什么是机器学习(Machine Learning)?
机器学习是]赋予计算机学习能力的研究领域 无需明确编程。 ——阿瑟·塞缪尔,1959
计算机程序可以从关于某些任务的经验 E 中学习 T 和一些绩效衡量 P,如果其在 T 上的绩效按 P 衡量, 随着经验E的提高而提高。 ——汤姆·米切尔,1997
通俗的说,机器学习(Machine Learning)是计算机编程的科学,它们可以从数据中进行学习。
机器学习好比电子邮件中的垃圾邮件过滤器, 由用户标记出垃圾邮件示例和常规邮件的示例,继而让机器去学习标记垃圾邮件。
那些由用户标记的示例用于学习的称为训练( training),而每个训练示例则成为训练实例(或称为训练样本),机器学习过程中并作出预测(predictions)的便成为模型(Model)。
神经网络(Neural networks)和随机森林( random forests)也都是模型的例子。
在这种情况下,任务 T 是标记新电子邮件的垃圾邮件,经验 E 是训练 数据,并且需要定义性能度量P; 例如,您可以使用 正确分类电子邮件的比率。 这种特殊的绩效衡量标准被称为 准确率高,常用于分类任务。
但如果您只是下载所有维基百科文章的副本,您的计算机上还有更多内容数据,但它在任何任务上都不会突然变得更好。 这不是机器学习。
为什么使用机器学习?
我们抛弃机器学习,使用传统编程方式来处理垃圾邮件的过滤器。
- 1、首先,您得检查
垃圾邮件是什么样子的。例如某商城活动推广、房产信息、股票推荐等等。 - 2、是的,您得为以上出现的种种情况编写一套检测算法。
- 3、您将测试您的程序并重复 1、2 步骤,直到它足够好为止。
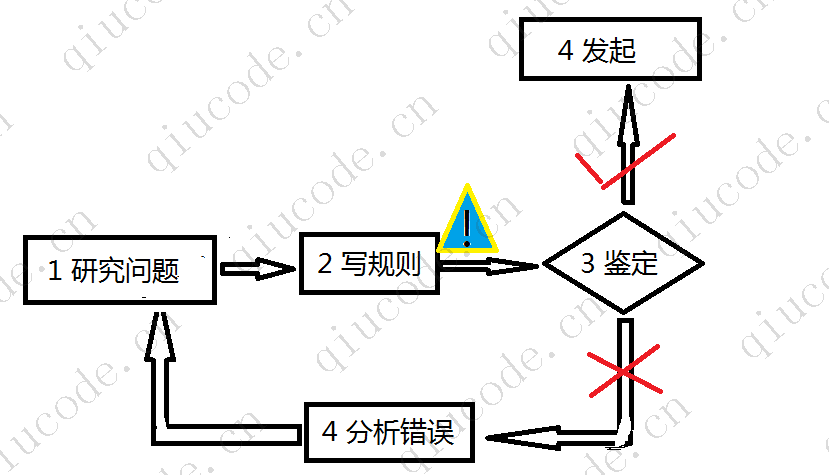
最终您的程序很可能会变成一长串复杂的规则——难以维护。
