同的半监督实验设置,分别对训练集中来自7个病人的136幅图像和来自3个病人的68幅图像进行标记。 有关详细信息,请参见SSL4MIS1。
ISIC数据集[Codella et al.,2018]包括2594幅皮肤镜图像,我们使用1815幅图像进行训练,779幅图像进行验证。 在训练集中,针对不同的半视觉实验设置,分别有5%(91)和10%(181)的图像被标记。
两个数据集中的所有图像都被调整为224×224,以满足所提方法的输入要求。 我们使用标准的数据增强来扩大训练集,包括随机裁剪、随机旋转、随机翻转和颜色抖动。 在我们的方法中,将记录转换的类别来计算QUANE。 为了评价该方法的性能,我们选择了DICE系数(记为DICE)和JACCARD指数(记为JACCARD)作为评价指标。
实施细节
为了进行公平的比较,所有实验中使用的方法都选择UNET作为图像分割的基准架构。 我们用RESNET-50代替UNET的编码器部分,并用在ImageNet上预先训练的权值初始化其参数。 我们采用SGD作为一个优化器,其权值衰减为0.0005,动量为0.9。 初始学习率为0.01,训练过程中采用多项式调度策略将初始学习率降至0.001。 我们使用PyTorch库实现了这些方法,并在NVIDIA RTX2080TI GPU上进行了训练。 批量大小设置为16,其中8个图像被标记。 所有方法在训练过程中执行6000次迭代。
4.2 定量实验
比较的方法。 我们将我们的方法与最近的一些半监督分割方法进行了比较,这些方法包括:肉老师(MT)[Tarvainen and Valpola,2017]、熵最小化(EM)[Vu et al.,2019]、不确定性感知均值老师(UA-MT)[Yu et al.,2019]、深度协同训练(DCT)[Chiai et al.,2018]、交叉一致性训练(CCT)[Ouali et al.,2020]和交叉伪监督(CPS)[Chen et al.,2021a]。 对于所有的比较方法,我们都采用官方的超参数设置。
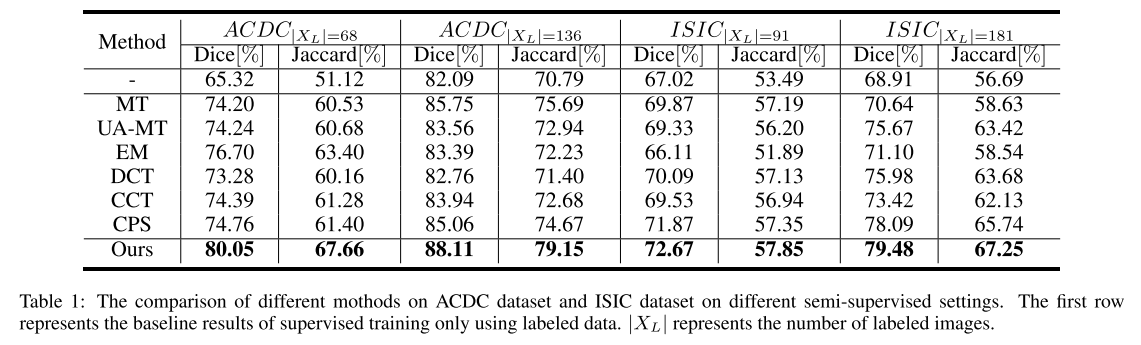
主要成果。 表1显示了我们在ACDC和ISIC数据集上的定量对比实验结果。 第一行表示仅用标记数据训练的基线模型的性能。 与基线模型相比,我们的方法可以有效地利用未标记数据来获得很大的性能。 在不同的数据集和不同的半变量设置下,我们提出的方法明显优于比较方法。 特别地,当ACDC数据集中只有68幅标记图像时,该方法比其他方法提高了3%以上。
