📚 前言
在信息时代,我们经常需要从大量的文章中获取有用的信息。本文将介绍如何使用Python进行数据处理,获取热榜文章的标题和标签,并使用jieba库进行数据分析。通过本文的学习,你将掌握获取和分析热榜文章数据的技巧。
先上看看效果:


🛠️ 环境准备
在开始编写代码之前,我们需要进行一些环境准备。以下是所需的环境和库:
- 操作系统:Windows
- 编程语言:Python 3
- 编辑器:VSCode(可选)
所使用的库
| 库名 | 作用 |
|---|---|
| requests | 发送HTTP请求获取网页内容 |
| BeautifulSoup | 处理和分析数据 |
| jieba | 中文分词工具 |
| wordcloud | 制作词云图 |
| matplotlib | 绘制图表 |
| csv | csv表格处理 |
| json | json格式 |
可以使用以下命令需要安装的库:
pip install BeautifulSoup
pip install jieba
pip install wordcloud
pip install matplotlib
请确保已经正确安装了Python 3,并且在编写代码之前设置了Python 3的环境变量。
📑 热榜信息获取
🎯热榜上的信息获取
首先,我们需要从全站综合热榜上获取热门文章的信息。
全站综合热榜https://blog.csdn.net/rank/list

需要的文章信息有
["标题", "标签","作者","评论数" ,"收藏量","浏览量", "热度值", "文章链接"]
