Multiframe-to-Multiframe Network for Video Denoising
摘要
现存方法:多相邻帧恢复一个干净帧,效果好但是由于按顺序去噪考虑可能造成视频闪烁;
本文:提出一个多帧对多帧的去噪模型,从连续噪声帧中恢复多个干净帧。本文基于训练策略,从时间和空间优化去噪视频,从而保持时间一致性。
MMNet架构:采用时空卷积机构,同时考虑帧间相似性和单帧特性。受益于并行机制
INTRODUCTION
1、去噪应用很广泛、基本的噪声退化模型为:z=r+α ,在视频中,区别于静态图像,视频中包含 possess spatial information和 rich temporal redundancy
由于视频特性,因此面临两个挑战:(1)the volume of video data 大,(2)the content in each frame varies continuously in the temporal dimension;(单帧的内容在时间维度上不断变化)
2、解决问题的传统方法——handcrafted priors to model clean videos,其中,经典的是patch-based methods (文中分析了实现的三步策略),目前CNN-Based的方法,通过中间的参考帧及其相邻辅助帧作为输入,输出与参考帧对应的去噪帧,但是存在缺点:(1)不能直接从时间维度上优化质量,因为它们以逐帧的方式恢复干净的序列,可能会导致视觉闪烁。(2)它们效率不够高,因为它们必须处理多个帧才能仅恢复一帧。

4、比较MM和SS/MS的不同和优势
比较SS:充分利用了序列的时间冗余信息,提高空间质量
比较MS:MS广泛用于video denoising和brust image denoising,但是本文提出可以输出多个连续帧而不是单帧,能够优化时间维度信息,
由于并行机制的做作,MM更有效,此外,与其他视频处理工作 [39]-[41] 采用以多帧作为输入并输出多帧的训练方案不同,所提出的方法侧重于在训练和测试阶段重建多帧.
5、MMNet模块及其作用
the proposed MMNet consists of an interframe denoising module, intraframe denoising module, and merging module
帧间去噪The interframe denoising module 通过从空间和时间维度提取特征来探索帧间相似性,这有助于利用连续帧内的时间冗余。
帧内去噪the intraframe denoising module 侧重于通过提取空间特征来细化单帧特征,这有助于提高每个单独帧的空间表示
Subsequently, the merging module 聚合两组特征并估计干净的序列。
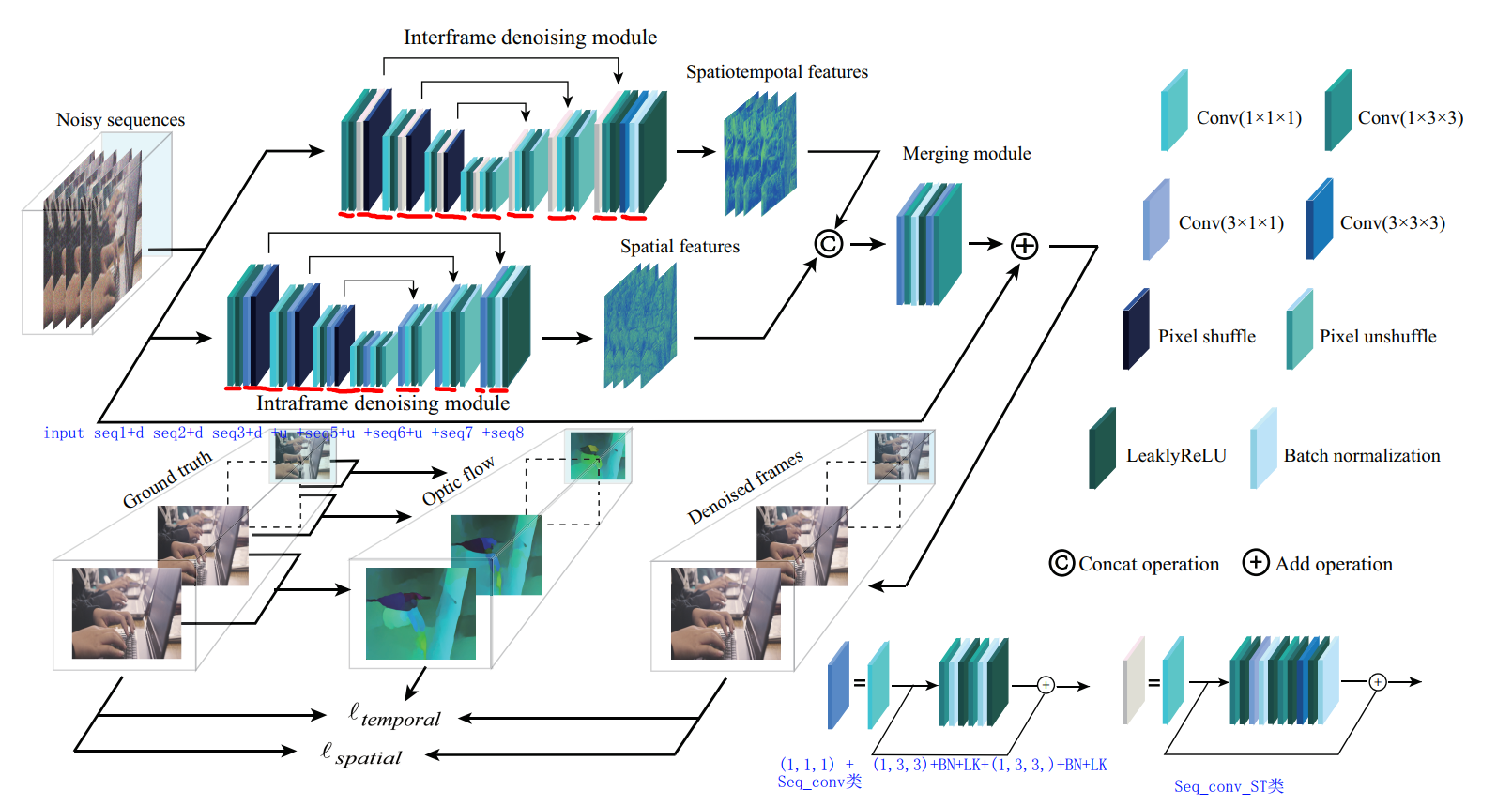