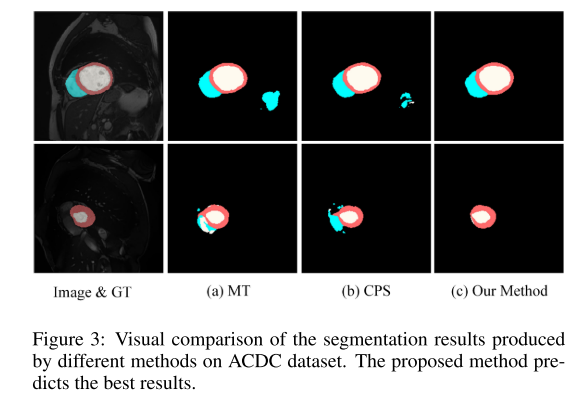
视觉对比。 图3显示了在ACDC数据集中使用136个标记图像时不同方法之间的一些视觉比较。 我们选择了实验中效果较好的MT和CPS两种方法进行比较。 与MT和CPS相比,我们的方法具有更好的预测效果和更少的虚假预测。
4.3 消融实验
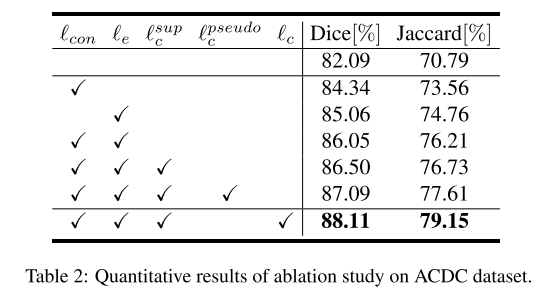
表2显示了我们的方法在ACDC数据集上136幅标记图像的烧蚀实验 结果。 我们选择只使用标记数据进行监督训练的UNET模型作为基线(第一行),并逐步增加提出的分量来证明其有效性。 此外,我们进一步增加了两个额外的比较设置,包括:1)仅使用标记数据进行对比学习(p.sup c)和2)使用伪标记进行对比学习(p.pseudo c)来证明我们提出的不确定性引导的对比学习方法的有效性。 实验结果表明,我们提出的方法的每个部分都有积极的影响。 对比学习的引入有效地建立了像素之间的关系,提高了模型的性能。 与伪标记方案相比,该方法充分利用了未标记数据,从而带来了显著的性能改善(DICE提高约1%)。
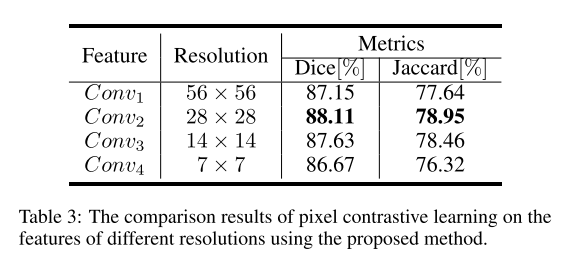
不同特征尺度上的对比。 不同特征的分辨率对对比学习样本的选择有重要影响。 为了寻找合适的特征量表,我们探讨了不同量表对ACDC数据集对比学习的影响。 表3显示了四种不同特征量表下的对比学习结果。 我们可以看到,对比学习在低分辨率(CONV4)下的性能较差,这可能是由标签下采样引起的语义不一致造成的。 更高分辨率特性(CONV1)也带来了性能下降。 潜在的原因是高分辨率像素向量包含的语义信息较少。 因此,我们认为利用中层特征进行对比学习可以带来更好的分割性能。
特征可视化。 在图4中,我们使用T-SNE算法来降低像素特征的维数以进行可视化。 从左到右分别是无对比学习训练结果、使用伪标签对比学习结果和提出的方法。 与第一种方法相比,该方法能使像素表示具有更好的类内紧凑性和类间可分离性,表明了对比学习在分割任务中的有效性。 与第二种方法相比,我们的方法具有更好的聚合效果,其潜在原因是我们的方法可以减少噪声采样的可能性。

5. 结论
提出了一种不确定度引导的像素对比学习半监督医学图像分割方法,利用不确定度解决了像素对比学习中未标记数据的噪声采样问题。 为了估计不确定性,在CNN和Transformer译码器的基础上,设计了一种异构一致性学习策略。 此外,我们构造了一个等变对比损失来加强模型的全局表征学习能力。 大量的实验表明,我们的方法可以达到最先进的性能。