自然语言处理(扩展学习1):Scheduled Sampling(计划采样)与2. Teacher forcing(教师强制)
作者:安静到无声 个人主页
作者简介:人工智能和硬件设计博士生、CSDN与阿里云开发者博客专家,多项比赛获奖者,发表SCI论文多篇。
Thanks♪(・ω・)ノ 如果觉得文章不错或能帮助到你学习,可以点赞👍收藏📁评论📒+关注哦! o( ̄▽ ̄)d
欢迎大家来到安静到无声的 《基于pytorch的自然语言处理入门与实践》,如果对所写内容感兴趣请看《基于pytorch的自然语言处理入门与实践》系列讲解 - 总目录,同时这也可以作为大家学习的参考。欢迎订阅,请多多支持!
目录标题
- 自然语言处理(扩展学习1):Scheduled Sampling(计划采样)与2. Teacher forcing(教师强制)
- 1. Scheduled Sampling(计划采样)
- 1.1 概念解释
- 1.2 代码实现
- 2. Teacher forcing(教师强制)
- 2.1 概念解释
- 2.1 代码实现
- 参考
1. Scheduled Sampling(计划采样)
1.1 概念解释
Scheduled Sampling是一种用于训练序列生成模型的策略,旨在缓解曝光偏差(Exposure Bias)问题。曝光偏差是指模型在训练时接触到的数据分布与测试时的数据分布不一致,导致性能下降。
在Scheduled Sampling中,模型在每个时间步骤都有一定的概率选择使用真实目标序列中的单词作为输入,而不是使用前一个时间步骤生成的单词。这样可以使模型更好地适应真实数据分布,减少曝光偏差问题。
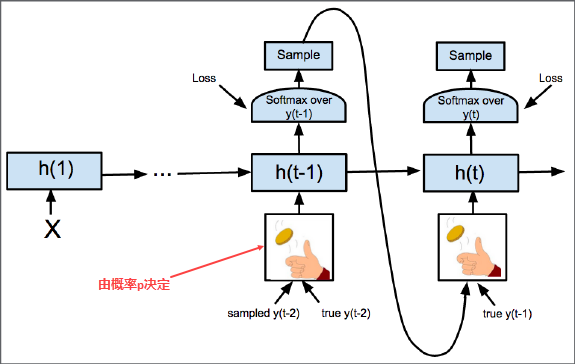
具体来说,Scheduled Sampling使用以下公式计算每个时间步骤生成当前单词的概率:
P ( y t ∣ y 1 , . . . , y t − 1 ) = ( 1 − ϵ ) ∗ P model ( y t ∣ y 1 , . . . , y t − 1 ) + ϵ ∗ P data ( y t ∣ y 1 , . . . , y t − 1 ) P(y_t|y_1, ..., y_{t-1}) = (1 - \epsilon) * P_{\text{model}}(y_t|y_1, ..., y_{t-1}) + \epsilon * P_{\text{data}}(y_t|y_1, ..., y_{t-1}) P(yt∣y1,...,yt−1)=(1−ϵ)∗Pmodel(yt∣y1,...,yt−1)+ϵ∗Pdata(yt∣y1,...,yt−1)其中, P ( y t ∣ y 1 , . . . , y t − 1 ) P(y_t|y_1, ..., y_{t-1}) P(yt∣y1,...,yt−1)表示在给定前面的生成序列条件下生成当前单词 y t y_t yt的概率, P model ( y t ∣ y 1 , . . . , y t − 1 ) P_{\text{model}}(y_t|y_1, ..., y_{t-1}) Pmodel(yt∣y1,...,yt−1)表示模型生成该单词的概率, P data ( y t ∣ y 1 , . . . , y t − 1 ) P_{\text{data}}(y_t|y_1, ..., y_{t-1}) Pdata(yt∣y1,...,yt−1)表示真实目标序列中该单词的概率。