原文:帧间去噪模块explores the interframe similarity by extracting the features from both the spatial and temporal dimensions, which helps to capitalize on the temporal redundancy within consecutive frames. 相比之下,帧内去噪模块 focuses on refining the single-frame characteristics by extracting spatial features, which helps to improve the spatial representation of each individual frame. 随后,合并模块ggregates both sets of features and estimates the clean sequence. MMNet recovers video in parallel and does not need to calculate the flow in the reference stage, which considerably improves the denoising efficiency.
RELATED WORK
(1)图像去噪
类似于SS方法,近几年比较火热,其中基于CNN的方法特别火,简单介绍两个人提出来的模型。这些基于CNN虽然扩展到图像去噪,但是由于特征提取过程中使用简单网络的局限性,因此性能有限
为了提取更具代表性的时空特征,大部分工作致力于CNN架构开发;简单介绍DnCNN和基于其改进的模型;通过编码器-解码器架构;通过建立噪声模型等等;但是这些没有考虑连续帧之间的时间冗余,性能并不好。
(2)视频去噪
相邻视频帧之间的高相关性提供了丰富的时间冗余,有助于提高去噪质量。为了充分利用时间冗余,现有的视频去噪方法倾向于采用MS去噪方案。例如,[12] 通过使用归纳过程在视频序列的数据自适应时空子域中搜索相似块,将 BM3D 提出的想法扩展到视频去噪 (VBM3D)。基于这种方法,VBM4D [15] 使用运动补偿的 3D 补丁来克服 VBM3D 无法区分分组相似补丁的时间和空间相似性的主要问题。在 [13] 中,VBM4D 的更新版本,称为 BM4D,通过将相互相似的矩形 3D 补丁堆叠成 4D 阵列,然后时在变换域中去除噪声来实现视频去噪。此外,为了减轻运动伪影,Buades 等人。[16] 提出了一种去噪算法,它将基于补丁的去噪方法与运动估计方法相结合。这些方法大大提高了最终的视频质量;然而,它们中的大多数依赖于手工制作的先验,并且在处理视频数据方面效率低下,在去噪质量和效率方面为进一步提高性能留下了相当大的空间。
最近,随着深度学习的进步,相关技术已应用于许多视频处理任务,例如语义分割[51]、事件摘要[52]-[54]和手语识别[55]。为了提高去噪性能,已经提出了许多基于深度学习的视频去噪方法。 [33] 中最早的尝试设计了一种用于视频去噪的循环架构。然而,这种方法不能有效地利用自相似性,导致去噪性能无法与基于补丁的方法竞争。为了解决这个问题,更多的研究倾向于采用 CNN 模型来学习从输入到输出的直接映射。特别是,[23]-[25] 中提出的方法使用级联 2D-CNN 分别执行空间和时间去噪,这使它们能够实现最先进的去噪性能。此外,在 [26]、[27] 中提出了一种将基于非局部补丁的方法与 CNN 模型相结合的视频非局部去噪网络。在[29]中,薛等人。将运动估计和图像处理步骤集成到视频处理模型中,以自我监督的方式利用面向任务的流程。在[31]中,徐等人开发了用于视频去噪的 3D 可变形内核,并提出了一种时空像素聚合网络,以有效地对时空空间中的像素进行采样。与基于补丁的方法相比,基于 CNN 的方法在去噪质量方面取得了巨大的进步。然而,他们逐帧恢复干净的序列,这使得他们无法在时间维度上优化去噪结果。此外,为了恢复干净的序列,他们必须多次处理每个有噪声的帧,这限制了他们的去噪效率。与上述方法相比,本文提出的方法采用了直接恢复短序列的MM去噪方案,使去噪模型能够在空间和时间维度上优化去噪结果,实现更具竞争力的去噪效率。