相比之下,基于机器学习技术的垃圾邮件过滤器会自动学习通过检测异常频率,可以很好地预测垃圾邮件, 与垃圾邮件示例相比, 该程序更短,更容易维护,而且很可能更多准确的。
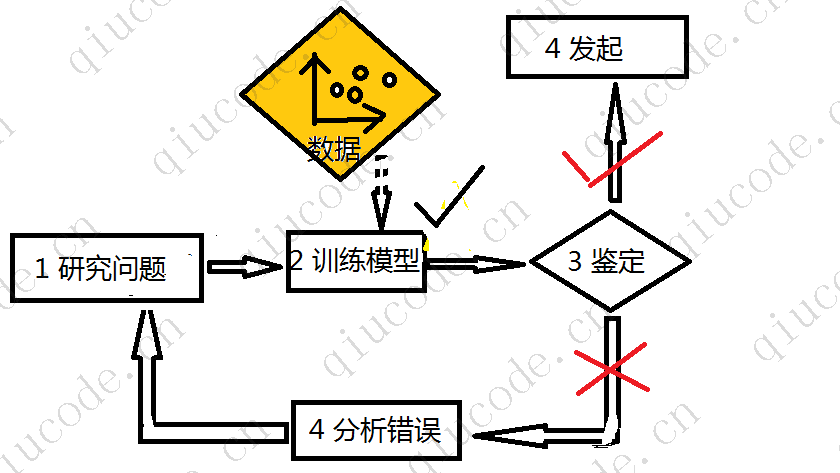
倘若垃圾邮件发送者发现所有含有商城活动推广链接的电子邮件都被阻止了,那该怎么办呢?他们势必会将链接换成短链接。
然而,使用传统编程的垃圾邮件过滤器,则需要更新技术来标记那些以短链接来隐藏的商城活动推广的电子邮件了。假使垃圾邮件发送者继续围绕垃圾邮件过滤器展开工作,您将永远处于被动下地去更新您的规则。
相比之下,基于机器学习技术的垃圾邮件过滤器会自动注意到以短链接形式的商城活动推广邮件,在用户标记的垃圾邮件中变得异常频繁,并且无需您的干预即可标记它们。
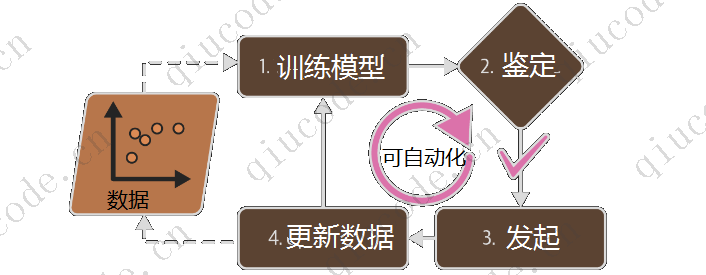
机器学习的亮点便是解决对于传统方法来说过于复杂、抑或是还没有算法的问题。
就拿语音识别来说吧!假使您想从简单开始编写一个能够区分 一 和 二 的程序,或许您可能硬编码一个算法来检测高低音强度并用它来区分。
很显然,这种硬编码技术是无法扩展到数以亿计的人所说的数千个汉语的。
不同的人在噪杂的环境中使用数十种语言,迄今为止最好的解决方案便是编写一个可以自我学习的算法,给出很多文字的录音的示例,最终让机器学习像人类一样去学习。
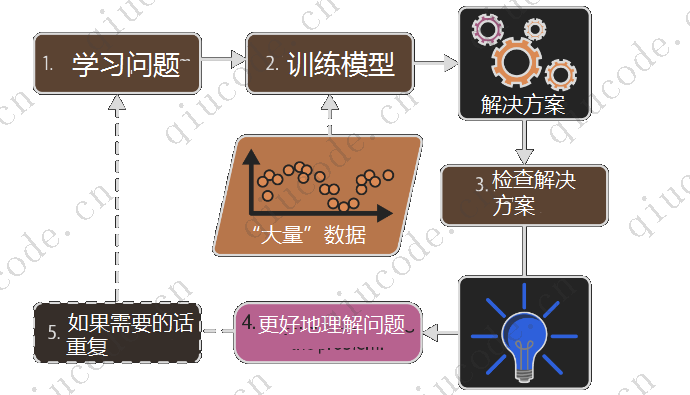
总而言之,机器学习非常适合以下场景:
- 现有解决方案需要大量微调或长列表的问题 规则(机器学习模型通常可以简化代码并且性能比 传统方法)
- 使用传统方法无法解决的复杂问题 (最好的机器学习技术也许可以找到解决方案)
- 波动的环境(机器学习系统可以轻松地进行重新训练 新数据,始终保持最新)
- 深入了解复杂问题和大量数据