参数 ϵ \epsilon ϵ用于控制采样策略,可以随着训练的进行而逐渐增加。
1.2 代码实现
下面是一个使用Python实现Scheduled Sampling的示例代码:
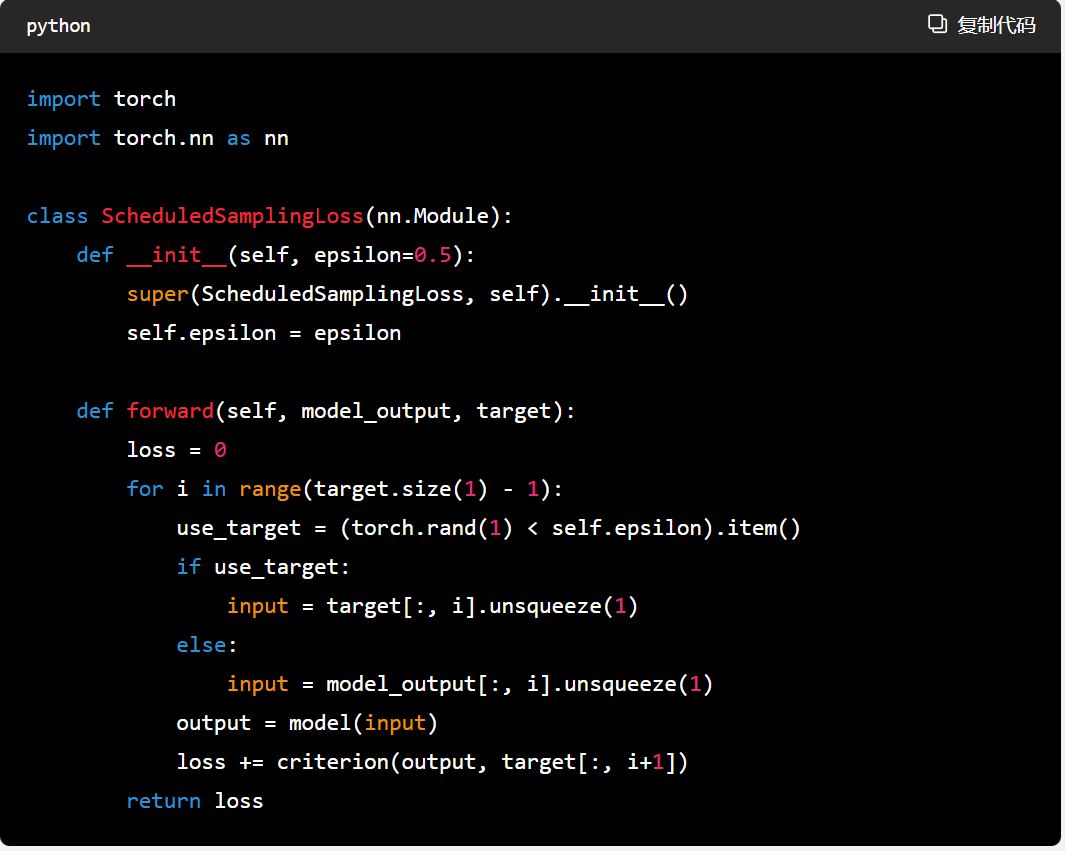
其中, P ( y t ∣ y < t , x ) P(y_t | y_{<t}, x) P(yt∣y<t,x)表示在给定前文和输入的条件下,生成当前时间步的输出的概率。 P model P_{\text{model}} Pmodel表示由模型生成的概率分布, P prev P_{\text{prev}} Pprev表示根据上一个时间步的真实输出计算得到的概率分布。sample是从均匀分布中采样得到的一个随机数,threshold是一个控制Scheduled Sampling引入程度的超参数。
2. Teacher forcing(教师强制)
2.1 概念解释
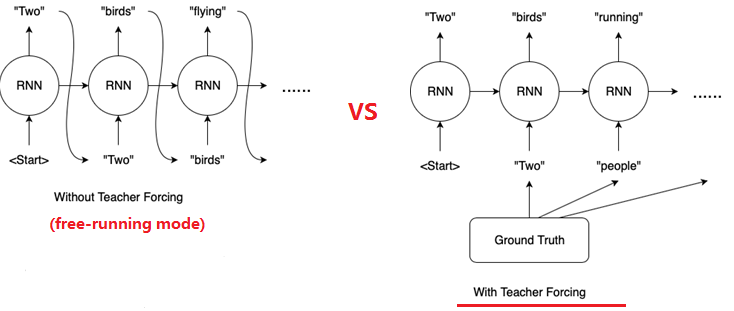
Teacher forcing(教师强制)是一种在序列生成模型中使用的训练技术。具体来说,当使用RNN(循环神经网络)或类似架构的模型进行序列生成时,每个时间步都会根据前一个时间步的输入和隐藏状态生成输出。在训练期间,如果使用teacher forcing,那么每个时间步的输入将是真实的目标序列(而不是模型自身生成的序列)。这意味着模型在每个时间步都能够观察到正确的答案,从而更容易地学习到正确的模式和规律。
2.1 代码实现
import torch
import torch.nn as nn
# 定义序列到序列模型
class Seq2SeqModel(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(Seq2SeqModel, self).__init__()
self.hidden_dim = hidden_dim
# 定义编码器
self.encoder = nn.RNN(input_dim, hidden_dim)
# 定义解码器
self.decoder = nn.RNN(output_dim, hidden_dim)
# 定义全连接层,将解码器的输出映射为目标序列
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, input_seq, target_seq):
# 编码器计算输入序列的隐藏状态
_, hidden_state = self.encoder(input_seq)