经分析,全站综合热榜文章信息数据可以在hot-rank 的api中获取到除文章标签外的信息:

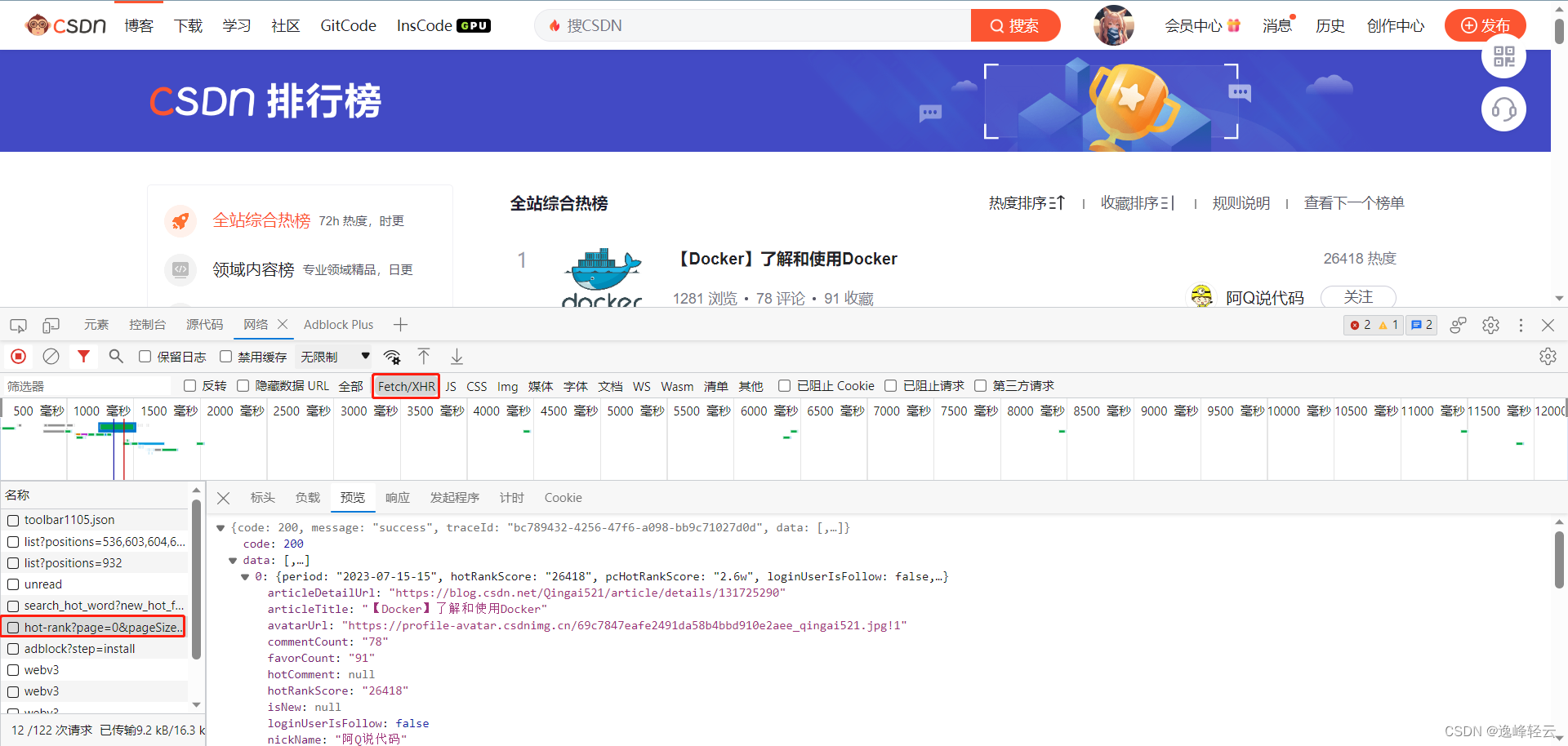
代码如下:
def get_hot_list(page):
# 每页25条信息,总共4页,100条
params = {
"page": page, # 页数
"pageSize": "25",
"type": ""
}
hot_rank_url = 'https://blog.csdn.net/phoenix/web/blog/hot-rank'
data = requests.get(url=hot_rank_url,headers=user_headers,params=params)
hot_rank_list = data.json()["data"]
for article in hot_rank_list:
Url = article["articleDetailUrl"] # 获取文章链接
tag_list = get_article_tag(Url,user_headers) # 文章标签,列表形式
tag = ",".join(tag_list) #列表转为字符串,使用“,”连接
Title = article["articleTitle"] # 获取文章标题
commentCount = article["commentCount"] # 评论
favorCount = article["favorCount"] # 收藏
hotRankScore = article["hotRankScore"] # 热度
nickName = article["nickName"] # 作者