METHODOLOGY
MM Denoising Scheme
$X \times T \rightarrow R $ 被定义为 z ( x , y , t ) = r ( x , y , t ) + η ( x , y , t ) x , y ∈ X , t ∈ T z(x, y, t)=r(x, y, t)+\eta(x, y, t) \quad x, y \in X, t \in T z(x,y,t)=r(x,y,t)+η(x,y,t)x,y∈X,t∈T
r代表干净视频,η表示增加噪声,(x,y,t)表示3D时空坐标,其中X为空间坐标,T为时间域
观察到的视频序列z(X,T),根据去噪模型D(.) 通过网络模型参数θ恢复得到去噪序列$ \overline r $
对于SS来说模型: r ~ ( X , t ) = D ( z ( X , t ) ; Θ ) \tilde{r}(X, t)=\mathrm{D}(z(X, t) ; \Theta) r~(X,t)=D(z(X,t);Θ)
对于MS来说模型: r ~ ( X , t ) = D ( z ( X , t { − n , n } ) ; Θ ) \tilde{r}(X, t)=\mathrm{D}\left(z\left(X, t_{\{-n, n\}}\right) ; \Theta\right) r~(X,t)=D(z(X,t{−n,n});Θ)
其中,z(X,t)表示从序列中Z(X,T)中的一个噪声帧,n表示相邻帧数量,$ \overline r $(X,t)表示t时刻恢复的干净帧,
显然,SS 或 MS 去噪模型的去噪结果的时间一致性无法在时间维度上进行优化,因为这些模型以逐帧方式恢复序列。此外,SS去噪模型根本无法利用时间冗余来提高去噪结果的空间质量。
本文模型: r ~ ( X , t { − n ^ , n ^ } ) = D ( z ( X , t { − n , n } ) ; Θ ) \tilde{r}\left(X, t_{\{-\hat{n}, \hat{n}\}}\right)=\mathrm{D}\left(z\left(X, t_{\{-n, n\}}\right) ; \Theta\right) r~(X,t{−n^,n^})=D(z(X,t{−n,n});Θ)
r ~ ( X , t { − n ^ , n ^ } ) \tilde{r}\left(X, t_{\{-\hat{n}, \hat{n}\}}\right) r~(X,t{−n^,n^}) 为去噪的序列, 去噪模型的恢复总帧数2 n ‾ \overline n n+1( n ‾ \overline n n<n);与 SS 和 MS 去噪方案相比,所提出的方案同时恢复多个连续帧,使其能够在空间和时间维度上优化去噪结果。因此,我们提出了一种由空间损失和时间损失组成的混合损失来训练去噪模型。
The Architecture of MMNet
1)Interframe Denoising Module