# 解码器初始化隐藏状态
decoder_hidden_state = hidden_state
# 用真实目标序列作为输入来指导解码器的生成过程
decoder_outputs, _ = self.decoder(target_seq, decoder_hidden_state)
# 对解码器的输出应用全连接层进行映射
output_seq = self.fc(decoder_outputs)
return output_seq
# 创建模型实例
input_dim = 10
hidden_dim = 20
output_dim = 10
model = Seq2SeqModel(input_dim, hidden_dim, output_dim)
# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练模型
num_epochs = 10
for epoch in range(num_epochs):
# 步骤1:将模型设为训练模式
model.train()
# 步骤2:清零梯度
optimizer.zero_grad()
# 步骤3:前向传播
input_seq = torch.randn(5, 3, input_dim) # 输入序列
target_seq = torch.randn(5, 3, output_dim) # 目标序列
output_seq = model(input_seq, target_seq)
# 步骤4:计算损失
loss = criterion(output_seq, target_seq)
# 步骤5:反向传播和优化
loss.backward()
optimizer.step()
print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, loss.item()))
上述代码中,我们定义了一个简单的序列到序列模型Seq2SeqModel,其中包括一个RNN编码器、一个RNN解码器和一个全连接层。在forward方法中,我们首先使用编码器计算输入序列的隐藏状态,然后将隐藏状态作为解码器的初始隐藏状态。接下来,我们使用真实目标序列来指导解码器的生成过程,并将解码器的输出映射为目标序列。在训练阶段,我们使用真实目标序列作为输入来指导模型的生成过程。最后,我们定义了损失函数和优化器,并进行训练。
需要注意的是,在实际应用中,模型的推理阶段并不会使用真实目标序列来指导生成过程。在推理阶段,可以将前一个时间步的模型输出作为下一个时间步的输入,从而进行序列的自我生成。
--------推荐专栏--------
🔥 手把手实现Image captioning
💯CNN模型压缩
💖模式识别与人工智能(程序与算法)
🔥FPGA—Verilog与Hls学习与实践
💯基于Pytorch的自然语言处理入门与实践
参考
Scheduled Sampling的搜索结果_百度图片搜索 (baidu.com)
Teacher forcing RNN的搜索结果_百度图片搜索 (baidu.com)