viewCount = article["viewCount"] # 浏览量
上述代码中,我们使用
requests库发送HTTP请求获取热榜xhr数据。然后,使用json方法处理数据,提取其中的表格数据。
🎯补充信息(文章标签)
文章标签需要访问文章详情页才能够拿到,所在位置如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mkPdg0JP-1689416684853)(C:\Users\LIN\AppData\Roaming\Typora\typora-user-images\image-20230715163532878.png)]
检查文章源代码,使用搜索可以找到,文章标签在body->script下
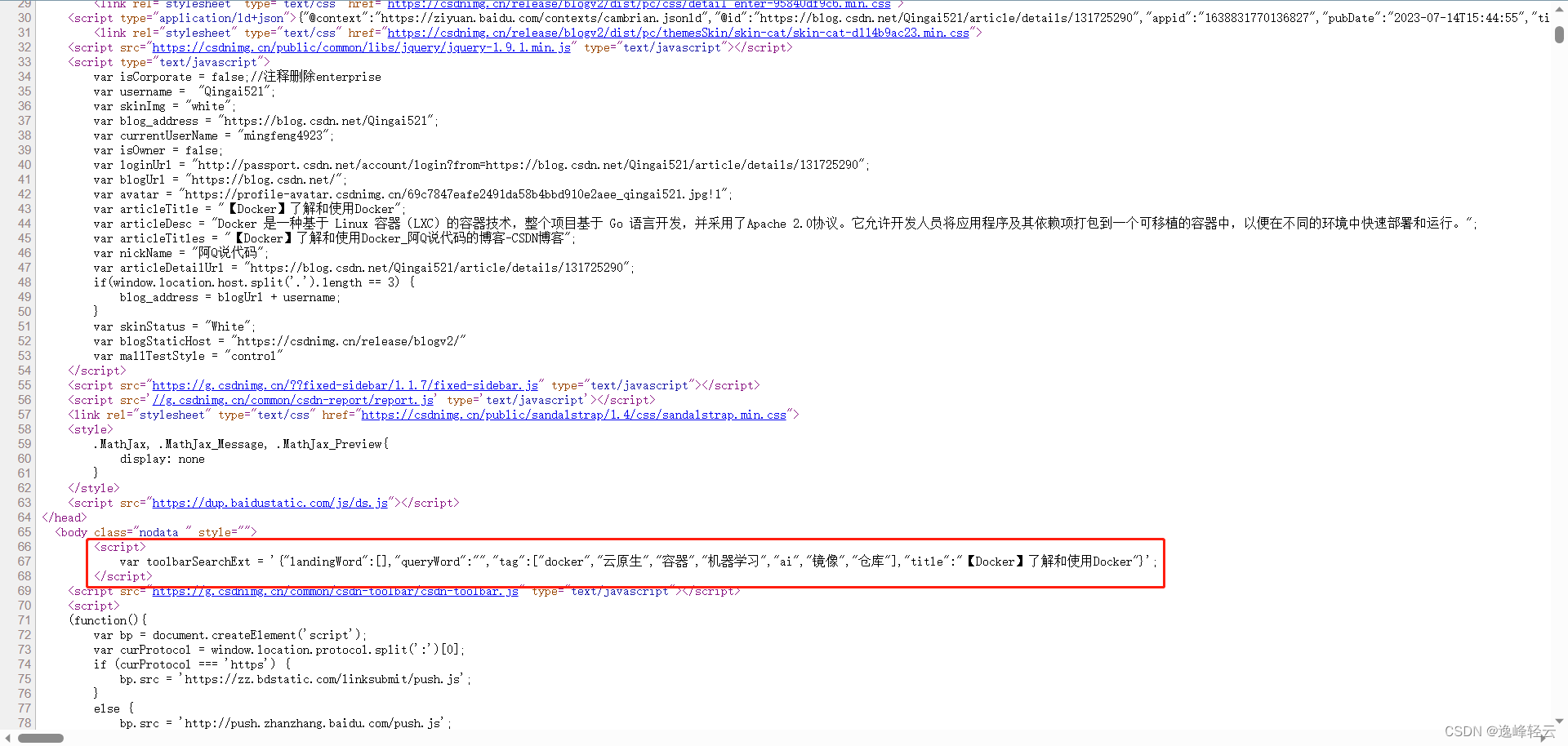
找到位置了,💪那就开始写代码…
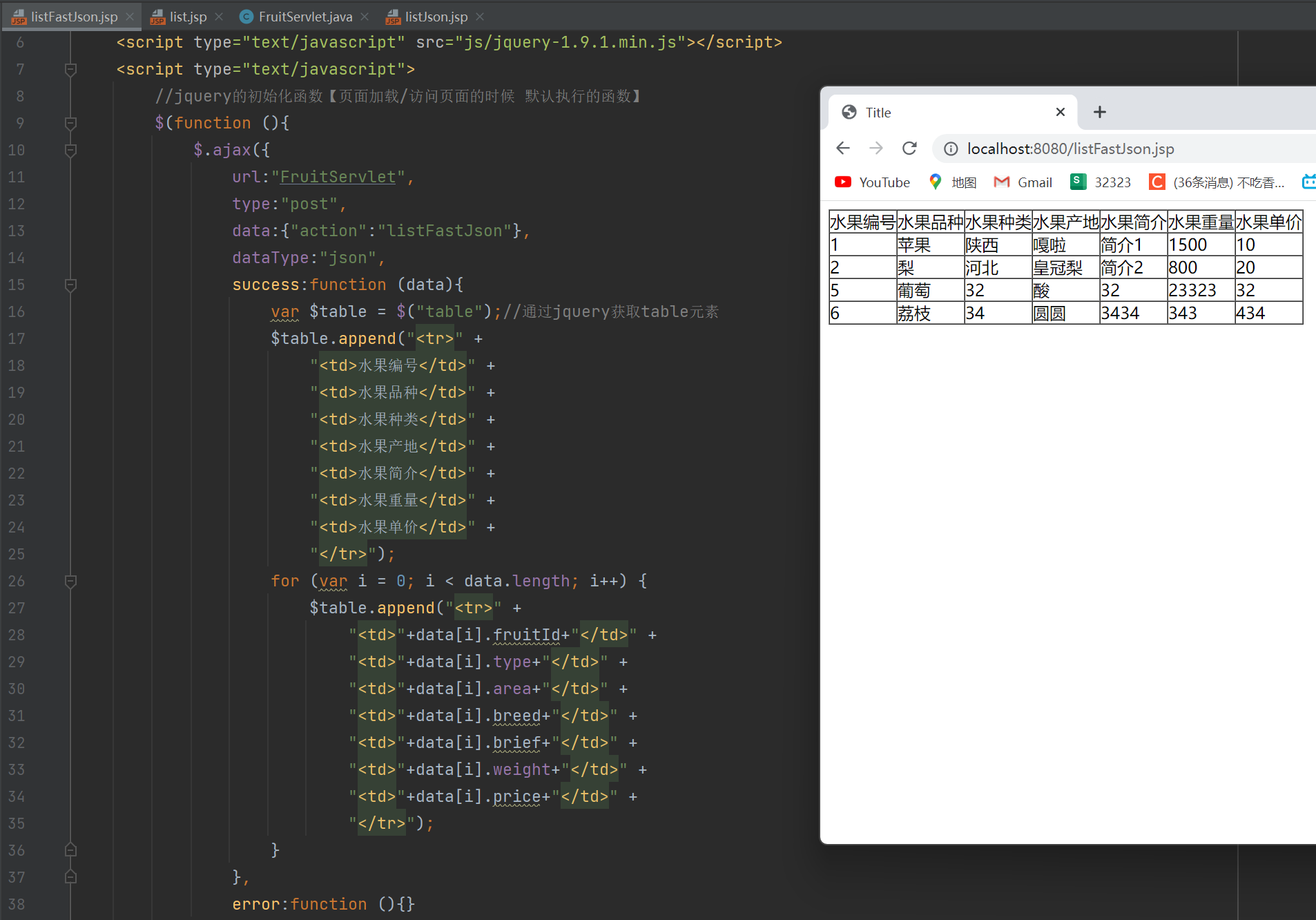
def get_article_tag(articleDetailUrl,user_headers):
"""
articleDetailUrl : 文章链接
"""
data = requests.get(url=articleDetailUrl,headers=user_headers)
# 使用html.parser解析响应文档
soup = BeautifulSoup(data.text, 'html.parser')
