目录
正则表达式
1、点:匹配所有字符
2、星号:重复匹配任意次
3、加号:重复匹配多次
4、花括号:匹配指定次数
5、贪婪模式和非贪婪模式
6、反斜杠:对元字符的转义
7、方括号:匹配几个字符之一
8、开始、结尾位置和单行、多行模式
9、圆括号:组选择
正则表达式
应用场景:文本处理提取信息
关键在于:如何正确地使用正则表达式的语法
验证网站:https://regex101.com/
字符分类:
- 普通字符:没有特殊含义,直接用来匹配
- 特殊字符:又称元字符,有特殊含义,不是直接用来匹配
1、点:匹配所有字符
“.”:表示要匹配除了 换行符 以外的 任何单个字符。
content = '''ive是芙
izone不是芙'''
import re
# r禁止了对字符的转义
p = re.compile(r'.芙')
# findall查找符合匹配条件的文本
for one in p.findall(content):
# <class 'str'>
print(type(one))
print(one)查看调用 compile 后 p 的类型:
# <class 're.Pattern'>
# 从而才能调用该类中的各种方法
print(type(p))2、星号:重复匹配任意次
点默认只匹配一个字符,而搭配使用星号等可以在此基础上匹配多个字符。
“*”:表示可以匹配 任意次数,包括 0 次。
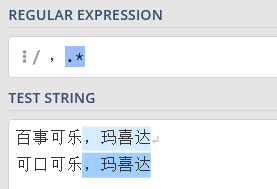
- “*” 搭配 “.” 来使用即 “.*”,表示要匹配指定字符前或后的所有字符,包括该指定字符。
- 比如:“,.*” 表示匹配中文逗号后的任何字符任意次数。
3、加号:重复匹配多次
“+”:表示可以匹配 任意次数,但不包括 0 次。
- 与 “*” 的区别就是一个包含 0 次而另一个不包含
4、花括号:匹配指定次数
“{}”:表示匹配 位于 “{}” 前面 的一个字符 指定次数。
- c{min, max}:c 是匹配的字符,min 是最少出现次数,max 是最多出现次数
- c{num}:直接指定需要匹配 num 次
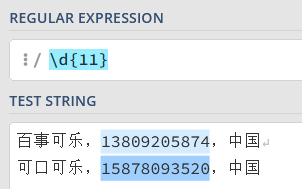
匹配电话号码:\d{11},\d 表示数字。
5、贪婪模式和非贪婪模式
“*”、“+”、“?” 都是 贪婪 的,它们会尽可能多地去匹配内容。
<html><head><title>Title</title></head></html>

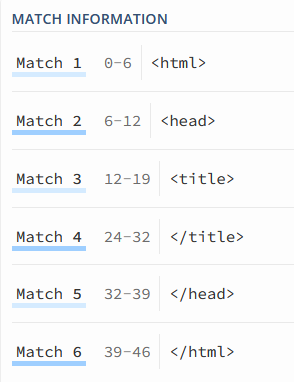
加上 “?” 变为 非贪婪 模式:
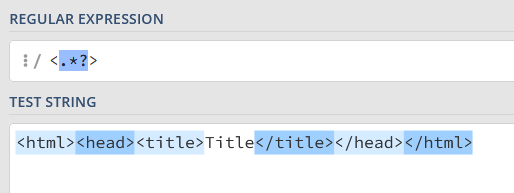
分别匹配到了多个对象:
6、反斜杠:对元字符的转义
“\” 将元字符转义为普通字符。

“\” 后面接一些字符,还能表示匹配 某种类型 的一个字符。
- \d:匹配 0-9 之间任意一个数字字符,等价于表达式 [0-9]
- \D:匹配任意一个不是 0-9 之间的数字字符,等价于表达式 [^0-9]
- \s:匹配任意一个空白字符,包括 空格、tab、换行符 等,等价于表达式 [\t\n\r\f\v]
- \S:匹配任意一个非空白字符,等价于表达式 [^\t\n\r\f\v]
- \w:匹配任意一个文字字符,包括大小写字母、数字、下划线,等价于表达式 [a-zA-Z0-9]
- \W:匹配任意一个非文字字符,等价于表达式 [^a-zA-Z0-9]
\w 缺省情况也包括 Unicode 文字字符,如果指定 ASCII 码标记,则只包括 ASCII 字母。
- re.compile(r'.芙', re.A)
7、方括号:匹配几个字符之一
- 1[35]\d{9}:表示几个字符
- 1[3-5]\d{9}:“-” 表示一个范围
更进一步:
- “.” 在 “[]” 里面变为普通字符,不再是元字符
- “^” 在“[]” 里面表示 “非” 的概念
8、开始、结尾位置和单行、多行模式
“^” 表示只需要处于 每行开始位置 的匹配内容。
- 单行模式下和多行模式下的匹配结果不一样
- 多行模式:re.compile(r'.芙', re.M)
“$” 表示只需要处于 每行结尾位置 的匹配内容。
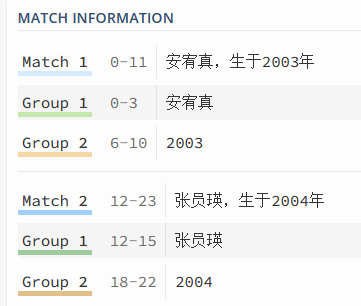
9、圆括号:组选择
组就是把正则表达式匹配的内容里面其中的某些部分标记为某个组。
我们可以在正则表达式中标记多个组。

匹配结果为多个组:




![[英语单词] components;](https://img-blog.csdnimg.cn/81a2a1d1622a47d3bc441bd41973d0f1.png#pic_center)