As shown in Fig. 3, in this module,
the down sampling or upsampling operationsare implemented using [56], which conducts a transformation between the spatial and channel dimensions for the extracted features. Moreover,a spatiotemporal convolution operation[57] is used to extract the spatiotemporal features from both the spatial and temporal dimensions by convolving a 3D kernel to the 3D ectangular patches of the consecutive input frames. Specifically, convolution kernels with sizes of 1 × 3 × 3,3 × 1 × 1, and 3 × 3 × 3 are used to extract the spatial features and the temporal features and aggregate the spatiotemporal information, respectively. The output feature maps are set to 64.
为了充分利用视频中的时间冗余,通过编码器-解码器架构实现的帧间去噪模块。如图 3 所示,在该模块中,下采样或上采样操作是使用the pixel-shuffle strategy像素混洗策略 [56] 实现,该策略对提取的特征进行空间和通道维度之间的转换。此外,时空卷积操作 [57] 用于通过将 3D 内核卷积到连续输入帧的 3D 矩形块上来从空间和时间维度中提取时空特征。具体来说,分别使用大小为 1×3×3、3×1×1 和 3×3×3 的卷积核来提取空间特征和时间特征并聚合时空信息。输出特征图设置为 64。此外,LeakyReLU 非线性[58]和批量归一化[59]用于促进模型训练。通过这种方式,所提出的模块有效地利用了输入的连续帧内的帧间相似性
2)Intraframe Denoising Module
原因:方法在时空特征的帮助下利用了连续帧内的时间冗余。然而,当去噪模型仅使用时空特征来表示每个帧时,**每个单独帧的空间表示可能会受到对象运动的影响。结果,去噪结果可能会受到运动伪影的影响。**因此,必须细化每个单独帧的特征以改善它们的空间表示。
在这项工作中,我们提出了一个帧内去噪模块来探索单帧特征。帧内去噪模块的主干类似于帧间去噪模块;然而,帧内去噪模块通过将2D内核卷积到输入帧的矩形块独立地提取每个输入帧的空间特征。因此,帧内去噪模型只关注每个输入帧的空间维度,有助于避免物体运动对每个帧的空间表示的影响。本质上,单帧特征是对时空特征的补充,有助于为每个单独的帧生成更准确的空间表示。
3)Merging Module
The merging module is used to recover consecutive frames by aggregating the extracted spatiotemporal and spatial features.