# 获取所有script对象内容
script_tag = soup.find('script', text=re.compile('toolbarSearchExt')).text.strip()
# 提取特定var变量的值
result = json.loads(script_tag[script_tag.find('{'):script_tag.find('}')+1])
return result["tag"]
🗐 信息保存
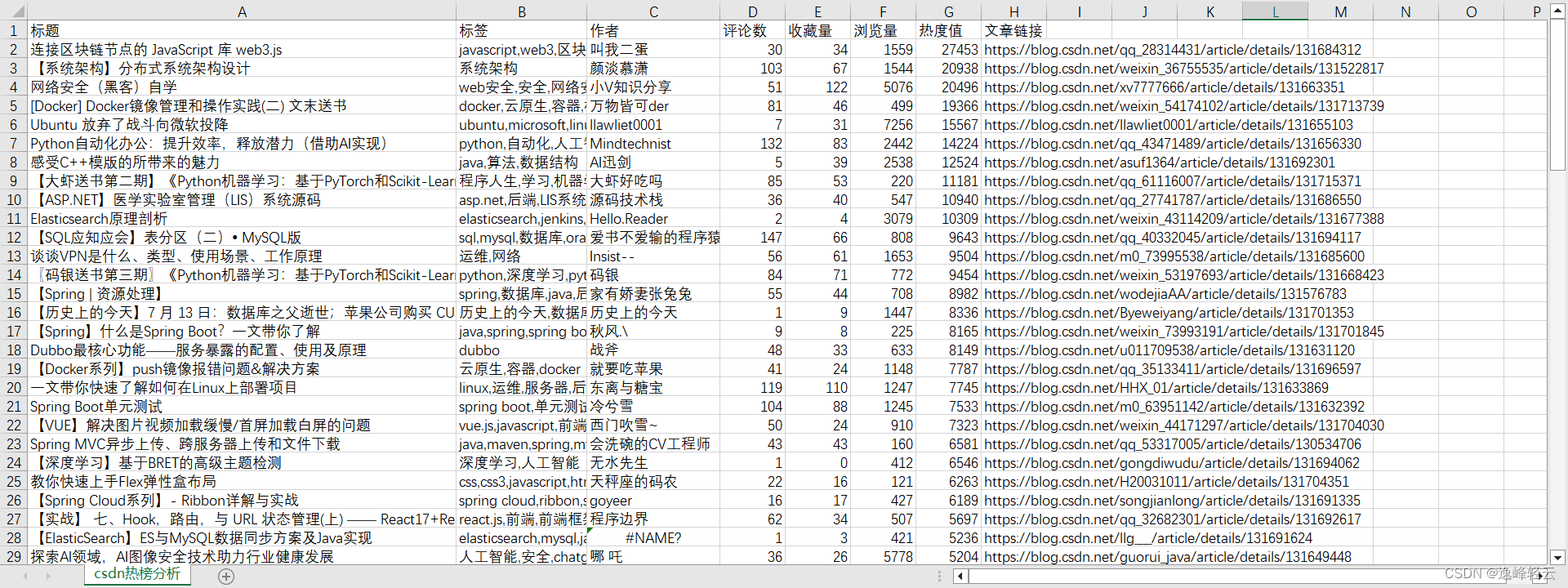
获取热榜文章信息后,我们可以将其保存到CSV文件中,并将标题和标签分别保存到文本文件中,为后面的jieba分析作准备。
def get_hot_list(page):
...
# 将信息存入对应的列表
hot_data_list.append([Title,tag,nickName,commentCount,favorCount,viewCount,hotRankScore,Url])
hot_title_list.append(Title)
hot_tag_list.extend(tag_list)
if __name__ == "__main__":
hot_data_list = [] # 热榜文章信息列表
hot_title_list = [] # 热榜文章标题列表
hot_tag_list = [] # 热榜文章标签列表
for i in range(4):
get_hot_list(i)
with open(r"..\file\csdn热榜分析.csv", "w", newline="", encoding="utf-8-sig") as file:
writer = csv.writer(file)
writer.writerow(["标题", "标签","作者","评论数" ,"收藏量","浏览量", "热度值", "文章链接"])
writer.writerows(hot_data_list)
with open(r"..\file\csdn热榜标签.txt", "w", newline="", encoding="utf-8") as f_tag:
f_tag.writelines(hot_tag_list)
with open(r"..\file\csdn热榜标题.txt", "w", newline="", encoding="utf-8") as f_title:
f_title.writelines(hot_title_list)
上述代码使用for循环获取全部文章信息,其中i表示页数。
使用sys库获取当前py文件所在的目录,以防代码在不同电脑上运行,路径不同存储读取出现问题
if __name__ == "__main__":
...
# 当前py文件所在的目录
bath_path = sys.path[0]
with open(f"{bath_path}\\file\csdn热榜分析.csv", "w", newline="", encoding="utf-8-sig") as file:
writer = csv.writer(file)
writer.writerow(["标题", "标签","作者","评论数" ,"收藏量","浏览量", "热度值", "文章链接"])
writer.writerows(hot_data_list)
...
🌐 分词
Jieba是一个流行的中文分词库,它能够将中文文本切分成词语,并对每个词语进行词性标注。中文分词是自然语言处理的重要步骤之一,它对于文本挖掘、信息检索、情感分析等任务具有重要意义。
接下来,我们将使用jieba库对标题和标签进行分词处理,以便后续的数据分析。
import jieba
# 读取标题和标签文本
with open('csdn热榜标签.txt', 'r') as file:
titles = file.readlines()
with open('csdn热榜标签.txt', 'r') as file:
tags = file.readlines()
# 分词处理
title_words = [jieba.lcut(title.strip()) for title in titles]
tag_words = [jieba.lcut(tag.strip()) for tag in tags]
# 查看分词结果
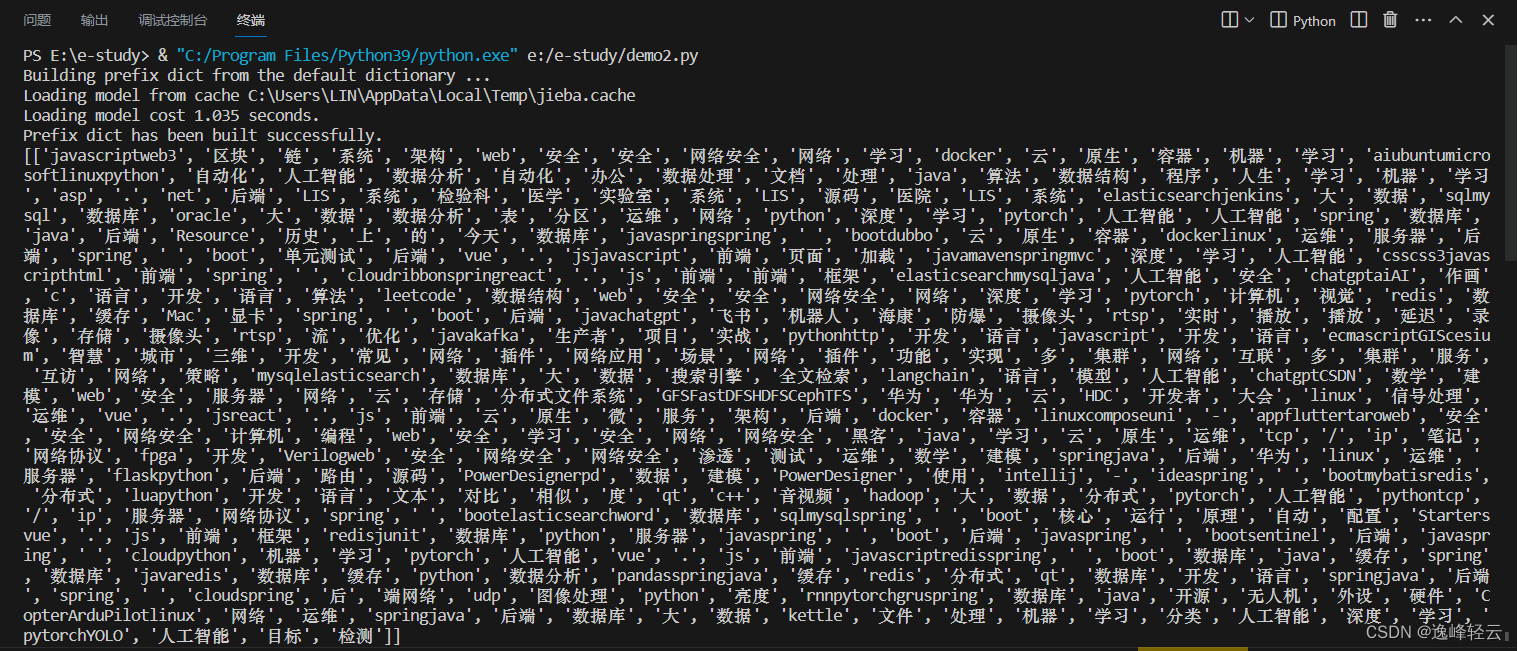
print(title_words[:5])
print(tag_words[:5])
在上述代码中,我们使用jieba库对标题和标签进行分词处理。首先,我们使用jieba.lcut()函数对每个标题和标签进行分词,并将结果存储在列表中。分词结果是一个列表的列表,每个子列表表示一个标题或标签的分词结果。
📊 柱形图
📊 分词统计
构造字典,逐一遍历分词结果中的中文单词进行处理,并用字典计数,然后转为列表进行排序(代码为标题部分示例)。
counts = {} # 构造字典,计数
for title_word in title_words:
for word in title_word:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word, 0) + 1
items = list(counts.items()) # 转换,排序
items.sort(key=lambda x: x[1], reverse=True)
📊 绘制柱形图