(1)connect the spatiotemporal and spatial features. 连接前面两个模块的特征
(2)**spatial convolution operation **时空卷积操作对提取的特征进行整合,生成残余噪声映射
(3)adopt the residual learning strategy [60]恢复去噪结果
此模块 我们使用一个简单的架构合并模块,因为特征已经完全提取了帧间和帧内去噪模块。
MM Training
To optimize the denoising model, we propose a hybrid loss(混合损失) for network training.因为混合损失函数包括时间损失,因为时间一致性是视频的重要perceptual factor感知因素
混合损失函数: ℓ h y b r i d = ℓ spatial ( r , r ~ ) + λ ℓ temporal ( r , r ~ ) \ell_{h y b r i d}=\ell_{\text {spatial }}(r, \tilde{r})+\lambda \ell_{\text {temporal }}(r, \tilde{r}) ℓhybrid=ℓspatial (r,r~)+λℓtemporal (r,r~)
三个分别代表空间、时间和混合损失,参数λ用来平衡时间和空间损失,其中空间损失类似于MS和SS中的损失函数;时间损失强制去噪序列中的对象运动和光照变化在时间上与原始序列的一致。
spatial loss 利用空间损失来确保每个去噪帧的内容尽可能接近地面真实值。一般来说,MS或SS去噪方法中常用的损失函数可以作为空间损失函数;其中包括均方损失[25]、总变异损失[61]和知觉损失[62]。本文为了简化采用mean-squared loss 均方差损失
ℓ
spatial
(
r
,
r
~
)
=
1
2
B
∑
i
=
1
B
∑
t
=
−
n
^
n
^
∥
r
~
i
(
X
,
t
)
−
r
i
(
X
,
t
)
∥
2
=
1
2
B
∑
i
=
1
B
∑
t
=
−
n
n
∥
D
(
z
i
(
X
,
t
)
;
Θ
)
−
r
i
(
X
,
t
)
∥
2
\begin{aligned} \ell_{\text {spatial }} &(r, \tilde{r})=\frac{1}{2 B} \sum_{i=1}^{B} \sum_{t=-\hat{n}}^{\hat{n}}\left\|\tilde{r}_{i}(X, t)-r_{i}(X, t)\right\|^{2} \\ =\frac{1}{2 B} \sum_{i=1}^{B} \sum_{t=-n}^{n}\left\|\mathrm{D}\left(z_{i}(X, t) ; \Theta\right)-r_{i}(X, t)\right\|^{2} \end{aligned}
ℓspatial =2B1i=1∑Bt=−n∑n∥D(zi(X,t);Θ)−ri(X,t)∥2(r,r~)=2B1i=1∑Bt=−n^∑n^∥r~i(X,t)−ri(X,t)∥2
B表示训练对的batch,ˆn表示参考帧的相邻帧。该去噪模型利用空间损失去除输入序列中的大部分噪声。然而,空间损失独立评估每个去噪帧,这导致无法从时间维度优化去噪序列。
Temporal Loss为了使去噪视频获得更好的时间一致性,我们提出了一个时间损失,通过强制去噪视频的运动和强度变化在时间上保持与原始视频的一致来优化恢复的连续帧。具体来说,我们首先计算帧r(X,t)和它的前帧r(X,t−1)之间的前向光流