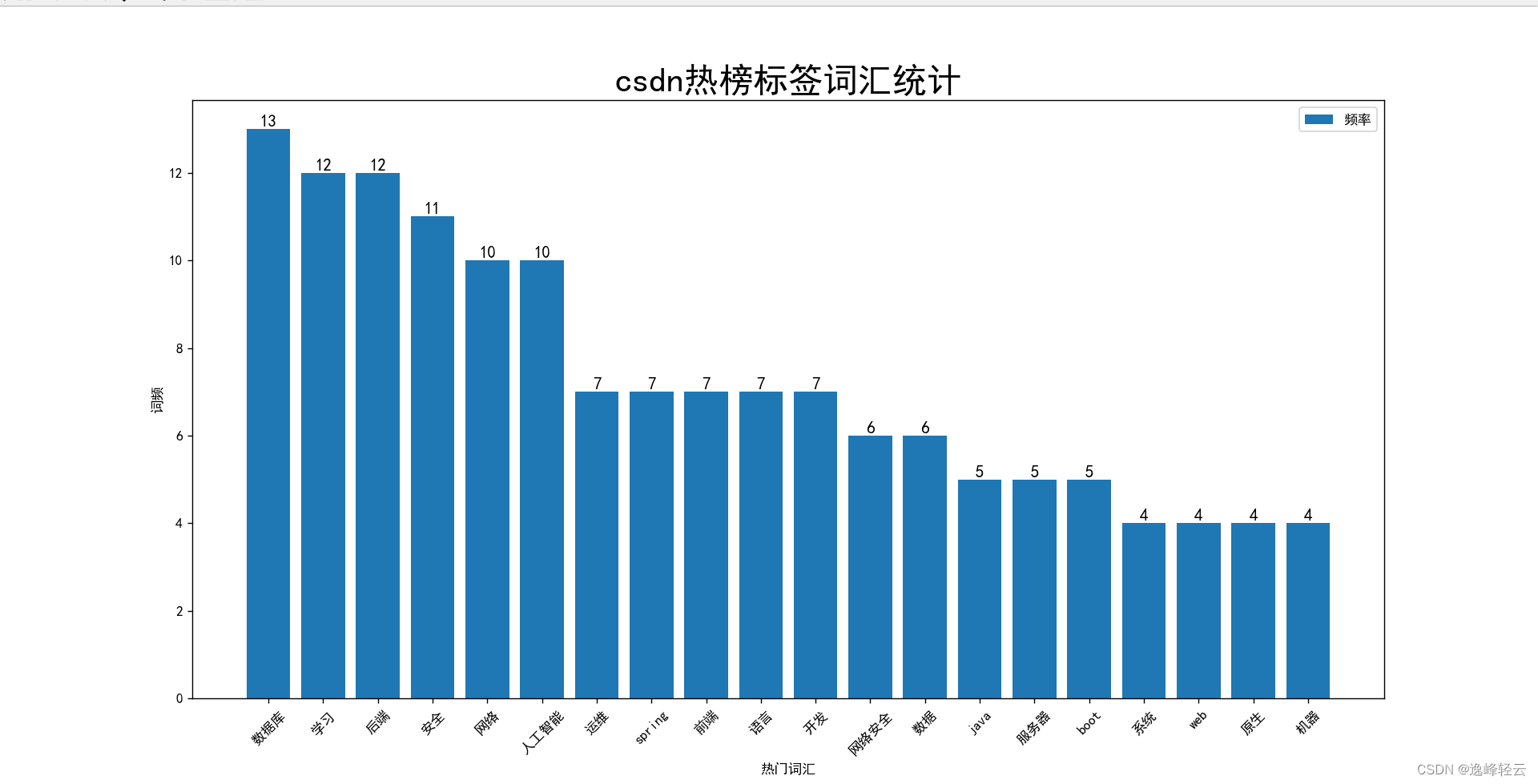
使用pyplot库对标题和标签分词数据进行可视化,这里截取前20的热词。(代码为标题部分示例)
from matplotlib import pyplot as plt
newitems = items[0:20:1] # 截取前20
tu = dict(newitems)
# 定义 x和 y的空列表,用于分别存放tu字典的键和值
x = []
y = []
# 列车键和分别追加到x和y列表
for k in tu:
x.append(k)
y.append(tu[k])
plt.title("csdn热榜标签词汇统计", fontsize=25)# 打印标题
plt.xlabel("热门词汇") # x标签
plt.ylabel("词频") # y标签
plt.xticks(rotation=45, fontsize=10)
# 输出图表中间的文字各种格式的定义
for a, b in zip(x, y):
plt.text(a, b, "%.0f" % b, ha="center", va="bottom", fontsize=12, )
plt.bar(x, y, label="频率") # 图示
plt.legend()
plt.show()# 图表展示
运行结果:

🤔中文显示出现问题,解决办法如下:
# 支持中文
plt.rcParams["font.sans-serif"] = ["SimHei"] # 用来正常显示中文标签
运行结果:
柱形图完成o( ̄▽ ̄)ブ
☁︎ 制作词云
词云是一种可视化工具,可以直观地显示文本数据中词语的重要程度。下面我们使用wordcloud库制作标题和标签的词云图。
# 分词处理
title_words = [jieba.lcut(title.strip()) for title in titles][0]
tag_words = [jieba.lcut(tag.strip()) for tag in tags][0]
title_words_str = ' '.join(title_words) # 连接成字符串