f
o
(
X
,
t
)
=
F
(
r
(
X
,
t
)
,
r
(
X
,
t
−
1
)
)
f o(X, t)=\mathrm{F}(r(X, t), r(X, t-1))
fo(X,t)=F(r(X,t),r(X,t−1))(F为光流估计函数),
然后,将去噪后的帧和gt帧按照以下计算流程进行变形: r w ′ ( X , t ) = W ( r ′ ( X , t − 1 ) , f o ( X , t ) ) r_{w}^{\prime}(X, t)=\mathrm{W}\left(r^{\prime}(X, t-1), f o(X, t)\right) rw′(X,t)=W(r′(X,t−1),fo(X,t)) 其中, r ′ ( X , t − 1 ) r^{\prime}(X, t-1) r′(X,t−1)表示gt的序列帧或者去噪的序列帧,W即为计算从t-1帧到t帧补偿光流的函数[40]
r
w
r_w
rw表示变形后的gt帧,
r
~
w
\tilde{r}_{w}
r~w表示变形后的去噪帧,由于我们只注重当前帧和变形帧的感知质量,由于在序列运动中,
r
′
r^{\prime}
r′的一些像素可能不在
r
w
′
r_{w}^{\prime}
rw′中,因此通过mask掩码m计算这些时间上的损失,
ℓ
temporal
(
r
,
r
~
)
=
1
B
∑
i
=
1
B
∑
t
=
−
n
^
+
1
n
^
∥
m
i
(
X
,
t
)
⊙
(
(
r
~
i
(
X
,
t
)
−
r
~
w
i
(
X
,
t
)
)
−
(
r
i
(
X
,
t
)
−
r
w
i
(
X
,
t
)
)
)
∥
,
\begin{array}{r} \ell_{\text {temporal }}(r, \tilde{r})=\frac{1}{B} \sum_{i=1}^{B} \sum_{t=-\hat{n}+1}^{\hat{n}} \| m_{i}(X, t) \odot\left(\left(\tilde{r}_{i}(X, t)-\right.\right. \\ \left.\left.\tilde{r}_{w i}(X, t)\right)-\left(r_{i}(X, t)-r_{w i}(X, t)\right)\right) \|, \end{array}
ℓtemporal (r,r~)=B1∑i=1B∑t=−n^+1n^∥mi(X,t)⊙((r~i(X,t)−r~wi(X,t))−(ri(X,t)−rwi(X,t)))∥,
其中m (X, t)∈[0,1]是利用光流计算的掩模,在遮挡边界和运动边界区域为0,在其他区域为1.圆圈表示乘法,虽然光流计算占用了大量的时间,但只需要在训练阶段进行计算;在参考阶段,不需要光流信息,这有助于提高模型的竞争性去噪效率。
EXPERIMENTAL RESULTS
Experimental Settings
(1)权值的初始化:采用Kaiming uniform initialization[64]Kaiming均匀初始化
(2)ADAM优化器,epoch=35,batch=10,lr init=0.0004,每6个epoch后lr降低2倍,patch=128,input_frame=7,loss的超参数为0.02(该参数设定参考第五节)
(3)训练数据集:(合成)向Vimeo-90K dataset添加参数为δ∈[0,55]的AWGN
(4)测试数据集:(真实) the Captured Raw Video Denoising (CRVD)2 dataset [30]
注意,所提出的方法适用于标准 RGB (sRGB) 视频去噪;但是,CRVD 数据集包含 RAW 格式的视频。因此,我们遵循 [30] 中使用的技术,并使用预训练的图像信号处理器 (ISP) 模型 [66] 生成真实的 sRGB 视频数据集。
(5)评估标准:PSNR和SSIM,还有一个:此外,在 FastDVDnet [25] 之后,the spatiotemporal reduced reference entropic differences (ST-RRED) [67] 指数来测量时间失真并评估时间一致性。
Comparison Results for Gaussian Noise
主要是于SS和MS方法的进行比较
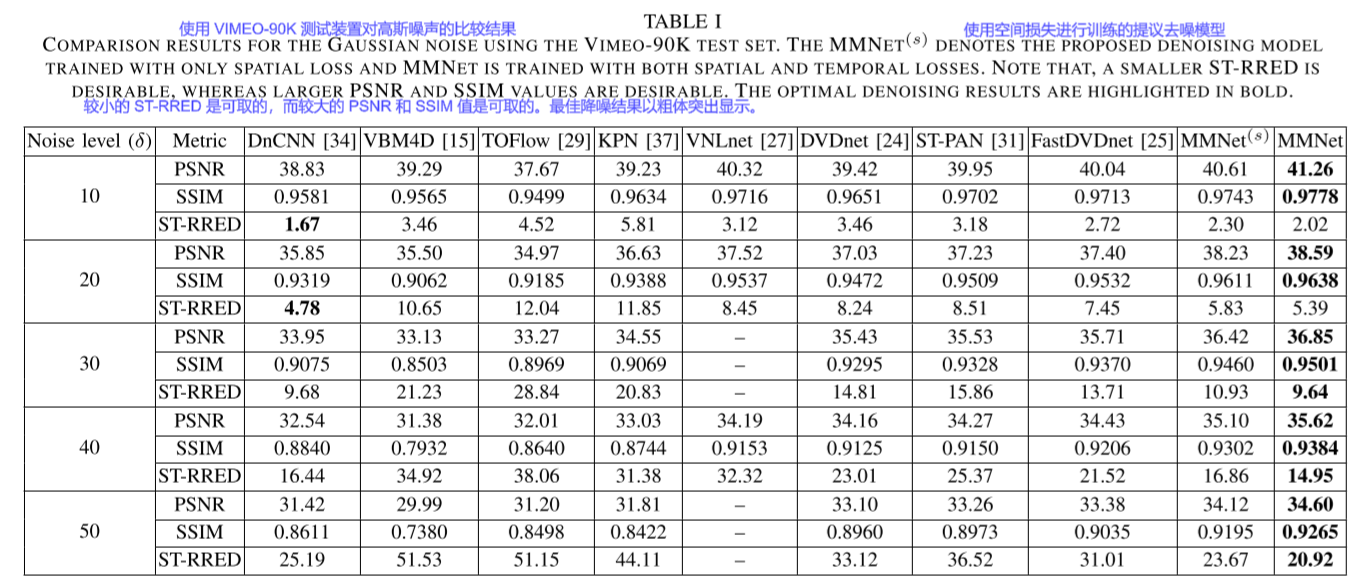
相比较于DnCNN,MMNet的成绩归功于其帧内去噪模块可以充分探索连续帧之间的空间和时间冗余信息
相比较于MS去噪,MMNet的成绩归功于其架构设计和提出的MM训练模式:充分考虑到帧间相似性和单帧特征,减少了时间冗余,减少伪影
另外,表中可以看出时间损失函数的设计可以优化结果,执行效果有提升(最后两个的区别 加不加temporal losses)
原图的图4 :注意绿色框中显示的面部和背景的清晰度。所提出的方法可以恢复更清晰的人脸并在背景中产生更少的伪影。
Comparison Results for Real-World Noise

这些值不同的原因:对真实噪声和高斯噪声进行去噪的不同方法的性能是不同的。这些差异可能是因为 CRVD 测试数据集的数据分布与 Vimeo-90K 测试数据集的数据分布不同,并且真实噪声比高斯噪声更复杂。此外,真实噪声和高斯噪声的去噪模型的学习能力和通用性是不同的。原图6显示这些方法的一些图片比较结果。
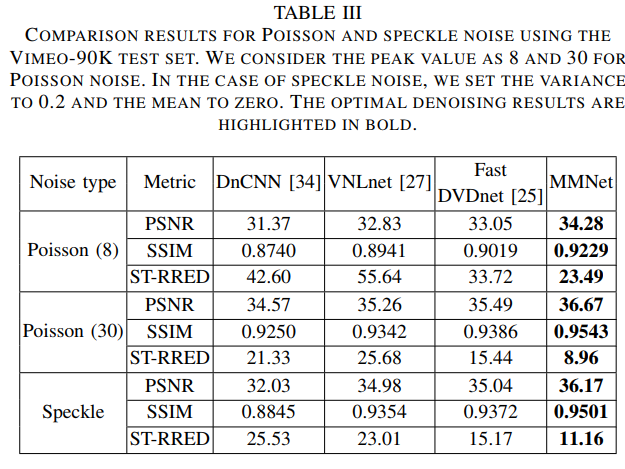
Generality Evaluation Using Other Types of Noise
与含有其他噪声的方法进行对比 Poisson noise and speckle noise (泊松噪声和散斑噪声) 【其模型都采用相应的噪声进行重新训练】
Temporal Consistency
Temporal consistency is an important factor for visual quality. 本文通过ST-RRED作为非主观的指标进行测评,结果见表1,ST-REDD值越小越好,
MS去噪方法的时间质量主要依赖于从连续输入帧中学习残差,但由于缺乏明确的监督,学习到的残差可能不准确。相比之下,所提出的 MMNet 不仅从输入中学习残差,而且从时间维度优化输出。此外,所提出的 MMNet 使用帧内去噪模块来细化每个单独帧的特征,以改善它们的空间表示,因此,其值更明显。

图8,DnCNN 无法利用时间冗余来恢复纹理细节,导致恢复草的过度平滑和草纹理的不一致。
最先进的方法 DVDnet和FastDVDnet能够恢复草地区域的一些细节,但它们会产生运动伪影,导致细节纹理的时间不一致。相比之下,在时间损失的帮助下,所提出的MMNet恢复了精细的细节并保持了高时间一致性。
Runtime

这种显着的改进可以归因于底层的并行机制和 MMNet 隐式处理运动的能力。
DISCUSSION AND ANALYSIS 细节问题讨论
Ablation Study
删除其中一个模块的结果
去掉帧间模块:使其无法利用时空冗余来恢复精细细节