tag_words_str = ' '.join(tag_words) # 连接成字符串
stopwords = ["[", "]", "【", "】",'(',')', '(', ')', '|', '/', ] # 去掉不需要显示的词
words_img = wordcloud.WordCloud(font_path="msyh.ttc",
width = 1000,
height = 700,
background_color='white',
max_words=100,stopwords=stopwords)
# msyh.ttc电脑本地字体,写可以写成绝对路径
words_img.generate(title_words_str) # 加载标题词云文本
words_img.to_file(r"..\file\标题词云.png") # 保存词云文件
words_img.generate(tag_words_str) # 加载标签词云文本
words_img.to_file(r"..\file\标签词云.png") # 保存词云文件
在上述代码中,我们首先将分词结果转换为一个字符串,以便传递给WordCloud类。然后,使用WordCloud类制作标题和标签的词云图。

📑 结论
通过本文的学习,我们掌握了使用Python获取热榜文章标题和标签的方法,并使用jieba库进行数据分析。我们学习了如何保存数据到CSV文件和文本文件中,如何使用jieba库进行分词处理,以及如何制作词云图和直方图来分析数据。
数据处理和分析是数据科学和机器学习的重要步骤之一。掌握这些技能可以帮助我们从大量的数据中提取有用的信息,并进行深入的数据分析和可视化。希望本文对你在Python数据处理和分析方面的学习有所帮助!
⭐️希望本篇文章对你有所帮助。
⭐️如果你有任何问题或疑惑,请随时向提问。
⭐️感谢阅读!
![[英语单词] components;](https://img-blog.csdnimg.cn/81a2a1d1622a47d3bc441bd41973d0f1.png#pic_center)