去掉帧内模块:仅使用时空特征来表示每一帧时,每一帧的空间表示可能会受到对象运动的影响,从而导致运动伪影。因此,帧间和帧内去噪模块都有助于提高去噪质量。

Discussion of the Number of Frames
设计:训练集仍采用Vimeo-90K dataset. 考虑GPU内存的问题,主要讨论帧数为:1,3,5,7
从两方面进行考虑,输出帧和输出帧的数量的问题
2)Discussion of the Number of Input Frames

2) Discussion of the Number of Output Frames
同时恢复多个帧使所提出的方法能够优化空间和时间维度的去噪结果,然而,它也导致不对称的时间信息利用,因为一些恢复的帧将不是输入序列的中心帧。

一个使用 7 帧作为输入并恢复 3 帧(以蓝色、绿色和红色框表示)的示例。绿色框对称地利用了前三帧和后三帧,而蓝色框不对称地利用了前两帧和后四帧;同样,红色框不对称地利用了前四帧和随后的两帧。
为了分析输出帧数的影响,我们进行了实验,其中输入帧数固定为 7,恢复输出帧数变化。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CcQtArwM-1689334219366)(https://data-1306794892.cos.ap-beijing.myqcloud.com/typora_imgs/typora_imgs/20220315-1248-332.png)]
当输出帧数大于1时,没有出现实质性的改善或下降,这表明非对称时间信息利用的影响非常有限。此外,与仅恢复一帧的方法相比,恢复多帧(即 3、5 和 7)的方法获得了更具竞争力的性能,这证明了从空间和时间维度优化去噪结果的有效
根据分析,结合10(b)我们发现在输出帧为7时,运行时间也会更小,决定选7
Analysis of the Hyperparameter λ
损失函数中参数设定
超参数 λ 对于优化去噪结果很重要。通过在 Vimeo-90K 测试集上进行实验来对λ进行敏感性分析,不同的λ值范围从0到1。噪声水平设置为25和45。如图12所示,总体而言,提出的MMNet当λ取值在 0.01到0.1之间时,去噪质量显着提高,当λ设置为0.02时,去噪效果最好。因此,在这项工作中,我们将λ设置为 0.02 来训练提出的MMNet

CONCLUSIONS
MMNet 实现了最先进的去噪质量。此外,它并行恢复视频帧,不需要在参考阶段计算流量,从而具有极具竞争力的去噪效率。对合成数据集和真实数据集的广泛比较证明了所提出方法的有效性和优越性。
问题:
(1)MMNet 需要成对的训练数据,因此当应用程序无法有效获取成对数据时,模型无法轻松微调
(2)MMNet 隐式处理对象运动,因此在某种程度上,它处理运动的能力依赖于训练数据。这些方面是所提出方法的主要限制。
(3)在未来的工作中,我们计划以自我监督的方式实施 MM 去噪方案,并提高 MMNet 对不同运动水平的鲁棒性。
外,它并行恢复视频帧,不需要在参考阶段计算流量,从而具有极具竞争力的去噪效率。对合成数据集和真实数据集的广泛比较证明了所提出方法的有效性和优越性。
问题:
(1)MMNet 需要成对的训练数据,因此当应用程序无法有效获取成对数据时,模型无法轻松微调
(2)MMNet 隐式处理对象运动,因此在某种程度上,它处理运动的能力依赖于训练数据。这些方面是所提出方法的主要限制。
(3)在未来的工作中,我们计划以自我监督的方式实施 MM 去噪方案,并提高 MMNet 对不同运动水平的鲁棒性。